
數據服務與數據分析場景是數據團隊在數據應用上兩個大的方向,行業內大家有可能會遇到很多問題,數據服務和數據分析系統也是無法統一,分析產生的數據結果往往是離線的,需要額外開發數據服務,無法快速轉化為線上服務賦能外部系統,使得分析和服務之間難以快速形成閉環。而且在以往數據加工過程中存儲往往只考慮了當時的需... ...
1 背景
數據服務與數據分析場景是數據團隊在數據應用上兩個大的方向,行業內大家有可能會遇到下麵的問題:
1.1 數據服務
- 煙囪式開發模式:每來一個需求開發一個數據服務,數據服務無法復用,難以平臺化,技術上無法積累
- 服務維護難度大:當開發了大量數據服務後,後期維護是大問題,尤其是618、雙11大促期間,在沒有統一的監控、限流、災備方案的情況下一個人維護上百個數據服務是一件很痛苦的事,也造成了很大的安全隱患
- 業務需求量大:數據開發的同學常常會被大量重覆枯燥的數據服務開發束縛,大量的時間投入在業務數據服務開發中
1.2 數據分析
- 找數據難:用戶難以找到自己想要,即便找到名稱相近的指標或數據,由於指標口徑不明確也不統一也無法直接使用
- 用數難:由於目前數據分佈在各個系統中,用戶無法用一個系統滿足所有的數據需求。特別是一線運營人員要通過每個從各個系統導出大量Excel的方式做數據分析,費時費力,同時也造成數據安全隱患
- 查詢慢:用傳統的Olap引擎,用戶跑SQL往往需要幾分鐘才出結果,大大降低了分析人員的效率。
- 查詢引擎不統一:系統可能有多種查詢引擎組成,每一種查詢引擎都有自己的DSL,增大了用戶的學習成本,同時需要跨多數據源查詢也是一件很不方便的事。異構查詢引擎帶來的另一個問題是形成了數據孤島,各系統間的數據之間無法相互關聯
- 數據實時更新:傳統離線T+1方式數據更新已經無法滿足當今的實時化運營的業務訴求,這就要求系統需要到達秒級別的延遲
除了以上問題,數據服務和數據分析系統也是無法統一,分析產生的數據結果往往是離線的,需要額外開發數據服務,無法快速轉化為線上服務賦能外部系統,使得分析和服務之間難以快速形成閉環。而且在以往數據加工過程中存儲往往只考慮了當時的需求,當後續需求場景擴展,最初的存儲引擎可能不適用,導致一份數據針對不同的場景要存儲到不同的存儲引擎,帶來數據一致性隱患和成本浪費問題。
