一、本地數據集上傳到到數據倉庫Hive 1、 實驗數據集的下載 1. 將user.zip下載到指定目錄 2.給hadoop用戶賦予針對bigdatacase目錄的各種操作許可權 3.創建一個dataset目錄用於保存數據集 4.解壓縮user.zip文件 5.可以看到dataset目錄下由兩個文件 6 ...
一、本地數據集上傳到到數據倉庫Hive
1、 實驗數據集的下載
1. 將user.zip下載到指定目錄

2.給hadoop用戶賦予針對bigdatacase目錄的各種操作許可權

3.創建一個dataset目錄用於保存數據集

4.解壓縮user.zip文件
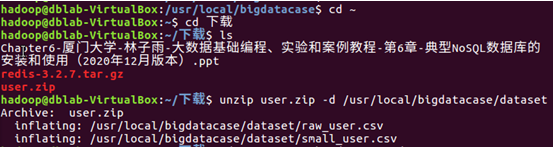
5.可以看到dataset目錄下由兩個文件

6.查看文件前五條記錄

2、 數據集的預處理
1. 刪除文件第一行記錄(即欄位名稱)
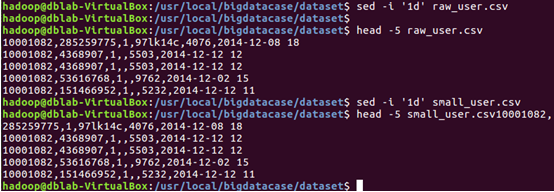
2. 對欄位進行預處理
1)新建一個腳本文件pre_deal.sh並放在dataset目錄下

2)在pre_deal.sh下麵加入以下代碼
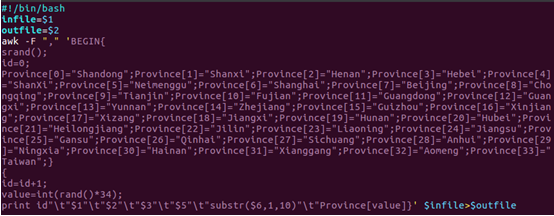
3)執行pre_deal.sh腳本文件,對small_user.csv進行數據預處理操作

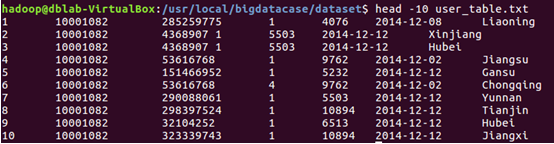
4)用head命令查看前10行數據
3、 導入資料庫
1. 啟動hdfs
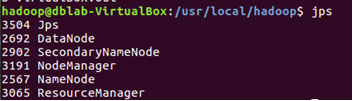
執行jps命令查看當前運行的進程
2.把user_table.txt上傳到hadoop中
1)在hdfs根目錄下創建新目錄

2)把本地文件系統中的user_table.txt上傳到hdfs系統的目錄下

3)查看HDFS中的user_table.txt的前10條記錄
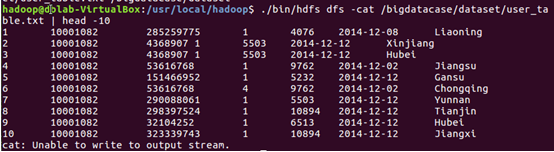
3. 在Hive上創建數據
1)啟動MySQL資料庫

