
一、背景介紹 1.1 爬取目標 用python開發的爬蟲採集軟體,可自動按指定博主抓取該博主已發佈筆記。 為什麼有了源碼還開發界面軟體呢?方便不懂編程代碼的小白用戶使用,無需安裝python,無需改代碼,雙擊打開即用! 軟體界面截圖: 爬取結果截圖: 結果截圖1: 結果截圖2: 結果截圖3: 以上。 ...
一、背景介紹
1.1 爬取目標
用python開發的爬蟲採集軟體,可自動按指定博主抓取該博主已發佈筆記。
為什麼有了源碼還開發界面軟體呢?方便不懂編程代碼的小白用戶使用,無需安裝python,無需改代碼,雙擊打開即用!
軟體界面截圖:
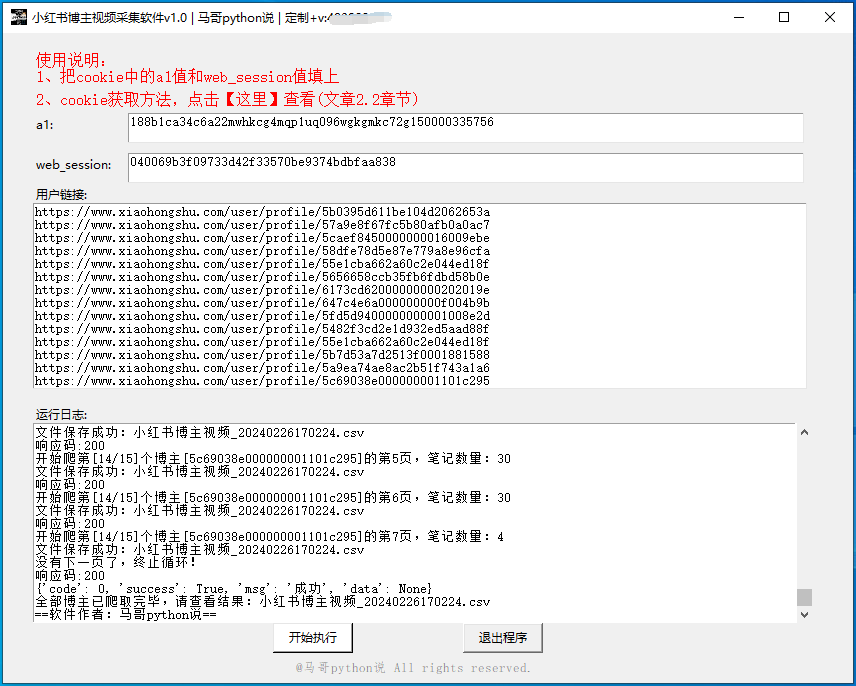
爬取結果截圖:
結果截圖1:
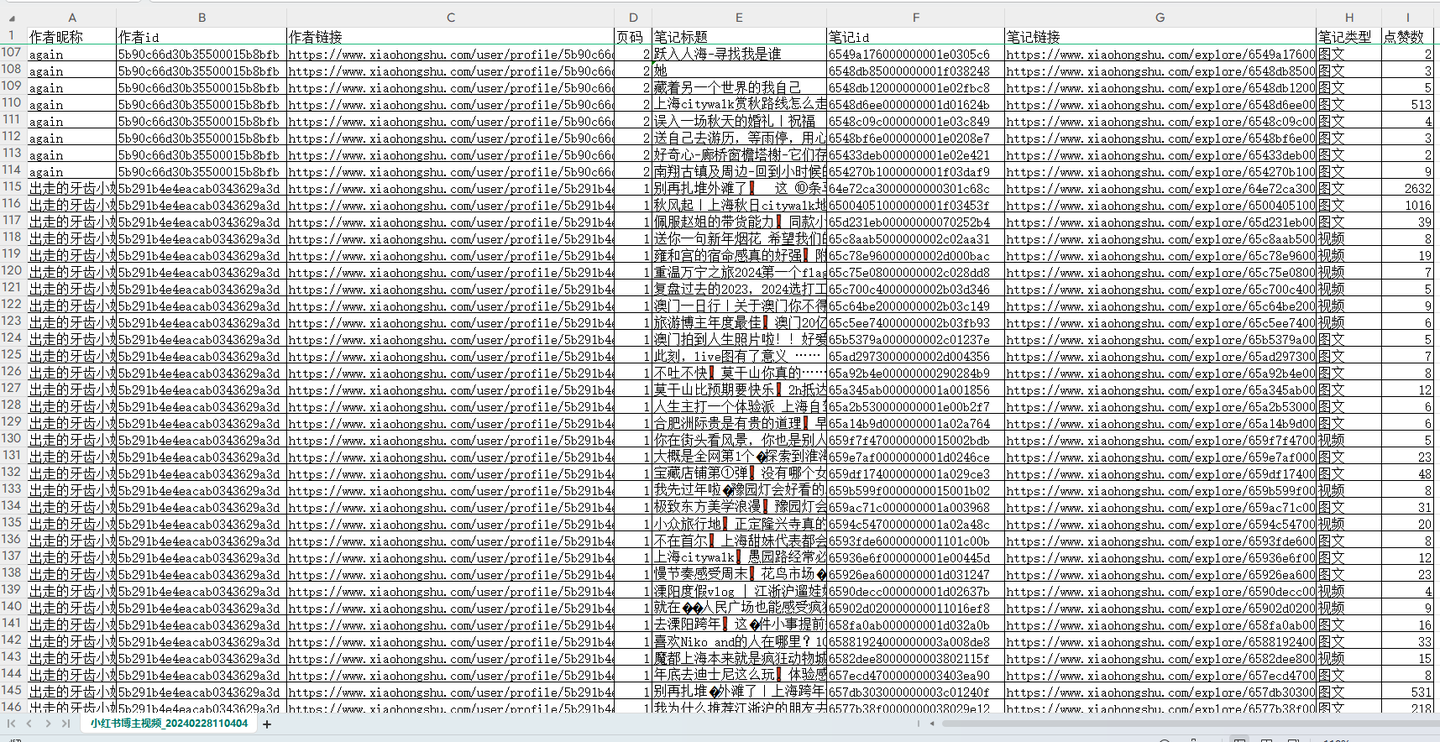
結果截圖2:

結果截圖3:
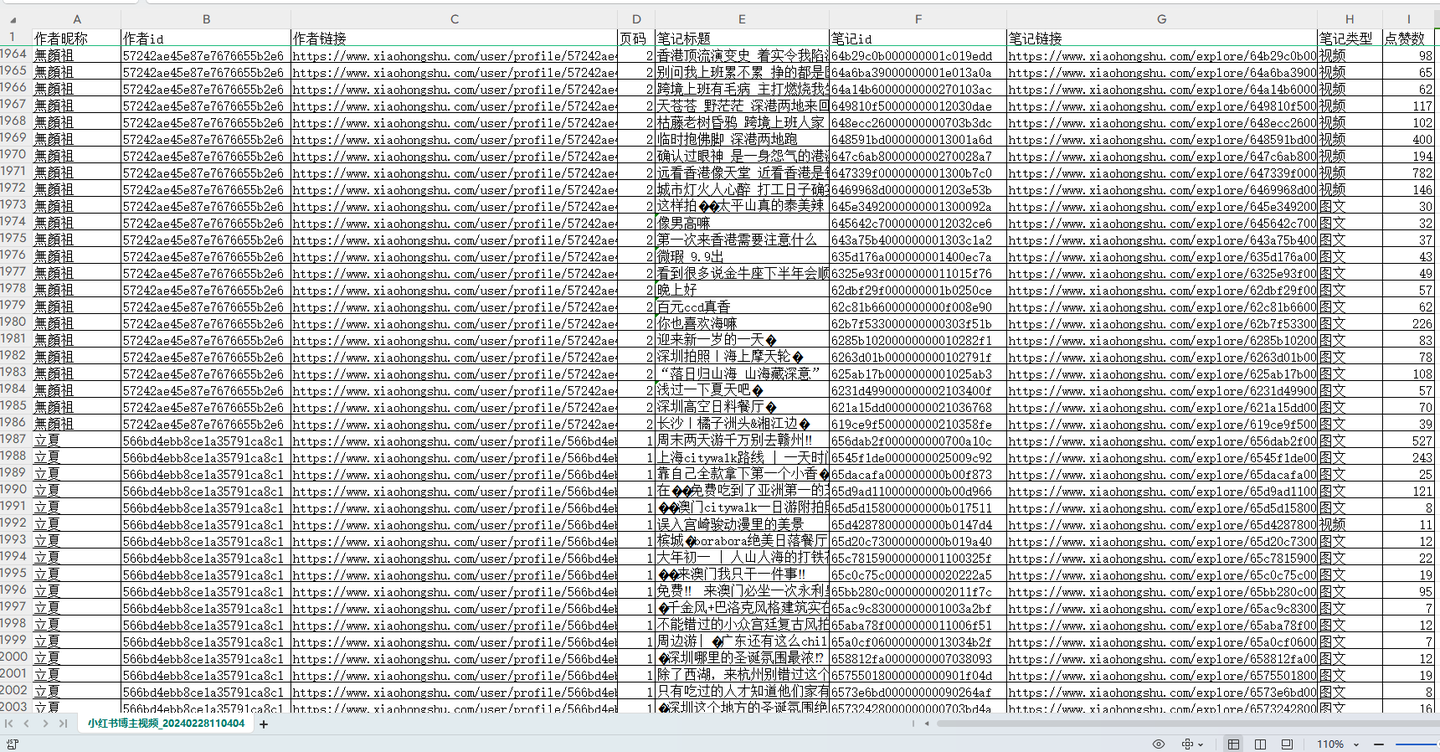
以上。
1.2 演示視頻
軟體使用演示:
見原文
1.3 軟體說明
幾點重要說明:
以上。
二、代碼講解
2.1 爬蟲採集模塊
首先,定義介面地址作為請求地址:
# 請求地址
posted_url = 'https://edith.xiaohongshu.com/api/sns/web/v1/user_posted'
定義一個請求頭,用於偽造瀏覽器:
# 請求頭
h1 = {
"Content-Type": "application/json; charset=utf-8",
"Accept": "application/json, text/plain, */*",
"Accept-Language": "zh-CN,zh;q=0.9",
