
通常在我寫EXISTS語句時,我會寫成IF EXISTS(SELECT TOP(1) 1 FROM XXX),也沒細細考究過為什麼要這麼寫,只是隱約認為這樣寫沒有啥問題,那今天就深究下吧! 首先準備測試測試數據 其中需要註意下索引IDX_ID, 雖然ID已經是主鍵索引,但仍創建一個非聚集索引以供後續 ...
通常在我寫EXISTS語句時,我會寫成IF EXISTS(SELECT TOP(1) 1 FROM XXX),也沒細細考究過為什麼要這麼寫,只是隱約認為這樣寫沒有啥問題,那今天就深究下吧!
首先準備測試測試數據
USE [TestDB1] GO CREATE TABLE TB1001 ( ID INT IDENTITY(1,1), C1 VARCHAR(200), CONSTRAINT PK_TB1001_ID PRIMARY KEY(ID) ) GO CREATE INDEX IDX_ID ON TB1001(ID) GO INSERT INTO TB1001(C1) SELECT name FROM sys.columns GO
其中需要註意下索引IDX_ID, 雖然ID已經是主鍵索引,但仍創建一個非聚集索引以供後續測試。
通常我們在寫EXISTS語句時,一個糾結點是要不要使用TOP,另外一個糾結點是SELECT 語句中的返回列,因此構造測試語句如下:
IF EXISTS(SELECT 1 FROM [dbo].[TB1001] WHERE ID>10) BEGIN PRINT 1 END IF EXISTS(SELECT TOP(1) 1 FROM [dbo].[TB1001] WHERE ID>10) BEGIN PRINT 1 END IF EXISTS(SELECT TOP(10) 1 FROM [dbo].[TB1001] WHERE ID>10) BEGIN PRINT 1 END IF EXISTS(SELECT * FROM [dbo].[TB1001] WHERE ID>10) BEGIN PRINT 1 END IF EXISTS(SELECT ID FROM [dbo].[TB1001] WHERE ID>10) BEGIN PRINT 1 END IF EXISTS(SELECT C1 FROM [dbo].[TB1001] WHERE ID>10) BEGIN PRINT 1 END
以上語句各種寫法,但最終生成的執行計劃都一樣,因此執行效率也一樣:

對於IF EXISTS(SELECT C1 FROM [dbo].[TB1001] WHERE ID>10)語句,索引IDX_ID並沒有包含C1列的數據,但查詢仍使用IDX_ID索引,證明查詢並不需要訪問C1列的數據
從上面的操作運算符來看,可以得到以下兩個結論:
1. 無論是TOP(1)還是TOP(10)或不使用TOP,執行計劃中都沒有TOP的操作,即使SQL語句中寫明TOP(1)也會被忽略,因此TOP並不影響生成執行計劃;
2. 無論使用SELECT 1 或者使用SELECT * 又或者使用SELECT C1 等,運算符都沒有返回列信息(OUTPUT LIST), 即EXISTS並不關心返回數據的內容,只關心有沒有數據,因此SELECT部分的內容也不影響生成執行計劃;
--========================================================
PS: Seek Keys[1] 並不代表只返回一行數據,如對於查詢:
SELECT TOP(10) * FROM [dbo].[TB1001] WHERE ID>10
其生成的執行計劃為: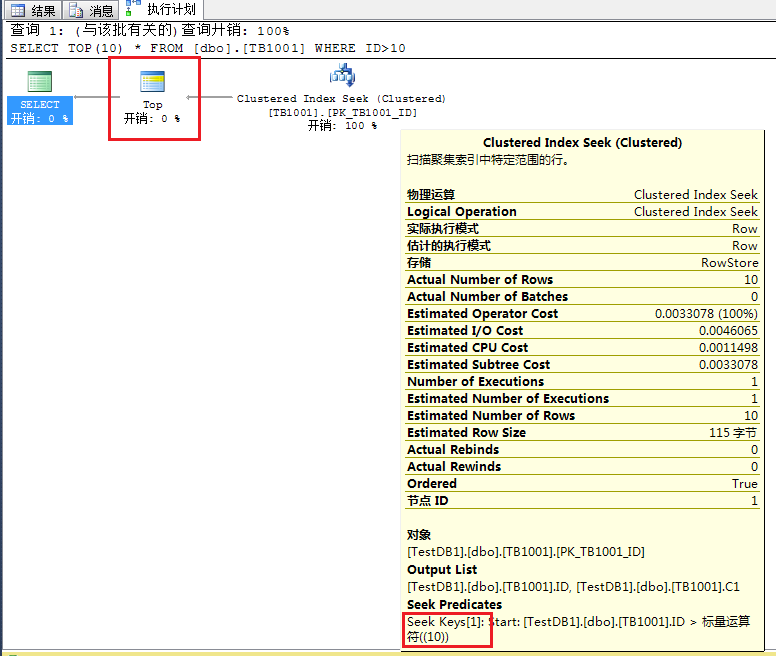
================================================



