
原文鏈接:http://dblab.xmu.edu.cn/blog/install-hadoop/當開始著手實踐 Hadoop 時,安裝 Hadoop 往往會成為新手的一道門檻。儘管安裝其實很簡單,書上有寫到,官方網站也有 Hadoop 安裝配置教程,但由於對 Linux 環境不熟悉,書上跟官網上簡...
原文鏈接:http://dblab.xmu.edu.cn/blog/install-hadoop/
當開始著手實踐 Hadoop 時,安裝 Hadoop 往往會成為新手的一道門檻。儘管安裝其實很簡單,書上有寫到,官方網站也有 Hadoop 安裝配置教程,但由於對 Linux 環境不熟悉,書上跟官網上簡略的安裝步驟新手往往 Hold 不住。加上網上不少教程也甚是坑,導致新手摺騰老幾天愣是沒裝好,很是打擊學習熱情。
本教程由廈門大學資料庫實驗室出品,轉載請註明。本教程適合於原生 Hadoop 2,包括 Hadoop 2.6.0, Hadoop 2.7.1 等版本,主要參考了官方安裝教程,步驟詳細,輔以適當說明,相信按照步驟來,都能順利安裝並運行Hadoop。另外有Hadoop安裝配置簡略版方便有基礎的讀者快速完成安裝。此外,希望讀者們能多去瞭解一些 Linux 的知識,以後出現問題時才能自行解決。
環境
本教程使用 Ubuntu 14.04 64位 作為系統環境(Ubuntu 12.04 也行,32位、64位均可),請自行安裝系統(可參考使用VirtualBox安裝Ubuntu)。
如果用的是 CentOS/RedHat 系統,請查看相應的CentOS安裝Hadoop教程_單機偽分散式配置。
本教程基於原生 Hadoop 2,在 Hadoop 2.6.0 (stable) 版本下驗證通過,可適合任何 Hadoop 2.x.y 版本,例如 Hadoop 2.4.1。
使用本教程請確保系統處於聯網狀態下,部分高校使用星網銳捷連接網路,可能導致虛擬機無法聯網,那麼建議您使用雙系統安裝ubuntu,然後再使用本教程!
Hadoop版本Hadoop 有兩個主要版本,Hadoop 1.x.y 和 Hadoop 2.x.y 系列,比較老的教材上用的可能是 0.20 這樣的版本。Hadoop 2.x 版本在不斷更新,本教程均可適用。如果需安裝 0.20,1.2.1這樣的版本,本教程也可以作為參考,主要差別在於配置項,配置請參考官網教程或其他教程。
新版是相容舊版的,書上舊版本的代碼應該能夠正常運行(我自己沒驗證,歡迎驗證反饋)。
裝好了 Ubuntu 系統之後,在安裝 Hadoop 前還需要做一些必備工作。
創建hadoop用戶
如果你安裝 Ubuntu 的時候不是用的 “hadoop” 用戶,那麼需要增加一個名為 hadoop 的用戶。
首先按 ctrl+alt+t 打開終端視窗,輸入如下命令創建新用戶 :
sudo useradd -m hadoop -s /bin/bash
這條命令創建了可以登陸的 hadoop 用戶,並使用 /bin/bash 作為 shell。
sudo命令本文中會大量使用到sudo命令。sudo是ubuntu中一種許可權管理機制,管理員可以授權給一些普通用戶去執行一些需要root許可權執行的操作。當使用sudo命令時,就需要輸入您當前用戶的密碼.