2)進入hive
3)在Hive中創建一個資料庫dblab

4. 創建外部表

5. 查詢數據
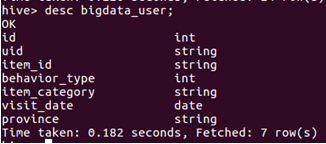
1)查看bigdata_user表的信息

2)查看表的簡單結構
3)查詢相關數據
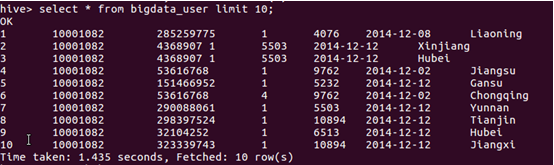
二、 Hive數據分析
1、 簡單查詢分析
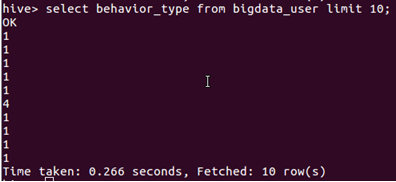
1. 查看前10位用戶對商品的行為
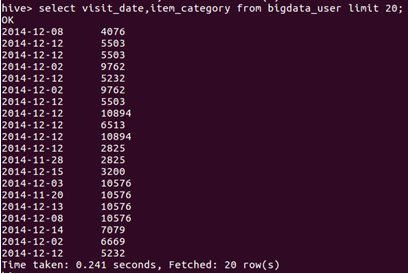
2.查詢前20位用戶購買商品時的時間和商品的種類
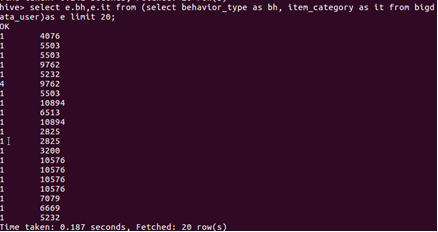
3.設置列的別名
2、 查詢條數統計分析
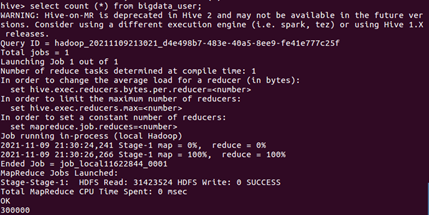
1.用聚合函數count()計算出表內由多少行數據
2.在函數內部加上distinct,查出uid不重覆的數據由多少條
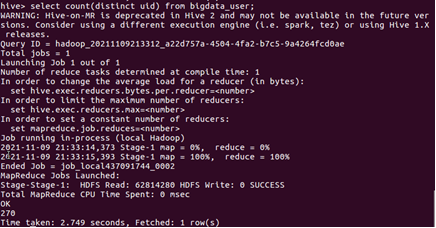
3.查詢不重覆的數據有多少條(為了排除客戶刷單情況)
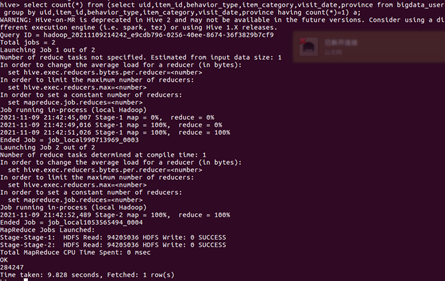
3、關鍵字條件查詢分析
1.以關鍵字的存在區間為條件的查詢
(1)查詢2014年12月10日到2014年12月13日有多少人瀏覽了商品

執行結果:

(2)以月的第n天為統計單位,依次顯示第n天網站賣出去的商品的個數。

執行結果:

2.關鍵字賦予定值為條件,對其他數據進行分析
取給定時間和給定地點,求當天發出到該地點的貨物的數量。

執行結果:

4、 根據用戶行為分析
1.查詢一件商品在某天的購買比例

執行結果:

查詢一件商品在某天的瀏覽比例

執行結果:

2.查詢某個用戶在某一天點擊網站占該天所有點擊行為的比例




3.給定購物商品的數量範圍,查詢某一天在該網站的購買該數量商品的用戶id


5、 用戶實時查詢分析
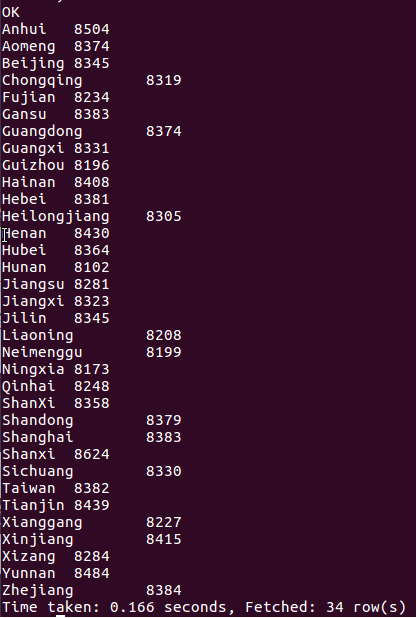
查詢某個地區的用戶當天瀏覽網站的次數,語句如下:
創建新的數據表進行存儲

導入數據

顯示結果
執行結果如下:
三、 Hive、MySQL、HBase數據互導
1、 Hive預操作
1.創建臨時表user_action
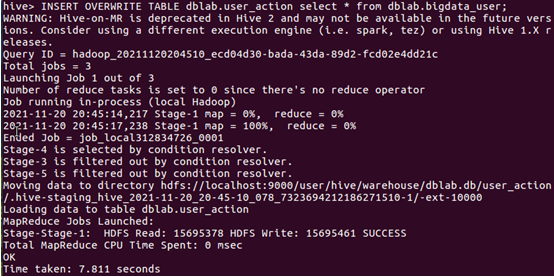
查看是否創建成功
2.將bigdata_user表中的數據插入到user_action
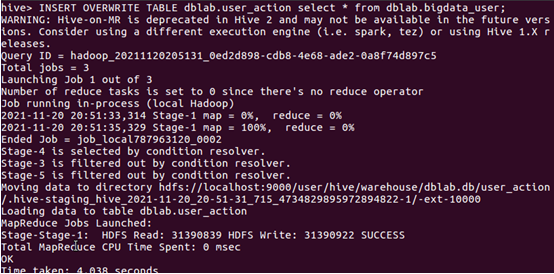
查看是否插入成功

2、 使用Sqoop將數據從Hive導入MySQL
1.將前面生成的臨時表數據從Hive導入到MySQL中
1)、登錄MySQL
新建終端,執行以下命令
2)、創建資料庫
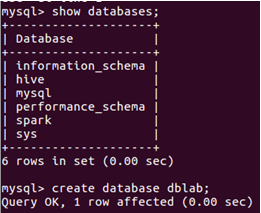
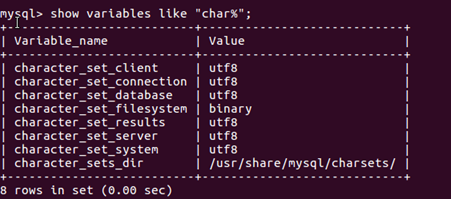
使用以下命令查看資料庫編碼是否utf8
3)創建表
在MySQL資料庫中dblab中創建一個新表user_action,並設置編碼為utf8

Exit
查看是否創建成功

4)導入數據

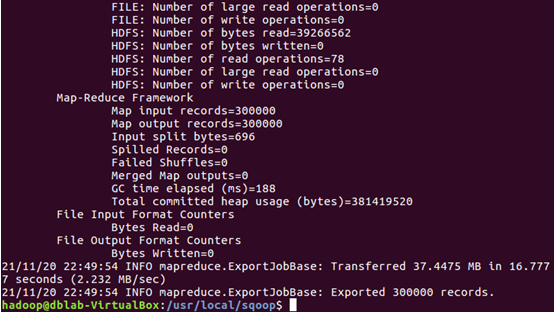
2.查看MySQL中的user_action表數據
啟動MySQL資料庫
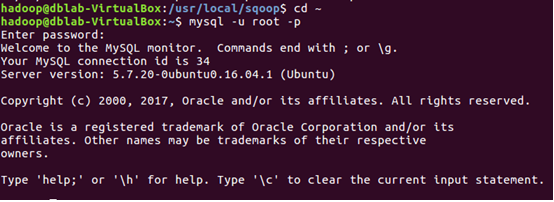
執行命令查詢user_action表中的數據

3、使用sqoop將數據從MySQL導入HBase
1.啟動Hadoop、MySQL、HBase
因為前面的操作所以除了HBase以外都啟動了,故此次啟動HBase,新建一個終端
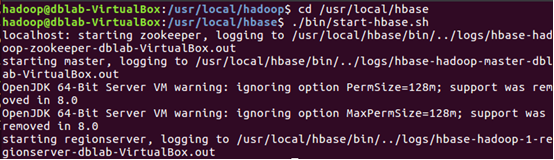
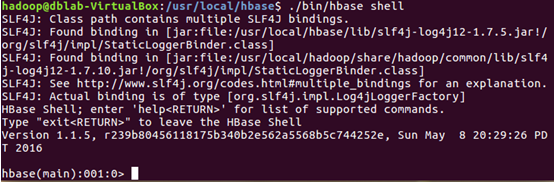
2.啟動Hbase shell
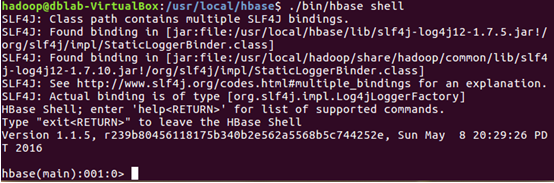
3.創建表user_action
4.新建終端,進入sqoop,導入數據
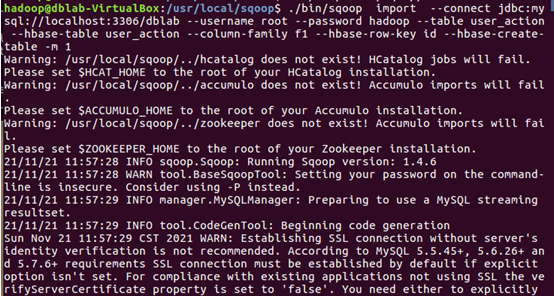
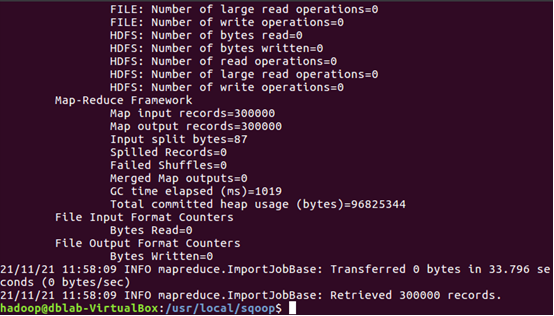
5.查看hbase中user_action表數據
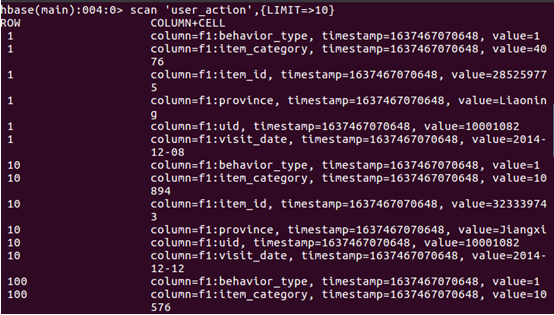
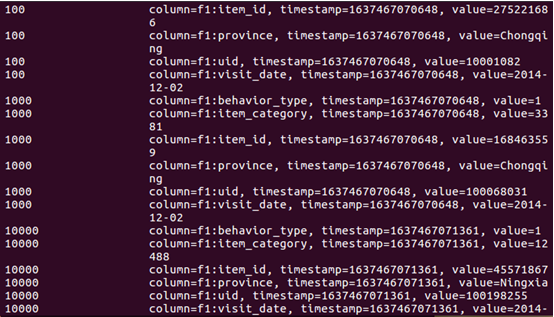
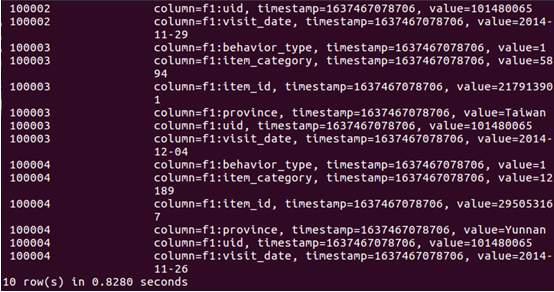
4、 使用HBase Java API 把數據從本地導入到HBase中
1.啟動Hadoop、HBase

2.數據準備
將之前的user_action數據從hdfs複製到linux系統的本地文件系統中,操作如下
先進入/usr/local/bigdatacase/dataset中

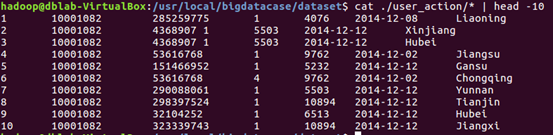
將hdfs上的user_action數據複製到本地當前目錄中

查看前10行數據
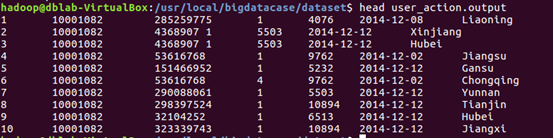
將00000*文件複製一份重命名為user_action.output(*表示通配符)

