
《最少必要面試題》第一版 相信大家都會有種及眼熟又陌生的感覺、看過可能在短暫的面試後又馬上忘記了。JavaPub 在這裡整理這些容易忘記的重點知識及 解答,建議收藏,經常溫習查閱。 點擊線上閱讀《最少必要面試題》 更多 作者:JavaPub2024 目錄緩存1. 什麼是緩存?2. 為什麼要用緩存?3 ...
《最少必要面試題》第一版
相信大家都會有種及眼熟又陌生的感覺、看過可能在短暫的面試後又馬上忘記了。JavaPub 在這裡整理這些容易忘記的重點知識及 解答,建議收藏,經常溫習查閱。
2024
- 緩存
- Docker
- ElasticSearch
- 1. 說說你們公司 es 的集群架構,索引數據大小,分片有多少,以及一些調優手段 。
- 2. elasticsearch 的倒排索引是什麼
- 3. elasticsearch 是如何實現 master 選舉的
- 5. 描述一下 Elasticsearch 索引文檔的過程
- 4. 詳細描述一下 Elasticsearch 搜索的過程?
- 5. Elasticsearch 在部署時,對 Linux 的設置有哪些優化方法
- 6. Elasticsearch 中的節點(比如共 20 個),其中的 10 個選了一個 master,另外 10 個選了另一個 master,怎麼辦?
- 7. 客戶端在和集群連接時,如何選擇特定的節點執行請求的?
- 8. 詳細描述一下 Elasticsearch 更新和刪除文檔的過程。
- 9. Elasticsearch 對於大數據量(上億量級)的聚合如何實現?
- 10. 在併發情況下,Elasticsearch 如果保證讀寫一致?
- 11. 介紹一下你們的個性化搜索方案?
- Java基礎
- Java併發
- Java 容器
- 1. 請說一下Java容器集合的分類,各自的繼承結構
- 2. Collection 和 Collections 有什麼區別?
- 3. List、Set、Map 之間的區別是什麼?
- 4. HashMap 和 Hashtable 有什麼區別?
- 5. 說一下 HashMap 的實現原理?
- 6. 談談 ArrayList 和 LinkedList 的區別
- 7. 談談ArrayList和Vector的區別
- 8. 請談一談 Java 集合中的 fail-fast 和 fail-safe 機制
- 9. HashMap是怎樣確定key存放在數組的哪個位置的?JDK1.8
- 10. 為什麼要把鏈表轉為紅黑樹,閾值為什麼是8?
- 拓展題. 為什麼 HashMap 數組的長度是2的冪次方?
- JavaEE
- JVM
- Kafka
- 術語0. Kafka中的ISR、AR又代表什麼?ISR的伸縮又指什麼
- 術語0. Kafka中的HW、LEO、LSO、LW等分別代表什麼?
- MyBatis
- {id} —> 10,相對於當前上下文對象.getId(),即 student.getId() 。
- {name} —> 小明。
- {course.score} —> 88,相當於 student.getCourse().getScore()。
緩存
1. 什麼是緩存?
緩存,就是數據交換的緩衝區,針對服務對象的不同(本質就是不同的硬體)都可以構建緩存。而我們平時說的緩存,大多是指記憶體。
目的是, 把讀寫速度【慢】的介質的數據保存在讀寫速度【快】的介質中,從而提高讀寫速度,減少時間消耗。 例如:
- CPU 高速緩存 :高速緩存的讀寫速度遠高於記憶體。
- CPU 讀數據時,如果在高速緩存中找到所需數據,就不需要讀記憶體
- CPU 寫數據時,先寫到高速緩存,再回寫到記憶體。
- 磁碟緩存:磁碟緩存其實就把常用的磁碟數據保存在記憶體中,記憶體讀寫速度也是遠高於磁碟的。
- 讀數據,時從記憶體讀取。
- 寫數據時,可先寫到記憶體,定時或定量回寫到磁碟,或者是同步回寫。
2. 為什麼要用緩存?
使用緩存的目的,就是提升讀寫性能。而實際業務場景下,更多的是為了提升讀性能,帶來更好的性能,更高的併發量。
日常業務中,我們使用比較多的資料庫是 MySQL ,緩存是 Redis 。Redis 比 MySQL 的讀寫性能好很多。那麼,我們將 MySQL 的熱點數據,緩存到 Redis 中,提升讀取性能,也減小 MySQL 的讀取壓力。例如說:
- 論壇帖子的訪問頻率比較高,且要實時更新閱讀量,使用 Redis 記錄帖子的閱讀量,可以提升性能和併發。
- 商品信息,數據更新的頻率不高,但是讀取的頻率很高,特別是熱門商品。
3. 請說說有哪些緩存演算法?是否能手寫一下 LRU 代碼的實現?
