
前言 日常的開發中,無不都是使用資料庫來進行數據的存儲,由於一般的系統任務中通常不會存在高併發的情況,所以這樣看起來並沒有什麼問題。 一旦涉及大數據量的需求,如一些商品搶購的情景,或者主頁訪問量瞬間較大的時候,單一使用資料庫來保存數據的系統會因為面向磁碟,磁碟讀/寫速度問題有嚴重的性能弊端,詳細的磁 ...
前言
日常的開發中,無不都是使用資料庫來進行數據的存儲,由於一般的系統任務中通常不會存在高併發的情況,所以這樣看起來並沒有什麼問題。
一旦涉及大數據量的需求,如一些商品搶購的情景,或者主頁訪問量瞬間較大的時候,單一使用資料庫來保存數據的系統會因為面向磁碟,磁碟讀/寫速度問題有嚴重的性能弊端,詳細的磁碟讀寫原理請參考這一片
在這一瞬間成千上萬的請求到來,需要系統在極短的時間內完成成千上萬次的讀/寫操作,這個時候往往不是資料庫能夠承受的,極其容易造成資料庫系統癱瘓,最終導致服務宕機的嚴重生產問題。
為了剋服上述的問題,項目通常會引入NoSQL技術,這是一種基於記憶體的資料庫,並且提供一定的持久化功能。
Redis技術就是NoSQL技術中的一種。Redis緩存的使用,極大的提升了應用程式的性能和效率,特別是數據查詢方面。
但同時,它也帶來了一些問題。其中,最要害的問題,就是數據的一致性問題,從嚴格意義上講,這個問題無解。如果對數據的一致性要求很高,那麼就不能使用緩存。
另外的一些典型問題就是,緩存穿透、緩存擊穿和緩存雪崩。本篇文章從實際代碼操作,來提出解決這三個緩存問題的方案,畢竟Redis的緩存問題是實際面試中高頻問點,理論和實操要兼得。
緩存穿透
緩存穿透是指查詢一條資料庫和緩存都沒有的一條數據,就會一直查詢資料庫,對資料庫的訪問壓力就會增大,緩存穿透的解決方案,有以下兩種:
- 緩存空對象:代碼維護較簡單,但是效果不好。
- 布隆過濾器:代碼維護複雜,效果很好。
緩存空對象
緩存空對象是指當一個請求過來緩存中和資料庫中都不存在該請求的數據,第一次請求就會跳過緩存進行資料庫的訪問,並且訪問資料庫後返回為空,此時也將該空對象進行緩存。
若是再次進行訪問該空對象的時候,就會直接擊中緩存,而不是再次資料庫,緩存空對象實現的原理圖如下:
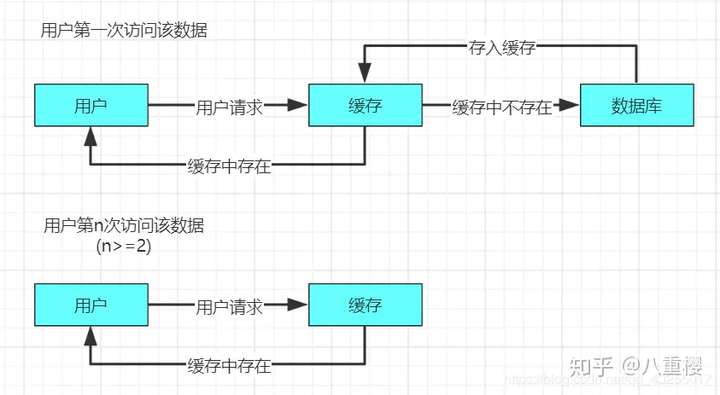
緩存空對象的實現代碼如下:
public class UserServiceImpl {
@Autowired
UserDAO userDAO;
@Autowired
RedisCache redisCache;
public User findUser(Integer id) {
Object object = redisCache.get(Integer.toString(id));
// 緩存中存在,直接返回
if(object != null) {
// 檢驗該對象是否為緩存空對象,是則直接返回null
if(object instanceof NullValueResultDO) {
return null;
}
return (User)object;
} else {
// 緩存中不存在,查詢資料庫
User user = userDAO.getUser(id);
// 存入緩存
if(user != null) {
redisCache.put(Integer.toString(id),user);
} else {
// 將空對象存進緩存
redisCache.put(Integer.toString(id), new NullValueResultDO());
}
return user;
}
}
}
緩存空對象的實現代碼很簡單,但是緩存空對象會帶來比較大的問題,就是緩存中會存在很多空對象,占用記憶體的空間,浪費資源,一個解決的辦法就是設置空對象的較短的過期時間,代碼如下:
// 再緩存的時候,添加多一個該空對象的過期時間60秒
redisCache.put(Integer.toString(id), new NullValueResultDO(),60);
布隆過濾器
布隆過濾器是一種基於概率的數據結構,主要用來判斷某個元素是否在集合內,它具有運行速度快(時間效率),占用記憶體小的優點(空間效率),但是有一定的誤識別率和刪除困難的問題。它只能告訴你某個元素一定不在集合內或可能在集合內。
在電腦科學中有一種思想:空間換時間,時間換空間。一般兩者是不可兼得,而布隆過濾器運行效率和空間大小都兼得,它是怎麼做到的呢?
在布隆過濾器中引用了一個誤判率的概念,即它可能會把不屬於這個集合的元素認為可能屬於這個集合,但是不會把屬於這個集合的認為不屬於這個集合,布隆過濾器的特點如下:
- 一個非常大的二進位位數組(數組裡只有0和1)
- 若幹個哈希函數
- 空間效率和查詢效率高
- 不存在漏報(False Negative):某個元素在某個集合中,肯定能報出來。
- 可能存在誤報(False Positive):某個元素不在某個集合中,可能也被爆出來。
- 不提供刪除方法,代碼維護困難。
- 位數組初始化都為0,它不存元素的具體值,當元素經過哈希函數哈希後的值(也就是數組下標)對應的數組位置值改為1。
實際布隆過濾器存儲數據和查詢數據的原理圖如下:
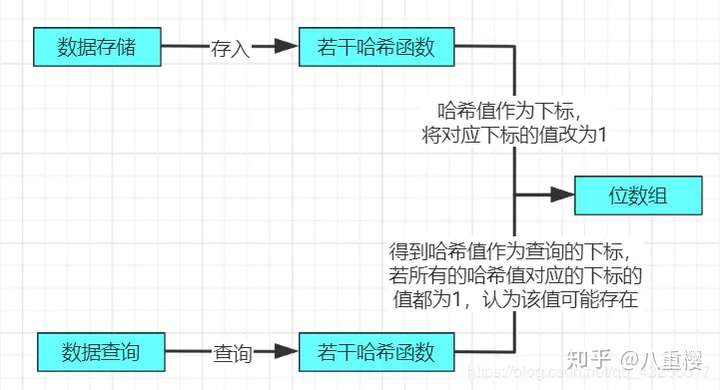
可能很多讀者看完上面的特點和原理圖,還是看不懂,別急下麵通過圖解一步一步的講解布隆過濾器,總而言之一句簡單的話概括就是布隆過濾器是一個很大二進位的位數組,數組裡面只存0和1。
初始化的布隆過濾器的結構圖如下:

以上只是畫了布隆過濾器的很小很小的一部分,實際布隆過濾器是非常大的數組(這裡的大是指它的長度大,並不是指它所占的記憶體空間大)。
那麼一個數據是怎麼存進布隆過濾器的呢?
當一個數據進行存入布隆過濾器的時候,會經過如幹個哈希函數進行哈希(若是對哈希函數還不懂的請參考這一片[]),得到對應的哈希值作為數組的下標,然後將初始化的位數組對應的下標的值修改為1,結果圖如下:
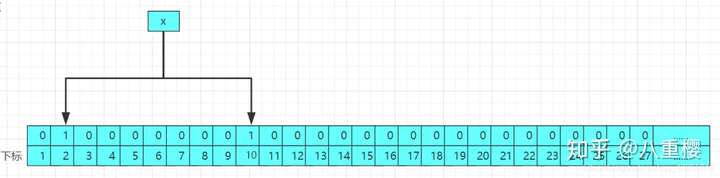
當再次進行存入第二個值的時候,修改後的結果的原理圖如下:
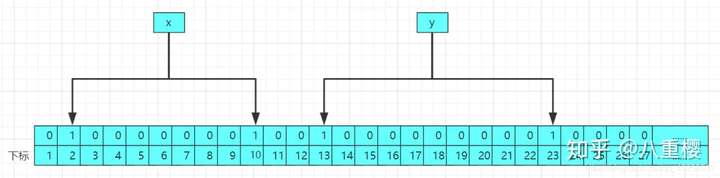
所以每次存入一個數據,就會哈希函數的計算,計算的結果就會作為下標,在布隆過濾器中有多少個哈希函數就會計算出多少個下標,布隆過濾器插入的流程如下:
- 將要添加的元素給m個哈希函數
- 得到對應於位數組上的m個位置
- 將這m個位置設為1
那麼為什麼會有誤判率呢?
假設在我們多次存入值後,在布隆過濾器中存在x、y、z這三個值,布隆過濾器的存儲結構圖圖如下所示:
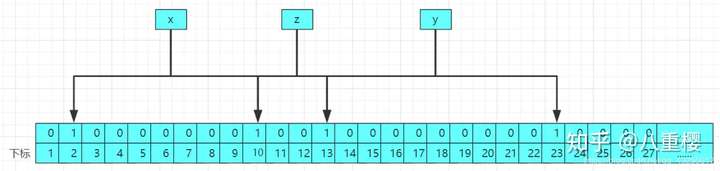
當我們要查詢的時候,比如查詢a這個數,實際中a這個數是不存在布隆過濾器中的,經過2哥哈希函數計算後得到a的哈希值分別為2和13,結構原理圖如下:
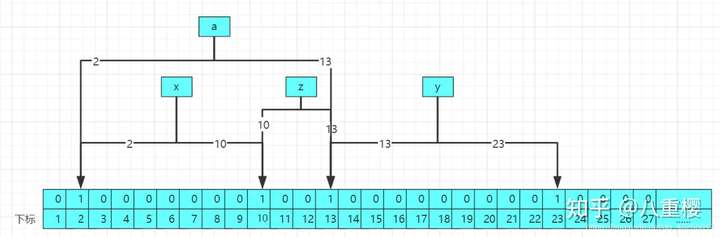
經過查詢後,發現2和13位置所存儲的值都為1,但是2和13的下標分別是x和z經過計算後的下標位置的修改,該布隆過濾器中實際不存在a,那麼布隆過濾器就會誤判改值可能存在,因為布隆過濾器不存元素值,所以存在誤判率。
那麼具體布隆過布隆過濾的判斷的準確率和一下兩個因素有關:
- 布隆過濾器大小:越大,誤判率就越小,所以說布隆過濾器一般長度都是非常大的。
- 哈希函數的個數:哈希函數的個數越多,那麼誤判率就越小。
那麼為什麼不能刪除元素呢?
原因很簡單,因為刪除元素後,將對應元素的下標設置為零,可能別的元素的下標也引用改下標,這樣別的元素的判斷就會收到影響,原理圖如下:
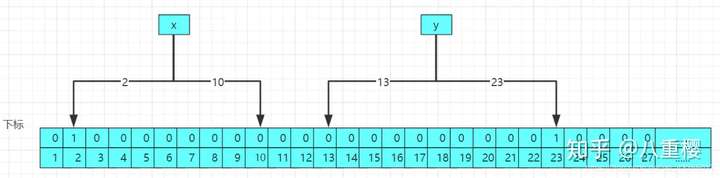
當你刪除z元素之後,將對應的下標10和13設置為0,這樣導致x和y元素的下標受到影響,導致數據的判斷不准確,所以直接不提供刪除元素的api。
以上說的都是布隆過濾器的原理,只有理解了原理,在實際的運用才能如魚得水,下麵就來實操代碼,手寫一個簡單的布隆過濾器。
對於要手寫一個布隆過濾器,首先要明確布隆過濾器的核心:
- 若幹哈希函數
- 存值得Api
- 判斷值得Api
實現得代碼如下:
public class MyBloomFilter {
// 布隆過濾器長度
private static final int SIZE = 2 << 10;
// 模擬實現不同的哈希函數
private static final int[] num= new int[] {5, 19, 23, 31,47, 71};
// 初始化位數組
private BitSet bits = new BitSet(SIZE);
// 用於存儲哈希函數
private MyHash[] function = new MyHash[num.length];
// 初始化哈希函數
public MyBloomFilter() {
for (int i = 0; i < num.length; i++) {
function [i] = new MyHash(SIZE, num[i]);
}
}
// 存值Api
public void add(String value) {
// 對存入得值進行哈希計算
for (MyHash f: function) {
// 將為數組對應的哈希下標得位置得值改為1
bits.set(f.hash(value), true);
}
}
// 判斷是否存在該值得Api
public boolean contains(String value) {
if (value == null) {
return false;
}
boolean result= true;
for (MyHash f : func) {
result= result&& bits.get(f.hash(value));
}
return result;
}
}
哈希函數代碼如下:
public static class MyHash {
private int cap;
private int seed;
// 初始化數據
public MyHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
// 哈希函數
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
布隆過濾器測試代碼如下:
public static void test {
String value = "4243212355312";
MyBloomFilter filter = new MyBloomFilter();
System.out.println(filter.contains(value));
filter.add(value);
System.out.println(filter.contains(value));
}
以上就是手寫了一個非常簡單得布隆過濾器,但是實際項目中可能事由牛人或者大公司已經幫你寫好的,如谷歌的Google Guava,只需要在項目中引入一下依賴:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>27.0.1-jre</version>
</dependency>
實際項目中具體的操作代碼如下:
public static void MyBloomFilterSysConfig {
@Autowired
OrderMapper orderMapper
// 1.創建布隆過濾器 第二個參數為預期數據量10000000,第三個參數為錯誤率0.00001
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")),10000000, 0.00001);
// 2.獲取所有的訂單,並將訂單的id放進布隆過濾器裡面
List<Order> orderList = orderMapper.findAll()
for (Order order;orderList ) {
Long id = order.getId();
bloomFilter.put("" + id);
}
}
在實際項目中會啟動一個系統任務或者定時任務,來初始化布隆過濾器,將熱點查詢數據的id放進布隆過濾器裡面,當用戶再次請求的時候,使用布隆過濾器進行判斷,改訂單的id是否在布隆過濾器中存在,不存在直接返回null,具體操作代碼:
// 判斷訂單id是否在布隆過濾器中存在
bloomFilter.mightContain("" + id)
布隆過濾器的缺點就是要維持容器中的數據,因為訂單數據肯定是頻繁變化的,實時的要更新布隆過濾器中的數據為最新。
緩存擊穿
緩存擊穿是指一個key非常熱點,在不停的扛著大併發,大併發集中對這一個點進行訪問,當這個key在失效的瞬間,持續的大併發就穿破緩存,直接請求資料庫,瞬間對資料庫的訪問壓力增大。
緩存擊穿這裡強調的是併發,造成緩存擊穿的原因有以下兩個:
- 該數據沒有人查詢過 ,第一次就大併發的訪問。(冷門數據)
- 添加到了緩存,reids有設置數據失效的時間 ,這條數據剛好失效,大併發訪問(熱點數據)
對於緩存擊穿的解決方案就是加鎖,具體實現的原理圖如下:
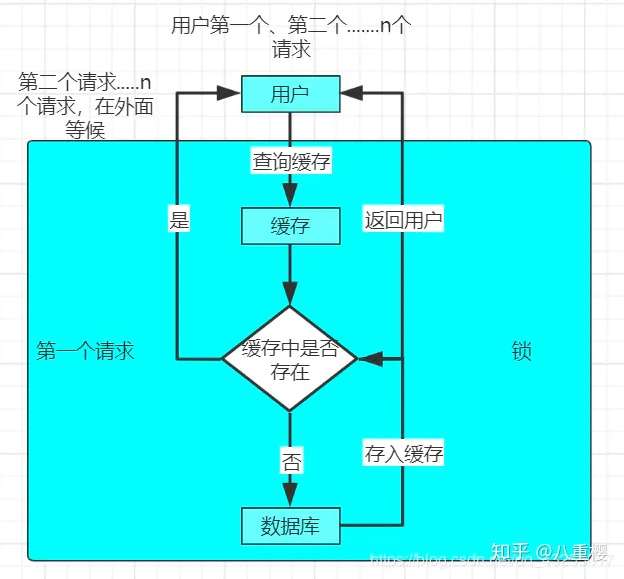
當用戶出現大併發訪問的時候,在查詢緩存的時候和查詢資料庫的過程加鎖,只能第一個進來的請求進行執行,當第一個請求把該數據放進緩存中,接下來的訪問就會直接集中緩存,防止了緩存擊穿。
業界比價普遍的一種做法,即根據key獲取value值為空時,鎖上,從資料庫中load數據後再釋放鎖。若其它線程獲取鎖失敗,則等待一段時間後重試。這裡要註意,分散式環境中要使用分散式鎖,單機的話用普通的鎖(synchronized、Lock)就夠了。
下麵以一個獲取商品庫存的案例進行代碼的演示,單機版的鎖實現具體實現的代碼如下:
// 獲取庫存數量
public String getProduceNum(String key) {
try {
synchronized (this) { //加鎖
// 緩存中取數據,並存入緩存中
int num= Integer.parseInt(redisTemplate.opsForValue().get(key));
if (num> 0) {
//沒查一次庫存-1
redisTemplate.opsForValue().set(key, (num- 1) + "");
System.out.println("剩餘的庫存為num:" + (num- 1));
} else {
System.out.println("庫存為0");
}
}
} catch (NumberFormatException e) {
e.printStackTrace();
} finally {
}
return "OK";
}
分散式的鎖實現具體實現的代碼如下:
public String getProduceNum(String key) {
// 獲取分散式鎖
RLock lock = redissonClient.getLock(key);
try {
// 獲取庫存數
int num= Integer.parseInt(redisTemplate.opsForValue().get(key));
// 上鎖
lock.lock();
if (num> 0) {
//減少庫存,並存入緩存中
redisTemplate.opsForValue().set(key, (num - 1) + "");
System.out.println("剩餘庫存為num:" + (num- 1));
} else {
System.out.println("庫存已經為0");
}
} catch (NumberFormatException e) {
e.printStackTrace();
} finally {
//解鎖
lock.unlock();
}
return "OK";
}
緩存雪崩
緩存雪崩 是指在某一個時間段,緩存集中過期失效。此刻無數的請求直接繞開緩存,直接請求資料庫。
造成緩存雪崩的原因,有以下兩種:
- reids宕機
- 大部分數據失效
比如天貓雙11,馬上就要到雙11零點,很快就會迎來一波搶購,這波商品在23點集中的放入了緩存,假設緩存一個小時,那麼到了凌晨24點的時候,這批商品的緩存就都過期了。
而對這批商品的訪問查詢,都落到了資料庫上,對於資料庫而言,就會產生周期性的壓力波峰,對資料庫造成壓力,甚至壓垮資料庫。
緩存雪崩的原理圖如下,當正常的情況下,key沒有大量失效的用戶訪問原理圖如下:
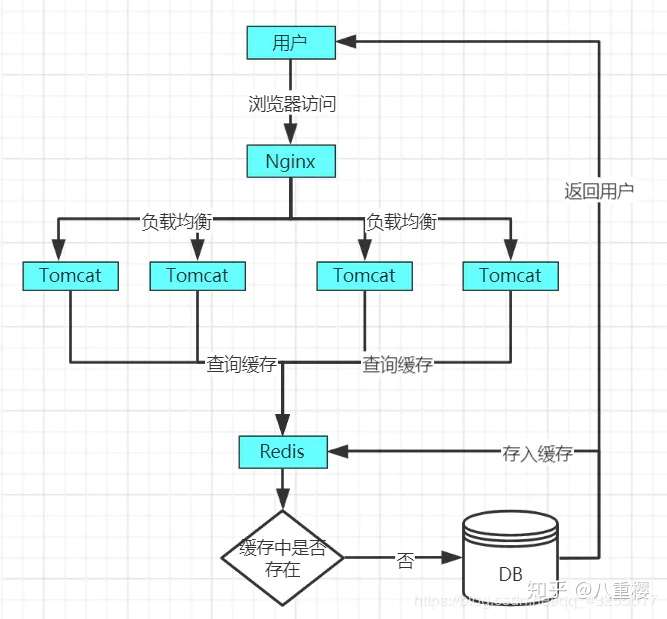
當某一時間點,key大量失效,造成的緩存雪崩的原理圖如下:
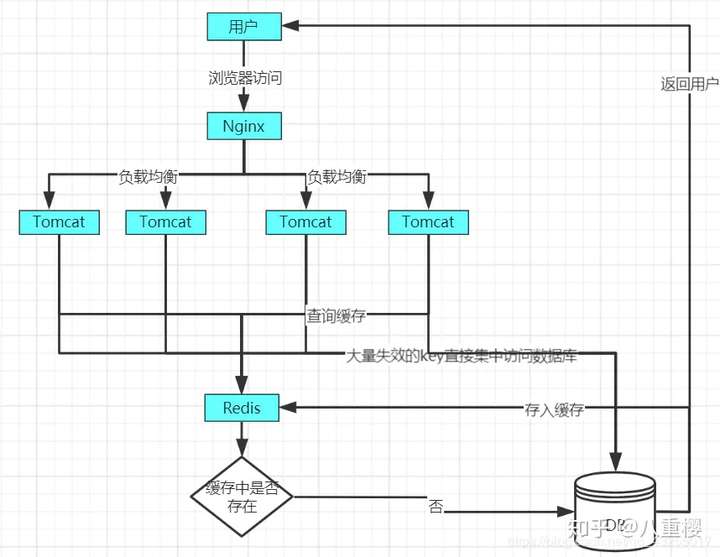
對於緩存雪崩的解決方案有以下兩種:
- 搭建高可用的集群,防止單機的redis宕機。
- 設置不同的過期時間,防止同意之間內大量的key失效。
針對業務系統,永遠都是具體情況具體分析,沒有最好,只有最合適。於緩存其它問題,緩存滿了和數據丟失等問題,我們後面繼續深入的學習。最後也提一下三個詞LRU、RDB、AOF,通常我們採用LRU策略處理溢出,Redis的RDB和AOF持久化策略來保證一定情況下的數據安全。
看完這篇Redis緩存三大問題,保你面試能造火箭,工作能擰螺絲。 - 掘金


