
現在很多用戶被資料庫的慢的問題所困擾,又苦於花錢請一個專業的DBA成本太高。軟體維護人員對資料庫的瞭解又不是那麼深入,所以導致問題遲遲不能解決,或只能暫時解決不能得到根治。開發人員解決數據問題基本又是搜遍百度各種方法嘗試個遍,可能錯過診斷問題的最佳時機又可能嘗試一堆方法最後無奈放棄。 怎麼樣讓瑣事纏 ...
現在很多用戶被資料庫的慢的問題所困擾,又苦於花錢請一個專業的DBA成本太高。軟體維護人員對資料庫的瞭解又不是那麼深入,所以導致問題遲遲不能解決,或只能暫時解決不能得到根治。開發人員解決數據問題基本又是搜遍百度各種方法嘗試個遍,可能錯過診斷問題的最佳時機又可能嘗試一堆方法最後無奈放棄。
怎麼樣讓瑣事纏身的程式維護人員,用最快的方式解決資料庫出現的問題?怎麼讓我們程式員的痛苦降低到最小...每天喝喝茶水,看看新聞平安度過一天呢?本系列重要通過Expert for sqlserver 工具講解下資料庫遇到的各種問題的表象及導致這樣問題的根本原因,讓定位問題更準確,解決問題思路更清晰!!
資料庫的性能好壞,對於最終用戶來說表現為點擊的操作是否能夠快速響應,那麼反應到資料庫上就是語句執行時間是否夠短!
對用運維人員資料庫性能的表現,簡單可能看成CPU 、記憶體、磁碟三巨頭指標是否正常,前面講述了CPU和記憶體的基本診斷
Expert 診斷優化系列------------------你的CPU高麽?
Expert 診斷優化系列------------------記憶體不夠用麽?
本篇我們就講述最後的一位巨頭,看看磁碟能夠看出哪些問題!
廢話不多說,直接開整-----------------------------------------------------------------------------------------
磁碟也許對部分軟體運維人員來說,這東西不歸我管!愛咋咋地,速度慢就換SSD,壞了就再買!但是用在資料庫上的磁碟你怎麼能判斷出是,磁碟的問題?不是你資料庫其他問題導致的?磁碟壞了...一般的維護人員就哭了。
磁碟配置的建議
這裡的配置建議主要針對資料庫的磁碟使用,首先我們先明確下物理磁碟和邏輯磁碟的概念。
物理硬碟是硬體實體,即安裝在電腦機箱內的硬碟; 邏輯硬碟是指人為在物理上划出分區以方便存取,管理裡面的文件。
註:當你感覺到磁碟有壓力,並且想用另一塊磁碟幫助分擔這個壓力時,你需要添加的是物理磁碟而不是邏輯磁碟。
SQL SERVER中主要存儲在磁碟,並且主要影響你系統的文件主要有:數據文件、日誌文件、tempDB數據文件(tempDB日誌可以忽略),很多用戶的一臺伺服器上運行這多個資料庫或多實例,那麼針對你的現有資料庫規劃好磁碟分配是第一課!
規劃磁碟分配的好處:假設你有兩個資料庫,業務操作都很繁忙,且讀/寫量都很大對磁碟的壓力都很大,那麼你自然會想到把他們分散到不同的磁碟上,這樣每個庫針對自己的磁碟讀/寫,不會互相影響且壓力相當於原來的1/2,從而可以提升磁碟操作的響應時間。
資料庫磁碟該怎麼劃分? 不同系統不同環境可能都不相同,下麵給出一些簡單建議:
- 按照文件類型劃分:數據文件、日誌文件、tempDB文件、備份文件,分別放在一個物理磁碟(3塊物理磁碟)
- 按照資料庫劃分:不同的業務資料庫(壓力大的)分別放在一個物理磁碟,tempDB和備份文件各一個物理磁碟。
上面的兩種分法是基本的劃分方式,但是根據系統壓力系統配置,均有不同情況。
當你的資料庫壓力較小,或磁碟資源緊張可以做適當的合併。當你的資料庫特別大,並且有多個文件組,也可以選擇把文件組更進一步細分。
類似於做了分區表,不同分區放在不同磁碟上,當需要多個分區數據時,可以利用IO並行提升效率。
如何區分你的磁碟是物理盤還是邏輯盤?