緩存演算法,比較常見的是三種:
- LRU(least recently used ,最近最少使用)
- LFU(Least Frequently used ,最不經常使用)
- FIFO(first in first out ,先進先出)
這裡我們可以藉助 LinkedHashMap 實現
public class LRULinkedMap<K,V> {
/**
* 最大緩存大小
*/
private int cacheSize;
private LinkedHashMap<K,V> cacheMap ;
public LRULinkedMap(int cacheSize) {
this.cacheSize = cacheSize;
cacheMap = new LinkedHashMap(16,0.75F,true){
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
if (cacheSize + 1 == cacheMap.size()){
return true ;
}else {
return false ;
}
}
};
}
public void put(K key,V value){
cacheMap.put(key,value) ;
}
public V get(K key){
return cacheMap.get(key) ;
}
public Collection<Map.Entry<K, V>> getAll() {
return new ArrayList<Map.Entry<K, V>>(cacheMap.entrySet());
}
}
使用案例:
@Test
public void put() throws Exception {
LRULinkedMap<String,Integer> map = new LRULinkedMap(3) ;
map.put("1",1);
map.put("2",2);
map.put("3",3);
for (Map.Entry<String, Integer> e : map.getAll()){
System.out.print(e.getKey() + " : " + e.getValue() + "\t");
}
System.out.println("");
map.put("4",4);
for (Map.Entry<String, Integer> e : map.getAll()){
System.out.print(e.getKey() + " : " + e.getValue() + "\t");
}
}
//輸出
1 : 1 2 : 2 3 : 3
2 : 2 3 : 3 4 : 4
4. 常見的常見的緩存工具和框架有哪些?
在 Java 後端開發中,常見的緩存工具和框架列舉如下:
-
本地緩存:Guava LocalCache、Ehcache、Caffeine 。
Ehcache 的功能更加豐富,Caffeine 的性能要比 Guava LocalCache 好。
-
分散式緩存:Redis、Memcached、Tair 。
Redis 最為主流和常用。
5. 用了緩存之後,有哪些常見問題?
常見的問題,可列舉如下:
寫入問題
- 緩存何時寫入?並且寫時如何避免併發重覆寫入?
- 緩存如何失效?
- 緩存和 DB 的一致性如何保證?
經典三連問
- 如何避免緩存穿透的問題?
- 如何避免緩存擊穿的問題?
- 如果避免緩存雪崩的問題?
6. 如何處理緩存穿透的問題
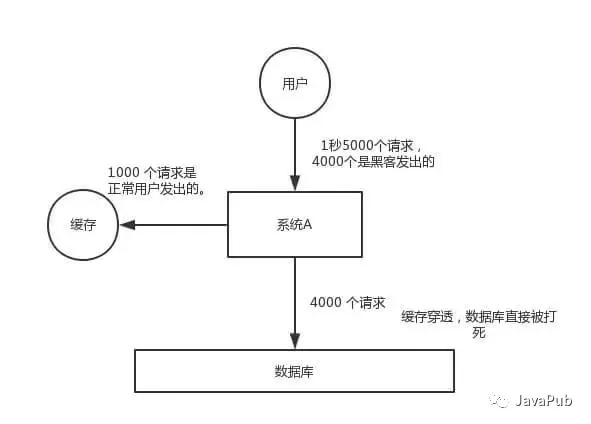
緩存穿透,是指查詢一個一定不存在的數據,由於緩存是不命中時被動寫,並且處於容錯考慮,如果從 DB 查不到數據則不寫入緩存,這將導致這個不存在的數據每次請求都要到 DB 去查詢,失去了緩存的意義。
在流量大時,可能 DB 就掛掉了,要是有人利用不存在的 key 頻繁攻擊我們的應用,這就是漏洞。如下圖:
如何解決
有兩種方案可以解決:
-
方案一,緩存空對象。
當從 DB 查詢數據為空,我們仍然將這個空結果進行緩存,具體的值需要使用特殊的標識,能和真正緩存的數據區分開。另外,需要設置較短的過期時間,一般建議不要超過 5 分鐘。 -
方案二,BloomFilter 布隆過濾器。
在緩存服務的基礎上,構建 BloomFilter 數據結構,在 BloomFilter 中存儲對應的 KEY 是否存在,如果存在,說明該 KEY 對應的值不為空。
如何選擇
這兩個方案,各有其優缺點。
| 緩存空對象 | BloomFilter 布隆過濾器 | |
|---|---|---|
| 適用場景 | 1、數據命中不高 2、保證一致性 | 1、數據命中不高, 2、數據相對固定、實時性低 |
| 維護成本 | 1、代碼維護簡單 2、需要過多的緩存空間 3、數據不一致 | 1、代碼維護複雜,2、緩存空間占用小 |
實際情況下,使用方案二比較多。因為,相比方案一來說,更加節省內容,對緩存的負荷更小。
7. 如何處理緩存雪崩的問題
緩存雪崩,是指緩存由於某些原因無法提供服務( 例如,緩存掛掉了 ),所有請求全部達到 DB 中,導致 DB 負荷大增,最終掛掉的情況。
如何解決
預防和解決緩存雪崩的問題,可以從以下多個方面進行共同著手。
-
緩存高可用:通過搭建緩存的高可用,避免緩存掛掉導致無法提供服務的情況,從而降低出現緩存雪崩的情況。假設我們使用 Redis 作為緩存,則可以使用 Redis Sentinel 或 Redis Cluster 實現高可用。
-
本地緩存:如果使用本地緩存時,即使分散式緩存掛了,也可以將 DB 查詢到的結果緩存到本地,避免後續請求全部到達 DB 中。如果我們使用 JVM ,則可以使用 Ehcache、Guava Cache 實現本地緩存的功能。
當然,引入本地緩存也會有相應的問題,例如說:
本地緩存的實時性怎麼保證?