2 基於StarRocks 的數據服務分析一體化實踐
基於以上這些業務痛點京東物流運營數據產品團隊研發了服務分析一體化系統——UData(Universal Data),UData系統是以StarRocks引擎為技術基礎的實現的。UData把數據指標生成的過程抽象出來,用配置的方式低代碼化生成數據服務,大大降低的開發複雜性和難度,讓非研發同學也可以根據自己的需求配置和發佈自己數據服務,指標的開發時間由之前的一兩天縮短為30分鐘,大大解放了研發力。平臺化的指標管理體系和數據地圖的功能,讓用戶更加直觀和方便地查找與維護指標,同時也讓指標復用變成可能。
在數據分析方面,我們用基於StarRocks的聯邦查詢方案打造了UData統一查詢引擎,解決了查詢引擎不統一和數據孤島問題,同時StarRocks提供了強悍的數據查詢性能,無論是大寬表還是多表關聯查詢性能都十分出色。StarRocks提供數據實時攝入的能力和多種實時數據模型,可以很好的支持數據實時更新場景。UData系統把分析和服務結合在一起,讓分析和服務不再是分割的兩個過程,用戶分析出有價值的數據後可以立即生成對應的數據服務,讓服務分析快速閉環。
數據流程架構圖:
改造前的架構:
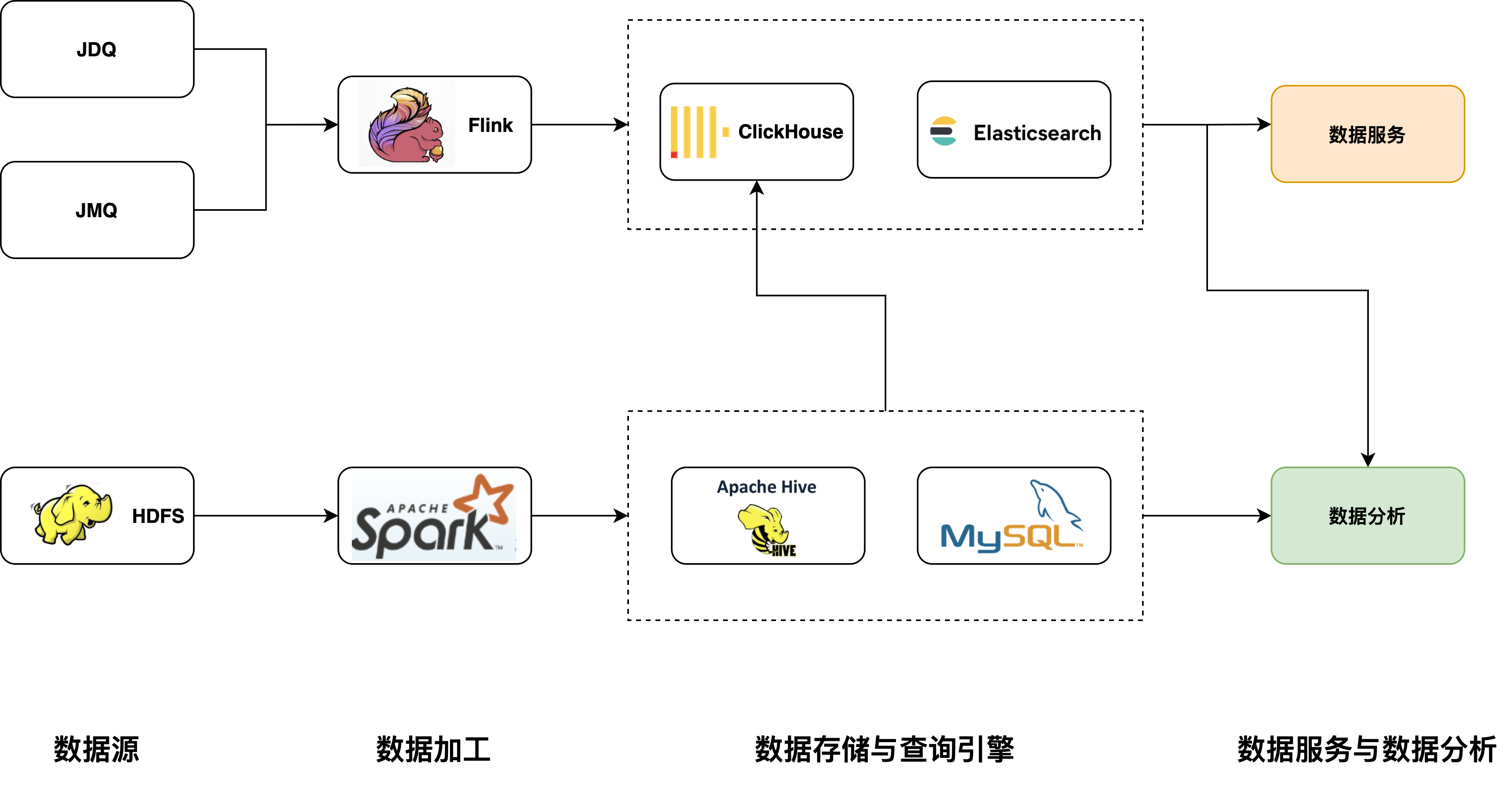
圖1 改造前架構圖
改造前實時數據由JDQ(京東日誌消息隊列,類似Kafka)和JMQ導入Flink做實時數據加工,加工後數據寫入Clickhouse和ElasticSearch,為數據服務和數據分析提供Olap查詢服務。離線數據由Spark做個數倉層級加工,APP層數據會同步至Mysql或Clickhouse做Olap查詢。此架構中,在數據服務和數據分析是兩個分隔的部分,分析工具由於要跨多數據源和不同的查詢語言做數據分析比較困難的,數據服務也是煙囪式開發。
改造後的架構:
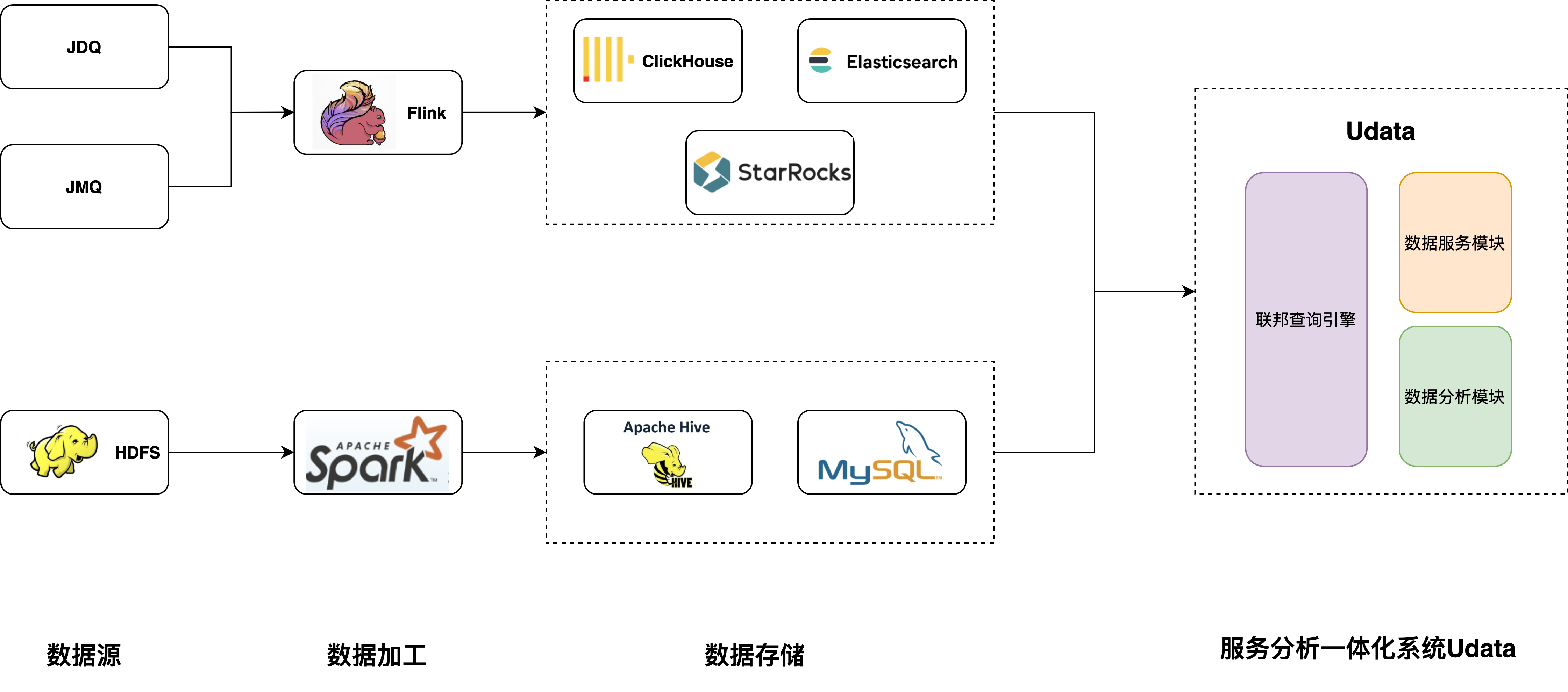
圖2 改造後的架構
改造後,我們在數據存儲層引入了StarRocks,StarRocks提供了極速的單表和多表查詢能力,同時以StarRocks為基礎我們打造了統一查詢引擎,統一查詢引擎根據京東的業務特點增加數據源和聚合下推等功能,UData在統一查詢引擎的基礎上統一了數據分析和數據服務功能。
