
本文介紹基於Python語言,按照一定命名規則批量修改多個文件的文件名的方法。 已知現有一個文件夾,其中包括班級所有同學上交的作業文件,每人一份;所有作業文件命名格式統一,都是地信1701_姓名_學習心得格式。 現需要對每一位同學的作業文件加以改名,有很多種需求。 第一種需求,將每一位同學作業文件名 ...
本文介紹基於Python語言,按照一定命名規則批量修改多個文件的文件名的方法。
已知現有一個文件夾,其中包括班級所有同學上交的作業文件,每人一份;所有作業文件命名格式統一,都是地信1701_姓名_學習心得格式。
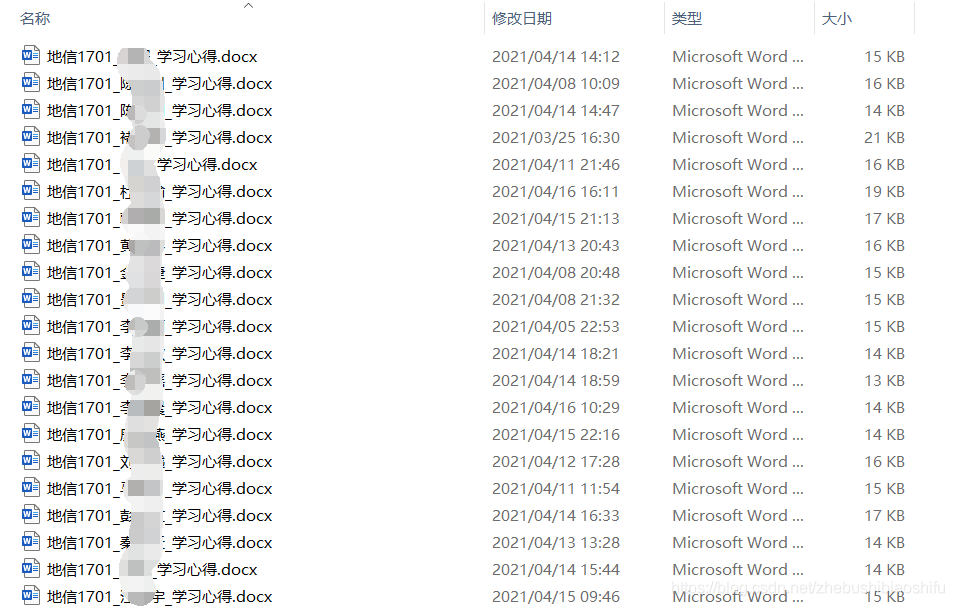
現需要對每一位同學的作業文件加以改名,有很多種需求。
第一種需求,將每一位同學作業文件名中原本是姓名的部分,都修改為學號。即原本的地信1701_姓名_學習心得修改為地信1701_學號_學習心得(每一位同學有且僅有一個學號,且相互不重覆,且姓名與學號的對應關係我們是已知的),如下圖所示。
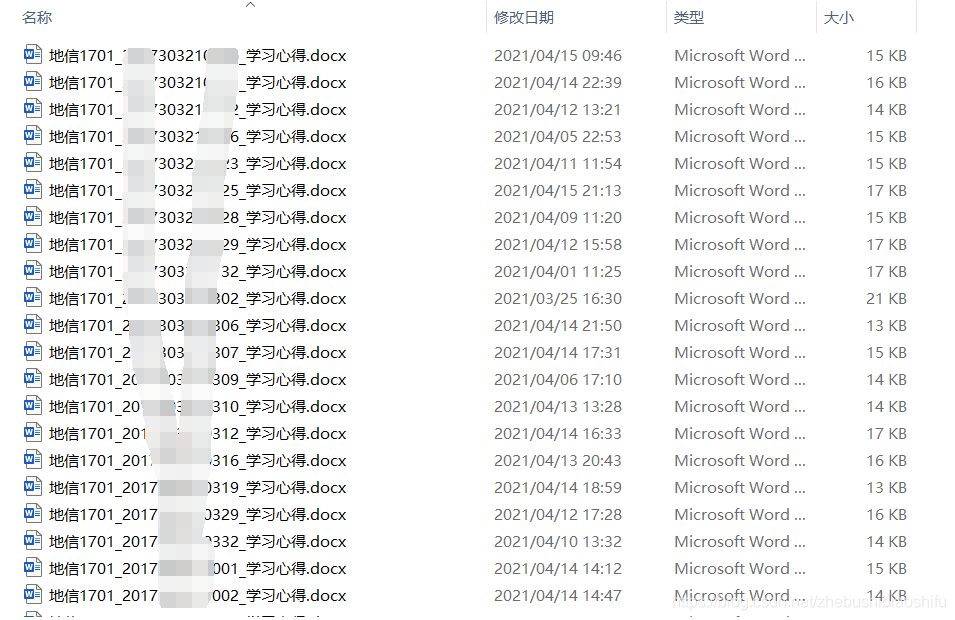
第二種需求,將每一位同學作業文件名中原本姓名的部分的後面,都添加上學號。即原本的地信1701_姓名_學習心得修改為地信1701_姓名_學號_學習心得,如下圖所示。
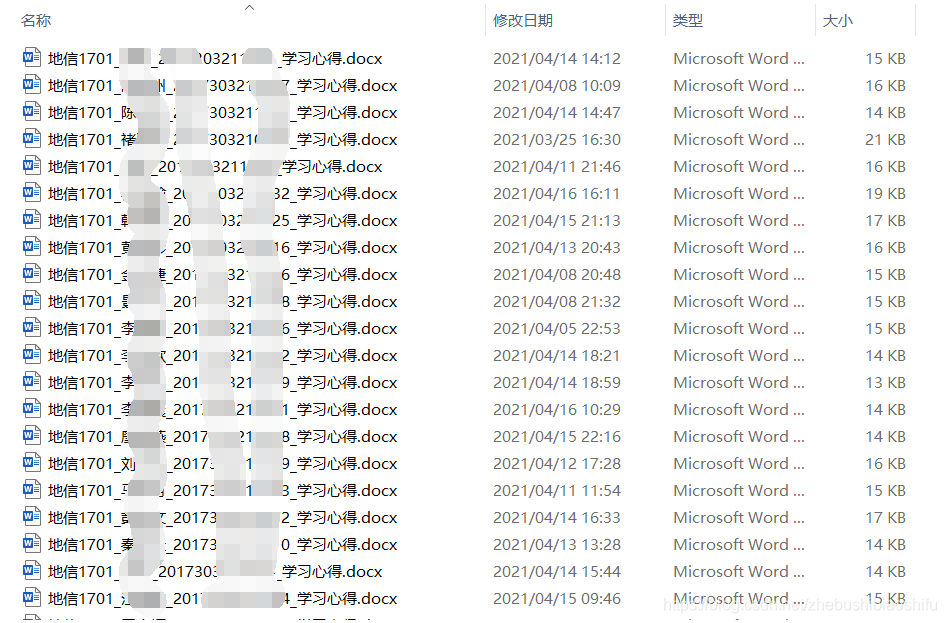
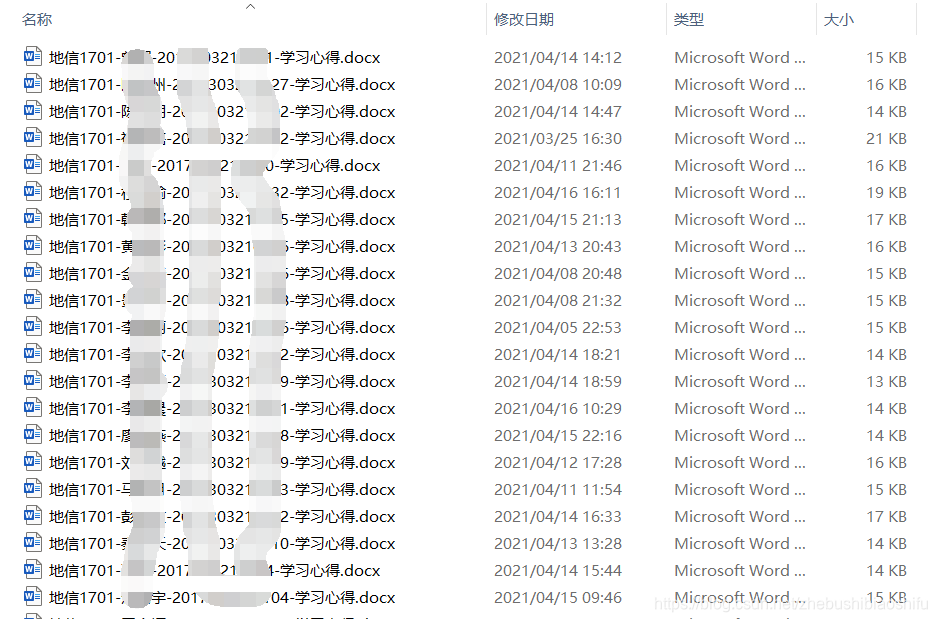
第三種需求,將每一位同學滿足第二種需求後的作業文件名中的下劃線_部分,都修改為連接符-。即原本的地信1701_姓名_學號_學習心得修改為地信1701-姓名-學號-學習心得,如下圖所示。
好了,知道了需求我們就可以開始進行代碼的編寫了。
首先,導入必要的庫。
import os
from openpyxl import load_workbook
接下來,我們首先需要讓程式知道每一位同學的姓名與學號之間的對應關係。因為我們已知姓名與學號之間的關係,因此首先需要類似於下圖的表格,其中為姓名與學號的一一對應關係。
接下來,我們需要將上述表格中的內容在Python中以字典的格式存儲。具體代碼如下,關於這一部分代碼的解釋大家查看Python導入Excel表格數據並以字典dict格式保存即可,此處就不再贅述。
