
摘要:本文主要介紹 Presto 如何更好的利用 Hudi 的數據佈局、索引信息來加速點查性能。 本文分享自華為雲社區《華為雲基於 Apache Hudi 極致查詢優化的探索實踐!》,作者:FI_mengtao。 背景 湖倉一體(LakeHouse)是一種新的開放式架構,它結合了數據湖和數據倉庫的最 ...
摘要:本文主要介紹 Presto 如何更好的利用 Hudi 的數據佈局、索引信息來加速點查性能。
本文分享自華為雲社區《華為雲基於 Apache Hudi 極致查詢優化的探索實踐!》,作者:FI_mengtao。
背景
湖倉一體(LakeHouse)是一種新的開放式架構,它結合了數據湖和數據倉庫的最佳元素,是當下大數據領域的重要發展方向。
華為雲早在2020年就開始著手相關技術的預研,並落地在華為雲 FusionInsight MRS智能數據湖解決方案中。
目前主流的三大數據湖組件 Apache Hudi、Iceberg、Delta各有優點,業界也在不斷探索選擇適合自己的方案。
華為湖倉一體架構核心基座是 Apache Hudi,所有入湖數據都通過 Apache Hudi 承載,對外通過 HetuEngine(Presto增強版)引擎承擔一站式SQL分析角色,因此如何更好的結合 Presto 和 Hudi 使其查詢效率接近專業的分散式數倉意義重大。查詢性能優化是個很大的課題,包括索引、數據佈局、預聚合、統計信息、引擎 Runtime優化等等。本文主要介紹 Presto 如何更好的利用 Hudi 的數據佈局、索引信息來加速點查性能。預聚合和統計信息我們將在後續分享。
數據佈局優化
大數據分析的點查場景一般都會帶有過濾條件,對於這種類型查詢,如果目標結果集很小,理論上我們可以通過一定手段在讀取表數據時大量跳過不相干數據,只讀取很小的數據集,進而顯著的提升查詢效率。我們可以把上述技術稱之為 DataSkipping。
好的數據佈局可以使相關數據更加緊湊(當然小文件問題也一併處理掉了)是實現 DataSkipping的關鍵一步。日常工作中合理設置分區欄位、數據排序都屬於數據佈局優化。當前主流的查詢引擎 Presto/Spark 都可以對Parquet文件做 Rowgroup 級別過濾,最新版本甚至支持 Page 級別的過濾;選取合適的數據佈局方式可以使引擎在讀取上述文件可以利用列的統計信息輕易過濾掉大量 Rowgroup/Page,進而減少IO。
那麼是不是 DataSkipping僅僅依賴數據佈局就好了?其實不然。上述過濾還是要打開表裡每一個文件才能完成過濾,因此過濾效果有限,數據佈局優化配合 FileSkipping才能更好的發揮效果。
當我們完成數據佈局後,對每個文件的相關列收集統計信息,下圖給個簡單的示例,數據經過排序後寫入表中生成三個文件,指定點查 where a < 10 下圖可以清楚的看出 a < 10的結果集只存在於 parquet1文件中,parquet2/parquet3 中 a 的最小值都比10大,顯然不可能存在結果集,所以直接裁剪掉 parquet2和 parquet3即可。

這就是一個簡單 FileSkipping,FileSkipping的目的在於盡最大可能裁剪掉不需要的文件,減少掃描IO,實現 FileSkipping有很多種方式,例如
min-max統計信息過濾、BloomFilter、Bitmap、二級索引等等,每種方式都各有優缺點,其中 min-max 統計信息過濾最為常見,也是 Hudi/Iceberg/DeltaLake 預設提供的實現方式。
Apache Hudi核心能力
Clustering
Hudi早在 0.7.0 版本就已經提供了 Clustering 優化數據佈局,0.10.0 版本隨著 Z-Order/Hilbert高階聚類演算法加入,Hudi的數據佈局優化日趨強大,Hudi 當前提供以下三種不同的聚類方式,針對不同的點查場景,可以根據具體的過濾條件選擇不同的策略

關於 Z-Order、Hilbert 具體原理可以查閱相關Wiki,https://en.wikipedia.org/wiki/Z-order 本文不再詳細贅述。
Metadata Table(MDT)
Metadata Table(MDT):Hudi的元數據信息表,是一個自管理的 Hudi MoR表,位於 Hudi 表的 .hoodie目錄,開啟後用戶無感知。同樣的 Hudi 很早就支持 MDT,經過不斷迭代 0.12版本 MDT 已經成熟,當前 MDT 表已經具備如下能力
(1)Column_stats/Bloomfilter
上文我們介紹了數據佈局優化,接下來說說 Hudi 提供的 FileSkipping能力。當前 Hudi 支持對指定列收集包括min-max value,null count,total count 在內的統計信息,並且 Hudi 保證這些信息收集是原子性,利用這些統計信息結合查詢引擎可以很好的完成 FileSkipping大幅度減少IO。BloomFilter是 Hudi 提供的另一種能力,當前只支持對主鍵構建 BloomFilter。BloomFilter判斷不存在就一定不存在的特性,可以很方便進行 FileSkipping,我們可以將查詢條件直接作用到每個文件的 BloomFilter 上,進而過濾點無效的文件,註意 BloomFilter 只適合等值過濾條件例如where a = 10,對於 a > 10這種就無能為力。
(2)高性能FileList
在查詢超大規模數據集時,FileList是不可避免的操作,在 HDFS 上該操作耗時還可以接受,一旦涉及到對象存儲,大規模 FileList 效率極其低下,Hudi 引入 MDT 將文件信息直接保存在下來,從而避免了大規模FileList。
Presto 與 Hudi的集成
HetuEngine(Presto)作為數據湖對外出口引擎,其查詢 Hudi 能力至關重要。對接這塊我們主要針對點查和複雜查詢做了不同的優化,下文著重介紹點查場景。在和 Hudi 集成之前首先要解決如下問題
- 如何集成 Hudi,在 Hive Connector 直接魔改,還是使用獨立的 Hudi Connector?
- 支持哪些索引做 DataSkipping?
- DataSkipping 在 Coordinator 側做還是在 Worker 端做?
問題1: 經過探討我們決定使用 Hudi Connector承載本次優化。當前社區的 Connector 還略優不足,缺失一些優化包括統計信息、Runtime Filter、Filter不能下推等導致 TPC-DS 性能不是很理想,我們在本次優化中重點優化了這塊,後續相關優化會推給社區。
問題2: 內部 HetuEngine 其實已經支持 Bitmap 和二級索引,本次重點集成了 MDT 的 Column statistics和 BloomFilter 能力,利用 Presto下推的 Filter 直接裁剪文件。
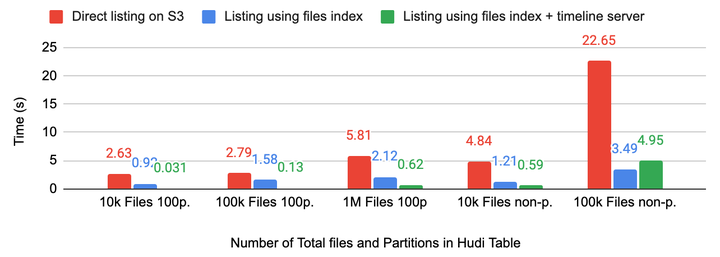
問題3: 關於這個問題我們做了測試,對於 column 統計信息來說,總體數據量並不大,1w 個文件統計信息大約幾M,載入到 Coordinator 記憶體完全沒有問題,因此選擇在 Coordinator 側直接做過濾。
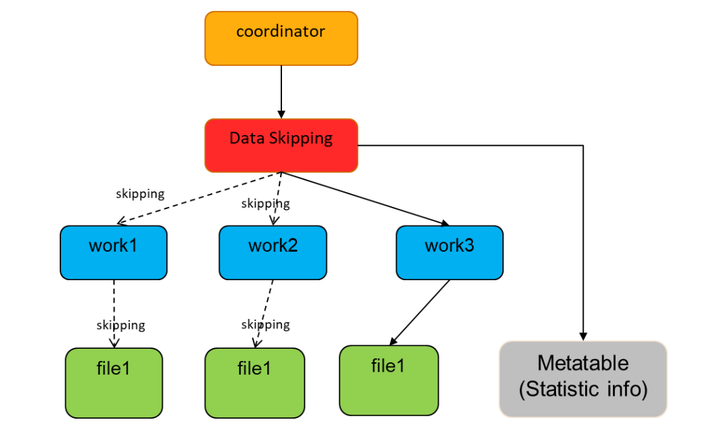
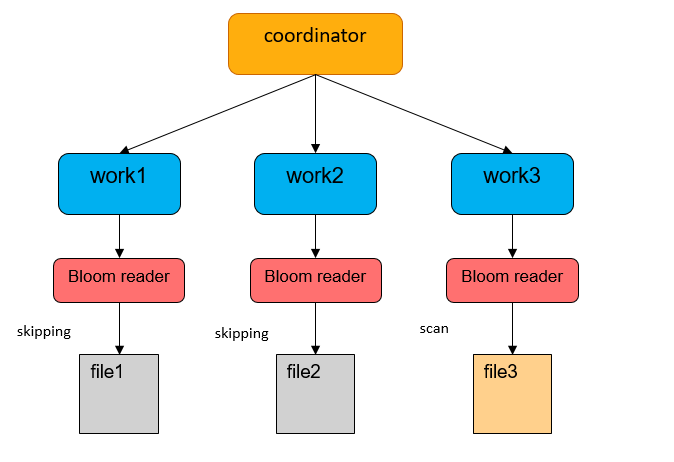
對於 BloomFilter、Bitmap 就完全不一樣了,測試結果表明 1.4T 數據產生了 1G 多的 BloomFilter 索引,把這些索引載入到 Coordinator 顯然不現實。我們知道 Hudi MDT 的 BloomFilter 實際是存在 HFile里,HFile點查十分高效,因此我們將 DataSkipping 下壓到 Worker 端,每個 Task 點查 HFile 查出自己的 BloomFilter 信息做過濾。
點查場景測試
測試數據
我們採用和 ClickHouse 一樣的SSB數據集進行測試,數據規模1.5T,120億條數據。
$ ./dbgen -s 2000 -T c $ ./dbgen -s 2000 -T l $ ./dbgen -s 2000 -T p $ ./dbgen -s 2000 -T s
測試環境
1CN+3WN Container 170GB,136GB JVM heap, 95GB Max Query Memory,40vcore
數據處理
利用 Hudi 自帶的 Hilbert 演算法直接預處理數據後寫入目標表,這裡 Hilbert 演算法指定 S_CITY,C_CITY,P_BRAND, LO_DISCOUNT作為排序列。
SpaceCurveSortingHelper .orderDataFrameBySamplingValues(df.withColumn("year", expr("year((LO_ORDERDATE))")), LayoutOptimizationStrategy.HILBERT, Seq("S_CITY", "C_CITY", "P_BRAND", "LO_DISCOUNT"), 9000) .registerTempTable("hilbert") spark.sql("insert into lineorder_flat_parquet_hilbert select * from hilbert")
測試結果
使用冷啟動方式,降低 Presto 緩存對性能的影響。
SSB Query
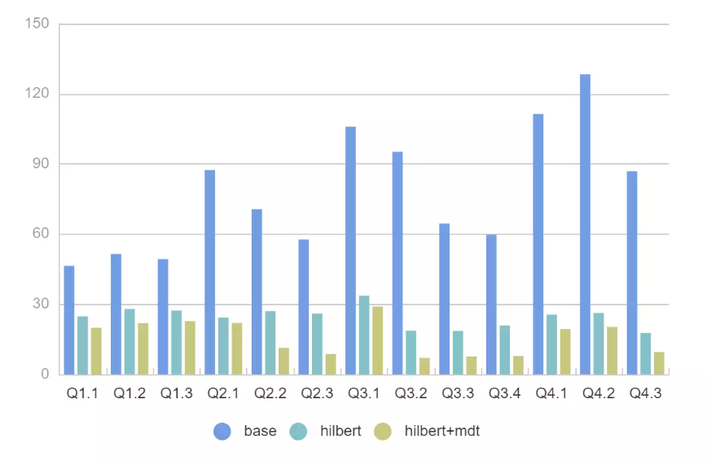
文件讀取量
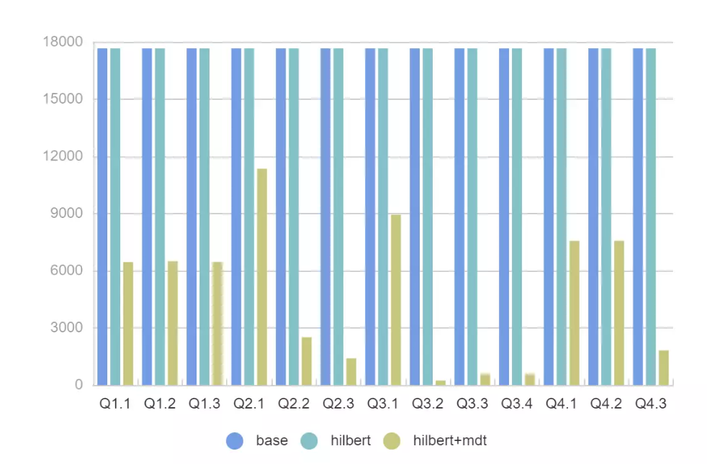
- 對於所有 SQL 我們可以看到 2x - 11x 的性能提升, FileSkipping 效果更加明顯過濾掉的文件有 2x - 200x 的提升。
- 即使沒有 MDT ,Presto 強大的 Rowgroup 級別過濾,配合 Hilbert 數據佈局優化也可以很好地提升查詢性能。
- SSB模型掃描的列數據都比較少, 實際場景中如果掃描多個列 Presto + MDT+ Hilbert 的性能可以達到 30x 以上。
- 測試中同樣發現了MDT的不足,120億數據產生的MDT表有接近50M,載入到記憶體裡面需要一定耗時,後續考慮給MDT配置緩存檔加快讀取效率。
關於 BloomFilter 的測試,由於 Hudi 只支持對主鍵構建 BloomFilter,因此我們構造了1000w 數據集做測試
spark.sql( """ |create table prestoc( |c1 int, |c11 int, |c12 int, |c2 string, |c3 decimal(38, 10), |c4 timestamp, |c5 int, |c6 date, |c7 binary, |c8 int |) using hudi |tblproperties ( |primaryKey = 'c1', |preCombineField = 'c11', |hoodie.upsert.shuffle.parallelism = 8, |hoodie.table.keygenerator.class = 'org.apache.hudi.keygen.SimpleKeyGenerator', |hoodie.metadata.enable = "true", |hoodie.metadata.index.column.stats.enable = "true", |hoodie.metadata.index.column.stats.file.group.count = "2", |hoodie.metadata.index.column.stats.column.list = 'c1,c2', |hoodie.metadata.index.bloom.filter.enable = "true", |hoodie.metadata.index.bloom.filter.column.list = 'c1', |hoodie.enable.data.skipping = "true", |hoodie.cleaner.policy.failed.writes = "LAZY", |hoodie.clean.automatic = "false", |hoodie.metadata.compact.max.delta.commits = "1" |) | |""".stripMargin)
最終一共產生了8個文件,結合 BloomFilter Skipping掉了7 個,效果非常明顯。
後續工作
後續關於點查這塊工作會重點關註 Bitmap 以及二級索引。最後總結一下 DataSkipping 中各種優化技術手段的選擇方式。
- Clustering中各種排序方式需要結合 Column statistics 才能達到更好的效果。
- BloomFilter 適合等值條件點查,不需要數據做排序, 但是要選擇高基欄位,低基欄位 BloomFIlter 用處不大;另外超高基也不要選 BloomFilter,產出的 BloomFilter 結果太大。