打造一款數據服務分析一體化系統對查詢引擎有比較高的要求,需要同時滿足:極速的查詢性能、支持聯邦查詢、實時與離線存儲統一。基於這三點要求,下麵我們就StarRocks極速的查詢性能的原因、我們對聯邦查詢的改造、實時場景的實踐展開討論。
2.1 StarRocks極速的查詢性能的原因
極速查詢的單表查詢:
StarRocks在極速查詢方面上做了很多,下麵著重介紹下麵四點:
- 向量化執行:StarRocks實現了從存儲層到查詢層的全面向量化執行,這是SR在速度上優勢的基礎。向量化執行充分發揮了CPU的處理能力。全面向量化引擎按照列式的方式組織和處理數據。StarRocks的數據存儲、記憶體中數據的組織方式,以及SQL運算元的計算方式,都是列式實現的。按列的數據組織也會更加充分的利用CPU的Cache,按列計算會有更少的虛函數調用以及更少的分支判斷從而獲得更加充分的CPU指令流水。另一方面,StarRocks的全面向量化引擎通過向量化演算法充分的利用CPU提供的SIMD指令。這樣StarRocks可以用更少的指令數目,完成更多的數據操作。經過標準測試集的驗證,StarRocks的全面向量化引擎可以將執行運算元的性能,整體提升3—10倍。
- 物化視圖加速查詢:在實際分析場景中,我們經常遇到分析上百億的大表情況,儘管SR性能優異但數據量過大查詢速度還是有影響的,此時在用戶經常聚合的維度加上了物化視圖,在不用改變查詢語句的情況下查詢速度提升10倍以上,SR智能化的物化視圖可以讓請求自動匹配視圖,無需手動查詢視圖。
- CBO:CBO(Cost-based Optimizer ) 優化器採用 Cascades 框架,使用多種統計信息來完善成本估算,同時補充邏輯轉換(Transformation Rule)和物理實現(Implementation Rule)規則,能夠在數萬級別執行計劃的搜索空間中,選擇成本最低的最優執行計劃。
- 自適應低基數優化:StarRocks可以自適的根據數據分佈,對低基數的字元串類型的列構建一張全局字典,用Int類型做存儲和查詢,使得記憶體開銷更小,有利於SIMD指令執行,加快了查詢速度。與此對應Clickhouse也有LowCardinality方式優化,只是需要在建表時候需要聲明,使用起來會麻煩一些。