密碼在Linux的終端中輸入密碼,終端是不會顯示任何你當前輸入的密碼,也不會提示你已經輸入了多少字元密碼。而在windows系統中,輸入密碼一般都會以“*”表示你輸入的密碼字元
輸入法中英文切換ubuntu中終端輸入的命令一般都是使用英文輸入。linux中英文的切換方式是使用鍵盤“shift”鍵來切換,也可以點擊頂部菜單的輸入法按鈕進行切換。
Ubuntu終端複製粘貼快捷鍵在Ubuntu終端視窗中,複製粘貼的快捷鍵需要加上 shift,即粘貼是 ctrl+shift+v。
接著使用如下命令設置密碼,可簡單設置為 hadoop,按提示輸入兩次密碼:
sudo passwd hadoop
可為 hadoop 用戶增加管理員許可權,方便部署,避免一些對新手來說比較棘手的許可權問題:
sudo adduser hadoop sudo
最後註銷當前用戶(點擊屏幕右上角的齒輪,選擇註銷),返回登陸界面。在登陸界面中選擇剛創建的 hadoop 用戶進行登陸。
更新apt
用 hadoop 用戶登錄後,我們先更新一下 apt,後續我們使用 apt 安裝軟體,如果沒更新可能有一些軟體安裝不了。按 ctrl+alt+t 打開終端視窗,執行如下命令:
sudo apt-get update
若出現如下 “Hash校驗和不符” 的提示,可通過更改軟體源來解決。若沒有該問題,則不需要更改。從軟體源下載某些軟體的過程中,可能由於網路方面的原因出現沒法下載的情況,那麼建議更改軟體源。在學習Hadoop過程中,即使出現“Hash校驗和不符”的提示,也不會影響Hadoop的安裝。
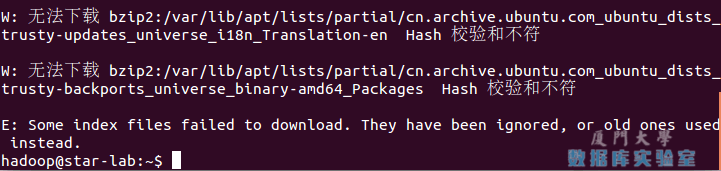 Ubuntu更新軟體源時遇到Hash校驗和不符的問題
Ubuntu更新軟體源時遇到Hash校驗和不符的問題
點擊查看:如何更改軟體源
後續需要更改一些配置文件,我比較喜歡用的是 vim(vi增強版,基本用法相同),建議安裝一下(如果你實在還不會用 vi/vim 的,請將後面用到 vim 的地方改為 gedit,這樣可以使用文本編輯器進行修改,並且每次文件更改完成後請關閉整個 gedit 程式,否則會占用終端):
sudo apt-get install vim
安裝軟體時若需要確認,在提示處輸入 y 即可。
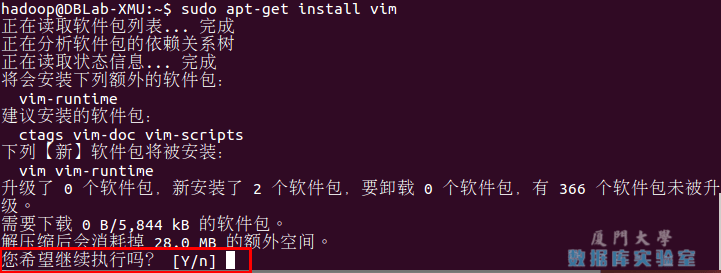 通過命令行安裝軟體
通過命令行安裝軟體
點擊查看:vim簡單操作指南
安裝SSH、配置SSH無密碼登陸
集群、單節點模式都需要用到 SSH 登陸(類似於遠程登陸,你可以登錄某台 Linux 主機,並且在上面運行命令),Ubuntu 預設已安裝了 SSH client,此外還需要安裝 SSH server:
sudo apt-get install openssh-server
安裝後,可以使用如下命令登陸本機:
ssh localhost
此時會有如下提示(SSH首次登陸提示),輸入 yes 。然後按提示輸入密碼 hadoop,這樣就登陸到本機了。
 SSH首次登陸提示
SSH首次登陸提示
但這樣登陸是需要每次輸入密碼的,我們需要配置成SSH無密碼登陸比較方便。
首先退出剛纔的 ssh,就回到了我們原先的終端視窗,然後利用 ssh-keygen 生成密鑰,並將密鑰加入到授權中:
exit # 退出剛纔的 ssh localhostcd ~/.ssh/ # 若沒有該目錄,請先執行一次ssh localhostssh-keygen -t rsa # 會有提示,都按回車就可以cat ./id_rsa.pub >> ./authorized_keys # 加入授權
在 Linux 系統中,~ 代表的是用戶的主文件夾,即 “/home/用戶名” 這個目錄,如你的用戶名為 hadoop,則 ~ 就代表 “/home/hadoop/”。 此外,命令中的 # 後面的文字是註釋,只需要輸入前面命令即可。