方案一,可以引入消息隊列。在數據更新時,發佈數據更新的消息;而進>程中有相應的消費者消費該消息,從而更新本地緩存。
方案二,設置較短的過期時間,請求時從 DB 重新拉取。
方案三,手動過期。
-
請求 DB 限流: 通過限制 DB 的每秒請求數,避免把 DB 也打掛了。如果我們使用 Java ,則可以使用 Guava RateLimiter、Sentinel、Hystrix 實現限流的功能。這樣至少能有兩個好處:
- 可能有一部分用戶,還可以使用,系統還沒死透。
- 未來緩存服務恢復後,系統立即就已經恢復,無需再處理 DB 也掛掉的情況。
-
提前演練:在項目上線前,演練緩存宕掉後,應用以及後端的負載情況以及可能出現的問題,在此基礎上做一些預案設定。
8. 如何處理緩存擊穿的問題
緩存擊穿,是指某個極度“熱點”數據在某個時間點過期時,恰好在這個時間點對這個 KEY 有大量的併發請求過來,這些請求發現緩存過期一般都會從 DB 載入數據並回設到緩存,但是這個時候大併發的請求可能會瞬間 DB 壓垮。
- 對於一些設置了過期時間的 KEY ,如果這些 KEY 可能會在某些時間點被超高併發地訪問,是一種非常“熱點”的數據。這個時候,需要考慮這個問題。
- 區別:
- 和緩存“雪崩“”的區別在於,前者針對某一 KEY 緩存,後者則是很多 KEY 。
- 和緩存“穿透“”的區別在於,這個 KEY 是真實存在對應的值的。
如何解決
有兩種方案可以解決:
-
方案一,使用互斥鎖。請求發現緩存不存在後,去查詢 DB 前,使用分散式鎖,保證有且只有一個線程去查詢 DB ,並更新到緩存。
-
方案二,手動過期。緩存上從不設置過期時間,功能上將過期時間存在 KEY 對應的 VALUE 里。流程如下:
- 獲取緩存。通過 VALUE 的過期時間,判斷是否過期。如果未過期,則直接返回;如果已過期,繼續往下執行。
- 通過一個後臺的非同步線程進行緩存的構建,也就是“手動”過期。通過後臺的非同步線程,保證有且只有一個線程去查詢 DB。
- 同時,雖然 VALUE 已經過期,還是直接返回。通過這樣的方式,保證服務的可用性,雖然損失了一定的時效性。
選擇
這兩個方案,各有其優缺點。
| 使用互斥鎖 | 手動過期 | |
|---|---|---|
| 優點 | 1、思路簡單 2、保證一致性 | 1、性價最佳,用戶無需等待 |
| 缺點 | 1、代碼複雜度增大 2、存在死鎖的風險 | 1、無法保證緩存一致性 |
9. 緩存和 DB 的一致性如何保證?
產生原因
主要有兩種情況,會導致緩存和 DB 的一致性問題:
- 併發的場景下,導致讀取老的 DB 數據,更新到緩存中。
主要指的是,更新 DB 數據之前,先刪除 Cache 的數據。在低併發量下沒什麼問題,但是在高併發下,就會存在問題。在(刪除 Cache 的數據, 和更新 DB 數據)時間之間,恰好有一個請求,我們如果使用被動讀,因為此時 DB 數據還是老的,又會將老的數據寫入到 Cache 中。
- 緩存和 DB 的操作,不在一個事務中,可能只有一個 DB 操作成功,而另一個 Cache 操作失敗,導致不一致。
當然,有一點我們要註意,緩存和 DB 的一致性,我們指的更多的是最終一致性。我們使用緩存只要是提高讀操作的性能,真正在寫操作的業務邏輯,還是以資料庫為準。例如說,我們可能緩存用戶錢包的餘額在緩存中,在前端查詢錢包餘額時,讀取緩存,在使用錢包餘額時,讀取資料庫。
解決方案
在開始說解決方案之前,胖友先看看如下幾篇文章,可能有一丟丟多,保持耐心。
當然無論哪種方案,比較重要的就是解決兩個問題:
-
- 將緩存可能存在的並行寫,實現串列寫。
-
- 實現數據的最終一致性。
- 先淘汰緩存,再寫資料庫
因為先淘汰緩存,所以數據的最終一致性是可以得到有效的保證的。為什麼呢?先淘汰緩存,即使寫資料庫發生異常,也就是下次緩存讀取時,多讀取一次資料庫。
那麼,我們需要解決緩存並行寫,實現串列寫。比較簡單的方式,引入分散式鎖。
- 在寫請求時,先淘汰緩存之前,先獲取該分散式鎖。
- 在讀請求時,發現緩存不存在時,先獲取分散式鎖。
- 先寫資料庫,再更新緩存
按照 “先寫資料庫,再更新緩存”,我們要保證 DB 和緩存的操作,能夠在 “同一個事務”中,從而實現最終一致性
10. 什麼是緩存預熱?如何實現緩存預熱?