極速的多表關聯:
在實時數據分析場景中只滿足單表極速查詢是不夠的,目前為了加速查詢速度行業內習慣於把多張表打成一張大寬表,大寬表雖隨度快,但是帶來的問題是極其不靈活,實時數據加工層是用flink將多表 join成一張表寫入大寬表,當業務方想修改或增加分析維度時往往數據開發周期過長,數據加工完成後發現已經錯過了分析最佳時機。所以需要更靈活的數據模型,比較理想的方法是把大寬表模式退歸回星型模型或者雪花模型。在此場景下查詢引擎對多表數據關聯查詢的性能成了關鍵,以往clickhouse以大寬表為主,多表聯查情況下無法保證查詢相應時間,甚至有很大幾率出現OOM。SR很好解決了這個問題,大表join性能提升3~5倍以上,成為星型模型分析利器。CBO(Cost-based Optimizer )是多表關聯極致性能關鍵,同時StarRocks 支持Broadcost Join、Shuffle Join、Bucket shuffle Join、Colocated Join、Replicated Join等多種join方式,CBO可以智能的選擇join順序和join方式。
2.2 對StarRocks聯邦查詢的改造
在存儲層層由於需求、場景、歷史等原因是很難做到真正統一的存儲的,在過去的數據服務開發中由於存儲層不統一、資料庫查詢語法不同,開發基本是煙囪式開發,已開發的指標很難復用,也很難管理大量的已開髮指標。聯邦查詢可以很好的解決這個問題,使用統一的查詢引擎屏蔽了不同olap的引擎的專有DSL,大大提升了開發效率和學習成本,同時可以用ONE SQL方式整合來自不同數據源的指標形成新的指標,從而提高了指標的復用性。StarRocks外表擴展功能讓它具備了實現聯邦查詢的基礎,但細節上我們有一些自己的業務需求。
StarRocks在聯邦查詢上支持了多種外表如ES、Mysql、hive、數據湖等,已經有了很好的聯邦查詢的基礎。不過在實際的業務場景需求中,一些聚合類的查詢需要從外部數據源拉取數據再聚合,而且這些數據源自身的聚合性能也不錯,這反而增加了查詢時間。我們的思路是讓這部分擅長聚合的引擎自己做聚合,把聚合操作下推到外部引擎,目前符合這個優化條件的引擎有:Mysql、ElasticSearch、Clickhouse。同時為了相容更多的數據源,我們還增加了 JSF(京東內部RPC服務)/HTTP 數據源,下麵簡單介紹下這兩部分:
1.Mysql、ElasticSearch的聚合下推功能
現在StarRocks對於聚合外部數據源的方案是拉取謂詞下推後的全量的數據,雖然謂詞下推後已經過濾一部分數據但是把數據拉取到StarRocks再聚合是一個很重的操作,導致聚合時間不理想。我們的思路是下推聚合操作,讓外部表引擎自己做聚合,節省數據拉取時間,同時本地化聚合效率更高。聚合下推的優化在某些場景下有10倍以上的性能提升。

圖3 物理計劃優化圖
在物理執行計劃層我們做了再次優化,當遇到ES、Mysql、clickhouse的聚合造作時,會把ScanNode+AGGNode的執行計劃優化為QueryNode,QueryNode為一種特殊的ScanNode,與普通的ScanNode區別為QueryNode會直接把聚合查詢請求直接發送到對應外部引擎,而不是scan數據後在本地執行聚合。其中EsQueryNode我們會在FE端就生成ES查詢的DSL語句,直接下推到BE端查詢 。在同時在BE端我們實現了EsQueryNode 和MysqlQueryNode這兩種QueryNode。
2.增加 JSF(京東內部RPC服務)/HTTP 數據源
數據服務中可能會涉及到整合外部數據服務和復用原先已開髮指標的場景,我們的思路是把JSF(京東內部RPC服務)/HTTP也抽象成StarRocks的外部表,用戶可以通過SQL像查詢資料庫一樣訪問數據服務,這樣不僅可以復用老的指標還可以結合其他數據源的數據生成新的複合指標。我們在FE和BE端同時增加JSF和HTTP 兩種ScanNode。
2.3 實時場景的實踐
京東物流實時數據絕大多數屬於更新場景,運單類數據會根據業務狀態的改變而改變,下麵介紹我們在生產中的三種實時更新方案:
方案一:基於ES的實時更新方案
原理如下:
- 內部先get獲取document
- 記憶體中更新老的document
- 將老的document標記為deleted
- 創建新的document
優點:
- 支持數據實時更新,可以做到partail update
缺點:
- ES 聚合性能較差,當出現多個聚合維度時查詢時間會很長
