
前言 位元組跳動如果上市,那麼鐘老闆將成為我國第一個世界首富 趁著現在還沒上市,咱們提前學習一下用Python分析股票歷史數據,抱住粗大腿坐等起飛~ 好了話不多說,我們直接開始正文 準備工作 環境使用 Python 3.10 解釋器 Pycharm 編輯器 模塊使用 requests —> 數據請求模 ...
前言
位元組跳動如果上市,那麼鐘老闆將成為我國第一個世界首富

趁著現在還沒上市,咱們提前學習一下用Python分析股票歷史數據,抱住粗大腿坐等起飛~
好了話不多說,我們直接開始正文
準備工作
環境使用
- Python 3.10 解釋器
- Pycharm 編輯器
模塊使用
- requests —> 數據請求模塊
- csv -> 保存csv表格
- pandas -> 可以實現保存Excel表格文件
requests和pandas是第三方模塊,需要手動安裝,直接pip install 加上模塊名字即可。
案例實現流程
數據來源分析
- 明確需求: 明確採集的網站以及數據內容
- 網址: 雪球網
- 數據: 股票數據 - 抓包分析: 分析 股票數據, 可以請求那個網址能夠得到
- 打開開發者工具: F12 / 右鍵點擊檢查選擇 network (網路)
- 點擊第二頁數據
數據包: https://stock.xueqiu.com/v5/stock/screener/quote/list.json?page=2&size=30&order=desc&order_by=amount&exchange=CN&market=CN&type=sha
請求網址:
請求方式:
請求頭:
代碼實現步驟
- 發送請求 -> 模擬瀏覽器對於url發送請求
- 獲取數據 -> 獲取伺服器返迴響應數據 <整個數據>
- 解析數據 -> 提取我們需要數據
- 保存數據 -> 保存表格文件 < csv / Excel > 中
代碼解析
保存表格文件
- csv -> csv模塊
- Excel -> pandas模塊
# 創建文件對象 f = open('股票.csv', mode='w', encoding='utf-8', newline='') # fieldnames 欄位名 表頭一行數據 <前面保存字典的鍵> csv_writer= csv.DictWriter(f, fieldnames=[ '股票代碼', '股票名稱', '當前價', '漲跌額', '漲跌幅', '年初至今', '成交量', '成交額', '換手率', '市盈率(TTM)', '股息率', '市值', ]) # 寫入表頭 csv_writer.writeheader() # 創建一個空列表 content_list = [] # 源碼領取摳裙:815624229
發送請求
模擬瀏覽器對於url發送請求
- 模擬瀏覽器: headers 請求頭
- 從瀏覽器開發者工具中直接複製
- 字典數據類型, 構建完整鍵值對形式
- 請求網址:
從瀏覽器開發者工具中直接複製 - 發送請求:
需要requests模塊 -> pip install requests
<Response [200]> 響應對象 表示請求成功
# 模擬瀏覽器 headers = { 'Cookie': 's=av17ye9exq; xq_a_token=cf755d099237875c767cae1769959cee5a1fb37c; xq_r_token=e073320f4256c0234a620b59c446e458455626d9; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTcwMTk5NTg4MCwiY3RtIjoxNzAwNTYzOTE3MDU2LCJjaWQiOiJkOWQwbjRBWnVwIn0.EbAa9h0fB9H_sH415f3x8r2CQiKmPbXZMnuKCy401scB1lMQKOffws6WTwPD2UzFWnntYxIQYSJpX509VUYYgCQkZ_bYtLbtYd5PfxLhWx7coauYA4d3x5aZolzB3eP5IthaYAb0Kbj3MPK8LVRBhABpRGr4wajISuABFNezroM_-5dpiOYK7Rk0UXtU2Qhrzxi1BVCgFUhPP-oR_vKenBw5tLzSqa6aO7CukgI7JVb-6LiymuBquE8FE-de8Vs3evai0fvtjiqryrH3EWM3nmDQIayigHRrYo595bD32kUPP4swHF5U2fwbLHTntIRAm9LsXn8sVf-6sUdgHoYZGg; cookiesu=931700563933974; u=931700563933974; device_id=5da9e0ae658f9fcd3d89078312131fb7; Hm_lvt_1db88642e346389874251b5a1eded6e3=1700563934; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1700563934', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36' } for