
1 開源解析和拆分文檔 第三方工具去對文件解析拆分,將文件內容給提取出來,並將我們的文檔內容去拆分成一個小的chunk。常見的PDF word mark down, JSON、HTML。都可以有很好的一些模塊去把這些文件去進行一個東西去提取。 1.1 優勢 支持豐富的文檔類型 每種文檔多樣化選擇 與 ...
1 開源解析和拆分文檔
第三方工具去對文件解析拆分,將文件內容給提取出來,並將我們的文檔內容去拆分成一個小的chunk。常見的PDF word mark down, JSON、HTML。都可以有很好的一些模塊去把這些文件去進行一個東西去提取。
1.1 優勢
- 支持豐富的文檔類型
- 每種文檔多樣化選擇
- 與開源框架無縫集成
但有時效果非常差,來內容跟原始的文件內容差別大。
2 PDF格式多樣性

複雜多變的文檔格式,提高解析效果十分困難。
3 複雜文檔格式解析問題
文檔內容質量將很大程度影響最終效果,文檔處理過程涉及問題:
3.1 內容不完整
對文檔的內容進行提取的時候,可能會發現提取出來的文檔它的內容是會被截斷的。跨頁形式,提取出來它的上下頁其實兩部分內容就會被截斷,導致文檔內部分內容丟失,我們去解析圖片或者是說雙欄複雜的這種格式。它會有一部分內容的丟失。
3.2 內容錯誤
同一頁PDF文件可能存在文本、表格、圖片等混合。
PDF解析過程中,同一頁它不同段落其實會也會有不同標準的一些格式。按通用格式去提取解析就遇到同頁不同段落格式不標準情況。
3.3 文檔格式
像常見PDF md文件,需要去支持把這些各類型的文檔格式的文件都給提取。
3,4 邊界場景
代碼塊還有單元格這些,都是我們去去解析一個複雜文檔格式中會遇到一些問題。
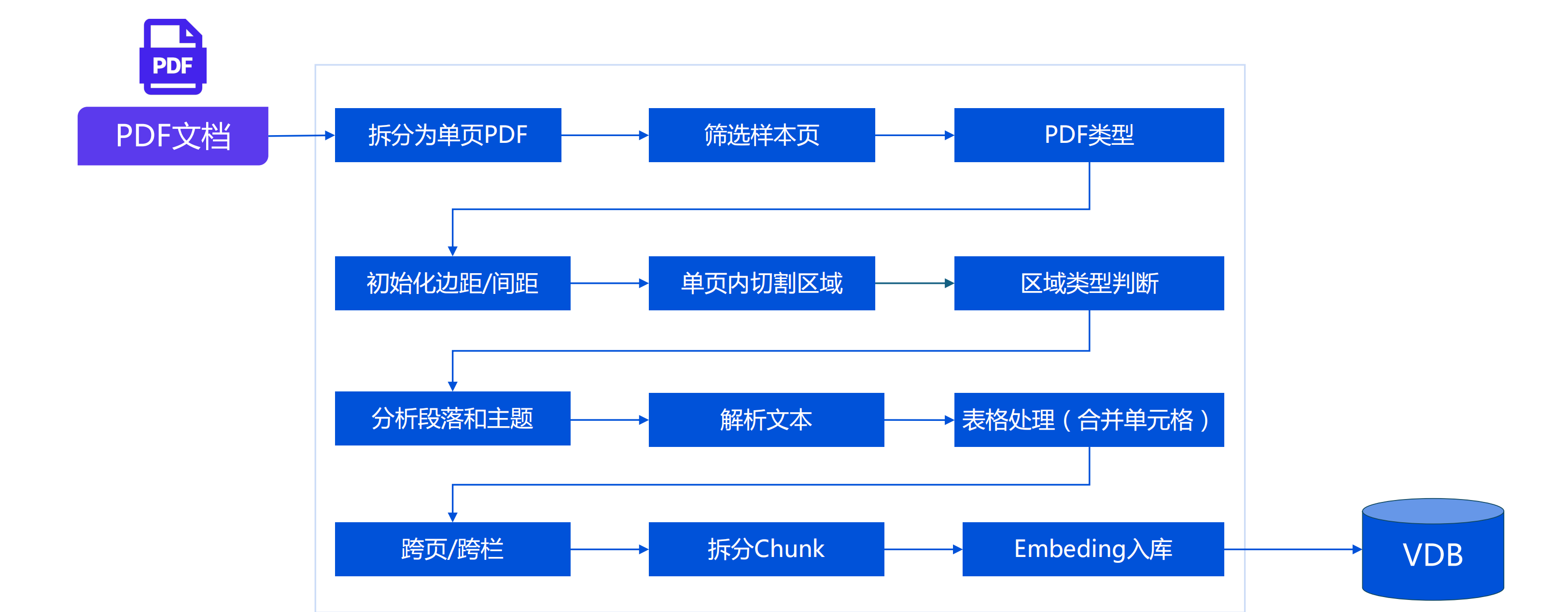
4 PDF內容提取流程
5 為啥解析文檔後需要做知識片段拆分?