此時再用 ssh localhost 命令,無需輸入密碼就可以直接登陸了,如下圖所示。
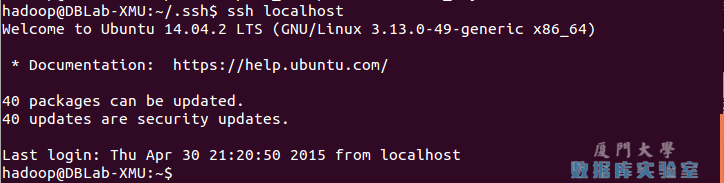 SSH無密碼登錄
SSH無密碼登錄
安裝Java環境
Java環境可選擇 Oracle 的 JDK,或是 OpenJDK,按http://wiki.apache.org/hadoop/HadoopJavaVersions中說的,新版本在 OpenJDK 1.7 下是沒問題的。為圖方便,這邊直接通過命令安裝 OpenJDK 7。
sudo apt-get install openjdk-7-jre openjdk-7-jdk
通過上述命令安裝 OpenJDK,預設安裝位置為 /usr/lib/jvm/java-7-openjdk-amd64(32位系統則是 /usr/lib/jvm/java-7-openjdk-i386,該路徑可以通過執行 dpkg -L openjdk-7-jdk | grep '/bin/javac' 命令確定,執行後會輸出一個路徑,除去路徑末尾的 “/bin/javac”,剩下的就是正確的路徑了)。OpenJDK 安裝後就可以直接使用 java、javac 等命令了。
接著需要配置一下 JAVA_HOME 環境變數,為方便,我們在 ~/.bashrc 中進行設置(擴展閱讀: 設置Linux環境變數的方法和區別):
vim ~/.bashrc
在文件最前面添加如下單獨一行(註意 = 號前後不能有空格),並保存:
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
如下圖所示(該文件原本可能不存在,內容為空,這不影響):
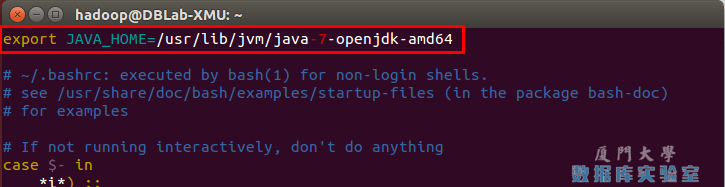 配置JAVA_HOME變數
配置JAVA_HOME變數
接著還需要讓該環境變數生效,執行如下代碼:
source ~/.bashrc # 使變數設置生效
設置好後我們來檢驗一下是否設置正確:
echo $JAVA_HOME # 檢驗變數值java -version$JAVA_HOME/bin/java -version # 與直接執行 java -version 一樣
如果設置正確的話,$JAVA_HOME/bin/java -version 會輸出 java 的版本信息,且和 java -version 的輸出結果一樣,如下圖所示:
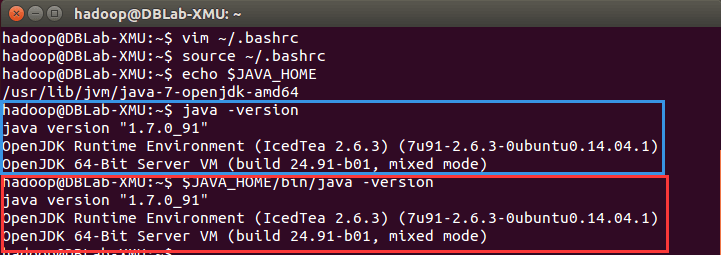 成功配置JAVA_HOME變數
成功配置JAVA_HOME變數
這樣,Hadoop 所需的 Java 運行環境就安裝好了。
安裝 Hadoop 2
Hadoop 2 可以通過 http://mirror.bit.edu.cn/apache/hadoop/common/ 或者http://mirrors.cnnic.cn/apache/hadoop/common/ 下載,本教程選擇的是 2.6.0 版本,下載時請下載 hadoop-2.x.y.tar.gz這個格式的文件,這是編譯好的,另一個包含 src 的則是 Hadoop 源代碼,需要進行編譯才可使用。
截止到2015年12月9日,Hadoop官方網站已經更新到2.7.1版本。對於2.6.0以上版本的Hadoop,仍可以參照此教程學習,可放心下載官網最新版本的Hadoop。請用虛擬機中的Ubuntu自帶firefox瀏覽器訪問本指南,再點擊下麵的地址,才能把hadoop文件下載虛擬機ubuntu中。
下載時強烈建議也下載 hadoop-2.x.y.tar.gz.mds 這個文件,該文件包含了檢驗值可用於檢查 hadoop-2.x.y.tar.gz 的完整性,否則若文件發生了損壞或下載不完整,Hadoop 將無法正常運行。
