
在分散式存儲系統中,數據需要分散存儲在多台設備上,數據分片(Sharding)就是用來確定數據在多台存儲設備上分佈的技術。本文主要介紹常見的數據分片方法,以及一致性哈希演算法的應用。 ...
在分散式存儲系統中,數據需要分散存儲在多台設備上,數據分片(Sharding)就是用來確定數據在多台存儲設備上分佈的技術。數據分片要達到三個目的:
- 分佈均勻,即每台設備上的數據量要儘可能相近;
- 負載均衡,即每台設備上的請求量要儘可能相近;
- 擴縮容時產生的數據遷移儘可能少。
數據分片方法
數據分片一般都是使用Key或Key的哈希值來計算Key的分佈,常見的幾種數據分片的方法如下:
- 劃分號段。這種一般適用於Key為整型的情況,每台設備上存放相同大小的號段區間,如把Key為[1, 10000]的數據放在第一臺設備上,把Key為[10001, 20000]的數據放在第二台設備上,依次類推。這種方法實現很簡單,擴容也比較方便,成倍增加設備即可,如原來有N台設備,再新增N台設備來擴容,把每台老設備上一半的數據遷移到新設備上,原來號段為[1, 10000]的設備,擴容後只保留號段[1, 5000]的數據,把號段為[5001, 10000]的數據遷移到一臺新增的設備上。此方法的缺點是數據可能分佈不均勻,如小號段數據量可能比大號段的數據量要大,同樣的各個號段的熱度也可能不一樣,導致各個設備的負載不均衡;並且擴容也不夠靈活,只能成倍地增加設備。
- 取模。這種方法先計算Key的哈希值,再對設備數量取模(整型的Key也可直接用Key取模),假設有N台設備,編號為0~N-1,通過Hash(Key)%N就可以確定數據所在的設備編號。這種方法實現也非常簡單,數據分佈和負載也會比較均勻,可以新增任何數量的設備來擴容。主要的問題是擴容的時候,會產生大量的數據遷移,比如從N台設備擴容到N+1台,絕大部分的數據都要在設備間進行遷移。
- 檢索表。在檢索表中存儲Key和設備的映射關係,通過查找檢索表就可以確定數據分佈,這裡的檢索表也可以比較靈活,可以對每個Key都存儲映射關係,也可結合號段劃分等方法來減小檢索表的容量。這樣可以做到數據均勻分佈、負載均衡和擴縮容數據遷移量少。缺點是需要存儲檢索表的空間可能比較大,並且為了保證擴縮容引起的數據遷移量比較少,確定映射關係的演算法也比較複雜。
- 一致性哈希。一致性哈希演算法(Consistent Hashing)在1997年由麻省理工學院提出的一種分散式哈希(DHT)實現演算法,設計目標是為瞭解決網際網路中的熱點(Hot Spot)問題,該方法的詳細介紹參考此處http://blog.csdn.net/sparkliang/article/details/5279393。一致性哈希的演算法簡單而巧妙,很容易做到數據均分佈,其單調性也保證了擴縮容的數據遷移是比較少的。
通過上面的對比,在這個系統選擇一致性哈希的方法來進行數據分片。
虛擬伺服器
為了讓系統有更好的擴展性,這裡提出存儲層VServer(虛擬伺服器)的概念,一個VServer是一個邏輯上的存儲伺服器,是分散式存儲系統的一個存儲單元,一臺物理設備上可以部署多個VServer,一個VServer支持一個寫進程和多個讀進程。
