
什麼是Hadoop HDFS? Hadoop 分散式文件系統是世界上最可靠的文件系統。HDFS可以再大量硬體組成的集群中存儲大文件。 它的設計原則是趨向於存儲少量的大文件,而不是存儲大量的小文件。 即使在硬體發生故障的時候,HDFS也能體現出它對數據存儲的可靠性。它支持高吞吐量的平行訪問方式。 HD ...
什麼是Hadoop HDFS?
Hadoop 分散式文件系統是世界上最可靠的文件系統。HDFS可以再大量硬體組成的集群中存儲大文件。
它的設計原則是趨向於存儲少量的大文件,而不是存儲大量的小文件。
即使在硬體發生故障的時候,HDFS也能體現出它對數據存儲的可靠性。它支持高吞吐量的平行訪問方式。
HDFS的介紹
源自於Google的GFS論文 發表於2003年10月 HDFS是GFS克隆版 ,HDFS的全稱是Hadoop Distributed File System易於擴展的分散式文件系統,運行在大量普通廉價機器上,提供容錯機制,為大量用戶提供性能不錯的文件存取服務 。
HDFS設計目標
1. 自動快速檢測應對硬體錯誤
2. 流式訪問數據
3. 移動計算比移動數據本身更划算
4. 簡單一致性模型
5. 異構平臺可移植
{
對於設計目標的詳細解釋:
I. 硬體故障(自動快速檢測應對硬體錯誤)
硬體故障已經不再是異常了,它變成了一個常規現象。HDFS實例由成千上萬的服務機器組成,這些機器中的任何一個都存儲著文件系統的部分數據。這裡元件的數量是龐大的,而且極可能導致硬體故障。這就意味著總是有一些組件不工作。所以,核心結構的目標是快速的自動的進行錯誤檢測和恢復。
II. 流數據訪問(流式訪問數據)
HDFS 應用需要依賴流去訪問它的數據集。Hadoop HDFS的設計方向主要面向於批處理而不是用戶交互。著力點在於重視數據訪問的高吞吐率而不是數據訪問的低延遲性。它註重於如何在分析日誌的同時盡肯能快速的獲得數據。
III. 巨大的數據集
HDFS通常需要工作在大數據集上。標準的實踐中是,HDFS系統中存在的文件大小範圍是GB到TB。HDFS架構的設計就是如果最好的存儲和獲得大量的數據。HDFS也提供高聚合數據的帶寬。它同樣應該具備在單一集群中可以擴展上百個節點的能力。與此同時,它也應該具備在一個單元實例中處理處理數千萬個文件的能力。
IV. 簡單的一致性模型(簡單一致性模型)
它工作在一次性寫入多次的讀取的理論上。一旦數據被創建、寫入和關閉,該文件是不能被修改的。這種方式解決數據一致性的問題同時也實現了高吞吐量訪問數據的需求。基於MapReduce的應用和或者網路爬蟲的應用在這種模型中擁有很高的適應性。和每一apache筆記一樣,未來計劃增加追加寫入文件這一功能。