本文涉及的文件均通過瀏覽器下載,預設保存在 “下載” 目錄中(若不是請自行更改 tar 命令的相應目錄)。另外,如果你用的不是 2.6.0 版本,則將所有命令中出現的 2.6.0 更改為你所使用的版本。
cat ~/下載/hadoop-2.6.0.tar.gz.mds | grep 'MD5' # 列出md5檢驗值# head -n 6 ~/下載/hadoop-2.7.1.tar.gz.mds # 2.7.1版本格式變了,可以用這種方式輸出md5sum ~/下載/hadoop-2.6.0.tar.gz | tr "a-z" "A-Z" # 計算md5值,並轉化為大寫,方便比較
若文件不完整則這兩個值一般差別很大,可以簡單對比下前幾個字元跟後幾個字元是否相等即可,如下圖所示,如果兩個值不一樣,請務必重新下載。
 檢驗文件完整性
檢驗文件完整性
我們選擇將 Hadoop 安裝至 /usr/local/ 中:
sudo tar -zxf ~/下載/hadoop-2.6.0.tar.gz -C /usr/local # 解壓到/usr/local中cd /usr/local/sudo mv ./hadoop-2.6.0/ ./hadoop # 將文件夾名改為hadoopsudo chown -R hadoop:hadoop ./hadoop # 修改文件許可權
Hadoop 解壓後即可使用。輸入如下命令來檢查 Hadoop 是否可用,成功則會顯示 Hadoop 版本信息:
cd /usr/local/hadoop./bin/hadoop version
請務必註意命令中的相對路徑與絕對路徑,本文後續出現的 ./bin/...,./etc/... 等包含 ./ 的路徑,均為相對路徑,以 /usr/local/hadoop 為當前目錄。例如在 /usr/local/hadoop 目錄中執行 ./bin/hadoop version 等同於執行 /usr/local/hadoop/bin/hadoop version。可以將相對路徑改成絕對路徑來執行,但如果你是在主文件夾 ~ 中執行 ./bin/hadoop version,執行的會是 /home/hadoop/bin/hadoop version,就不是我們所想要的了。
Hadoop單機配置(非分散式)
Hadoop 預設模式為非分散式模式,無需進行其他配置即可運行。非分散式即單 Java 進程,方便進行調試。
現在我們可以執行例子來感受下 Hadoop 的運行。Hadoop 附帶了豐富的例子(運行 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar 可以看到所有例子),包括 wordcount、terasort、join、grep 等。
在此我們選擇運行 grep 例子,我們將 input 文件夾中的所有文件作為輸入,篩選當中符合正則表達式 dfs[a-z.]+ 的單詞並統計出現的次數,最後輸出結果到 output 文件夾中。
cd /usr/local/hadoopmkdir ./inputcp ./etc/hadoop/*.xml ./input # 將配置文件作為輸入文件./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'cat ./output/* # 查看運行結果
執行成功後如下所示,輸出了作業的相關信息,輸出的結果是符合正則的單詞 dfsadmin 出現了1次
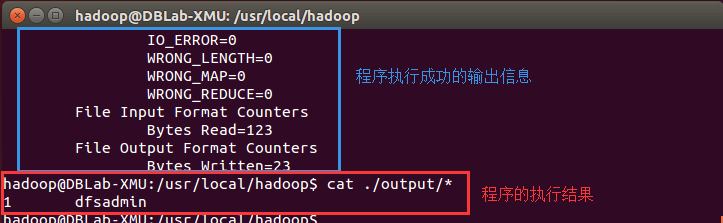 Hadoop單機模式運行grep的輸出結果
Hadoop單機模式運行grep的輸出結果
註意,Hadoop 預設不會覆蓋結果文件,因此再次運行上面實例會提示出錯,需要先將 ./output 刪除。
rm -r ./output