"Origin": "https://www.xiaohongshu.com",
"Referer": "https://www.xiaohongshu.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Connection": "keep-alive",
"Cookie": "gid=yYDqDJSjjy7dyYDqDJSqDv8iydu4WMhDIKxCvVfJJ3FkTJq836EFDT888jyKJK28id4dYD42; sec_poison_id=9473b193-aa0e-436e-848a-c53f539ae316; webBuild=4.2.1; websectiga=f47eda31ec99545da40c2f731f0630efd2b0959e1dd10d5fedac3dce0bd1e04d; xsecappid=xhs-pc-web; web_session={}; customer-sso-sid=65a493817900000000000011; x-user-id-pgy.xiaohongshu.com=642651810000000011022ed2; customerClientId=171221914380812; a1={}; webId=e9a9990ce615eec84d0fd8a2f4e9e29d; abRequestId=7c4f00be-699b-57f5-81c9-2783ff470960".format(
self.web_session, self.a1),
}
說明一下,cookie是個關鍵參數。
其中,cookie里的a1和web_session獲取方法,如下:
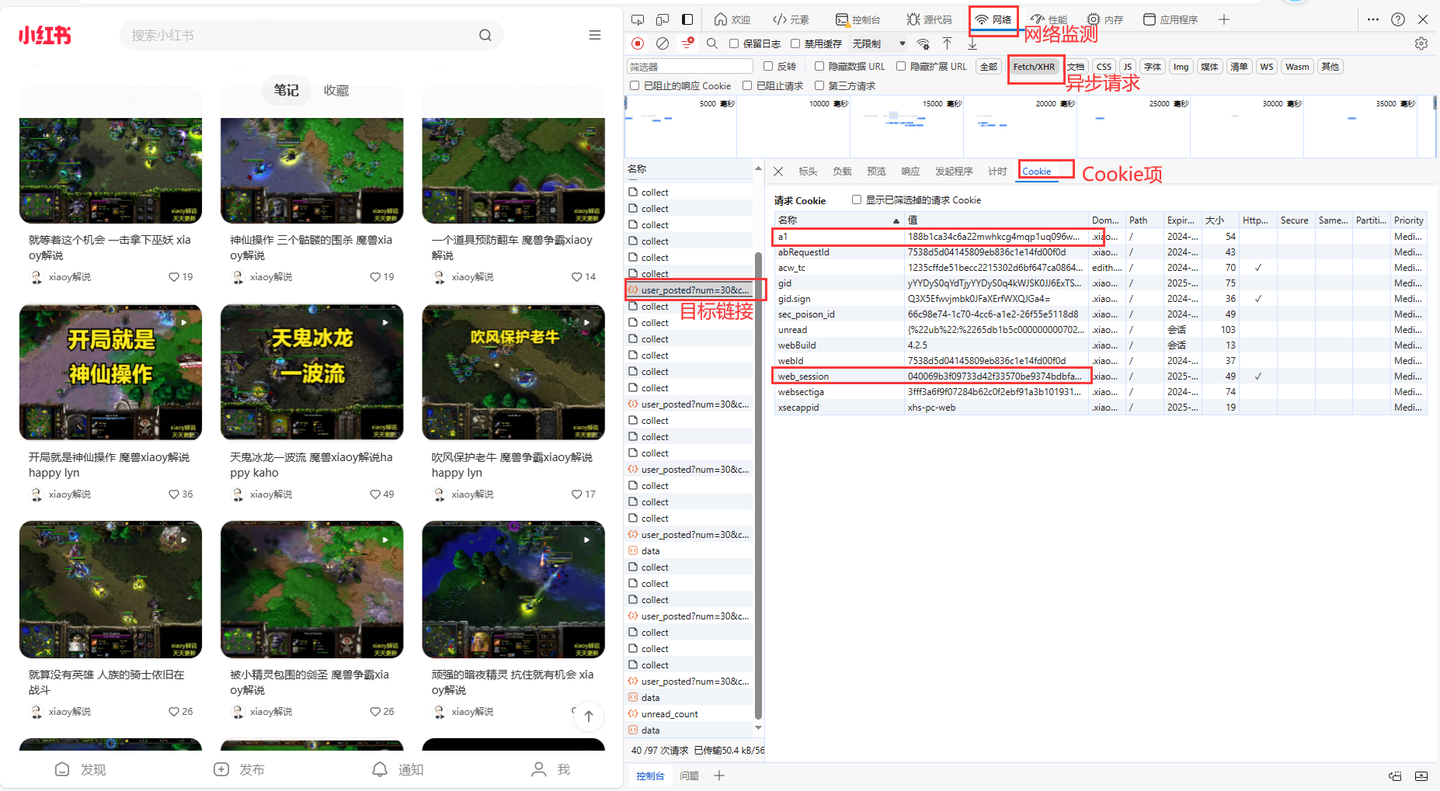