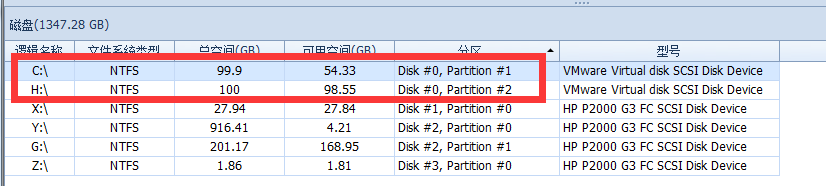
此例中C:H:是同一物理盤,Y:G:是同一物理盤,Y: 和 Z:都是單分區的物理盤。這次中共有4個物理磁碟
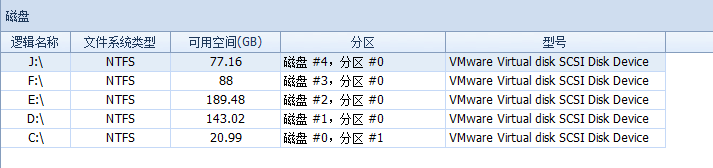
此例中每個都是一個單獨的物理磁碟
註:磁碟信息可以通過系統信息(運行-msinfo32)或通過性能計數器等等手段查看。
下麵看一個文件劃分的例子: (例子使用上面C:D:E:F:J都是單獨物理磁碟)
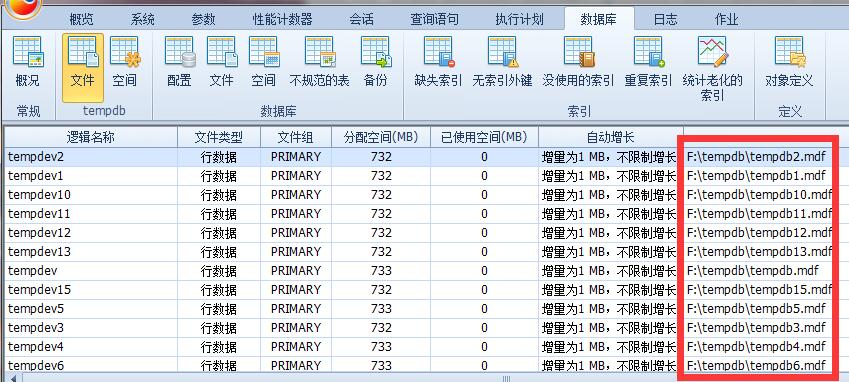
tempDB放在F盤

數據文件(.mdf)放在D盤,日誌文件(.ldf)放在E盤
磁碟壓力的診斷和分析
磁碟的壓力分析,主要使用下麵幾個性能計數器 (針對單獨的物理盤,每個物理磁碟都會有一組):
- Avg. Disk Read Queue Length 讀隊列(越小越好,理想值 2 以下,隊列越高說明一個操作的響應時間越長)
- Avg. Disk Write Queue Length 寫隊列(越小越好,理想值 2 以下,隊列越高說明一個操作的響應時間越長)
- Avg. Disk sec/Read
- Avg. Disk sec/Write
- Disk Read Bytes/sec
- Disk Write Bytes/sec
註:常規判斷系統磁碟壓力,通過讀寫隊列即可判斷,後面4個主要用於磁碟是否自身性能存在問題,本文不介紹。
首先有哪些情況會對磁碟造成壓力?
- 記憶體不足導致需要頻繁和磁碟交互 (一般為主因)
- 經常有大量冷數據需要從磁碟讀取,或經常有大批量臟頁一次寫入(checkpoint觸發)
- 磁碟讀寫速度,不能滿足業務需要
為什麼記憶體不足會導致磁碟壓力大?
上一篇介紹了,記憶體這三個計數器是如何聯動的?
Page life expectancy 不被使用的頁在緩存中停留的秒數,如果低說明記憶體壓力
Page Reads/sec 所要讀的數據不在記憶體中需要物理讀取
Lazy writes/sec 記憶體壓力時成批的刷新老化緩衝區
磁碟的讀寫計數器:Avg. Disk Write Queue Length和Avg. Disk Read Queue Length和記憶體計數器很大程度上也是聯動的!