Hadoop偽分散式配置
Hadoop 可以在單節點上以偽分散式的方式運行,Hadoop 進程以分離的 Java 進程來運行,節點既作為 NameNode 也作為 DataNode,同時,讀取的是 HDFS 中的文件。
Hadoop 的配置文件位於 /usr/local/hadoop/etc/hadoop/ 中,偽分散式需要修改2個配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每個配置以聲明 property 的 name 和 value 的方式來實現。
修改配置文件 core-site.xml (通過 gedit 編輯會比較方便: gedit ./etc/hadoop/core-site.xml),將當中的
<configuration>
</configuration>
修改為下麵配置:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
同樣的,修改配置文件 hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
配置完成後,執行 NameNode 的格式化:
./bin/hdfs namenode -format
成功的話,會看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若為 “Exitting with status 1” 則是出錯。
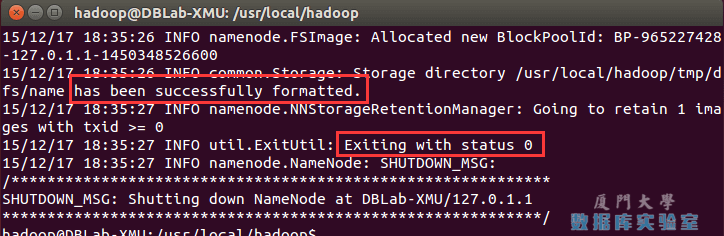 執行namenode格式化
執行namenode格式化
./sbin/start-dfs.sh
若出現如下SSH提示,輸入yes即可。
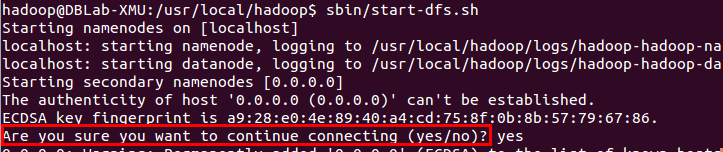 啟動Hadoop時的SSH提示
啟動Hadoop時的SSH提示
啟動時可能會出現如下 WARN 提示:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable WARN 提示可以忽略,並不會影響正常使用。
啟動完成後,可以通過命令 jps 來判斷是否成功啟動,若成功啟動則會列出如下進程: “NameNode”、”DataNode” 和 “SecondaryNameNode”(如果 SecondaryNameNode 沒有啟動,請運行 sbin/stop-dfs.sh 關閉進程,然後再次嘗試啟動嘗試)。如果沒有 NameNode 或 DataNode ,那就是配置不成功,請仔細檢查之前步驟,或通過查看啟動日誌排查原因。
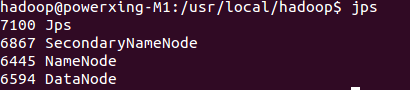 通過jps查看啟動的Hadoop進程
通過jps查看啟動的Hadoop進程
有時 Hadoop 無法正確啟動,如 NameNode 進程沒有順利啟動,這時可以查看啟動日誌來排查原因,註意幾點:
- 啟動時會提示形如 “DBLab-XMU: starting namenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-namenode-DBLab-XMU.out”,其中 DBLab-XMU 對應你的機器名,但其實啟動日誌信息是記錄在 /usr/local/hadoop/logs/hadoop-hadoop-namenode-DBLab-XMU.log 中,所以應該查看這個尾碼為 .log 的文件;
- 每一次的啟動日誌都是追加在日誌文件之後,所以得拉到最後面看,看下記錄的時間就知道了。
- 一般出錯的提示在最後面,通常是寫著 Fatal、Error 或者 Java Exception 的地方。
- 可以在網上搜索一下出錯信息,看能否找到一些相關的解決方法。