V. 轉移計算量比轉移數據更合理(移動計算比移動數據本身更划算)
如果一個應用在它操作的數據附近進行計算,總會比在離它遠的地方做計算更高效。這個現象在處理大的數據集時,往往提現的更明顯。這樣做主要的優勢體現在增加系統的總吞吐量上。它同時也最小化了網路阻塞。其理念是,將計算移動到離數據更近的位置,來代替將數據轉移到離計算更近的位置。
VI. 便捷的訪問有不同軟體和硬體組成的平臺(異構平臺可移植)
HDFS 被設計成便捷的在平臺之間切換。這讓HDFS系統能夠因為其適應性而廣泛傳播。這是在處理大數據集數據的最好的平臺。
}
HDFS的特點
優點:
1. 高可靠性:Hadoop按位存儲和處理數據的能力值得人們信賴;
2. 高擴展性:Hadoop是在可用的電腦集簇間分配數據並完成計算任務的,這些集簇可以方便地擴展到數以千計的節點中。
3. 高效性: Hadoop能夠在節點之間動態地移動數據,並保證各個節點的動態平衡,因此處理速度非常快。
4. 高容錯性:Hadoop能夠自動保存數據的多個副本,並且能夠自動將失敗的任務重新分配。
缺點:
1. 不適合低延遲數據訪問。
2. 無法高效存儲大量小文件。
3. 不支持多用戶寫入及任意修改文件。
hdfs核心設計思想及作用
- 分而治之:將大文件、大批量文件,分散式存放在大量伺服器上,以便於採取分而治之的方式對海量數據進行運算分析;
- 為各類分散式運算框架(如:mapreduce,spark,tez,……)提供數據存儲服務
- hdfs描述
首先,它是一個文件系統,用於存儲文件,通過統一的命名空間——目錄樹來定位文件
其次,它是分散式的,由很多伺服器聯合起來實現其功能,集群中的伺服器有各自的角色;
重要特性如下:
- HDFS中的文件在物理上是分塊存儲(block),塊的大小可以通過配置參數( dfs.blocksize)來規定,預設大小在hadoop2.x版本中是128M,老版本中是64M。
- HDFS文件系統會給客戶端提供一個統一的抽象目錄樹,客戶端通過路徑來訪問文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。
- 目錄結構及文件分塊信息(元數據)的管理由namenode節點承擔——namenode是HDFS集群主節點,負責維護整個hdfs文件系統的目錄樹,以及每一個路徑(文件)所對應的block塊信息(block的id,及所在的datanode伺服器)。
- 文件的各個block的存儲管理由datanode節點承擔--- datanode是HDFS集群從節點,每一個block都可以在多個datanode上存儲多個副本(副本數量也可以通過參數設置dfs.replication)。
- HDFS是設計成適應一次寫入,多次讀出的場景,且不支持文件的修改
NameNode.SecondaryNameNode.StandByNameNode,Blocks
NO.1 NameNode的功能
NameNode在HDFS架構中也被成為主節點。HDFS NameNode存儲元數據,比如,數據塊的數量,副本的數量和其它的一些細節。這些元數據被存放在主節點的記憶體中,為了達到最快速度的獲取數據。NameNode 負責維護和管理從節點並且給從節點分配任務。它是整個HDFS的中心環節,所以應該將其部署在可靠性高的機器上。
NameNode的任務:
· 管理文件系統命名空間
· 規定客戶端訪問文件規則
· 對文件執行命名,關閉,打開文件或打開路徑等 操作
· 所有的數據節點發送心跳給NameNode, NameNode需要確保DataNode是否線上。一個數據塊報告包含所有這個數據點上的所有block的情況。
· NameNode也負責管理複製因數的數量。
文件呈現在NameNode的元數據表示和管理:
FsImage :元數據鏡像文件 (保存文件系統的目錄樹) -
- 記憶體中保存一份最新的
- 記憶體中鏡像= FsImage + Edits
- FsImage在NameNode中是一個“鏡像文件”。它將全部的文件系統的命名空間保存為一個文件存儲在NameNode的本地文件系統中,這個文件中還包含所有的文件序列化路徑和在文件系統中的文件inodes,每個inode都是文件或者目錄元數據的內部表示。
Edits :元數據操作日誌 (針對目錄樹的修改操作) -
- 日誌文件包含所有在鏡像文件上對系統的最新修改。當NameNode從客戶端收到一個創建/更新/刪除請求時,這條請求會先被記錄到日誌文件中。
- 定期合併fsimage與edits(- Edits文件過大將導致NameNode重啟速度慢, Secondary Namenode負責定期合併他們)
NO.2 NameNode 啟動過程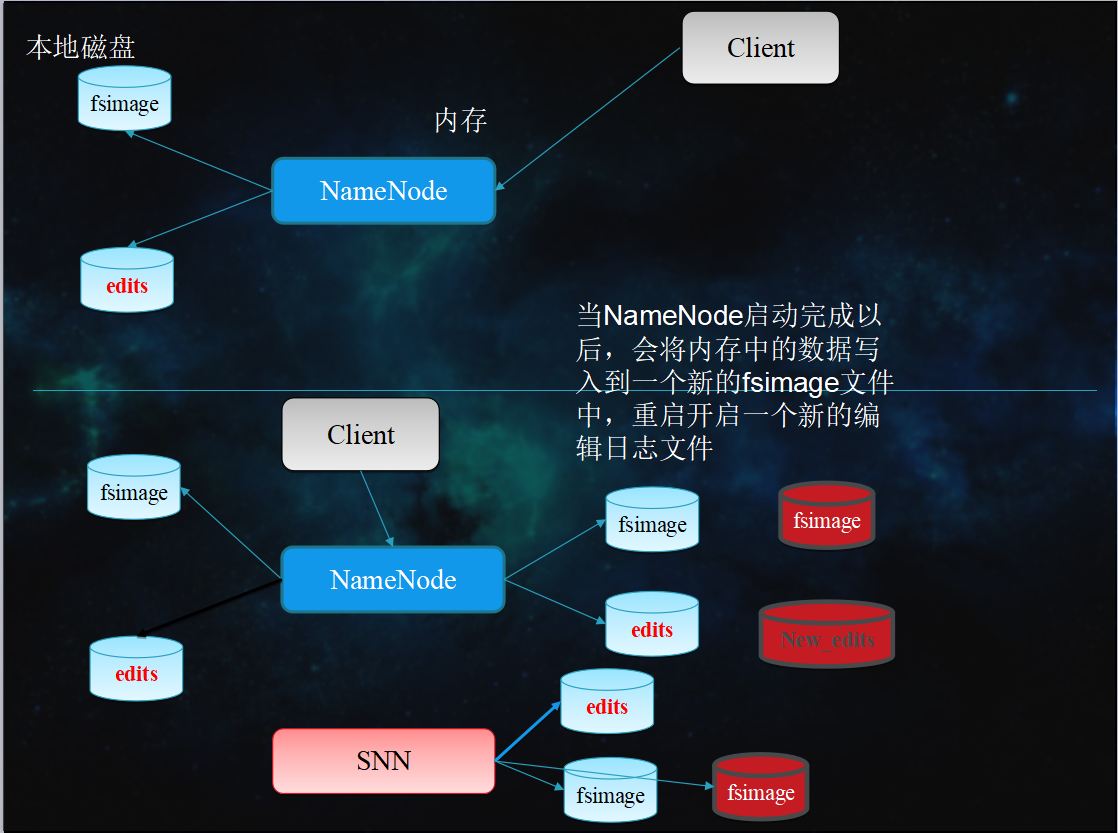
- NameNode啟動的時候首先將fsimage(鏡像)載入記憶體,並執行(replay)編輯日誌edits的的各項操作
- 一旦在記憶體中建立文件系統元數據映射,則創建一個新的fsimage文件(這個過程不需SecondaryNameNode) 和一個空的edits
- 在安全模式下,各個datanode會向namenode發送塊列表的最新情況
- 此刻namenode運行在安全模式。即NameNode的文件系統對於客戶端來說是只讀的。(顯示目錄,顯示文件內容等。寫、刪除、重命名都會失敗)
- NameNode開始監聽RPC和HTTP請求
解釋RPC:RPC(Remote Procedure Call Protocol)——遠程過程通過協議,它是一種通過網路從遠程電腦程式上請求服務,而不需要瞭解底層網路技術的協議
- 系統中數據塊的位置並不是由namenode維護的,而是以塊列表形式存儲在datanode中
- 在系統的正常操作期間,namenode會在記憶體中保留所有塊信息的映射信息
NO.3 SecondaryNameNode 合併fsimage和edits 生成fsimage的過程
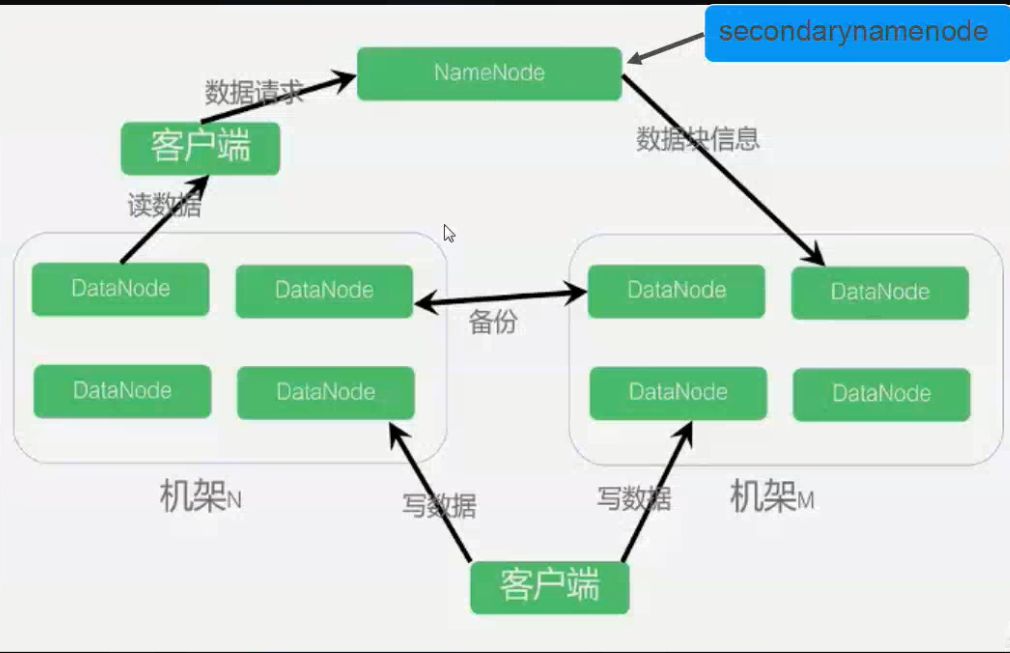
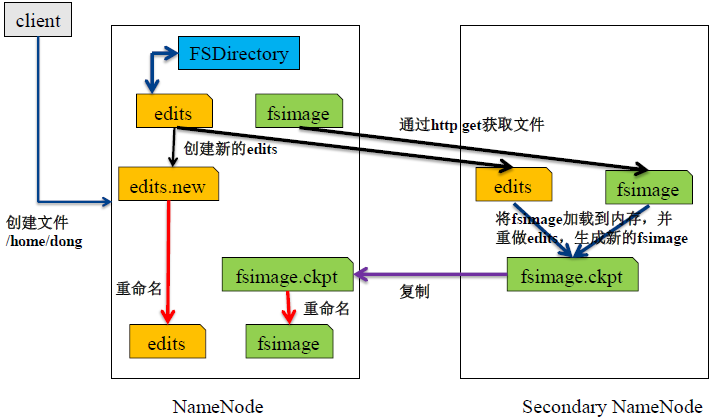
- Secondary NN通知NameNode切換edits。
- Secondary NN從NameNode 獲得fsimage和editlog(通過http方式)。
- Secondary NN將fsimage載入記憶體,然後開始合併edits。
- Secondary NN 將新的fsimage發回給NameNode NameNode 用新的fsimage替換舊的fsimage。
NOTE: SecondaryNameNode 在HDFS中起到一個常規檢查點的作用。
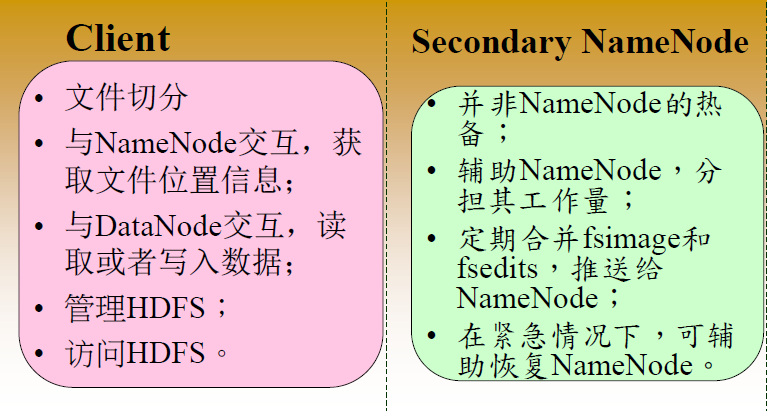
檢查節點是一個定期在命名空間創建檢查點的節點。在Hadoop中的檢查點先從活動的Namenode中下載FsImage文件和日誌文件,它在本地將兩個文件進行融合,然後上傳新的鏡像給活動NameNode。它存儲最後的檢查點的結構,所以它的路徑結構應該跟NameNode的路徑結構一樣。讀取檢查點鏡像的許可權,如果有必要應該一直為NameNode開放。
NO.4 StandByNameNode
- 備份節點也提供和檢查節點一樣的檢查功能。
- 在Hadoop中,Backup節點保留記憶體中最新文件系統命名空間的副本。
- 它和NameNode的狀態總是同步的。
- 在HDFS架構中的備份節點不需要從活動的NameNode中下載FsImage和它日誌文件去創建檢查點。
- 它在記憶體中已經擁有了最新的命名空間狀態。
- 備份節點的檢查點流程比起檢查節點的檢查流程效率更高,因為它只需要保存命名空間到本地鏡像文件和重置日誌文件就夠了。
- NameNode一次只支持一個備份節點。
NO.5 Blocks
- HDFS將巨大的文件分割成小的文件塊,這種文件塊就叫Blocks. 這些Blocks是文件系統中最小的數據單元。
- 客戶端或者管理員,不需要控制這些blocks的存儲位置,由NameNode決定類似的事情。
- 預設的HDFS block大小為128MB,當然這值可以根據不同需求而改變。一個文件除了最後一個block其他block的大小都是相同的,最後一個文件的大小可以是128MB,也可以更小。
- 如果數據的大小比block預設值小的話,block大小就會等於數據的大小。
例如一個數據的大小為129MB,則系統會為這個數據創建兩個Block一個大小為128MB,另一個大小隻為1MB. 存儲成這樣的好處是,既可以節省空間,有可以節省查詢時間。
NO.6 複製管理
- Block複製支持容錯機制。如果一個副本不能被訪問或者損壞,我們可以從其他的副本中讀取數據。
- 在HDFS架構中一個文件的副本數量叫做複製因數。預設的複製因數為3,可以通過修改配置文件修改複製因數。當複製因數為3的時候每個block會被存放在3個不同的DataNode中。
- 如果一個文件是128MB,根據預設配置它將占用384MB的系統空間存儲。
- NameNode通過從DataNode定期接收數據塊上報去維護複製因數,當一個數據塊過多複製或者複製不足,則NameNode負責根據需要增加或刪除副本。
NO.7 機架感知
- 在大型的Hadoop集群中,為了提高讀、寫HDFS文件的效率,NameNode都是按就近原則選擇數據節點的,一般的都是選擇相同機架的DataNode或者是鄰近機架的DataNode去讀、寫數據。NameNode通過為維護每個數據節點的機架ID來獲取機架信息。機架感知在hadoop中是一個有機架信息來獲取數據節點的概念。
- 在HDFS架構中, NameNode必須確保所有的副本不存放在相同機架或者單一機架中,並遵循機架感知演算法來減少延遲和提高容錯。詳情查看後邊: 數據存儲位置與複製詳解...