- ES 的DSL語法增加了開發工作,雖然ES可以支持簡單SQL但是無法滿足複雜的業務場景
- 舊數據清理難,當觸發compaction物理刪除標記位文檔的時候會觸發大量的io操作,如果此時寫入量又很大,嚴重影響讀寫性能
方案二:基於clickhouse實現準實時的方案
原理如下:
- 使用ReplacingMergeTree 的方式實現
- 將Primary key相同的數據分發到同一個數據節點的同一個數據分區
- 查詢時做Merge on read ,合併多版本數據讀取
優點:
- clickhouse 寫入基本是append寫入,所以寫入性能強
缺點:
- 由於讀取時做版本合併,查詢和併發性能較差
- clickhouse的join性能不佳,會造成數據孤島問題
方案三:基於StarRocks主鍵模型的實時更新方案
原理:StarRocks收到對某行的更新操作時,會通過主鍵索引找到該條記錄的位置,並對其標記為刪除,再插入一條新的記錄。相當於把Update改寫為Delete+Insert。StarRocks收到對某行的刪除操作時,會通過主鍵索引找到該條記錄的位置,對其標記為刪除。這樣在查詢時不影響謂詞下推和索引的使用, 保證了查詢的高效執行。查詢速度比Merge on read方式快5-10倍。
優點:
- 只有唯一版本數據,查詢性能強,實時更新
- 雖然Delete+Insert在寫入性能有輕微損失,但總體上還是十分強悍
- Mysql協議,使用簡單
缺點:
- 目前版本在數據刪除上有一些限制,無法使用delete語句進行刪除,新版本中社區會增加此功能
實時更新場景總的來說有以下幾種方案:
- Merge on read :StarRocks 的聚合、Unique模型和Clickhouse的ReplacingMergeTree、AggregatingMergeTree都是用的此方案。此方案特點是append方式寫入性能好,但是查詢時需要合併多版本數據導致查詢性能不佳。適合數據查詢性能要求不高的實時分析場景。
- Copy on write :目前一些數據湖系統如hudi、iceberg都有copy on write 的方案現實,此方案原理是當有更新數據後,會合併新老數據並重寫一份新的文件替換掉老文件,查詢時無需做merge操作,所以查詢性能很好。帶來的問題是寫和數據合併的操作很重,所以此方案不適合實時性強的寫入場景。