成功啟動後,可以訪問 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,還可以線上查看 HDFS 中的文件。
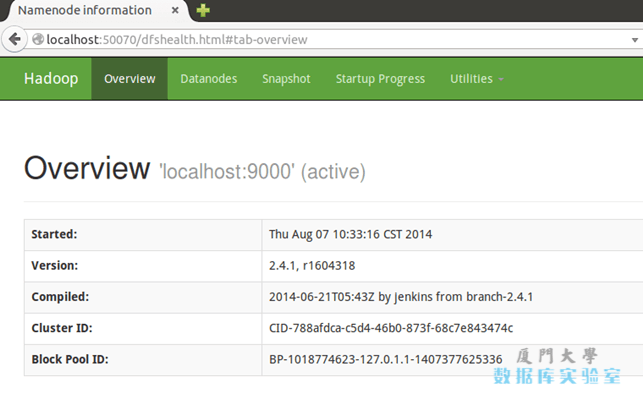 Hadoop的Web界面
Hadoop的Web界面
運行Hadoop偽分散式實例
上面的單機模式,grep 例子讀取的是本地數據,偽分散式讀取的則是 HDFS 上的數據。要使用 HDFS,首先需要在 HDFS 中創建用戶目錄:
./bin/hdfs dfs -mkdir -p /user/hadoop
接著將 ./etc/hadoop 中的 xml 文件作為輸入文件複製到分散式文件系統中,即將 /usr/local/hadoop/etc/hadoop 複製到分散式文件系統中的 /user/hadoop/input 中。我們使用的是 hadoop 用戶,並且已創建相應的用戶目錄 /user/hadoop ,因此在命令中就可以使用相對路徑如 input,其對應的絕對路徑就是 /user/hadoop/input:
./bin/hdfs dfs -mkdir input./bin/hdfs dfs -put ./etc/hadoop/*.xml input
複製完成後,可以通過如下命令查看文件列表:
./bin/hdfs dfs -ls input
偽分散式運行 MapReduce 作業的方式跟單機模式相同,區別在於偽分散式讀取的是HDFS中的文件(可以將單機步驟中創建的本地 input 文件夾,輸出結果 output 文件夾都刪掉來驗證這一點)。
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
查看運行結果的命令(查看的是位於 HDFS 中的輸出結果):
./bin/hdfs dfs -cat output/*
結果如下,註意到剛纔我們已經更改了配置文件,所以運行結果不同。
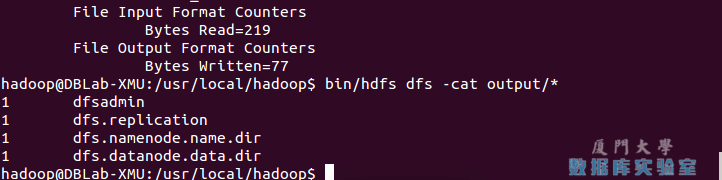 Hadoop偽分散式運行grep結果
Hadoop偽分散式運行grep結果
我們也可以將運行結果取回到本地:
rm -r ./output # 先刪除本地的 output 文件夾(如果存在)./bin/hdfs dfs -get output ./output # 將 HDFS 上的 output 文件夾拷貝到本機cat ./output/*
Hadoop 運行程式時,輸出目錄不能存在,否則會提示錯誤 “org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost:9000/user/hadoop/output already exists” ,因此若要再次執行,需要執行如下命令刪除 output 文件夾:
./bin/hdfs dfs -rm -r output # 刪除 output 文件夾
運行 Hadoop 程式時,為了防止覆蓋結果,程式指定的輸出目錄(如 output)不能存在,否則會提示錯誤,因此運行前需要先刪除輸出目錄。在實際開發應用程式時,可考慮在程式中加上如下代碼,能在每次運行時自動刪除輸出目錄,避免繁瑣的命令行操作:
Configuration conf = new Configuration();Job job = new Job(conf);/* 刪除輸出目錄 */Path outputPath = new Path(args[1]);outputPath.getFileSystem(conf).delete(outputPath, true);
若要關閉 Hadoop,則運行
./sbin/stop-dfs.sh
下次啟動 hadoop 時,無需進行 NameNode 的初始化,只需要運行 ./sbin/start-dfs.sh 就可以!