5.1 Token限制
- 絕大部分開源限制 <= 512 Tokens
- bge_base、e5_large、m3e_base、text2vector_large_chinese、multilingnal-e5-base..
5.2 效果影響
- 召回效果:有限向量維度下表達較多的文檔信息易產生失真
- 回答效果:召回內容中包含與問題無關信息對LLM增加干擾
5.3 成本控制
- LLM費用:按照Token計費
- 網路費用:按照流量計費
6 Chunk拆分對最終效果的影響
Chunk太長
信息壓縮失真
Chunk太短
表達缺失上下文;匹配分數容易變高
Chunk跨主題
內容關係脫節
原文連續內容(含表格)被截斷
單個Chunk信息表達不完整,或含義相反
干擾信息
如空白、HTML、XML等格式,同等長度下減少有效信息、增加干擾信息
主題和關係丟失
缺失了主題和知識點之間的關係
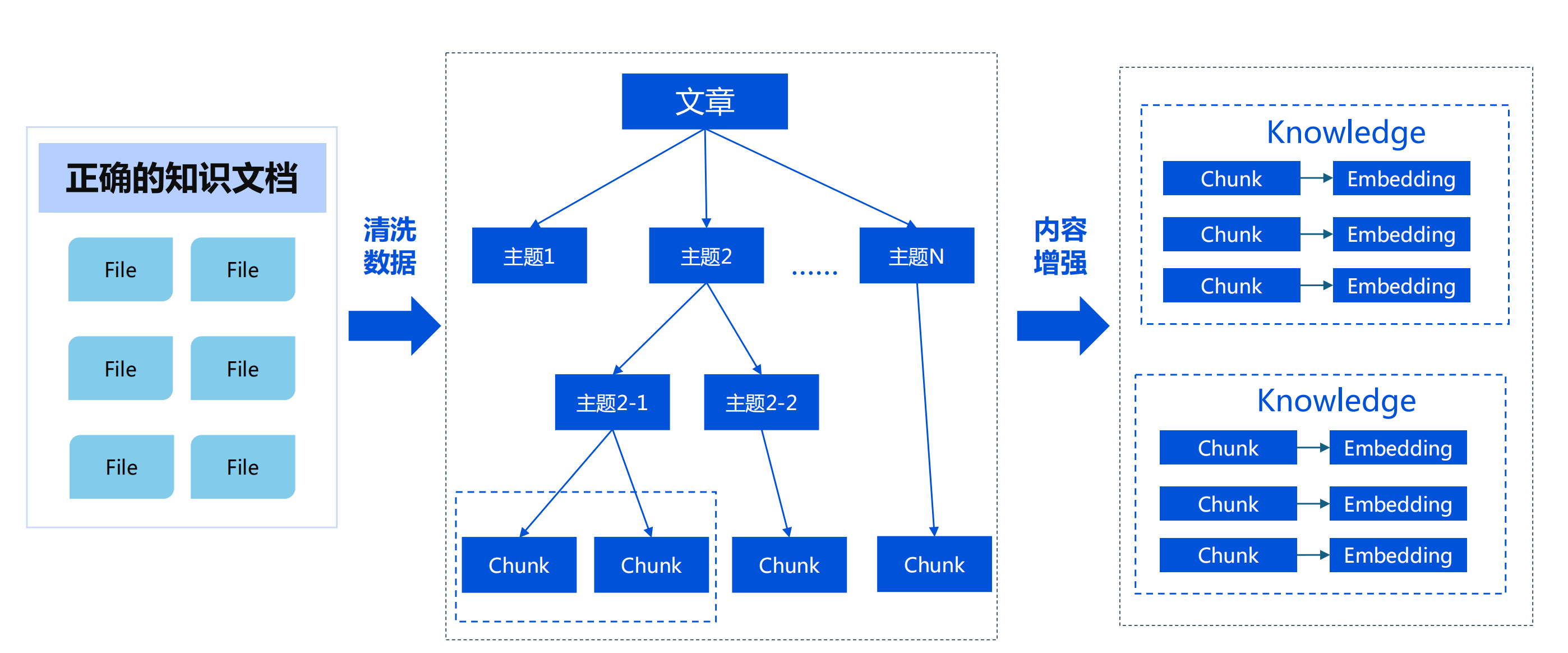
7 改進知識的拆分方案
關註我,緊跟本系列專欄文章,咱們下篇再續!
作者簡介:魔都架構師,多家大廠後端一線研發經驗,在分散式系統設計、數據平臺架構和AI應用開發等領域都有豐富實踐經驗。
各大技術社區頭部專家博主。具有豐富的引領團隊經驗,深厚業務架構和解決方案的積累。
負責:
- 中央/分銷預訂系統性能優化
- 活動&券等營銷中台建設
- 交易平臺及數據中台等架構和開發設計
- 車聯網核心平臺-物聯網連接平臺、大數據平臺架構設計及優化
- LLM應用開發
目前主攻降低軟體複雜性設計、構建高可用系統方向。
參考:
本文由博客一文多發平臺 OpenWrite 發佈!


