
一、std::string 的底層實現 1、深拷貝 1 class String{ 2 public: 3 String(const String &rhs):m_pstr(new char[strlen(rhs) + 1]()){ 4 } 5 private: 6 char* m_pstr; 7 ...
初識MapReduce
一、什麼是MapReduce
MapReduce是一種編程範式,它藉助Map將一個大任務分解成多個小任務,再藉助Reduce歸併Map的結果。MapReduce雖然原理很簡單,但是使用MapReduce設計出一個解決問題的應用卻不是一件簡單的事情。下麵通過一個簡單的小例子來介紹MapReduce。
二、使用MapReduce尋找銷售人員業績最大值
《Hadoop權威指南》的例子是尋找天氣最大值,需要去下載數據。但是我們並不需要完全復刻他的場景,所以這裡用了另外一個例子。假設有一批銷售日誌數據文件,它的一部分是這樣的。
66$2021-01-01$5555
67$2021-01-01$5635
每一行代表某一位銷售人員某個日期的銷售數量,具體格式為
銷售用戶id$統計日期$銷售數量
我們需要尋找每一個銷售用戶的銷售最大值是多少。需要說明的是,這裡僅僅是舉一個很簡單的示例,便於學習MapReduce。
1、數據解析器
我首先寫了一個解析器來識別每一行的文本,它的作用是將每一行文本轉換為數據實體,數據實體這裡偷了個懶,欄位全部設置成了public。代碼片段如下:
/**
* 銷售數據解釋器
* 銷售數據格式為
* userId$countDate(yyyy-MM-dd)$saleCount
*/
public class SaleDataParse implements TextParse<SaleDataEntity> {
@Override
public SaleDataEntity parse(String text) {
if (text == null) {
return null;
}
text = text.trim();
if (text.isEmpty()) {
return null;
}
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
String[] split = text.split("\\$");
SaleDataEntity data = new SaleDataEntity();
data.userId = Long.valueOf(split[0]);
data.countDate = sdf.parse(split[1], new ParsePosition(0));
data.saleCount = Integer.valueOf(split[2]);
return data;
}
}
/**
* 銷售數據實體
*/
public class SaleDataEntity {
/**
* 銷售用戶id
*/
public Long userId;
/**
* 銷售日期
*/
public Date countDate;
/**
* 銷售總數
*/
public Integer saleCount;
}
2、Map函數
Mapper是一個泛型類,它需要4個泛型參數,從左到右分別是輸入鍵、輸入值、輸出鍵和輸出值。也就是這樣
Mapper<輸入鍵, 輸入值, 輸出鍵, 輸出值>
其中輸入鍵和輸入值的格式是由InputFormatClass決定的,關於輸入格式的討論之後會展開討論。MapReduce預設會把文件按行拆分,然後偏移量(輸入鍵)->行文本(輸入值)的映射傳遞給Mapper的map方法。輸出鍵和輸出值則由用戶進行指定。
這裡由於是找每一個用戶的最大銷售數量,Mapper的功能是接收並解析每行數據。所以輸出鍵我設成了銷售人員id->銷售數量的映射。所以實際的Mapper實現看起來像這樣:
/**
* 解析輸入的文本數據
*/
public class MaxSaleMapper extends Mapper<LongWritable, Text, LongWritable, IntWritable> {
protected TextParse<SaleDataEntity> saleDataParse = new SaleDataParse();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String s = value.toString();
SaleDataEntity data = saleDataParse.parse(s);
if (data != null) {
//寫入輸出給Reducer
context.write(new LongWritable(data.userId), new IntWritable(data.saleCount));
}
}
}
其中LongWritable相當於java里的long,Text相當於java里的String,IntWritable相當於java里的int。
這裡你可能會想到,既然已經解析成了數據實體,為什麼不直接把實體設置成輸出值?因為map函數和reduce函數不一定運行在同一個進程里,所以會涉及到序列化和反序列化,這裡先不展開。
3、Reduce函數
Reducer也是一個泛型類,它也需要4個參數,從左到右分別是輸入鍵、輸入值、輸出鍵和輸出值。也就是這樣
Reducer<輸入鍵, 輸入值, 輸出鍵, 輸出值>
與Mapper不同的是,輸入鍵和輸入值來源於Mapper的輸出,也就是Mapper實現中的context.write()。