緩存預熱
在剛啟動的緩存系統中,如果緩存中沒有任何數據,如果依靠用戶請求的方式重建緩存數據,那麼對資料庫的壓力非常大,而且系統的性能開銷也是巨大的。
此時,最好的策略是啟動時就把熱點數據載入好。這樣,用戶請求時,直接讀取的就是緩存的數據,而無需去讀取 DB 重建緩存數據。舉個例子,熱門的或者推薦的商品,需要提前預熱到緩存中。
如何實現
一般來說,有如下幾種方式來實現:
- 數據量不大時,項目啟動時,自動進行初始化。
- 寫個修複數據腳本,手動執行該腳本。
- 寫個管理界面,可以手動點擊,預熱對應的數據到緩存中。
拓展:緩存數據的淘汰策略有哪些?
除了緩存伺服器自帶的緩存自動失效策略之外,我們還可以根據具體的業務需求進行自定義的“手動”緩存淘汰,常見的策略有兩種:
- 定時去清理過期的緩存。
- 當有用戶請求過來時,再判斷這個請求所用到的緩存是否過期,過期的話就去底層系統得到新數據並更新緩存。
兩者各有優劣,第一種的缺點是維護大量緩存的 key 是比較麻煩的,第二種的缺點就是每次用戶請求過來都要判斷緩存失效,邏輯相對比較複雜!Redis 的緩存淘汰策略就是很好的實踐方式。
具體用哪種方案,大家可以根據自己的應用場景來權衡。
Docker
1. 什麼是 Docker 容器?
Docker 是一種流行的開源軟體平臺,可簡化創建、管理、運行和分發應用程式的過程。它使用容器來打包應用程式及其依賴項。我們也可以將容器視為 Docker 鏡像的運行時實例。
2. Docker 和虛擬機有什麼不同?
Docker 是輕量級的沙盒,在其中運行的只是應用,虛擬機裡面還有額外的系統。
3. 什麼是 DockerFile?
Dockerfile 是一個文本文件,其中包含我們需要運行以構建 Docker 鏡像的所有命令,每一條指令構建一層,因此每一條指令的內容,就是描述該層應當如何構建。Docker 使用 Dockerfile 中的指令自動構建鏡像。我們可以 docker build 用來創建按順序執行多個命令行指令的自動構建。
一些最常用的指令如下:
FROM :使用 FROM 為後續的指令建立基礎映像。在所有有效的 Dockerfile 中, FROM 是第一條指令。
LABEL: LABEL 指令用於組織項目映像,模塊,許可等。在自動化佈署方面 LABEL 也有很大用途。在 LABEL 中指定一組鍵值對,可用於程式化配置或佈署 Docker 。
RUN: RUN 指令可在映像當前層執行任何命令並創建一個新層,用於在映像層中添加功能層,也許最來的層會依賴它。
CMD: 使用 CMD 指令為執行的容器提供預設值。在 Dockerfile 文件中,若添加多個 CMD 指令,只有最後的 CMD 指令運行。
4. 使用Docker Compose時如何保證容器A先於容器B運行?
Docker Compose 是一個用來定義和運行複雜應用的Docker工具。一個使用Docker容器的應用,通常由多個容器組成。使用Docker Compose不再需要使用shell腳本來啟動容器。Compose 通過一個配置文件來管理多個Docker容器。簡單理解:Docker Compose 是docker的管理工具。
Docker Compose 在繼續下一個容器之前不會等待容器準備就緒。為了控制我們的執行順序,我們可以使用“取決於”條件,depends_on 。這是在 docker-compose.yml 文件中使用的示例
version: "2.4"
services:
backend:
build: . # 構建自定義鏡像
depends_on:
- db
db:
image: mysql
用 docker-compose up 命令將按照我們指定的依賴順序啟動和運行服務。
5. 一個完整的Docker由哪些部分組成?