啟動YARN
(偽分散式不啟動 YARN 也可以,一般不會影響程式執行)
有的讀者可能會疑惑,怎麼啟動 Hadoop 後,見不到書上所說的 JobTracker 和 TaskTracker,這是因為新版的 Hadoop 使用了新的 MapReduce 框架(MapReduce V2,也稱為 YARN,Yet Another Resource Negotiator)。
YARN 是從 MapReduce 中分離出來的,負責資源管理與任務調度。YARN 運行於 MapReduce 之上,提供了高可用性、高擴展性,YARN 的更多介紹在此不展開,有興趣的可查閱相關資料。
上述通過 ./sbin/start-dfs.sh 啟動 Hadoop,僅僅是啟動了 MapReduce 環境,我們可以啟動 YARN ,讓 YARN 來負責資源管理與任務調度。
首先修改配置文件 mapred-site.xml,這邊需要先進行重命名:
mv ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml
然後再進行編輯,同樣使用 gedit 編輯會比較方便些 gedit ./etc/hadoop/mapred-site.xml :
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
接著修改配置文件 yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
然後就可以啟動 YARN 了(需要先執行過 ./sbin/start-dfs.sh):
./sbin/start-yarn.sh $ 啟動YARN./sbin/mr-jobhistory-daemon.sh start historyserver # 開啟歷史伺服器,才能在Web中查看任務運行情況
開啟後通過 jps 查看,可以看到多了 NodeManager 和 ResourceManager 兩個後臺進程,如下圖所示。
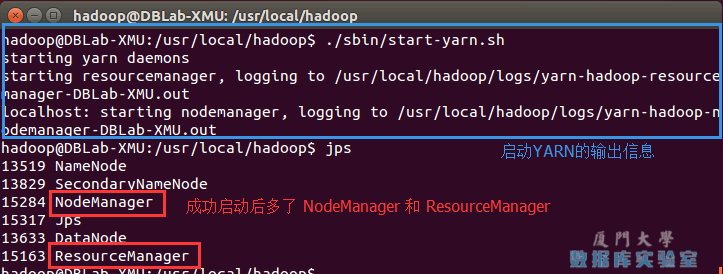 開啟YARN
開啟YARN
啟動 YARN 之後,運行實例的方法還是一樣的,僅僅是資源管理方式、任務調度不同。觀察日誌信息可以發現,不啟用 YARN 時,是 “mapred.LocalJobRunner” 在跑任務,啟用 YARN 之後,是 “mapred.YARNRunner” 在跑任務。啟動 YARN 有個好處是可以通過 Web 界面查看任務的運行情況:http://localhost:8088/cluster,如下圖所示。
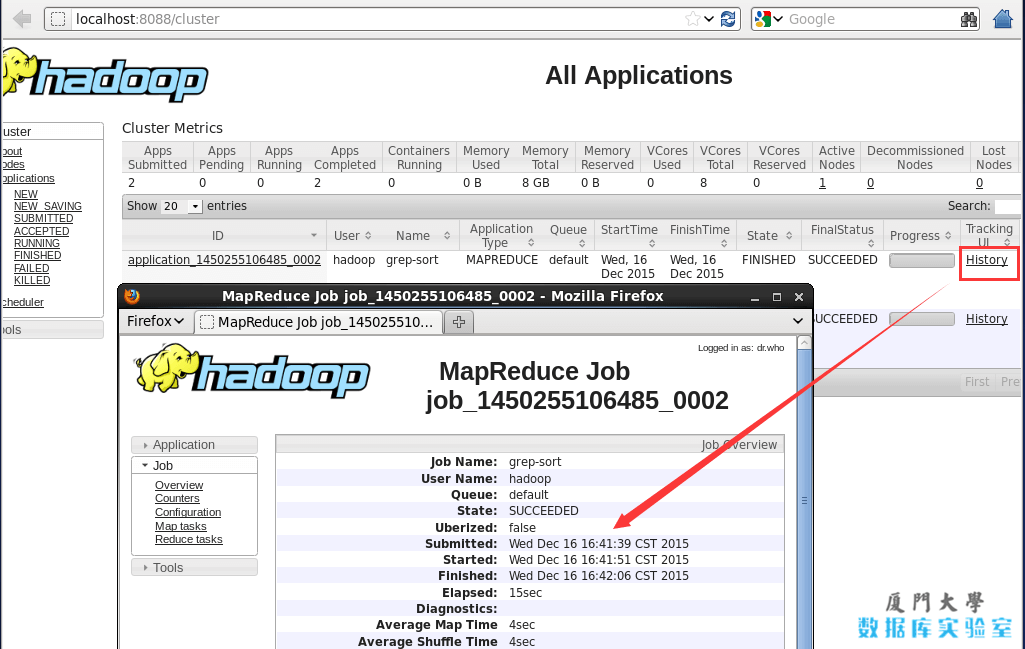 開啟YARN後可以查看任務運行信息
開啟YARN後可以查看任務運行信息
但 YARN 主要是為集群提供更好的資源管理與任務調度,然而這在單機上體現不出價值,反而會使程式跑得稍慢些。因此在單機上是否開啟 YARN 就看實際情況了。