當一個操作需要大量讀取數據,且數據頁不在緩存中 ——》 那麼需要大量從磁碟讀取冷數據放入緩存(Page Reads/sec 升高,Avg. Disk Read Queue Length升高) ——》緩存有明顯壓力的時候Lazy writes/sec就會觸發(Lazy writes/sec升高),大批量的將老化的數據或緩存計劃等刷出緩存 ——》數據被清出緩存(有臟頁需要寫入磁碟Avg. Disk Write Queue Length),那麼頁生命周期就會下降(Page life expectancy)
——》
借用上一篇 Expert 診斷優化系列------------------記憶體不夠用麽? 三小時一次記憶體的例子,我們看看磁碟是什麼樣的表現
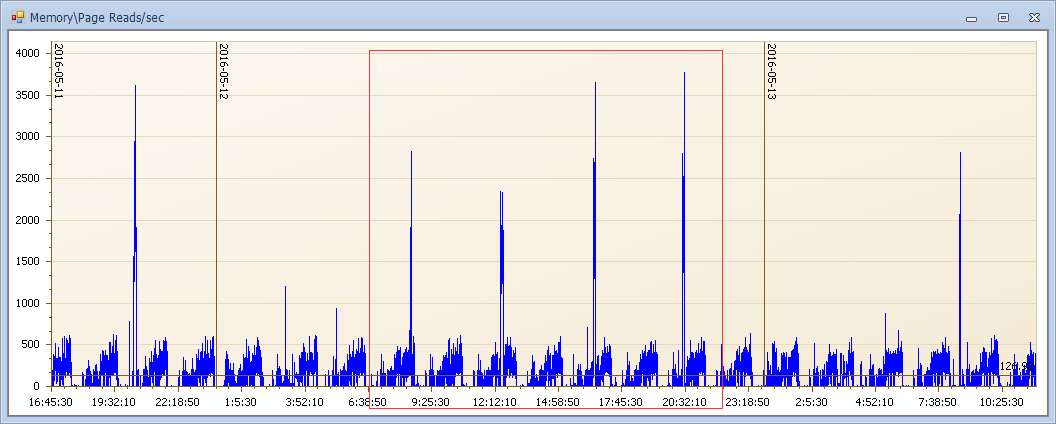
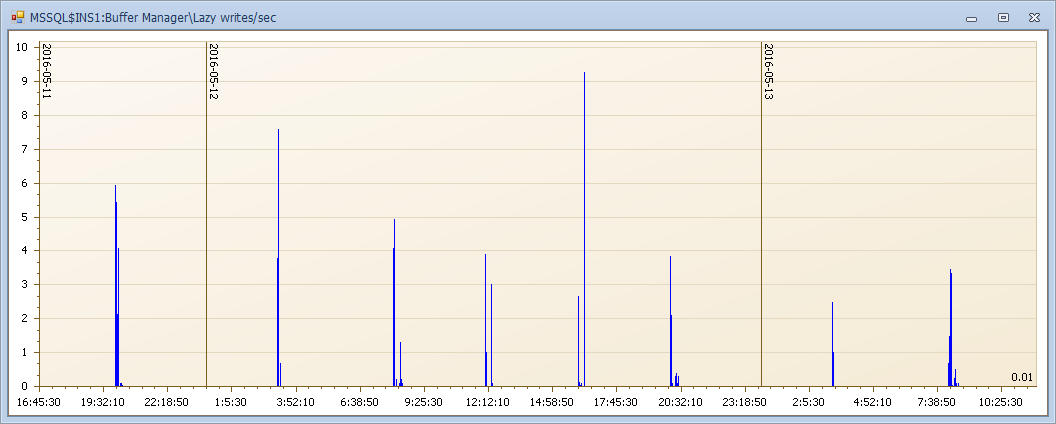
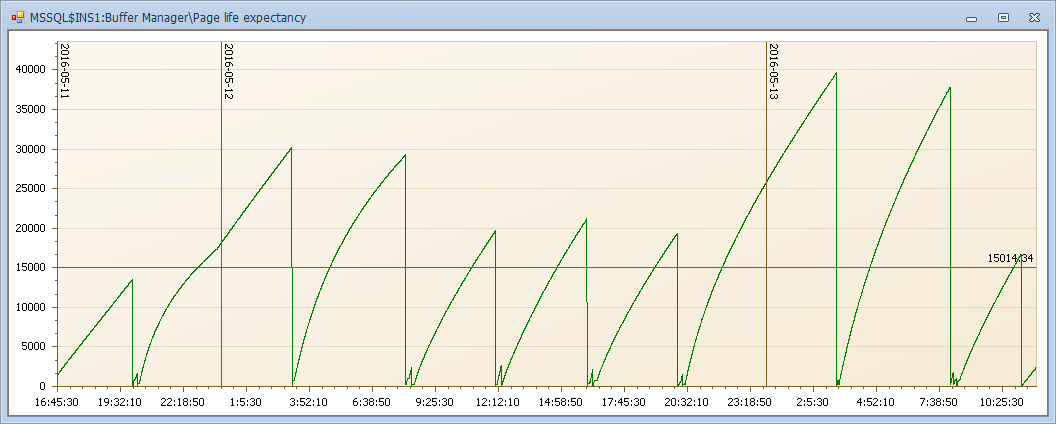
這內規律波動,記憶體壓力很有規律,記憶體壓力不過多介紹請參見上一篇。我們看看磁碟對應時間點的計數器是什麼樣子的? 你能想想到麽?
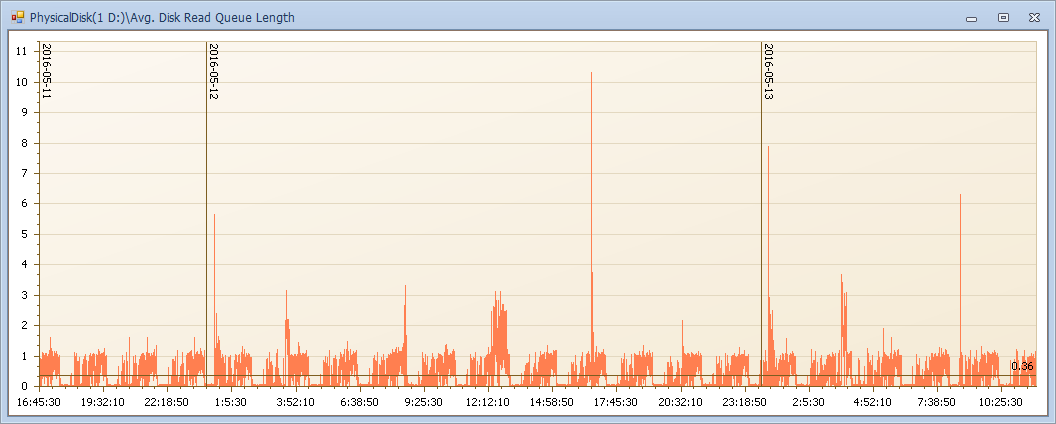
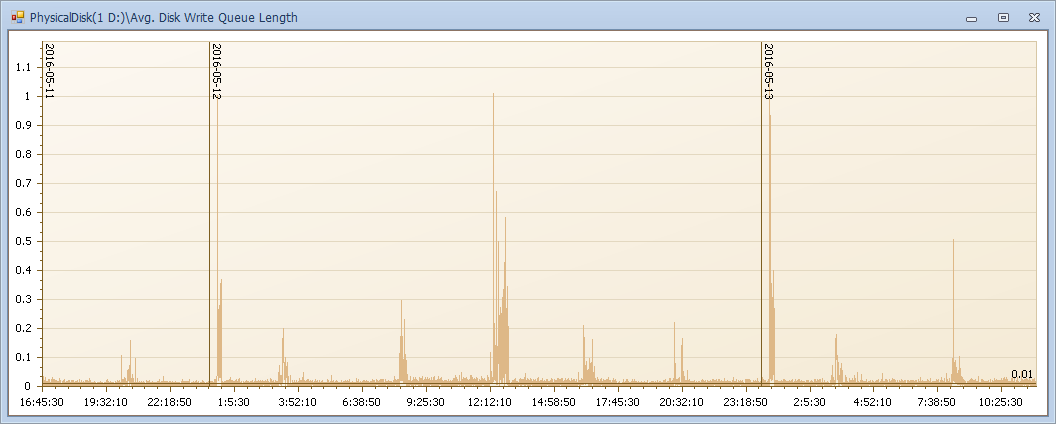
是不是規律很強?這個例子展示了磁碟壓力和記憶體的聯動,也說明當你看到磁碟隊列很高的時候,不要輕易定位磁碟的問題,先看看當前系統記憶體是怎麼樣的狀態吧。
藉助上一篇第二個,記憶體嚴重不足的例子:
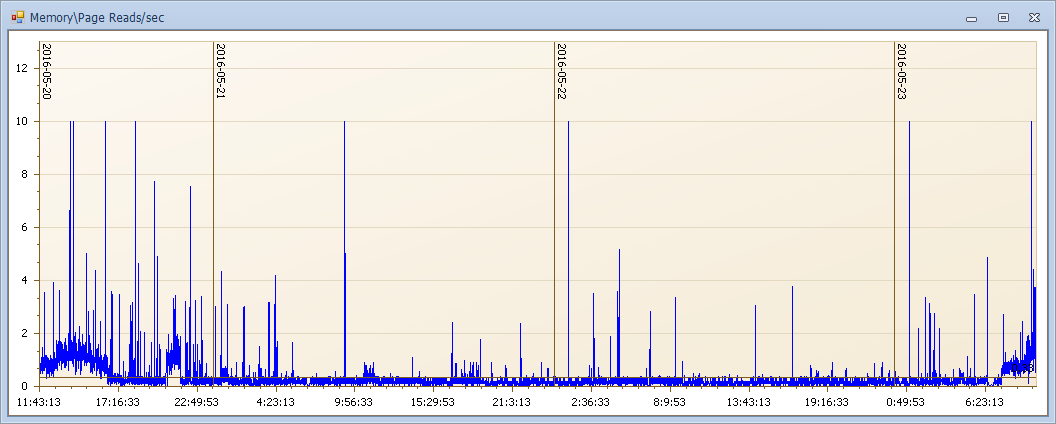


