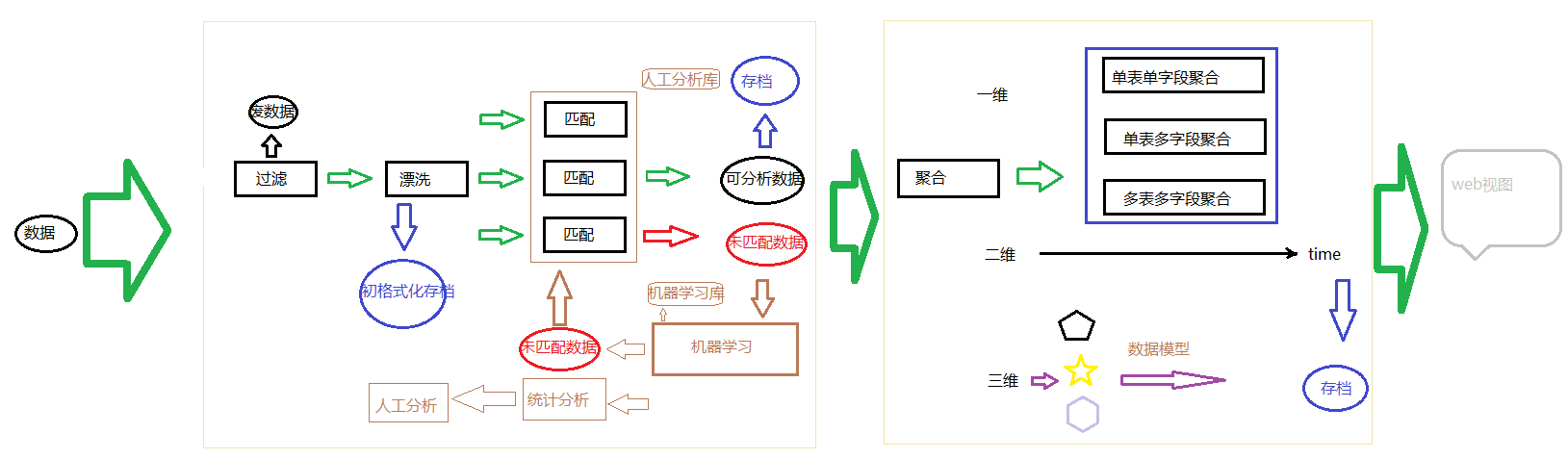
數據處理過程分為數據挖掘和數據分析,廣義上說數據分析泛指整個過程,然而數據分析大的流程大致相同,如圖: 數據挖掘一般都要經過過濾、漂洗、匹配三個過程: 1.過濾:主要將數據中的不適合分析的數據過濾掉,就好比產品流水線的殘次品一樣,對數據進行組粒度的過濾,其規則可按數據大小,字元長短; 2.漂洗:也稱 ...
數據處理過程分為數據挖掘和數據分析,廣義上說數據分析泛指整個過程,然而數據分析大的流程大致相同,如圖:
數據挖掘一般都要經過過濾、漂洗、匹配三個過程:
1.過濾:主要將數據中的不適合分析的數據過濾掉,就好比產品流水線的殘次品一樣,對數據進行組粒度的過濾,其規則可按數據大小,字元長短;
2.漂洗:也稱格式化,對數據進行分塊,數據也有組成的,有時間、數據源、數據體等等,就好比頭、身體、腳一樣。將數據變成我們想要的格式,此過程也是打標簽的過程,意將數據分類處理。
3.匹配:匹配就是抽取欄位,將數據中的有用的地方抽取出來。(正則處理)由於數據的分類太多,無法完成所有的數據的匹配,這就需要機器自動識別。註意機器學習的結果並不精準,是故數據分開存儲。
數據挖掘的過程也就是無格式數據和半格式化數據的格式化過程,換言之就是講數據規則化。
數據挖掘過程結束後,就是數據分析階段,其過程如圖:

數據分析就是sql聚合操作,將數據格式化就是為了能夠用sql語言去處理數據,換句話說就是,想怎麼分析就怎麼分析,只要你會操作資料庫。
然而數據分析也有多層面的:按照維度劃分為一維、二維、三維分析。
一維分析主要基於表查詢,多個欄位、單個欄位、topN、分組等等的聚合函數
二維分析主要基於時間,為什麼這麼說呢,基於時間的分析就會複雜,多與預測有關係(預測那肯定不能人想,得機器想)
三維分析主要基於對象,對象怎麼說,是將數據模型化,數據模型化就好比Java類一樣,構造虛擬實體,基於實體的分析。
上述維度基於上一維度來說的。
有沒有四維、五維,有木肯定有木,舉個運維的例子:
例子:伺服器運行情況
伺服器A 2016-07-09 12:00:00 CPU:90% Mem:90%
應用程式A 2016-07-09 12:00:00 CPU:40% Mem:40% (men>60%才能正常運行)
應用程式B 2016-07-09 12:00:00 CPU:40% Mem:40% (men>30%才能正常運行)
伺服器A系統 2016-07-09 12:00:00 CPU:10% Mem:10%
所以應用程式A就會運行不正常
整個數據處理流程的完整流程圖: