
pip install --upgrade langchain==0.0.279 -i https://pypi.org/simple 1 創建一個LLM 自有算力平臺+開源大模型(需要有龐大的GPU資源)企業自己訓練數據 第三方大模型API(openai/百度文心/阿裡通義千問...)數據無所謂 ...
pip install --upgrade langchain==0.0.279 -i https://pypi.org/simple
1 創建一個LLM
- 自有算力平臺+開源大模型(需要有龐大的GPU資源)企業自己訓練數據
- 第三方大模型API(openai/百度文心/阿裡通義千問...)數據無所謂
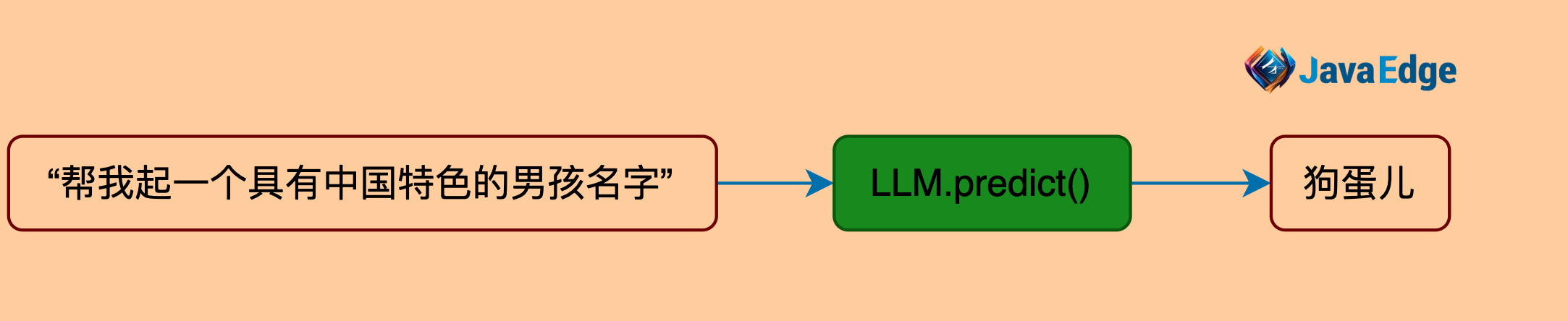
讓LLM給孩子起具有中國特色的名字。
在LangChain中最基本的功能就是根據文本提示來生成新的文本
使用方法:predict
生成結果根據你調用的模型不同而會產生非常不同的結果差距,並且你的模型的tempurature參數也會直接影響最終結果(即LLM的靈敏度)。
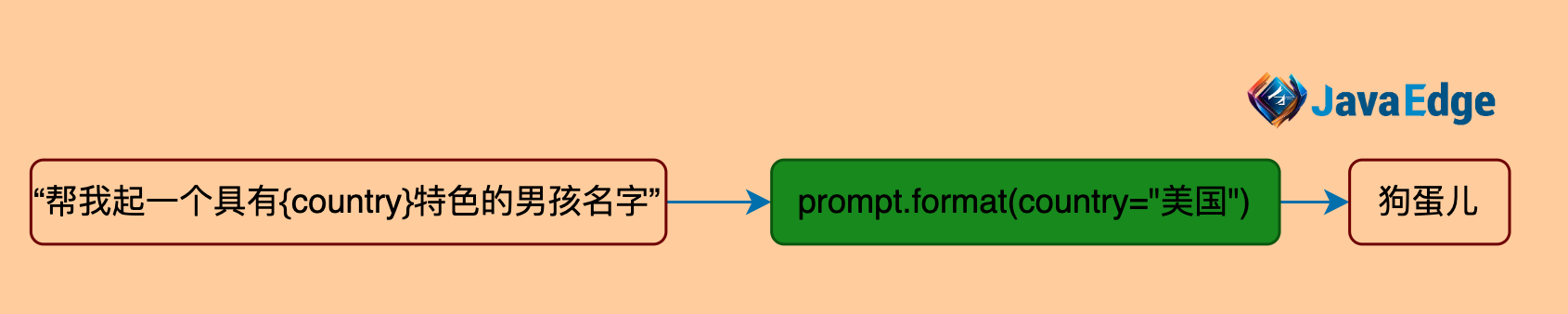
2 自定義提示詞模版
- 將提問的上下文模版化
- 支持參數傳入
讓LLM給孩子起具有美國特色的名字。
將提示詞模版化後會產生很多靈活多變的應用,尤其當它支持參數定義時。
使用方法
langchain.prompts
3 輸出解釋器
- 將LLM輸出的結果各種格式化
- 支持類似json等結構化數據輸出
讓LLM給孩子起4個有中國特色的名字,並以數組格式輸出而不是文本。
與chatGPT只能輸出文本不同,langchain允許用戶自定義輸出解釋器,將生成文本轉化為序列數據使用方法:
langchain.schema
第一個實例
讓LLM以人機對話的形式輸出4個名字
名字和性別可以根據用戶輸出來相應輸出
輸出格式定義為數組
4 開始運行
pip install openai==v0.28.1 -i https://pypi.org/simple
引入openai key
import os
os.environ["OPENAI_KEY"] = "xxxxx"
# 為上網,所以需要添加
os.environ["OPENAI_API_BASE"] = "xxxxx"
從環境變數中讀取:
import os
openai_api_key = os.getenv("OPENAI_KEY")
openai_api_base = os.getenv("OPENAI_API_BASE")
print("OPENAI_API_KEY:", openai_api_key)
print("OPENAI_PROXY:", openai_api_base)
運行前查看下安裝情況
! pip show langchain
! pip show openai
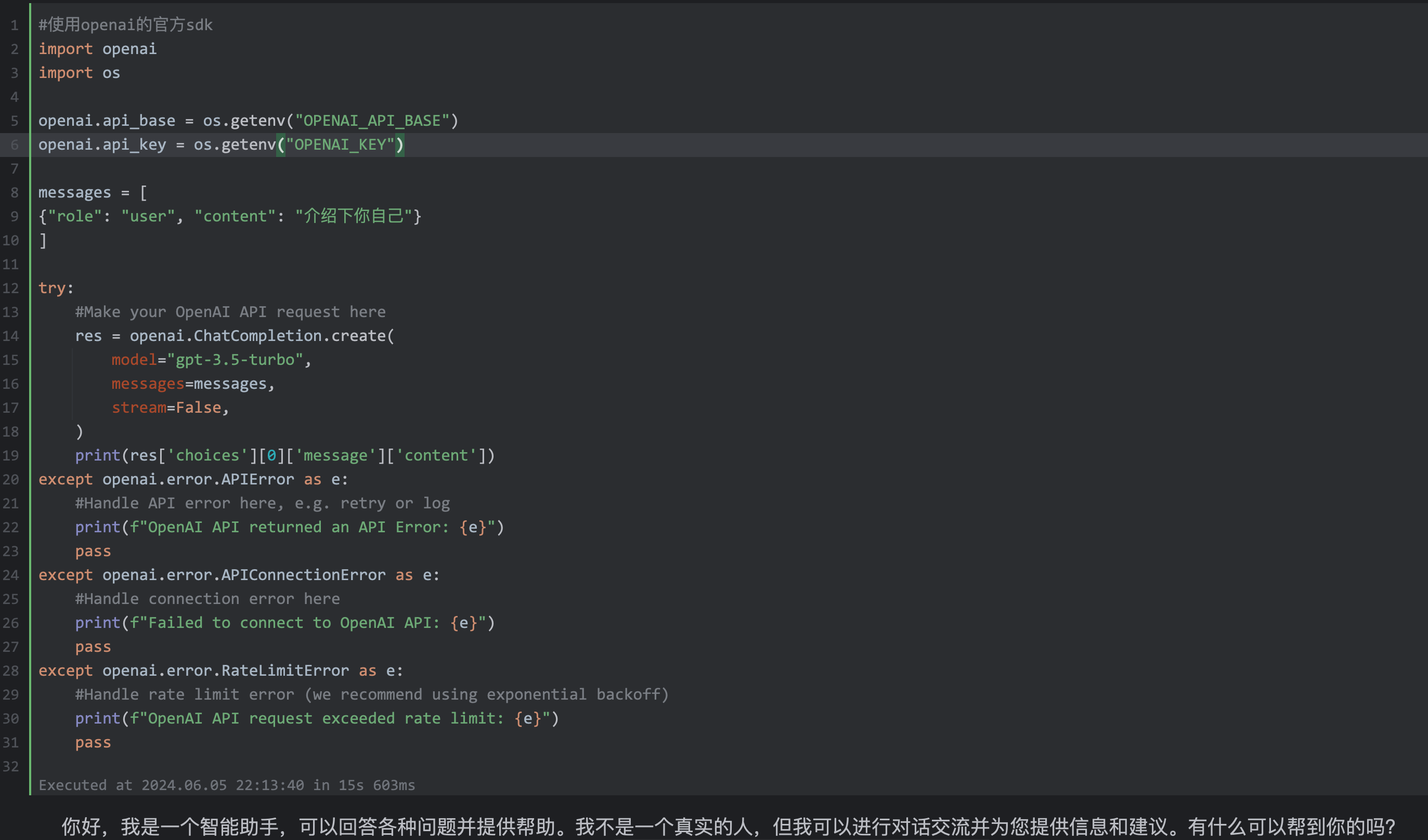