我們來看看這麼大記憶體的壓力下,磁碟是什麼狀態,我想已經不用我說過多了。
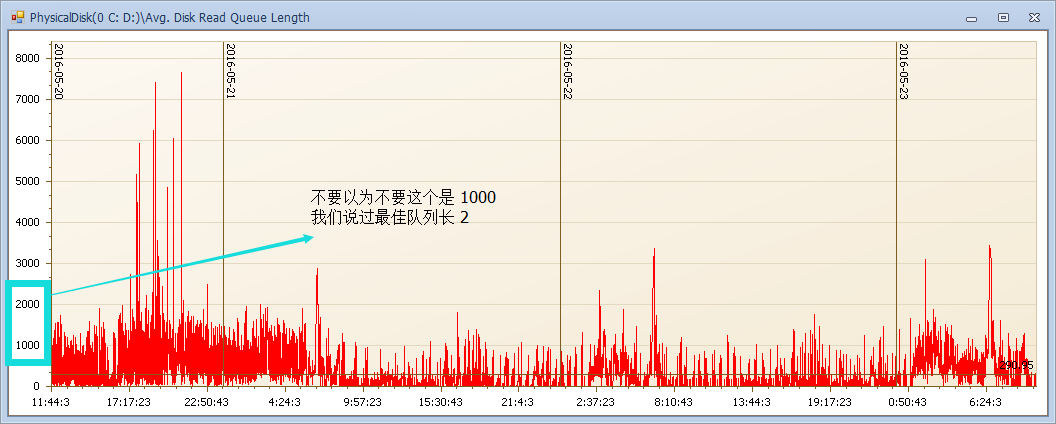
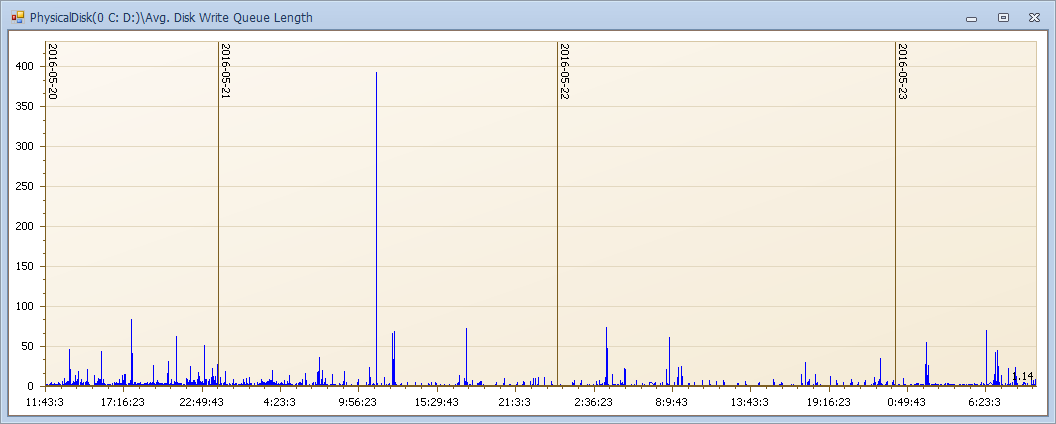
高能預警:隊列高可能,不那麼直觀的說明啥,下麵我們來看一下這麼高隊列下的響應時間。每次和磁碟交互就要有1秒以上的磁碟響應時間(正常幾毫秒),那麼一個語句多次交互會是什麼樣的效果?