- DockerClient 客戶端
- Docker Daemon 守護進程
- Docker Image 鏡像
- DockerContainer 容器
6. docker常用命令
命令建議在本地安裝做一個實操,記憶會更深刻。
也可以克隆基於docker的倆萬(springboot+vue)項目練手,提供視頻+完善文檔。地址:https://gitee.com/rodert/liawan-vue
- 查看本地主機的所用鏡像:`docker images``
- 搜索鏡像:`docker search mysql``
- 下載鏡像:
docker pull mysql,沒寫 tag 就預設下載最新的 lastest - 下載指定版本的鏡像:`docker pull mysql:5.7``
- 刪除鏡像:`docker rmi -f 鏡像id 鏡像id 鏡像id``
7. 描述 Docker 容器的生命周期。
Docker 容器經歷以下階段:
- 創建容器
- 運行容器
- 暫停容器(可選)
- 取消暫停容器(可選)
- 啟動容器
- 停止容器
- 重啟容器
- 殺死容器
- 銷毀容器
8. docker容器之間怎麼隔離?
這是一道涉獵很廣泛的題目,理解性閱讀。
Linux中的PID、IPC、網路等資源是全局的,而Linux的NameSpace機制是一種資源隔離方案,在該機制下這些資源就不再是全局的了,而是屬於某個特定的NameSpace,各個NameSpace下的資源互不幹擾。
Namespace實際上修改了應用進程看待整個電腦“視圖”,即它的“視線”被操作系統做了限制,只能“看到”某些指定的內容。對於宿主機來說,這些被“隔離”了的進程跟其他進程並沒有區別。
雖然有了NameSpace技術可以實現資源隔離,但進程還是可以不受控的訪問系統資源,比如CPU、記憶體、磁碟、網路等,為了控制容器中進程對資源的訪問,Docker採用control groups技術(也就是cgroup),有了cgroup就可以控制容器中進程對系統資源的消耗了,比如你可以限制某個容器使用記憶體的上限、可以在哪些CPU上運行等等。
有了這兩項技術,容器看起來就真的像是獨立的操作系統了。
強烈建議大家實操,才能更好的理解docker。
低谷蓄力
ElasticSearch
1. 說說你們公司 es 的集群架構,索引數據大小,分片有多少,以及一些調優手段 。
節點數、分片數、副本數,儘量根據自己公司使用情況回答,當然適當放大也可行。
調優手段是現在很常見的面試題,下麵這幾種調優手段一定要瞭解懂。當然,下麵的每一條都可以當做調優的一部分。
設計調優
參考:
https://www.cnblogs.com/sanduzxcvbnm/p/12084012.html
a. 根據業務增量需求,採取基於日期模板創建索引,通過 rollover API 滾動索引;(rollover API我會單獨寫一個代碼案例做講解,公眾號:JavaPub)
b. 使用別名進行索引管理;(es的索引名不能改變,提供的別名機制使用非常廣泛。)
c. 每天凌晨定時對索引做force_merge操作,以釋放空間;
d. 採取冷熱分離機制,熱數據存儲到SSD,提高檢索效率;冷數據定期進行shrink操作,以縮減存儲;
e. 採取curator進行索引的生命周期管理;
f. 僅針對需要分詞的欄位,合理的設置分詞器;
g. Mapping階段充分結合各個欄位的屬性,是否需要檢索、是否需要存儲等。
進100+原創文章:https://gitee.com/rodert/JavaPub
寫入調優
- 寫入前副本數設置為0;
- 寫入前關閉refresh_interval設置為-1,禁用刷新機制;
- 寫入過程中:採取bulk批量寫入;
- 寫入後恢復副本數和刷新間隔;
- 儘量使用自動生成的id。
查詢調優
- 禁用wildcard;(通配符模式,類似於%like%)
- 禁用批量terms(成百上千的場景);
- 充分利用倒排索引機制,能keyword類型儘量keyword;
- 數據量大時候,可以先基於時間敲定索引再檢索;
- 設置合理的路由機制。
2. elasticsearch 的倒排索引是什麼
倒排索引也就是單詞到文檔的映射,當然不只是存里文檔id這麼簡單。還包括:詞頻(TF,Term Frequency)、偏移量(offset)、位置(Posting)。
3. elasticsearch 是如何實現 master 選舉的
ElasticSearch 的選主是 ZenDiscovery 模塊負責,源碼分析將首發在。 https://gitee.com/rodert/JavaPub
- 對所有可以成為 Master 的節點(node.master: true)根據 nodeId 排序,每次選舉每個節點都把自己所知道節點排一次序,然後選出第一個(第0位)節點,暫且認為它是 Master 節點。
- 如果對某個節點的投票數達到一定的值(可以成為master節點數n/2+1)並且該節點自己也選舉自己,那這個節點就是master。否則重新選舉。
(當然也可以自己設定一個值,最小值設定為超過能成為Master節點的n/2+1,否則會出現腦裂問題。discovery.zen.minimum_master_nodes)
5. 描述一下 Elasticsearch 索引文檔的過程

- 客戶端向 Node 1 發送新建、索引或者刪除請求。