original_path='F:/學習/2020-2021-2/形勢與政策(二)/論文與學習心得/01_學習心得/地信1701-學習心得/'
look_up_table_path='F:/學習/2020-2021-2/形勢與政策(二)/論文與學習心得/01_學習心得/Name_Number.xlsx'
look_up_table_row_start=2
look_up_table_row_number=32
name_number_dict={}
look_up_table_excel=load_workbook(look_up_table_path)
look_up_table_all_sheet=look_up_table_excel.get_sheet_names()
look_up_table_sheet=look_up_table_excel.get_sheet_by_name(look_up_table_all_sheet[0])
for i in range(look_up_table_row_start,look_up_table_row_start+look_up_table_row_number):
number=look_up_table_sheet.cell(i,1).value
name=look_up_table_sheet.cell(i,2).value
name_number_dict[number]=name
接下來,進行第一種需求的代碼實現。
# Replacement Renaming
all_word=os.listdir(original_path)
for i in range(len(all_word)):
old_name=all_word[i]
old_name_name_end=old_name.rfind('_')
old_name_name=old_name[7:old_name_name_end]
new_name_number=[k for k, v in name_number_dict.items() if v==old_name_name]
new_name=old_name.replace(old_name_name,''.join(str(w) for w in new_name_number))
os.rename(original_path+old_name,original_path+new_name)