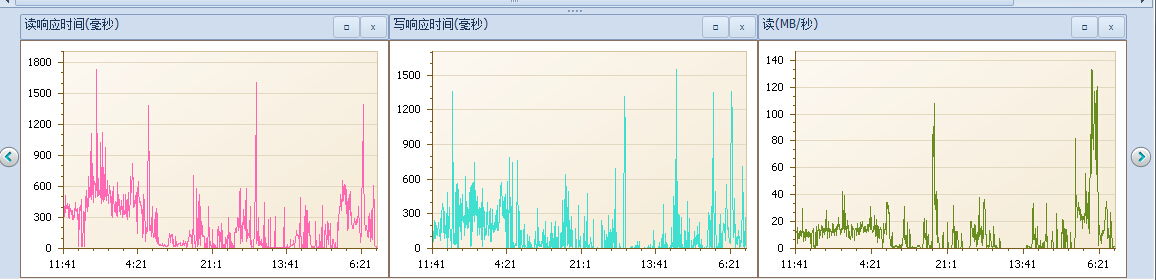
----------------------------------------------------------------------------------
至此我們瞭解到了,系統磁碟隊列高的根本原因是由於記憶體不足導致的,那麼我們拋開記憶體壓力不談,遇到上面的情況我們怎麼緩解磁碟壓力呢???
那就是前面提到的用多塊磁碟分擔這個壓力或選用速度更快的。
看一下這個系統的磁碟及資料庫文件分佈

可以看到這個伺服器只配置了一塊物理磁碟
資料庫1

資料庫2
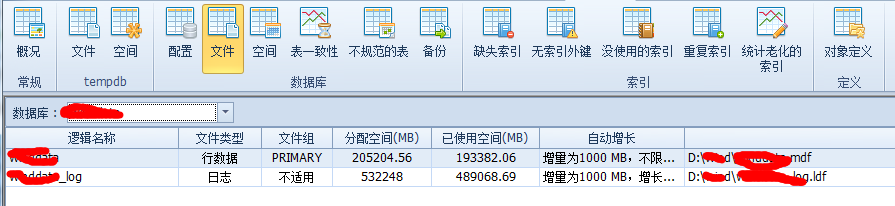
tempDB

2個業務頻繁的大資料庫,數據文件、日誌文件和系統tempDB都在同一個磁碟上!
如果有其他物理磁碟可以分攤壓力,讀寫隊列會有降低,讀寫響應時間也會大幅縮短,但我們不能忽略根本原因是記憶體的超大壓力!
最佳的優化效果,當然即做記憶體做優化(請參見上一篇 Expert 診斷優化系列------------------記憶體不夠用麽? ) 又按照最佳的實踐把文件分散到多個磁碟分擔壓力。
-----------------------------------------------------------------------------------------------------
總結:現在硬體成本越來越低,很多用戶都採用SSD或高級存儲等,直接以提升硬體的方式對系統做出優化。
但本文主要介紹了磁碟壓力的主因是記憶體不足引起的,記憶體不足又很大程度是語句寫的太差,或明顯缺少索引導致。
不要讓一個很簡單調優就能解決的問題,升級為要花高價換硬體。
不能否認提升硬體效果肯定會有,但是找出系統真正的原因,對症下藥更為重要。
----------------------------------------------------------------------------------------------------
註:此文章為原創,歡迎轉載,請在文章頁面明顯位置給出此文鏈接!
若您覺得這篇文章還不錯請點擊下右下角的推薦,非常感謝!
引用高大俠的一句話 :“拒絕SQL Server背鍋,從我做起!”


