
通過javascript進行UTF 8編碼 javascript的字元集: javascript程式是使用 字元集編寫的。 是`ASCII Latin 1 ECMAScript3 Unicode2.1 ECMAScript5 Unicode3`及後續版本。所以,我們編寫出來的javascript程式 ...
通過javascript進行UTF-8編碼
javascript的字元集:
javascript程式是使用Unicode字元集編寫的。Unicode是ASCII和Latin-1的超集,並支持地球上幾乎所有的語言。ECMAScript3要求JavaScript必須支持Unicode2.1及後續版本,ECMAScript5則要求支持Unicode3及後續版本。所以,我們編寫出來的javascript程式,都是使用Unicode編碼的。
UTF-8
UTF-8(UTF8-bit Unicode Transformation Format)是一種針對Unicode的可變長度字元編碼,也是一種首碼碼。
它可以用來表示Unicode標準中的任何字元,且其編碼中的第一個位元組仍與ASCII相容,這使得原來處理ASCII字元的軟體無須或只須做少部分修改,即可繼續使用。因此,它逐漸成為電子郵件、網頁及其他存儲或發送文字的應用中,優先採用的編碼。
目前大部分的網站,都是使用的UTF-8編碼。
將javascript生成的Unicode編碼字元串轉為UTF-8編碼的字元串
如標題所說的應用場景十分常見,例如發送一段二進位到伺服器時,伺服器規定該二進位內容的編碼必須為UTF-8。這種情況下,我們必須就要通過程式將javascript的Unicode字元串轉為UTF-8編碼的字元串。
轉換方法
轉換之前我們必須瞭解Unicode的編碼結構是固定的。
不信可以試一試 String 的 charCodeAt 這個方法,看看返回的 charCode 占幾個位元組。
- 英文占1個字元,漢字占2個字元
然而,UTF-8的編碼結構長度是根據某單個字元的大小來決定長度有多少。
下麵為單個字元的大小占用幾個位元組。單個unicode字元編碼之後的最大長度為6個位元組。
- 1個位元組:Unicode碼為0 - 127
- 2個位元組:Unicode碼為128 - 2047
- 3個位元組:Unicode碼為2048 - 0xFFFF
- 4個位元組:Unicode碼為65536 - 0x1FFFFF
- 5個位元組:Unicode碼為0x200000 - 0x3FFFFFF
- 6個位元組:Unicode碼為0x4000000 - 0x7FFFFFFF
具體請看圖片:
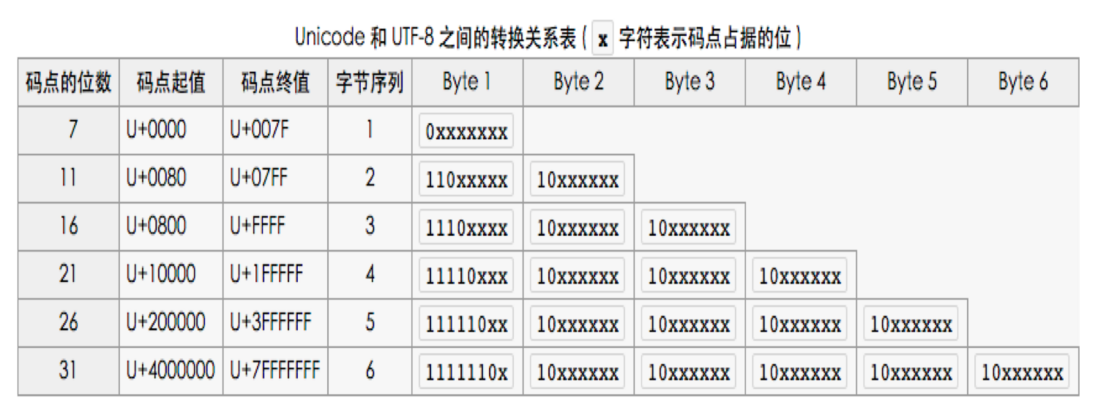
因為英文和英文字元的Unicode碼為0 - 127,所以英文在Unicode和UTF-8中的長度和位元組都是一致的,只占用1個位元組。這也就是為什麼UTF8是Unicode的超集!
現在我們再來討論漢字,因為漢字的unicode碼區間為0x2e80 - 0x9fff, 所以漢字在UTF8中的長度最長為3個位元組。
那麼漢字是如何從Unicode的2個位元組轉換為UTF8的三個位元組的哪?