查看user_action.output前十行
3.編寫數據導入程式
啟動eclipse

創建java project並命名為ImportHBase
新建HBaseImportTest class,並輸入以下代碼
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseImportTest extends Thread {
public Configuration config;
public HTable table;
public HBaseAdmin admin;
public HBaseImportTest() {
config = HBaseConfiguration.create();
// config.set("hbase.master", "master:60000");
// config.set("hbase.zookeeper.quorum", "master");
try {
table = new HTable(config, Bytes.toBytes("user_action"));
admin = new HBaseAdmin(config);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
if (args.length == 0) { //第一個參數是該jar所使用的類,第二個參數是數據集所存放的路徑
throw new Exception("You must set input path!");
}
String fileName = args[args.length-1]; //輸入的文件路徑是最後一個參數
HBaseImportTest test = new HBaseImportTest();
test.importLocalFileToHBase(fileName);
}
public void importLocalFileToHBase(String fileName) {
long st = System.currentTimeMillis();
BufferedReader br = null;
try {
br = new BufferedReader(new InputStreamReader(new FileInputStream(
fileName)));
String line = null;
int count = 0;
while ((line = br.readLine()) != null) {
count++;
put(line);
if (count % 10000 == 0)
System.out.println(count);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (br != null) {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
try {
table.flushCommits();
table.close(); // must close the client
} catch (IOException e) {
e.printStackTrace();
}
}
long en2 = System.currentTimeMillis();
System.out.println("Total Time: " + (en2 - st) + " ms");
}
@SuppressWarnings("deprecation")
public void put(String line) throws IOException {
String[] arr = line.split("\t", -1);
String[] column = {"id","uid","item_id","behavior_type","item_category","date","province"};
if (arr.length == 7) {
Put put = new Put(Bytes.toBytes(arr[0]));// rowkey
for(int i=1;i<arr.length;i++){
put.add(Bytes.toBytes("f1"), Bytes.toBytes(column[i]),Bytes.toBytes(arr[i]));
}
table.put(put); // put to server
}
}
public void get(String rowkey, String columnFamily, String column,
int versions) throws IOException {
long st = System.currentTimeMillis();
Get get = new Get(Bytes.toBytes(rowkey));
get.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column));
Scan scanner = new Scan(get);
scanner.setMaxVersions(versions);
ResultScanner rsScanner = table.getScanner(scanner);
for (Result result : rsScanner) {
final List<KeyValue> list = result.list();
for (final KeyValue kv : list) {
System.out.println(Bytes.toStringBinary(kv.getValue()) + "\t"
+ kv.getTimestamp()); // mid + time
}
}
rsScanner.close();
long en2 = System.currentTimeMillis();
System.out.println("Total Time: " + (en2 - st) + " ms");
}
}
在/usr/local/bigdatacase下新建hbase子目錄,用來存放導出的ImportHBase.jar

打包成可執行jar包並導出至/usr/local/bigdatacase/hbase目錄下

4.數據導入
在導入數據前,先把user_action表清空

運行hadoop jar命令來運行剛剛的jar包


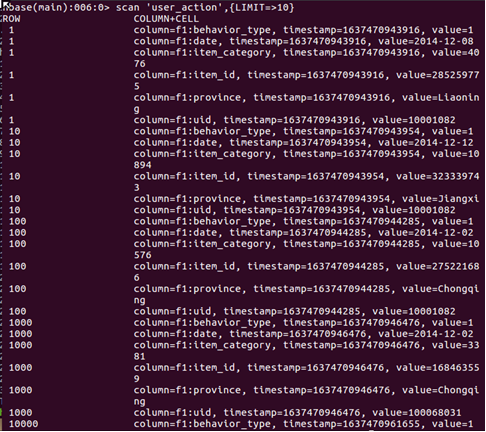
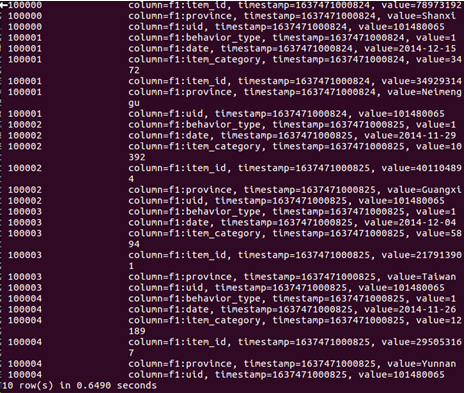
5.查看HBase中user_action表數據
四、利用R進行數據可視化分析
1、安裝R
用vim編輯器打開/etc/apt/sources.list文件