- 機架感知對於提升一下方面有著重要作用:
· 數據高可用性和可靠性
· 集群的表現
· 提升網路帶寬
HDFS工作機制詳解
NO.1 HDFS概述
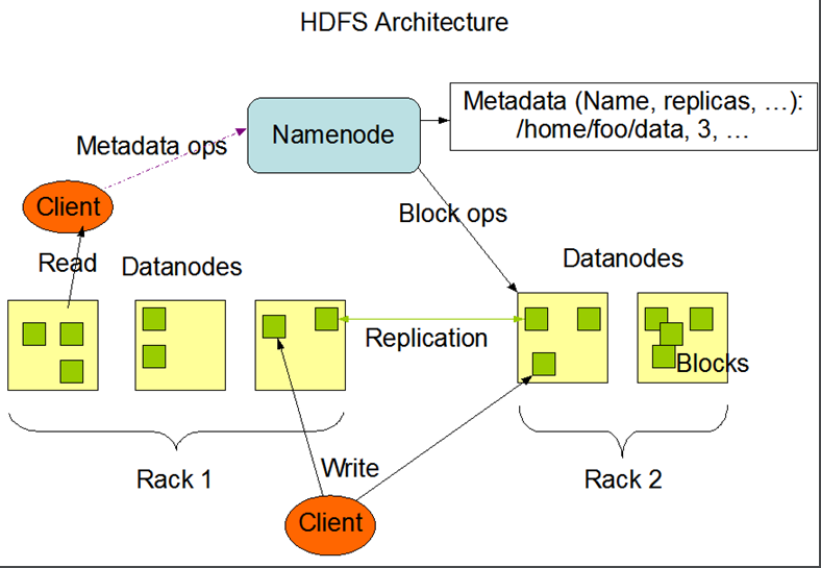
- HDFS集群分為兩大角色:NameNode、DataNode
- NameNode負責管理整個文件系統的元數據
- DataNode 負責管理用戶的文件數據塊block
- 文件會按照固定的大小(blocksize)切成若幹塊後分散式存儲在若幹台datanode上
- 每一個文件塊可以有多個副本,並存放在不同的datanode上
- Datanode會定期向Namenode彙報自身所保存的文件block信息,而namenode則會負責保持文件的副本數量
- HDFS的內部工作機制對客戶端保持透明,客戶端請求訪問HDFS都是通過向namenode申請來進行
- 集群中主機分別放置在不同的機架(rack)中
NO.2 寫入過程分析
客戶端要向HDFS寫數據,首先要跟namenode通信以確認“可以寫文件”並獲得接收文件block的datanode,
然後,客戶端按順序將文件逐個block傳遞給相應datanode,並由接收到block的datanode負責向其他datanode複製block的副本 。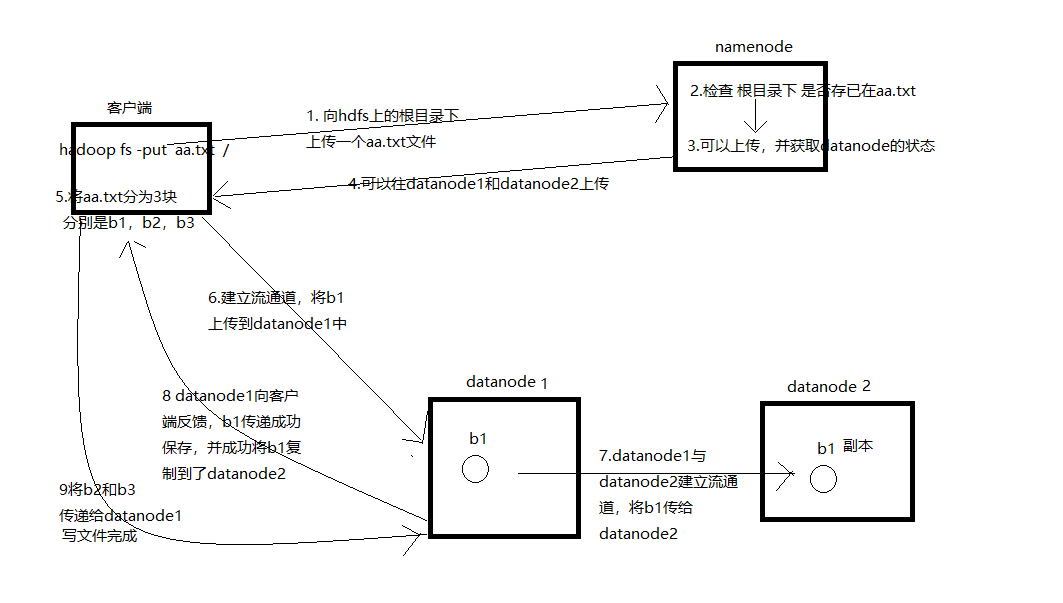
NO.3 數據存儲位置與複製詳解
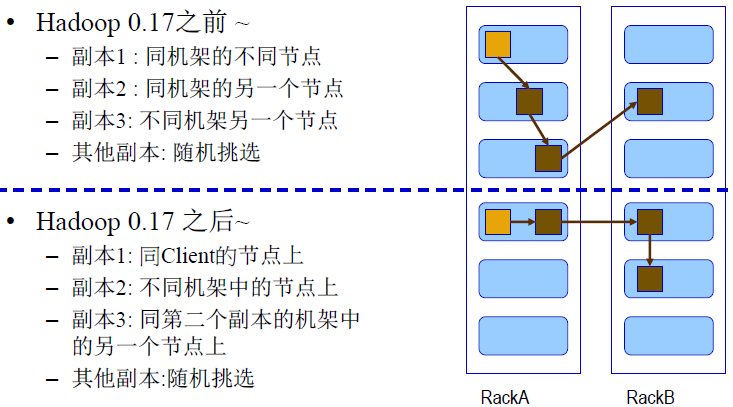
- 同一節點上的存儲數據
- 同一機架上不同節點上的存儲數據
- 同一數據中心不同機架上的存儲數據
- 不同數據中心的節點
HDFS 數據存放策略就是採用同節點與同機架並行的存儲方式。在運行客戶端的當前節點上存放第一個副本,第二個副本存放在於第一個副本不同的機架上的節點,第三個副本放置的位置與第二個副本在同一個機架上而非同一個節點。