這兩個值非常重要,軟體界面需要填寫!!
加上請求參數,告訴程式你的爬取條件是什麼:
# 請求參數
params = {
"num": 30,
"cursor": next_cursor,
"user_id": user_id,
"image_scenes": ""
}
下麵就是發送請求和接收數據:
# 發送請求
r = requests.post(posted_url, headers=h1, params=params)
# 接收數據
json_data = r.json()
逐個解析欄位數據,以"筆記標題"為例:
# 筆記標題
title = i['display_title']
title_list.append(title)
其他欄位同理,不再贅述。
保存數據到Dataframe中:
# 保存數據到DF
df = pd.DataFrame(
{
'作者昵稱': author_name_list,
'作者id': author_id_list,
'作者鏈接': ['https://www.xiaohongshu.com/user/profile/' + str(i) for i in author_id_list],
'頁碼': page,
'筆記標題': title_list,
'筆記id': note_id_list,
'筆記鏈接': note_url_list,
'筆記類型': note_type_list,
'點贊數': likes_list,
}
)
最後,再把數據保存到csv文件:
# 設置csv文件表頭
if os.path.exists(self.result_file):
header = False
else:
header = True
# 保存到csv
df.to_csv(self.result_file, mode='a+', header=header, index=False, encoding='utf_8_sig')
self.tk_show('文件保存成功:' + self.result_file)
完整代碼中,還含有:判斷迴圈結束條件、轉換時間戳、js逆向解密等關鍵實現邏輯,詳見文末。
2.2 軟體界面模塊
主視窗部分:
# 創建主視窗
root = tk.Tk()
root.title('小紅書博主筆記採集軟體v1.0 | 馬哥python說 |')
# 設置視窗大小
root.minsize(width=850, height=650)
輸入控制項部分:
# a1填寫
tk.Label(root, justify='left', text='a1:').place(x=30, y=80)
entry_a1 = tk.Text(root, bg='#ffffff', width=96, height=2, )
entry_a1.place(x=125, y=80, anchor='nw') # 擺放位置
# web_session填寫
tk.Label(root, justify='left', text='web_session:').place(x=30, y=120)
entry_web_session = tk.Text(root, bg='#ffffff', width=96, height=2, )
entry_web_session.place(x=125, y=120, anchor='nw') # 擺放位置
底部版權部分:
# 版權信息
copyright = tk.Label(root, text='@馬哥python說 All rights reserved.', font=('仿宋', 10), fg='grey')
