
今天看到一篇講解設計模式六大原則的文章,非常深刻細緻,轉過來給大家共同學習。 作者:zhengzhb ,發佈於2012-11-2,來源:CSDN 作者:zhengzhb ,發佈於2012-11-2,來源:CSDN 設計模式六大原則(1):單一職責原則 定義:不要存在多於一個導致類變更的原因。通俗的說 ...
今天看到一篇講解設計模式六大原則的文章,非常深刻細緻,轉過來給大家共同學習。
|
作者:zhengzhb ,發佈於2012-11-2,來源:CSDN |
定義:不要存在多於一個導致類變更的原因。通俗的說,即一個類只負責一項職責。
問題由來:類T負責兩個不同的職責:職責P1,職責P2。當由於職責P1需求發生改變而需要修改類T時,有可能會導致原本運行正常的職責P2功能發生故障。
解決方案:遵循單一職責原則。分別建立兩個類T1、T2,使T1完成職責P1功能,T2完成職責P2功能。這樣,當修改類T1時,不會使職責P2發生故障風險;同理,當修改T2時,也不會使職責P1發生故障風險。
說到單一職責原則,很多人都會不屑一顧。因為它太簡單了。稍有經驗的程式員即使從來沒有讀過設計模式、從來沒有聽說過單一職責原則,在設計軟體時也會自覺的遵守這一重要原則,因為這是常識。在軟體編程中,誰也不希望因為修改了一個功能導致其他的功能發生故障。而避免出現這一問題的方法便是遵循單一職責原則。雖然單一職責原則如此簡單,並且被認為是常識,但是即便是經驗豐富的程式員寫出的程式,也會有違背這一原則的代碼存在。為什麼會出現這種現象呢?因為有職責擴散。所謂職責擴散,就是因為某種原因,職責P被分化為粒度更細的職責P1和P2。
比如:類T只負責一個職責P,這樣設計是符合單一職責原則的。後來由於某種原因,也許是需求變更了,也許是程式的設計者境界提高了,需要將職責P細分為粒度更細的職責P1,P2,這時如果要使程式遵循單一職責原則,需要將類T也分解為兩個類T1和T2,分別負責P1、P2兩個職責。但是在程式已經寫好的情況下,這樣做簡直太費時間了。所以,簡單的修改類T,用它來負責兩個職責是一個比較不錯的選擇,雖然這樣做有悖於單一職責原則。(這樣做的風險在於職責擴散的不確定性,因為我們不會想到這個職責P,在未來可能會擴散為P1,P2,P3,P4……Pn。所以記住,在職責擴散到我們無法控制的程度之前,立刻對代碼進行重構。)
舉例說明,用一個類描述動物呼吸這個場景:
class Animal{
public void breathe(String animal){
System.out.println(animal+"呼吸空氣");
}
}
public class Client{
public static void main(String[] args){
Animal animal = new Animal();
animal.breathe("牛");
animal.breathe("羊");
animal.breathe("豬");
}
}
|
運行結果:
牛呼吸空氣
羊呼吸空氣
豬呼吸空氣
程式上線後,發現問題了,並不是所有的動物都呼吸空氣的,比如魚就是呼吸水的。修改時如果遵循單一職責原則,需要將Animal類細分為陸生動物類Terrestrial,水生動物Aquatic,代碼如下:
class Terrestrial{
public void breathe(String animal){
System.out.println(animal+"呼吸空氣");
}
}
class Aquatic{
public void breathe(String animal){
System.out.println(animal+"呼吸水");
}
}
public class Client{
public static void main(String[] args){
Terrestrial terrestrial = new Terrestrial();
terrestrial.breathe("牛");
terrestrial.breathe("羊");
terrestrial.breathe("豬");
Aquatic aquatic = new Aquatic();
aquatic.breathe("魚");
}
}
|
運行結果:
牛呼吸空氣
羊呼吸空氣
豬呼吸空氣
魚呼吸水
我們會發現如果這樣修改花銷是很大的,除了將原來的類分解之外,還需要修改客戶端。而直接修改類Animal來達成目的雖然違背了單一職責原則,但花銷卻小的多,代碼如下:
class Animal{
public void breathe(String animal){
if("魚".equals(animal)){
System.out.println(animal+"呼吸水");
}else{
System.out.println(animal+"呼吸空氣");
}
}
}
public class Client{