假設我需要把漢字"中"轉為UTF-8的編碼
1、獲取漢字Unicode值大小
var str = '中';
var charCode = str.charCodeAt(0);
console.log(charCode); // => 200132、根據大小判斷UTF8的長度
由上一步我們得到漢字"中"的charCode為20013.然後我們發現20013位於2048 - 0xFFFF這個區間里,所以漢字"中"應該在UTF8中占3個位元組。
3、補碼
既然知道漢字"中"需要占3個位元組,那麼這3個位元組如何得到哪?
這就需要設計到補碼,具體補碼邏輯如下:
好吧,我知道這個圖你們也看不明白,還是我來講吧!
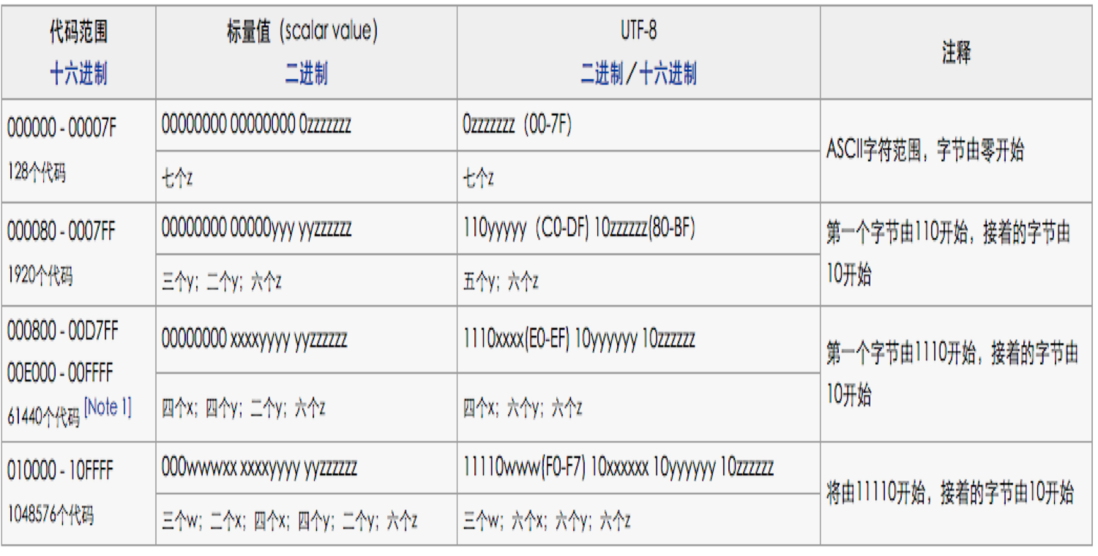
具體的補位碼如下,"x"表示空位,用來補位的。
- 0xxxxxxx
- 110xxxxx 10xxxxxx
- 1110xxxx 10xxxxxx 10xxxxxx
- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
- 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
- 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
warning:有沒有發現?補位碼第一個位元組前面有幾個1就表示整個UTF-8編碼占多少個位元組!UTF-8解碼為Unicode就是利用的這個特點哦~
我們先舉個簡單的例子。把英文字母"A"轉為UTF8編碼。
1、“A”的charCode為65
2、65位於0-127的區間,所以“A”占一個位元組
3、UTF8中一個位元組的補位為0xxxxxxx,x表示的是空位,是用來補位的。
4、將65轉為二進位得到1000001
5、將1000001按照從前到後的順序,依次補到1xxxxxxx的空位中,得到01000001
6、將11000001轉為字元串,得到"A"
7、最終,"A"為UTF8編碼之後“A”
通過這個小例子,我們是否再次驗證了UTF-8是Unicode的超集!
好了,我們現在再回到漢字"中"上,之前我們已經得到了"中"的charCode為20013,二進位為01001110 00101101。具體如下:
var code = 20013;
code.toString(2);
// => 100111000101101 等同於 01001110 00101101然後,我們按照上面“A”補位的方法,來給"中"補位。
將01001110 00101101按照從前到後的順序依此補位到1110xxxx 10xxxxxx 10xxxxxx上.得到11100100 10111000 10101101.