- 節點使用文檔的 _id 確定文檔屬於分片 0 。請求會被轉發到 Node 3,因為分片 0 的主分片目前被分配在 Node 3 上。
- Node 3 在主分片上面執行請求。如果成功了,它將請求並行轉發到 Node 1 和 Node 2 的副本分片上。一旦所有的副本分片都報告成功, Node 3 將向協調節點報告成功,協調節點向客戶端報告成功。
一圖勝千文,記住這幅圖,上面是文檔在節點間分發的過程,接著說一下文檔從接收到寫入磁碟過程。
協調節點預設使用文檔 ID 參與計算(也支持通過 routing),以便為路由提供合適的分片。
shard = hash(document_id) % (num_of_primary_shards)
- 當分片所在的節點接收到來自協調節點的請求後,會將請求寫入到 MemoryBuffer,然後定時(預設是每隔 1 秒)寫入到 Filesystem Cache,這個從 MomeryBuffer 到 Filesystem Cache 的過程就叫做 refresh;
- 當然在某些情況下,存在 Momery Buffer 和 Filesystem Cache 的數據可能會丟失,ES 是通過 translog 的機制來保證數據的可靠性的。其實現機制是接收到請求後,同時也會寫入到 translog 中,當 Filesystem cache 中的數據寫入到磁碟中時,才會清除掉,這個過程叫做 flush;
- 在 flush 過程中,記憶體中的緩衝將被清除,內容被寫入一個新段,段的 fsync將創建一個新的提交點,並將內容刷新到磁碟,舊的 translog 將被刪除並開始一個新的 translog。
- flush 觸發的時機是定時觸發(預設 30 分鐘)或者 translog 變得太大(預設為 512M)時;
1. translog 可以理解為就是一個文件,一直追加。
2. MemoryBuffer 應用緩存。
3. Filesystem Cache 系統緩衝區。
延伸閱讀:Lucene 的 Segement:
- Lucene 索引是由多個段組成,段本身是一個功能齊全的倒排索引。
- 段是不可變的,允許 Lucene 將新的文檔增量地添加到索引中,而不用從頭重建索引。
- 對於每一個搜索請求而言,索引中的所有段都會被搜索,並且每個段會消耗CPU 的時鐘周、文件句柄和記憶體。這意味著段的數量越多,搜索性能會越低。
- 為瞭解決這個問題,Elasticsearch 會合併小段到一個較大的段,提交新的合併段到磁碟,並刪除那些舊的小段。
4. 詳細描述一下 Elasticsearch 搜索的過程?
es作為一個分散式的存儲和檢索系統,每個文檔根據 _id 欄位做路由分發被轉發到對應的shard上。
搜索執行階段過程分倆個部分,我們稱之為 Query Then Fetch。
4.1 query-查詢階段
當一個search請求發出的時候,這個query會被廣播到索引裡面的每一個shard(主shard或副本shard),每個shard會在本地執行查詢請求後會生成一個命中文檔的優先順序隊列。
這個隊列是一個排序好的top N數據的列表,它的size等於from+size的和,也就是說如果你的from是10,size是10,那麼這個隊列的size就是20,所以這也是為什麼深度分頁不能用from+size這種方式,因為from越大,性能就越低。
es裡面分散式search的查詢流程如下:

查詢階段包含以下三個步驟:
- 客戶端發送一個 search 請求到 Node 3 , Node 3 會創建一個大小為 from + size 的空優先隊列。
- Node 3 將查詢請求轉發到索引的每個主分片或副本分片中。每個分片在本地執行查詢並添加結果到大小為 from + size 的本地有序優先隊列中。
- 每個分片返回各自優先隊列中所有文檔的 ID 和排序值給協調節點,也就是 Node 3 ,它合併這些值到自己的優先隊列中來產生一個全局排序後的結果列表。
4.2 fetch - 讀取階段 / 取回階段

分散式階段由以下步驟構成:
- 協調節點辨別出哪些文檔需要被取回並向相關的分片提交多個 GET 請求。
- 每個分片載入並 豐富 文檔,如果有需要的話,接著返迴文檔給協調節點。
- 一旦所有的文檔都被取回了,協調節點返回結果給客戶端。
協調節點首先決定哪些文檔 確實 需要被取回。例如,如果我們的查詢指定了 { "from": 90, "size": 10 } ,最初的90個結果會被丟棄,只有從第91個開始的10個結果需要被取回。這些文檔可能來自和最初搜索請求有關的一個、多個甚至全部分片。
協調節點給持有相關文檔的每個分片創建一個 multi-get request ,併發送請求給同樣處理查詢階段的分片副本。
分片載入文檔體-- _source 欄位—如果有需要,用元數據和 search snippet highlighting 豐富結果文檔。 一旦協調節點接收到所有的結果文檔,它就組裝這些結果為單個響應返回給客戶端。
拓展閱讀:
深翻頁(Deep Pagination)
---
先查後取的過程支持用 from 和 size 參數分頁,但是這是 有限制的 。 要記住需要傳遞信息給協調節點的每個分片必須先創建一個 from + size 長度的隊列,協調節點需要根據 number_of_shards * (from + size) 排序文檔,來找到被包含在 size 里的文檔。