輸出鍵和輸出值也是由用戶指定,預設的輸出會寫到文件中,關於Reducer的輸出以後會討論。
Reducer的功能是尋找每個用戶的最大值,所以Reducer的實現看起來像這樣:
/**
* 查找每一個用戶的最大銷售值
*/
public class MaxSaleReducer extends Reducer<LongWritable, IntWritable, LongWritable, IntWritable> {
@Override
protected void reduce(LongWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int max = 0;
for (IntWritable value : values) {
if (value.get() > max) {
max = value.get();
}
}
context.write(key, new IntWritable(max));
}
}
你可能會奇怪,為什麼reduce方法的第二個參數是一個迭代器。簡單來說,Mapper會把映射的值進行歸併,然後再傳遞給Reducer。
4、驅動程式
我們已經完成了map和reduce函數的實現,現在我們需要把它們組裝起來。我們需要寫一個Main類,它看起來像這樣
public class MaxSale {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance();
job.setJarByClass(MaxSale.class);
job.setJobName("MaxSale");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxSaleMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(MaxSaleReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//設置Reduce任務數
job.setNumReduceTasks(1);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
這裡解釋一下
- 首先我們創建了一個Job
- 然後設置輸入目錄和輸出目錄,它們分別是FileInputFormat.addInputPath和FileOutputFormat.setOutputPath
- 使用setMapperClass設置了map函數,setMapOutputKeyClass設置了map函數的輸入鍵類型,setMapOutputValueClass設置了輸出鍵類型
- 使用setReducerClass設置了reduce函數,setOutputKeyClass設置了輸出鍵類型,setOutputValueClass設置了輸出值類型
- 然後使用setNumReduceTasks設置reduce任務個數為1,每個reduce任務都會輸出一個文件,這裡是為了方便查看
- 最後job.waitForCompletion(true)啟動並等待任務結束
5、運行結果
使用maven package打包,會生成一個jar,我生成的名字是maxSaleMapReduce-1.0-SNAPSHOT.jar。如果打包的jar有除了Hadoop的其他依賴,需要設置一下HADOOP_CLASSPATH,然後把依賴放到HADOOP_CLASSPATH目錄中。
最後輸入啟動命令,格式為:hadoop jar 生成的jar.jar 輸入數據目錄 輸出數據目錄。這裡給出我使用的命令示例:
Windows:
set HADOOP_CLASSPATH=C:\xxxxxxxxx\lib\*
hadoop jar maxSaleMapReduce-1.0-SNAPSHOT.jar input output
然後你會看到程式有如下輸出,這裡截取的部分:
23/01/18 12:10:29 INFO mapred.MapTask: Starting flush of map output
23/01/18 12:10:29 INFO mapred.MapTask: Spilling map output
23/01/18 12:10:29 INFO mapred.MapTask: bufstart = 0; bufend = 17677320; bufvoid = 104857600
23/01/18 12:10:29 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 20321960(81287840); length = 5892437/6553600
23/01/18 12:10:30 INFO mapred.MapTask: Finished spill 0
23/01/18 12:10:30 INFO mapred.Task: Task:attempt_local1909247000_0001_m_000000_0 is done. And is in the process of committing
23/01/18 12:10:30 INFO mapred.LocalJobRunner: map
23/01/18 12:10:30 INFO mapred.Task: Task 'attempt_local1909247000_0001_m_000000_0' done.