其中,由於大家的姓名有兩個字、三個字或者更多字,因此我們使用了old_name_name_end獲取原有文件名稱中姓名最後一個字所在的下標;而姓名開始的位置是確定的,即從而確定了每一位同學姓名在原有文件名中的起始與終止下標位置。同時利用replace,依據同學的姓名,在字典中搜索該同學的學號,最後將同學的名字替換為其對應的學號。
其次,是第二種需求。
# Additional Renaming
all_word=os.listdir(original_path)
for i in range(len(all_word)):
old_name=all_word[i]
old_name_name_end=old_name.rfind('_')
old_name_name=old_name[7:old_name_name_end]
new_name_number=[k for k, v in name_number_dict.items() if v==old_name_name]
old_name_list=list(old_name)
insert_number=''.join(str(w) for w in new_name_number)+'_'
old_name_list.insert(old_name_name_end+1,insert_number)
new_name=''.join(old_name_list)
os.rename(original_path+old_name,original_path+new_name)
在這裡,同樣使用old_name_name_end獲取原有文件名稱中姓名最後一個字所在的下標,從而確定了每一位同學姓名在原有文件名中的起始與終止下標位置。此外,利用insert,將學號這一項插入到原有的文件名稱中。
最後,是第三種需求。
# Modified Renaming
all_word=os.listdir(original_path)
for i in range(len(all_word)):
old_name=all_word[i]
new_name=old_name.replace('_',"-",3)
os.rename(original_path+old_name,original_path+new_name)
這個就簡單很多了,直接利用replace,用連接符-替換掉原有的下劃線_即可。
至此,大功告成。