取決於你的文檔的大小,分片的數量和你使用的硬體,給 10,000 到 50,000 的結果文檔深分頁( 1,000 到 5,000 頁)是完全可行的。但是使用足夠大的 from 值,排序過程可能會變得非常沉重,使用大量的CPU、記憶體和帶寬。因為這個原因,我們強烈建議你不要使用深分頁。
實際上, “深分頁” 很少符合人的行為。當2到3頁過去以後,人會停止翻頁,並且改變搜索標準。會不知疲倦地一頁一頁的獲取網頁直到你的服務崩潰的罪魁禍首一般是機器人或者web spider。
如果你 確實 需要從你的集群取回大量的文檔,你可以通過用 scroll 查詢禁用排序使這個取回行為更有效率,我們會在 later in this chapter 進行討論。
註:https://www.elastic.co/guide/cn/elasticsearch/guide/current/scroll.html
5. Elasticsearch 在部署時,對 Linux 的設置有哪些優化方法
- 關閉緩存swap;
原因:大多數操作系統會將記憶體使用到文件系統緩存,會將應用程式未用到的記憶體交換出去。會導致jvm的堆記憶體交換到磁碟上。交換會導致性能問題。會導致記憶體垃圾回收延長。會導致集群節點響應時間變慢,或者從集群中斷開。
-
堆記憶體設置為:Min(節點記憶體/2, 32GB);
-
設置最大文件句柄數;
後倆點不懂可以先說有一定瞭解,關註JavaPub會做詳細講解。
-
調整線程池和隊列大小
-
磁碟存儲 raid 方式——存儲有條件使用 RAID6,增加單節點性能以及避免單節點存儲故障。
6. Elasticsearch 中的節點(比如共 20 個),其中的 10 個選了一個 master,另外 10 個選了另一個 master,怎麼辦?
-
當集群 master 候選數量不小於 3 個時,可以通過設置最少投票通過數量(discovery.zen.minimum_master_nodes)超過所有候選節點一半以上來解決腦裂問題;
-
當候選數量為兩個時,只能修改為唯一的一個 master 候選,其他作為 data節點,避免腦裂問題。
7. 客戶端在和集群連接時,如何選擇特定的節點執行請求的?
client 遠程連接連接一個 elasticsearch 集群。它並不加入到集群中,只是獲得一個或者多個初始化的地址,並以輪詢的方式與這些地址進行通信。
8. 詳細描述一下 Elasticsearch 更新和刪除文檔的過程。
- 刪除和更新也都是寫操作,但是 Elasticsearch 中的文檔是不可變的,因此不能被刪除或者改動以展示其變更;(根本原因是底層lucene的segment段文件不可更新刪除)
- 磁碟上的每個段都有一個相應的 .del 文件。當刪除請求發送後,文檔並沒有真 的被刪除,而是在
.del文件中被標記為刪除。該文檔依然能匹配查詢,但是會在 結果中被過濾掉。當段合併時,在.del 文件中被標記為刪除的文檔將不會被寫入 新段。 - 在新的文檔被創建時,Elasticsearch 會為該文檔指定一個版本號,當執行更新 時,舊版本的文檔在.del 文件中被標記為刪除,新版本的文檔被索引到一個新段。
舊版本的文檔依然能匹配查詢,但是會在結果中被過濾掉。
9. Elasticsearch 對於大數據量(上億量級)的聚合如何實現?
這道題目較難,相信大家看到很多類似這種回答
Elasticsearch 提供的首個近似聚合是cardinality 度量。它提供一個欄位的基數,即該欄位的distinct或者unique值的數目。它是基於HLL演算法的。HLL 會先對我們的輸入作哈希運算,然後根據哈希運算的結果中的 bits 做概率估算從而得到基數。其特點是:可配置的精度,用來控制記憶體的使用(更精確 = 更多記憶體);小的數據集精度是非常高的;我們可以通過配置參數,來設置去重需要的固定記憶體使用量。無論數千還是數十億的唯一值,記憶體使用量只與你配置的精確度相關。
科普&拓展:
HyperLogLog:
下麵簡稱為HLL,它是 LogLog 演算法的升級版,作用是能夠提供不精確的去重計數。存在以下的特點:
1. 能夠使用極少的記憶體來統計巨量的數據,在 Redis 中實現的 HyperLogLog,只需要12K記憶體就能統計2^64個數據。
2. 計數存在一定的誤差,誤差率整體較低。標準誤差為 0.81% 。
3. 誤差可以被設置輔助計算因數進行降低。
---
應用場景:
1. 基數不大,數據量不大就用不上,會有點大材小用浪費空間
2. 有局限性,就是只能統計基數數量,而沒辦法去知道具體的內容是什麼
3. 和bitmap相比,屬於兩種特定統計情況,簡單來說,HyperLogLog 去重比 bitmap 方便很多
4. 一般可以bitmap和hyperloglog配合使用,bitmap標識哪些用戶活躍,hyperloglog計數
---
應用場景:
1. 基數不大,數據量不大就用不上,會有點大材小用浪費空間
2. 有局限性,就是只能統計基數數量,而沒辦法去知道具體的內容是什麼
3. 和bitmap相比,屬於兩種特定統計情況,簡單來說,HyperLogLog 去重比 bitmap 方便很多
4. 一般可以bitmap和hyperloglog配合使用,bitmap標識哪些用戶活躍,hyperloglog計數
來源:刷刷面試
10. 在併發情況下,Elasticsearch 如果保證讀寫一致?