在文件的最後一行添加廈門大學的鏡像源
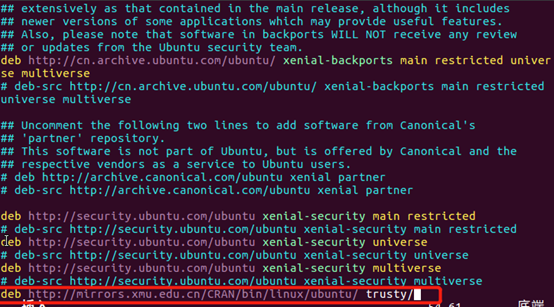
保存文件退出vim編輯器,執行如下命令更新軟體源列表
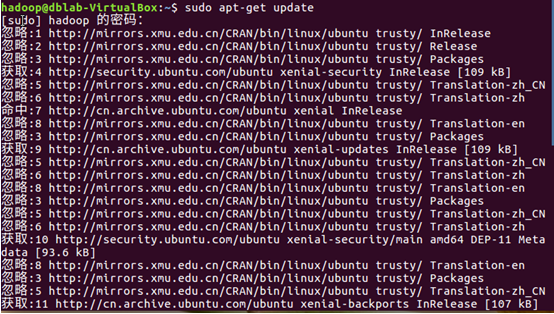
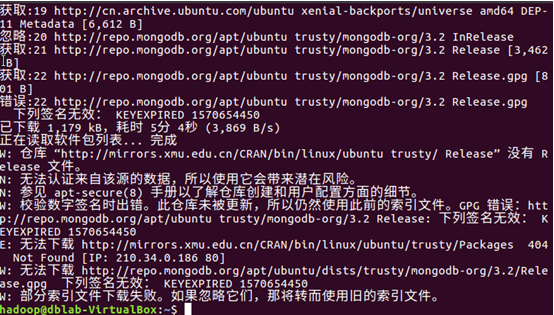
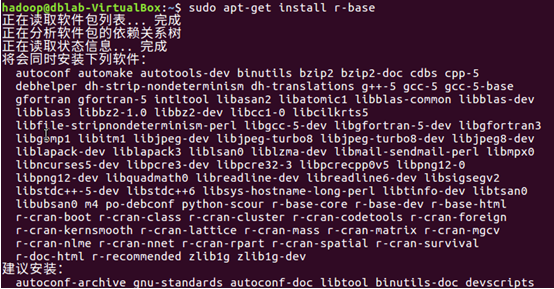
執行如下命令安裝R語言
用vim編輯器打開/etc/apt/sources.list文件

在文件最後一行添加下列語句

保存文件退出vim編輯器,執行如下命令更新軟體源列表
執行如下命令安裝R語言

啟動R
執行以下命令退出

2、安裝依賴庫
進入R命令模式,輸入以下命令
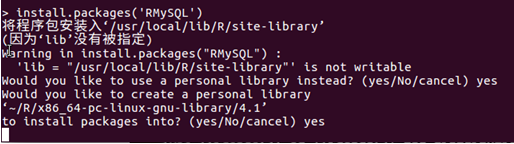
出現以下錯誤信息
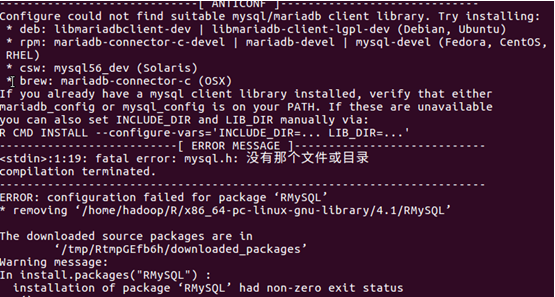
執行下列語句

再次執行RMySQL下載命令
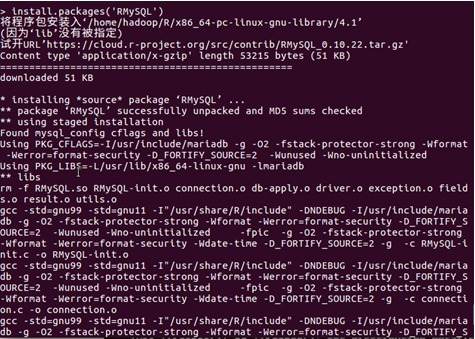

執行如下命令安裝繪圖包ggplot2

運行以下命令安裝devtools
安裝相應的包




Install.packages(‘相應的依賴’)

再次嘗試下載devtools,成功。
最後執行如下命令安裝taiyun/recharts.
3、可視化分析
1、連接MySQL,並獲取數據
新建終端,並啟動mysql

進入mysql命令提示符狀態

輸入SQL語句查詢數據

切換到R命令視窗,連接到MySQL資料庫

2、分析消費者對商品的行為
使用summary()函數查看MySQL資料庫表user_action的欄位behavior_type的類型

看出user_action表中欄位behavior_type的類型是字元型,這樣不方便作比較,需要將其轉換為數值型,命令與執行結果如下

用柱狀圖展示消費者的行為類型的行為類型分佈情況


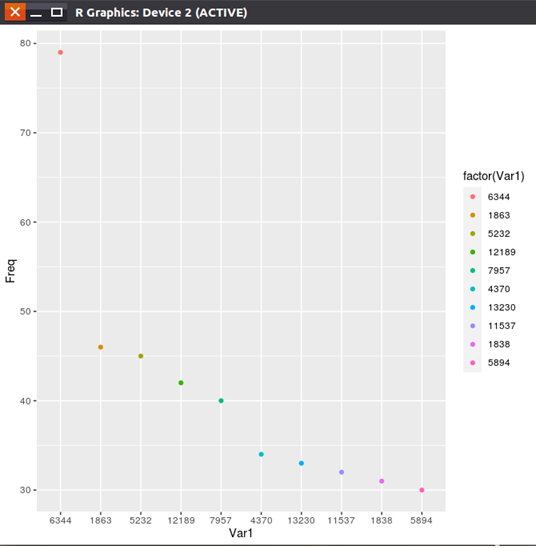
3、分析銷量排名前十的商品及其銷量
獲取子數據集,排序,並獲取第1個到第10個排序結果(第一行是商品分類,第二行表示該類的銷量)

採用散點圖展示上面的分析結果
將count矩陣結果轉換成數據框,完成散點圖繪製

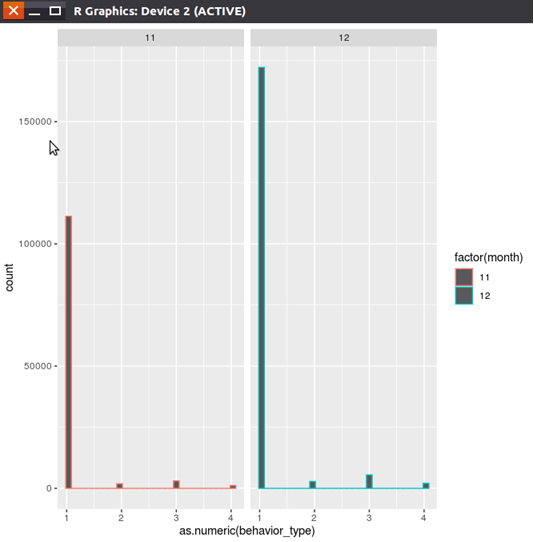
4、分析每年的哪個月銷量最大
在數據集中增加一列關於月份的數據
visti_date變數中截取月份,user_ation中增加一列月份數據

用柱狀圖展示消費者在一年的不同月份的購買量情況

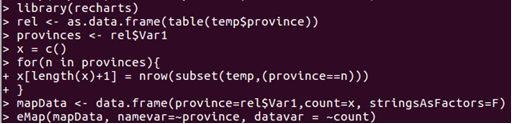
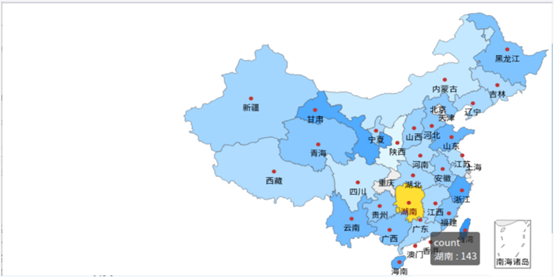
5、分析國內哪個省份的消費者最有購買欲望