page in range(1, 58): print(f'==============正在採集第{page}頁數據內容==============') # 請求網址 url = f'https://stock.xueqiu.com/v5/stock/screener/quote/list.json?page={page}&size=30&order=desc&order_by=amount&exchange=CN&market=CN&type=sha' # 發送請求 response = requests.get(url=url, headers=headers)
獲取數據
獲取伺服器返迴響應數據 <整個數據>
- response.text 獲取響應文本數據 <字元串>
- response.json() 獲取響應json數據 <json數據 大部分情況字典數據>
- response.content 獲取響應二進位數據 <保存圖片/視頻/音頻/特定格式文件的時候>
解析數據
提取我們需要數據
解決數據方法根據獲取數據來選擇的:
字典取值方法 -> 鍵值對取值 (根據冒號左邊的內容[鍵], 提取冒號右邊的內容[值])
json_data = response.json() # 返回json字典數據 # for迴圈遍歷 for index in json_data['data']['list'][1:]: # 提取數據保存到字典裡面, 方便後續保存表格文件 dit = { '股票代碼': index['symbol'], '股票名稱': index['name'], '當前價': index['current'], '漲跌額': index['chg'], '漲跌幅': index['percent'], '年初至今': index['current_year_percent'], '成交量': index['volume'], '成交額': index['amount'], '換手率': index['turnover_rate'], '市盈率(TTM)': index['pe_ttm'], '股息率': index['dividend_yield'], '市值': index['market_capital'], } # 保存數據 csv_writer.writerow(dit) # 把字典添加到空列表裡面 content_list.append(dit) print(dit)
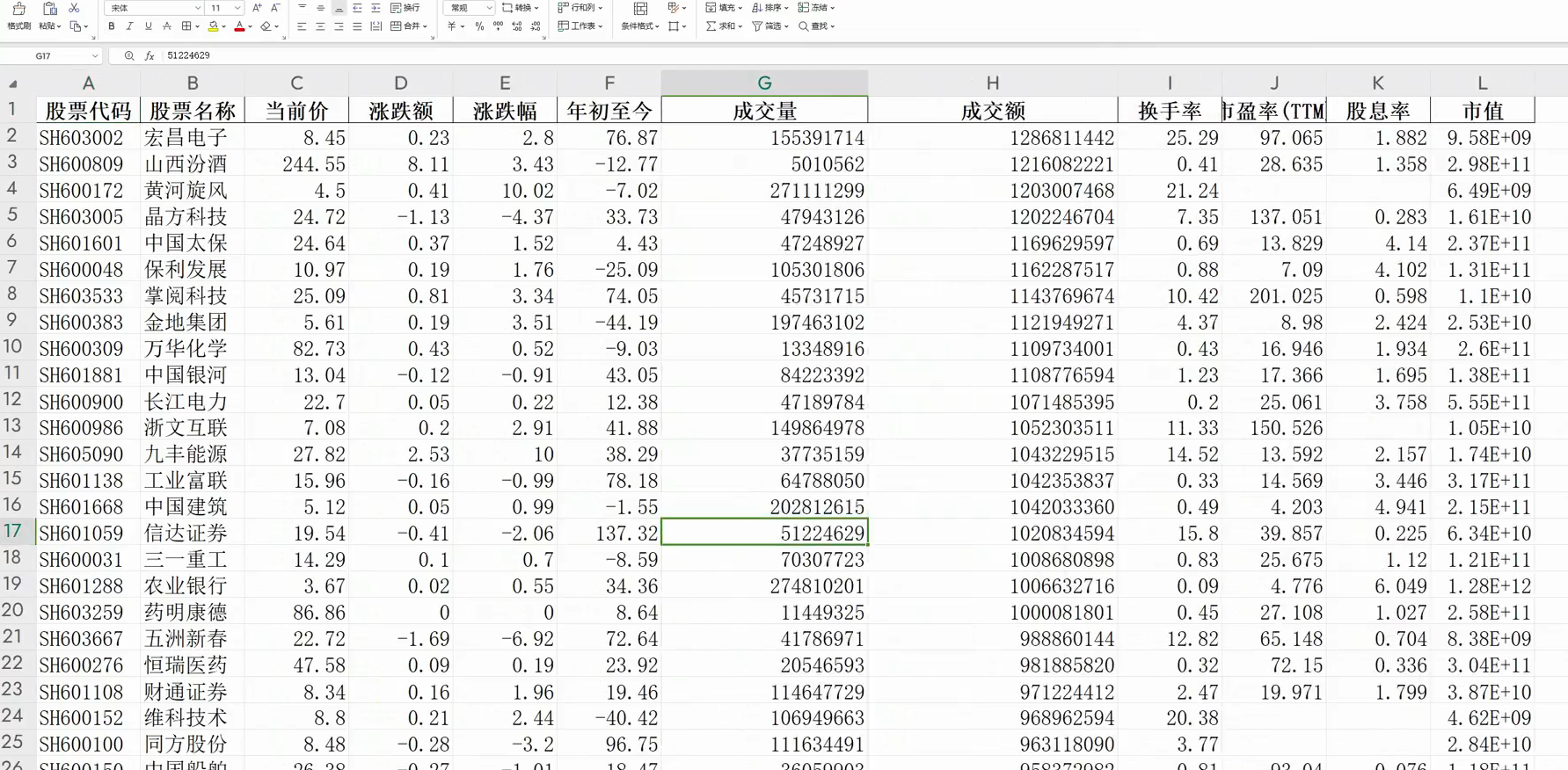
效果展示
獲取到數據保存到表格後

採集數據和可視化分析部分的代碼我都打包好了,下方源碼中自取。

可視化分析
import pandas as pd # 做表格數據處理模塊 第三方的 from pyecharts.charts import Bar # 可視化模塊 第三方模塊 from pyecharts import options as opts # 可視化模塊裡面的設置模塊(圖表樣式) # 1. 讀取數據 # 源碼領取+摳裙 815624229 df = pd.read_csv('股票.csv') x = list(df['股票名稱'].values) y = list(df['成交量'].values) c = ( Bar() .add_xaxis(x[:10]) .add_yaxis("成交額", y[:10]) .set_global_opts( xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)), title_opts=opts.TitleOpts(title="Bar-旋轉X軸標簽", subtitle="解決標簽名字過長的問題"), ) .render("成交量圖表.html") )
好了,今天的分享就到這結束了,下次見。