NO.4 巨集觀的代碼實現
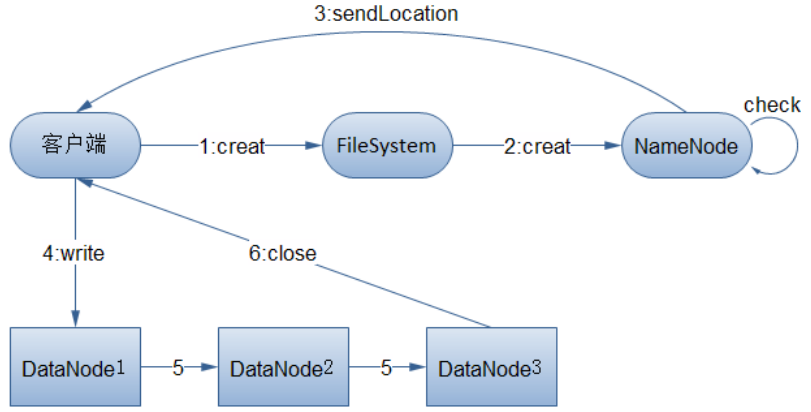
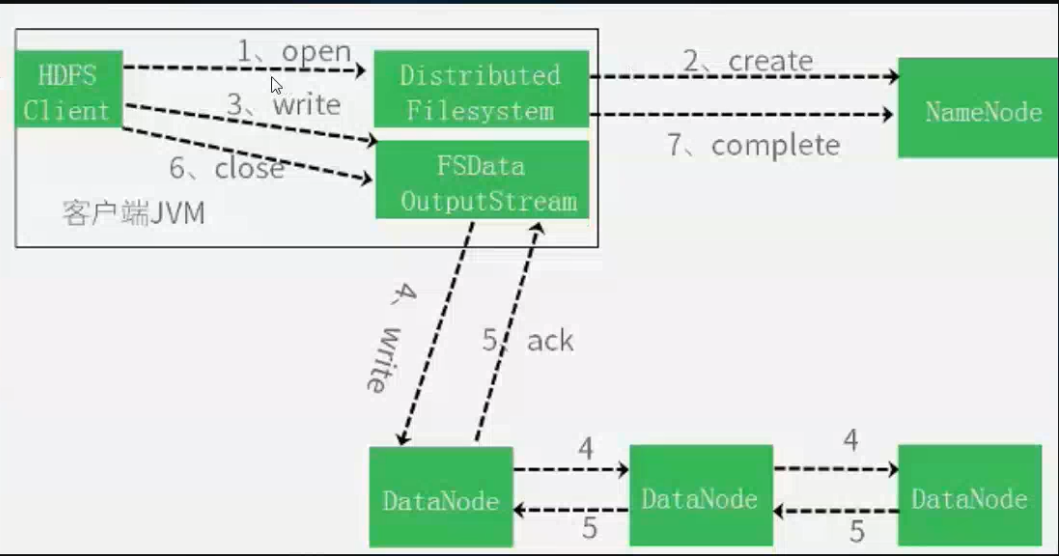
1. Client 通過調用 FileSystem 的 create()方法來請求創建文件
2. FileSystem 通過對 NameNode 發出遠程請求,在 NameNode 裡面創建一個新的文件,但此時並不關聯任何的塊。 NameNode 進行很多檢查來保證不存在要創建的文件已經存在於文件系統中,同時檢查是否有相應的許可權來創建文件。如果這些檢查都完成了,那麼NameNode 將記錄下來這個新文件的信息。 FileSystem 返回一個 FSDataOutputStream 給客戶端用來寫入數據。和讀的情形一樣, FSDataOutputStream 將包裝一個 DFSOutputStream 用於和 DataNode 及 NameNode 通信。而一旦文件創建失敗,客戶端會收到一個 IOExpection,標示文件創建失敗,停止後續任務。
3. 客戶端開始寫數據。 FSDataOutputStream 把要寫入的數據分成包的形式,將其寫入到中間隊列中。其中的數據由 DataStreamer 來讀取。 DataStreamer 的職責是讓 NameNode分配新的塊——通過找出合適的 DataNode——來存儲作為備份而複製的數據。這些DataNode 組成一個流水線,我們假設這個流水線是個三級流水線,那麼裡面將含有三個節點。此時, DataStreamer 將數據首先寫入到流水線中的第一個節點。此後由第一個節點將數據包傳送並寫入到第二個節點,然後第二個將數據包傳送並寫入到第三個節點。