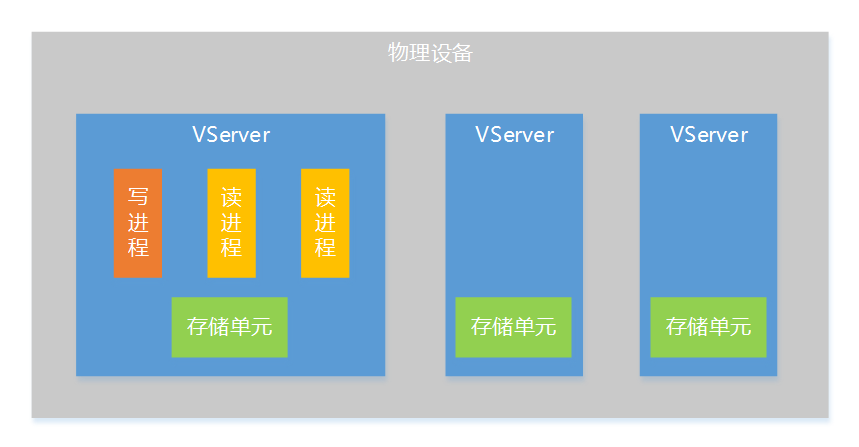
通過VServer的方式,會有下麵一些好處:
- 提高單機性能。為了不引入複雜的鎖機制,採用了單寫進程的設計,如果單機只有一個寫進程,寫併發能力會受到限制,通過VServer方式把單機上的存儲資源(記憶體、硬碟)劃分為多個存儲單元,這樣就支持多個寫進程同時工作,大大提升單機寫併發能力。
- 部署擴展性更好。VServer的方式在部署上非常靈活,可以根據單機的資源情況來確定VServer的數量,針對不同的機型配置不同的VServer數量,這樣不同的機型都能充分利用機器上的資源,即使在一個系統中使用多種機型,也能做到機器的負載比較均衡。
一致性哈希的應用
數據分片是在介面層實現的,目的是把數據均勻地劃分到不同的VServer上。有了介面層的存在,邏輯層定址就輕量了很多,定址存儲層VServer的工作全部由介面層負責,邏輯層只需要隨機選一個介面層機器訪問即可。
介面層使用了一致性哈希的割環演算法來實現數據分片,在割環演算法中,為了讓數據均勻分佈到各個VServer,每個VServer需要有多個VNode(虛擬節點)。一個Key定址的過程如下圖所示,首先根據Hash(Key)在哈希環上找到對應的VNode,在根據VNode和VServer的映射表確定所屬的VServer。
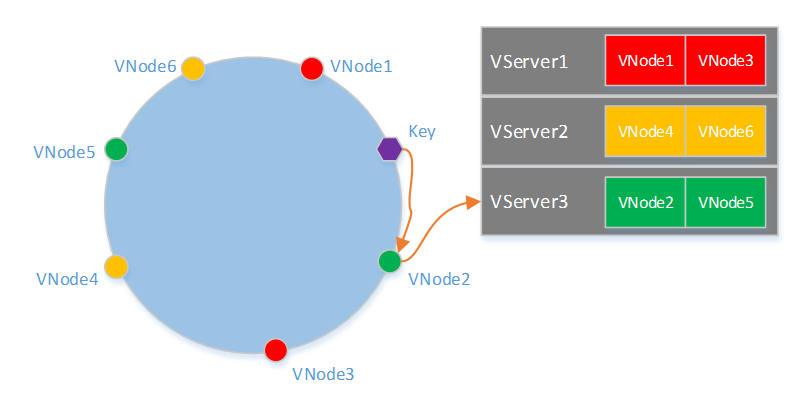
由上述查找過程可知,需要事先離線計算出VNode在哈希環上的分佈、VServer和VNode映射關係。為了是計算結果具有通用性,即在擁有任何數量VServer的一個系統都可以使用該結果得到一致性哈希的映射表,這就要求結果是與機器無關的,比如不能使用IP來計算VNode的哈希值。在計算前需要確定每個VServer包含的VNode數量,以及一個系統所支持的最大VServer數量。一個簡單的方法是類似上文鏈接中提到的方法,但不能和IP相關,可以改用VServer和VNode的編號來計算哈希值,如Hash("1#1"),Hash("1#2")… 這種方法要求一個VServer包含的VNode的數量比較多,大概需要500個才能使各個VServer上的數據比較均勻。當然還有其他的一些方法做到一個VServer上包含更少的VNode數量,並且讓數據分佈偏差在一定範圍內。
Google提出了一種新的一致性哈希演算法Jump Consistent Hash,此演算法零記憶體消耗,均勻分配,快速,並且只有5行代碼,優勢非常明顯,詳細介紹見此處http://my.oschina.net/u/658658/blog/424161。和上面介紹的方法相比,一個最大的不同點是,在擴容重新分佈數據時,在上面的方法中,新機器的一個VNode上的數據只會來自一個老機器上的VNode,而這種方法是會來自所有老機器上的VNode。這個問題可能會導致一些設計上複雜化,所以使用的時候要慎重考慮。