- Delete and insert:此方案是upsert 方案,通過記憶體中的主鍵索引定位要更新的行,標記刪除然後插入。在犧牲了部分寫入性能的情況下,帶來查詢上數倍於Merge on read 的提升,同時也提升了併發性能。
實時更新在Olap領域一直是一個技術難點,以往的解決方案很難同時具備寫入性能好、讀取性能好、使用簡單這幾個特性。StarRocks的Delete and insert方式目前更接近於理想的方案,在讀寫方面都有很優秀的性能,支持Mysql協議使用上簡單友好。同時離線分析Udata也是用StarRocks完成,讓我們實現了實時離線分析一體化的目標。
3 後續方向
數據湖探索:批流一體已經成為今後發展的大趨勢,數據湖作為批流一體的存儲載體已經成為標準,我們以後大方向也必然是批流一體。目前批流一體中一個大痛點問題是沒有一種查詢引擎可以在數據湖上做極速查詢,後期我們會藉助SR打造在湖上的極速分析能力,讓批流一體不只停留在計算階段。
架構圖如下:
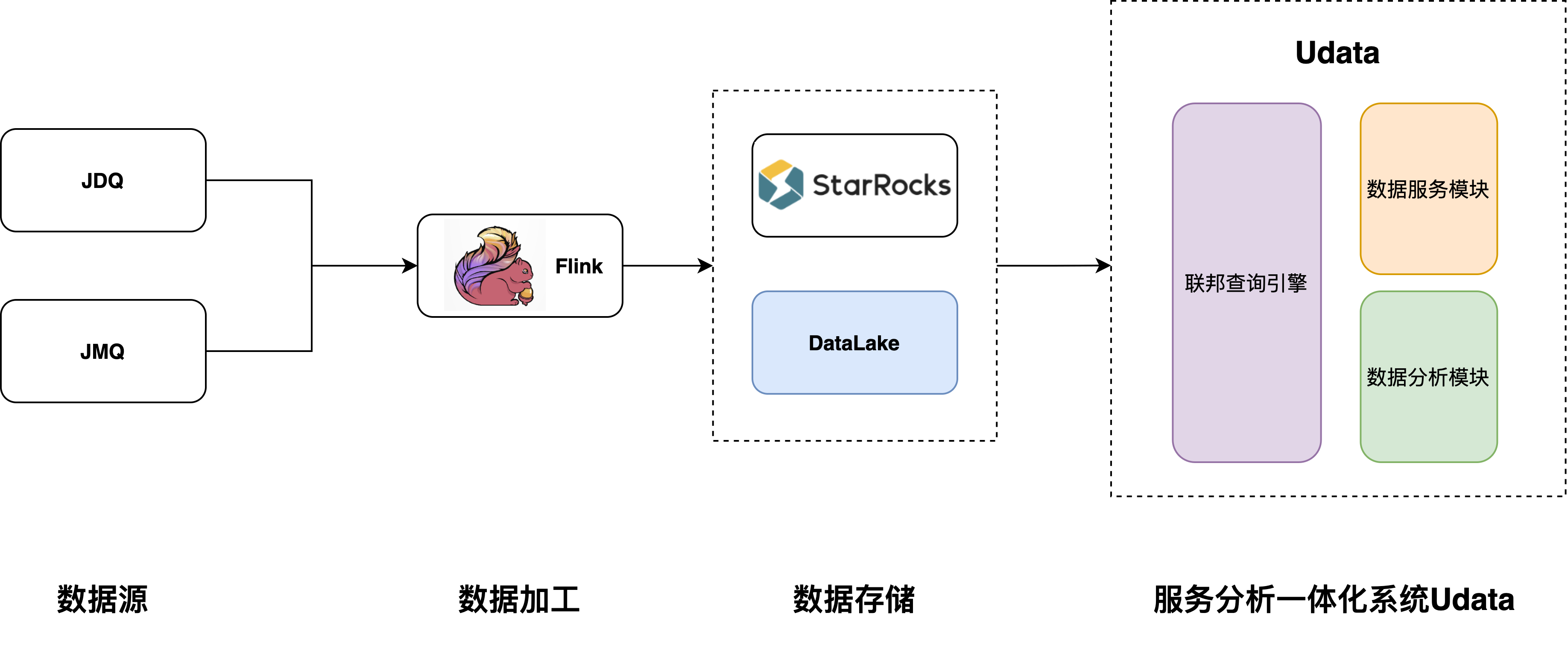
圖4 後期計劃架構圖
- 實時數據存儲統一:目前系統中還是有多套實時存儲方案,運維成本還是相當高,後期我們會逐步把ES、Clickhouse替換為StarRocks,在實時層做到存儲統一。我們也很期待StarRocks後期關於主鍵模型支持detele語句方式刪除數據的Feature,這個Feature可以簡化目前的數據清除問題。
- 支持更多的數據源:今後我們還會支持更多的數據源,如Redis、Hbase等kv類型的Nosql資料庫,增強SR的點查能力。
- StarRocks集群間的聯邦查詢:在實際生產中很難做到只用一個大集群,特別是當實時有大量實時寫入的情況,比較安全的做法是拆分不同的小集群,當一個集群出問題時不會影響其他業務。但是帶來的問題是,集群間可能又會變為數據孤島,即便把StarRocks偽裝成Mysql創建外表,但也需要工具去同步各個集群的表結構等信息,管理起來費時費力,後續我們也會和社區討論如何實現集群間的聯邦功能。
作者:京東物流 張棟 賀思遠
來源:京東雲開發者社區 自猿其說Tech 轉載請註明來源