4. FSDataOutputStream 維護了一個內部關於 packets 的隊列,裡面存放等待被DataNode 確認無誤的 packets 的信息。這個隊列稱為等待隊列。一個 packet 的信息被移出本隊列當且僅當 packet 被流水線中的所有節點都確認無誤
5. 當完成數據寫入之後客戶端調用流的 close 方法,在通知 NameNode 完成寫入之前,這個方法將 flush 殘留的 packets,並等待確認信息( acknowledgement)。 NameNode 已經知道文件由哪些塊組成(通過 DataStream 詢問數據塊的分配),所以它在返回成功前只需要等待數據塊進行最小值複製。
NO.5 安全模式
安全模式下,集群屬於只讀狀態。但是嚴格來說,只是保證HDFS元數據信息的訪問,而不保證文件的訪問,因為文件的組成Block信息此時NameNode還不一定已經知道了。所以只有NameNode已瞭解了Block信息的文件才能讀到。而安全模式下任何對HDFS有更新的操作都會失敗。
- 對於全新創建的HDFS集群,NameNode啟動後不會進入安全模式,因為沒有Block信息。
安全模式相關命令
- 查詢當前是否安全模式 hadoop dfsadmin -safemode get Safe mode is ON
- 等待safemode關閉,以便後續操作 hadoop dfsadmin -safemode wait
- 退出安全模式 hadoop dfsadmin -safemode leave
- 設置啟用safemode hadoop dfsadmin -safemode enter
(註: 文檔有參考 ----> https://www.jianshu.com/p/86a70ac1f5f9 )