不啟動 YARN 需重命名 mapred-site.xml如果不想啟動 YARN,務必把配置文件 mapred-site.xml 重命名,改成 mapred-site.xml.template,需要用時改回來就行。否則在該配置文件存在,而未開啟 YARN 的情況下,運行程式會提示 “Retrying connect to server: 0.0.0.0/0.0.0.0:8032” 的錯誤,這也是為何該配置文件初始文件名為 mapred-site.xml.template。
同樣的,關閉 YARN 的腳本如下:
./sbin/stop-yarn.sh./sbin/mr-jobhistory-daemon.sh stop historyserver
自此,你已經掌握 Hadoop 的配置和基本使用了。安裝好的Hadoop項目中已經包含了第三章的HDFS,繼續學習第3章HDFS文件系統,請參考如下學習指南:
大數據技術原理與應用 第三章 學習指南
附加教程: 配置PATH環境變數
在這裡額外講一下 PATH 這個環境變數(可執行 echo $PATH 查看,當中包含了多個目錄)。例如我們在主文件夾 ~ 中執行 ls 這個命令時,實際執行的是 /bin/ls 這個程式,而不是 ~/ls 這個程式。系統是根據 PATH 這個環境變數中包含的目錄位置,逐一進行查找,直至在這些目錄位置下找到匹配的程式(若沒有匹配的則提示該命令不存在)。
上面的教程中,我們都是先進入到 /usr/local/hadoop 目錄中,再執行 sbin/hadoop,實際上等同於運行/usr/local/hadoop/sbin/hadoop。我們可以將 Hadoop 命令的相關目錄加入到 PATH 環境變數中,這樣就可以直接通過 start-dfs.sh 開啟 Hadoop,也可以直接通過 hdfs 訪問 HDFS 的內容,方便平時的操作。
同樣我們選擇在 ~/.bashrc 中進行設置(vim ~/.bashrc,與 JAVA_HOME 的設置相似),在文件最前面加入如下單獨一行:
export PATH=$PATH:/usr/local/hadoop/sbin:/usr/local/hadoop/bin
添加後執行 source ~/.bashrc 使設置生效,生效後,在任意目錄中,都可以直接使用 hdfs 等命令了,讀者不妨現在就執行 hdfs dfs -ls input 查看 HDFS 文件試試看。
安裝Hadoop集群
在平時的學習中,我們使用偽分散式就足夠了。如果需要安裝 Hadoop 集群,請查看Hadoop集群安裝配置教程。
相關教程
- 使用Eclipse編譯運行MapReduce程式: 使用 Eclipse 可以方便的開發、運行 MapReduce 程式,還可以直接管理 HDFS 中的文件。
- 使用命令行編譯打包運行自己的MapReduce程式: 有時候需要直接通過命令來編譯、打包 MapReduce 程式。
參考資料
- http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
- http://www.cnblogs.com/xia520pi/archive/2012/05/16/2503949.html
- http://www.micmiu.com/bigdata/hadoop/hadoop-2x-ubuntu-build/