openai 官方SDK
#使用openai的官方sdk
import openai
import os
openai.api_base = os.getenv("OPENAI_API_BASE")
openai.api_key = os.getenv("OPENAI_KEY")
messages = [
{"role": "user", "content": "介紹下你自己"}
]
res = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages,
stream=False,
)
print(res['choices'][0]['message']['content'])
使用langchain調用
#hello world
from langchain.llms import OpenAI
import os
api_base = os.getenv("OPENAI_API_BASE")
api_key = os.getenv("OPENAI_KEY")
llm = OpenAI(
model="gpt-3.5-turbo-instruct",
temperature=0,
openai_api_key=api_key,
openai_api_base=api_base
)
llm.predict("介紹下你自己")
起名大師
#起名大師
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
import os
api_base = os.getenv("OPENAI_API_BASE")
api_key = os.getenv("OPENAI_KEY")
llm = OpenAI(
model="gpt-3.5-turbo-instruct",
temperature=0,
openai_api_key=api_key,
openai_api_base=api_base
)
prompt = PromptTemplate.from_template("你是一個起名大師,請模仿示例起3個{county}名字,比如男孩經常被叫做{boy},女孩經常被叫做{girl}")
message = prompt.format(county="中國特色的",boy="狗蛋",girl="翠花")
print(message)
llm.predict(message)
輸出:
'\n\n男孩: 龍飛、鐵柱、小虎\n女孩: 玉蘭、梅香、小紅梅'
格式化輸出
from langchain.schema import BaseOutputParser
#自定義class,繼承了BaseOutputParser
class CommaSeparatedListOutputParser(BaseOutputParser):
"""Parse the output of an LLM call to a comma-separated list."""