首先要瞭解什麼是一致性,在分散式系統中,我們一般通過CPA理論分析。
分散式系統不可能同時滿足一致性(C:Consistency)、可用性(A:Availability)和分區容忍性(P:Partition Tolerance),最多只能同時滿足其中兩項。

- 可以通過版本號使用樂觀併發控制,以確保新版本不會被舊版本覆蓋,由應用層來處理具體的衝突;
- 另外對於寫操作,一致性級別支持 quorum/one/all,預設為 quorum,即只有當大多數分片可用時才允許寫操作。但即使大多數可用,也可能存在因為網路等原因導致寫入副本失敗,這樣該副本被認為故障,分片將會在一個不同的節點上重建。
- 對於讀操作,可以設置 replication 為 sync(預設),這使得操作在主分片和副本分片都完成後才會返回;如果設置 replication 為 async 時,也可以通過設置搜索請求參數_preference 為 primary 來查詢主分片,確保文檔是最新版本。
11. 介紹一下你們的個性化搜索方案?
如果你沒有很多實戰經驗,可以基於 word2vec 做一些練習,我的博客提供了 word2vec Java版的一些Demo。
基於 word2vec 和 Elasticsearch 實現個性化搜索,它有以下優點:
- 基於word2vec的商品向量還有一個可用之處,就是可以用來實現相似商品的推薦;
Java基礎
1. instanceof 關鍵字的作用
instanceof 是 Java 的保留關鍵字。它的作用是測試它左邊的對象是否是它右邊的類的實例,返回 boolean 的數據類型。
boolean result = obj instanceof class
當 obj 為 Class 的對象,或者是其直接或間接子類,或者是其介面的實現類,結果result 都返回 true,否則返回false。
註意一點:編譯器會檢查 obj 是否能轉換成右邊的class類型,如果不能轉換則直接報錯,如果不能確定類型,則通過編譯,具體看運行時定。
obj 必須為引用類型,只能作為對象的判斷,不能是基本類型。
int i = 0;
System.out.println(i instanceof Integer);//編譯不通過
System.out.println(i instanceof Object);//編譯不通過
源碼參考:JavaSE 8 instanceof 的實現演算法:https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-6.html#jvms-6.5.instanceof
2. Java自動裝箱和拆箱
什麼是裝箱拆箱,這裡不做源碼層面解讀,源碼解讀在JavaPub公眾號發出。這裡通過講解 int 和 Interger 區別,解答Java自動裝箱和拆箱。
自動裝箱 ----- 基本類型的值 → 包裝類的實例
自動拆箱 ----- 基本類型的值 ← 包裝類的實例
- Integer變數必須實例化後才能使用,而int變數不需要
- Integer實際是對象的引用,當new一個Integer時,實際上是生成一個指針指向此對象;而int則是直接存儲數據值 。
- Integer的預設值是null,int的預設值是0
Java中8種基本數據類型。左邊基本類型,右邊包裝類型。

在面試中:
下麵這段代碼的輸出結果是什麼?
public class Main {
public static void main(String[] args) {
Integer i1 = 100;
Integer i2 = 100;
Integer i3 = 200;
Integer i4 = 200;
System.out.println(i1==i2);
System.out.println(i3==i4);
}
}
//true
//false
輸出結果表明i1和i2指向的是同一個對象,而i3和i4指向的是不同的對象。此時只需一看源碼便知究竟,下麵這段代碼是Integer的valueOf方法的具體實現:
public static Integer valueOf(int i) {
if(i >= -128 && i <= IntegerCache.high)
return IntegerCache.cache[i + 128];
else
return new Integer(i);
}
private static class IntegerCache {
static final int high;
static final Integer cache[];
static {
final int low = -128;
// high value may be configured by property
int h = 127;
if (integerCacheHighPropValue != null) {
// Use Long.decode here to avoid invoking methods that
// require Integer's autoboxing cache to be initialized
int i = Long.decode(integerCacheHighPropValue).intValue();
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - -low);
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
}
private IntegerCache() {}
}
從這2段代碼可以看出,在通過valueOf方法創建Integer對象的時候,如果數值在[-128,127]之間,便返回指向IntegerCache.cache中已經存在的對象的引用;否則創建一個新的Integer對象。
上面的代碼中i1和i2的數值為100,因此會直接從cache中取已經存在的對象,所以i1和i2指向的是同一個對象,而i3和i4則是分別指向不同的對象。
註意,Integer、Short、Byte、Characte