23/01/18 12:10:30 INFO mapred.Task: Final Counters for attempt_local1909247000_0001_m_000000_0: Counters: 17
File System Counters
FILE: Number of bytes read=33569210
FILE: Number of bytes written=21132276
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=1473110
Map output records=1473110
Map output bytes=17677320
Map output materialized bytes=20623546
Input split bytes=122
Combine input records=0
Spilled Records=1473110
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=36
Total committed heap usage (bytes)=268435456
File Input Format Counters
Bytes Read=33558528
23/01/18 12:10:30 INFO mapred.LocalJobRunner: Finishing task: attempt_local1909247000_0001_m_000000_0
23/01/18 12:10:30 INFO mapred.LocalJobRunner: Starting task: attempt_local1909247000_0001_m_000001_0
23/01/18 12:10:30 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
23/01/18 12:10:30 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false
等待程式執行結束,output文件夾會有輸出part-r-00000,文件里每一行是每一個用戶的id和他銷售最大值。
0 9994
1 9975
2 9987
3 9985
4 9978
5 9998
三、MapReduce執行流程
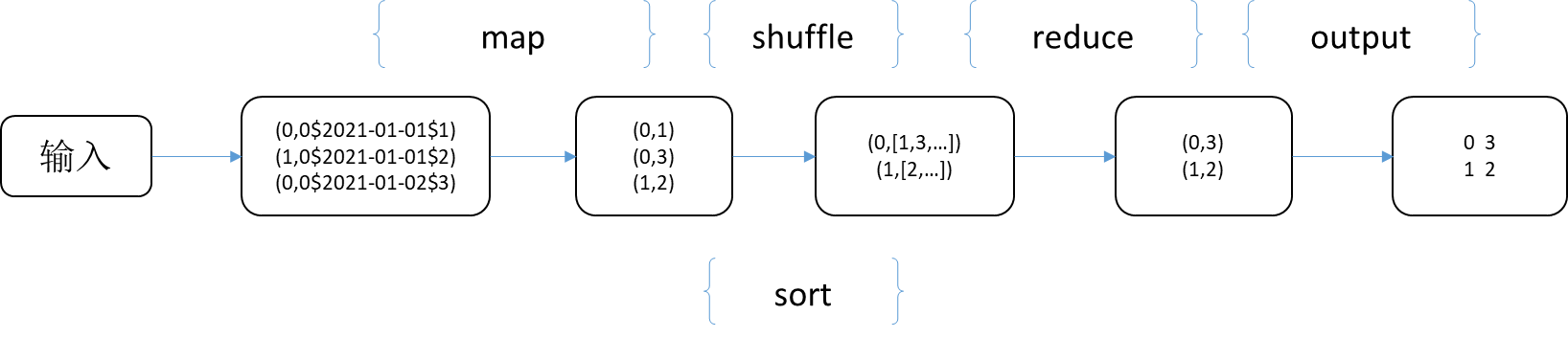
簡單分析一下這個示常式度的執行流程:
- 首先輸入文件被按行切分,輸入到各個maper
- maper的輸出按輸出鍵進行分類,經過shuffle操作後輸入到reducer
- reducer收到maper的輸出後,執行尋找最大值操作,然後輸出
- 輸出會被預設的輸出格式格式化後輸出到文件part-r-00000中
四、示例代碼說明
本文所有的代碼放在我的github上,地址是:https://github.com/xunpengliu/hello-hadoop
下麵是項目目錄說明:
- maxSaleMapReduce模塊是Map函數和Reduce的實現,這個模塊依賴common模塊。所以運行的時候需要把common模塊生成的jar添加到HADOOP_CLASSPATH中
- common模塊是公共模塊,裡面有一個SaleDataGenerator的數據生成器,可以生成本次示例代碼使用的生成數據
最後需要說明的是,項目代碼主要用於學習,代碼風格並非代表本人實際風格,不完善之處請輕噴。
五、常見問題
-
java.lang.RuntimeException: java.io.FileNotFoundException: Could not locate Hadoop executable: xxxxxxxxxxxx\bin\winutils.exe -see https://wiki.apache.org/hadoop/WindowsProblems
這個是因為沒有下載winutils.exe和hadoop.dll,具體可以參考《安裝一個最小化的Hadoop》中windows額外說明
-
運行出現異常java.lang.NullPointerException
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1012)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:482)
at org.apache.hadoop.util.Shell.run(Shell.java:455)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:702) ......
這個和問題1類似,Hadoop在Windows需要winutils.exe和hadoop.dll訪問文件,這兩個文件通過org.apache.hadoop.util.Shell#getQualifiedBinPath這個方法獲取,而這個方法又依賴Hadoop的安裝目錄。
設置HADOOP_HOME環境變數,或者傳入系統參數hadoop.home.dir為Hadoop程式目錄,具體參見《安裝一個最小化的Hadoop》