copyright.place(x=290, y=625)
以上。
2.3 日誌模塊
好的日誌功能,方便軟體運行出問題後快速定位原因,修複bug。
核心代碼:
def get_logger(self):
self.logger = logging.getLogger(__name__)
# 日誌格式
formatter = '[%(asctime)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s'
# 日誌級別
self.logger.setLevel(logging.DEBUG)
# 控制台日誌
sh = logging.StreamHandler()
log_formatter = logging.Formatter(formatter, datefmt='%Y-%m-%d %H:%M:%S')
# info日誌文件名
info_file_name = time.strftime("%Y-%m-%d") + '.log'
# 將其保存到特定目錄
case_dir = r'./logs/'
info_handler = TimedRotatingFileHandler(filename=case_dir + info_file_name,
when='MIDNIGHT',
interval=1,
backupCount=7,
encoding='utf-8')
日誌文件截圖:
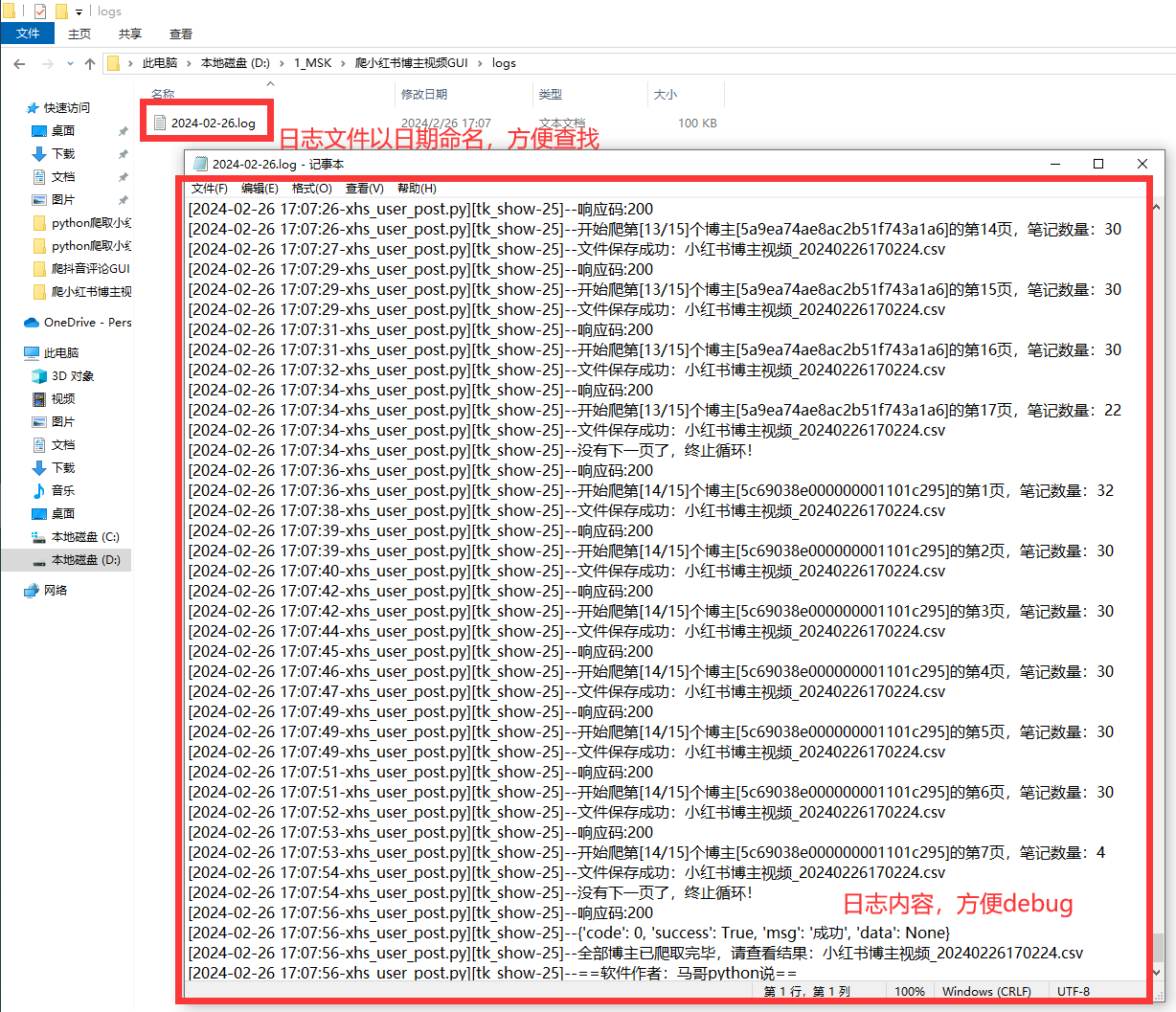
以上。
三、轉載聲明
轉載已獲原作者 @馬哥python說 授權:
博客園原文鏈接: 【GUI軟體】小紅書指定博主批量採集筆記,支持多博主同時採集!