def parse(self, text: str):
"""Parse the output of an LLM call."""
return text.strip().split(", ")
CommaSeparatedListOutputParser().parse("hi, bye")
['hi', 'bye']
完整案例
#起名大師,輸出格式為一個數組
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
import os
from langchain.schema import BaseOutputParser
#自定義類
class CommaSeparatedListOutputParser(BaseOutputParser):
"""Parse the output of an LLM call to a comma-separated list."""
def parse(self, text: str):
"""Parse the output of an LLM call."""
print(text)
return text.strip().split(",")
api_base = os.getenv("OPENAI_API_BASE")
api_key = os.getenv("OPENAI_KEY")
llm = OpenAI(
model="gpt-3.5-turbo-instruct",
temperature=0,
openai_api_key=api_key,
openai_api_base=api_base
)
prompt = PromptTemplate.from_template("你是一個起名大師,請模仿示例起3個具有{county}特色的名字,示例:男孩常用名{boy},女孩常用名{girl}。請返回以逗號分隔的列表形式。僅返回逗號分隔的列表,不要返回其他內容。")
message = prompt.format(county="美國男孩",boy="sam",girl="lucy")
print(message)
strs = llm.predict(message)
CommaSeparatedListOutputParser().parse(strs)
['jack', ' michael', ' jason']
關註我,緊跟本系列專欄文章,咱們下篇再續!
作者簡介:魔都架構師,多家大廠後端一線研發經驗,在分散式系統設計、數據平臺架構和AI應用開發等領域都有豐富實踐經驗。
各大技術社區頭部專家博主。具有豐富的引領團隊經驗,深厚業務架構和解決方案的積累。
負責:
- 中央/分銷預訂系統性能優化
- 活動&券等營銷中台建設
- 交易平臺及數據中台等架構和開發設計
- 車聯網核心平臺-物聯網連接平臺、大數據平臺架構設計及優化
- LLM應用開發
目前主攻降低軟體複雜性設計、構建高可用系統方向。
參考:
本文由博客一文多發平臺 OpenWrite 發佈!