4、得到UTF8編碼的內容
通過上面的步驟,我們得到了"中"的三個UTF8位元組,11100100 10111000 10101101。
我們將每個位元組轉為16進位,得到0xE4 0xB8 0xAD;
那麼這個0xE4 0xB8 0xAD就是我們最終得到的UTF8編碼了。
我們使用nodejs的buffer來驗證一下是否正確。
var buffer = new Buffer('中');
console.log(buffer.length); // => 3
console.log(buffer); // => <Buffer e4 b8 ad>
// 最終得到三個位元組 0xe4 0xb8 0xad因為16進位是不分大小寫的,所以是不是跟我們算出來0xE4 0xB8 0xAD一模一樣。
將上面的編碼邏輯寫到一個函數中。
// 將字元串格式化為UTF8編碼的位元組
var writeUTF = function (str, isGetBytes) {
var back = [];
var byteSize = 0;
for (var i = 0; i < str.length; i++) {
var code = str.charCodeAt(i);
if (0x00 <= code && code <= 0x7f) {
byteSize += 1;
back.push(code);
} else if (0x80 <= code && code <= 0x7ff) {
byteSize += 2;
back.push((192 | (31 & (code >> 6))));
back.push((128 | (63 & code)))
} else if ((0x800 <= code && code <= 0xd7ff)
|| (0xe000 <= code && code <= 0xffff)) {
byteSize += 3;
back.push((224 | (15 & (code >> 12))));
back.push((128 | (63 & (code >> 6))));
back.push((128 | (63 & code)))
}
}
for (i = 0; i < back.length; i++) {
back[i] &= 0xff;
}
if (isGetBytes) {
return back
}
if (byteSize <= 0xff) {
return [0, byteSize].concat(back);
} else {
return [byteSize >> 8, byteSize & 0xff].concat(back);
}
}
writeUTF('中'); // => [0, 3, 228, 184, 173]
// 前兩位表示後面utf8位元組的長度。因為長度為3,所以前兩個位元組為`0,3`
// 內容為`228, 184, 173`轉成16進位就是`0xE4 0xB8 0xAD`// 讀取UTF8編碼的位元組,並專為Unicode的字元串
var readUTF = function (arr) {
if (typeof arr === 'string') {
return arr;
}
var UTF = '', _arr = this.init(arr);
for (var i = 0; i < _arr.length; i++) {
var one = _arr[i].toString(2),
v = one.match(/^1+?(?=0)/);
if (v && one.length == 8) {
var bytesLength = v[0].length;
var store = _arr[i].toString(2).slice(7 - bytesLength);
for (var st = 1; st < bytesLength; st++) {
store += _arr[st + i].toString(2).slice(2)
}
UTF += String.fromCharCode(parseInt(store, 2));
i += bytesLength - 1
} else {
UTF += String.fromCharCode(_arr[i])
}
}
return UTF
}
readUTF([0, 3, 228, 184, 173]); => '中'另外一種將中文解析得到UTF8位元組碼的方法
另外一種比較簡單的將中文轉為UTF8位元組碼的方法比較簡單,瀏覽器也提供了一個方法,而且這個方法大家都一直在用,是什麼哪?就是encodeURI。當然,encodeURIComponent也是可以的。
沒錯,就是這個方法。那麼這個方法是怎麼將一個Unicode編碼的中文轉為UTF8的位元組碼嘞?
var str = '中';
var code = encodeURI(str);
console.log(code); // => %E4%B8%AD有沒有發現得到了一個轉義後的字元串,而且這個字元串中的內容和我之前在上面得到的位元組碼是一樣的~~~。
下麵我們將%E4%B8%AD轉為一個number數組。
var codeList = code.split('%');
codeList = codeList.map(item => parseInt(item,16));
console.log(codeList); // => [228, 184, 173]如此簡單,有木有~~~
這個簡便方法的原理是什麼?
這裡就涉及到的URI中的querystring編碼的問題了。因為按照規定,URI中的querystring必須按照UTF8的編碼進行傳輸,而JavaScript是Unicode的,所以瀏覽器就給我們提供了一個方法,也就是encodeURI/encodeURIComponent方法。這個方法會講非英文字元(這裡考慮下,為什麼是非英文字元?)先轉為UTF8的位元組碼,然後前面加個%進行拼接,所以我們將漢字"中"轉義下便得到了"%E4%B8%AD".
好吧,原理就這些,沒有其他的了。
不過,這種方法還有個缺點,那就是只會轉義非英文字元,所以當我們需要將英文字元也格式化為UTF8編碼時,這個方法是達不到我們需求的,我們還需要額外的將英文字元也給轉義下。
那我想要解析回來應該怎麼做哪?用decodeURI/decodeURIComponent就可以了。
var codeList = [228, 184, 173];
var code = codeList.map(item => '%'+item.toString(16)).join('');
decodeURI(code); // => 中好了,到這裡本文也就介紹完UTF8的編碼了。
希望可以幫助大家瞭解到UTF-8編碼的原理。