public static void main(String[] args){
Animal animal = new Animal();
animal.breathe("牛");
animal.breathe("羊");
animal.breathe("豬");
animal.breathe("魚");
}
}
|
可以看到,這種修改方式要簡單的多。但是卻存在著隱患:有一天需要將魚分為呼吸淡水的魚和呼吸海水的魚,則又需要修改Animal類的breathe方法,而對原有代碼的修改會對調用“豬”“牛”“羊”等相關功能帶來風險,也許某一天你會發現程式運行的結果變為“牛呼吸水”了。這種修改方式直接在代碼級別上違背了單一職責原則,雖然修改起來最簡單,但隱患卻是最大的。還有一種修改方式:
class Animal{
public void breathe(String animal){
System.out.println(animal+"呼吸空氣");
}
public void breathe2(String animal){
System.out.println(animal+"呼吸水");
}
}
public class Client{
public static void main(String[] args){
Animal animal = new Animal();
animal.breathe("牛");
animal.breathe("羊");
animal.breathe("豬");
animal.breathe2("魚");
}
}
|
可以看到,這種修改方式沒有改動原來的方法,而是在類中新加了一個方法,這樣雖然也違背了單一職責原則,但在方法級別上卻是符合單一職責原則的,因為它並沒有動原來方法的代碼。這三種方式各有優缺點,那麼在實際編程中,採用哪一中呢?其實這真的比較難說,需要根據實際情況來確定。我的原則是:只有邏輯足夠簡單,才可以在代碼級別上違反單一職責原則;只有類中方法數量足夠少,才可以在方法級別上違反單一職責原則;
例如本文所舉的這個例子,它太簡單了,它只有一個方法,所以,無論是在代碼級別上違反單一職責原則,還是在方法級別上違反,都不會造成太大的影響。實際應用中的類都要複雜的多,一旦發生職責擴散而需要修改類時,除非這個類本身非常簡單,否則還是遵循單一職責原則的好。
遵循單一職責原的優點有:
- 可以降低類的複雜度,一個類只負責一項職責,其邏輯肯定要比負責多項職責簡單的多;
- 提高類的可讀性,提高系統的可維護性;
- 變更引起的風險降低,變更是必然的,如果單一職責原則遵守的好,當修改一個功能時,可以顯著降低對其他功能的影響。
需要說明的一點是單一職責原則不只是面向對象編程思想所特有的,只要是模塊化的程式設計,都適用單一職責原則。
肯定有不少人跟我剛看到這項原則的時候一樣,對這個原則的名字充滿疑惑。其實原因就是這項原則最早是在1988年,由麻省理工學院的一位姓里的女士(Barbara Liskov)提出來的。
定義1:如果對每一個類型為 T1的對象 o1,都有類型為 T2 的對象o2,使得以 T1定義的所有程式 P 在所有的對象 o1 都代換成 o2 時,程式 P 的行為沒有發生變化,那麼類型 T2 是類型 T1 的子類型。
定義2:所有引用基類的地方必須能透明地使用其子類的對象。
問題由來:有一功能P1,由類A完成。現需要將功能P1進行擴展,擴展後的功能為P,其中P由原有功能P1與新功能P2組成。新功能P由類A的子類B來完成,則子類B在完成新功能P2的同時,有可能會導致原有功能P1發生故障。
解決方案:當使用繼承時,遵循里氏替換原則。類B繼承類A時,除添加新的方法完成新增功能P2外,儘量不要重寫父類A的方法,也儘量不要重載父類A的方法。
繼承包含這樣一層含義:父類中凡是已經實現好的方法(相對於抽象方法而言),實際上是在設定一系列的規範和契約,雖然它不強制要求所有的子類必須遵從這些契約,但是如果子類對這些非抽象方法任意修改,就會對整個繼承體系造成破壞。而里氏替換原則就是表達了這一層含義。
繼承作為面向對象三大特性之一,在給程式設計帶來巨大便利的同時,也帶來了弊端。比如使用繼承會給程式帶來侵入性,程式的可移植性降低,增加了對象間的耦合性,如果一個類被其他的類所繼承,則當這個類需要修改時,必須考慮到所有的子類,並且父類修改後,所有涉及到子類的功能都有可能會產生故障。
舉例說明繼承的風險,我們需要完成一個兩數相減的功能,由類A來負責。
class A{
public int func1(int a, int b){
return a-b;
}
}
public class Client{
public static void main(String[] args){
A a = new A();
System.out.println("100-50="+a.func1(100, 50));
System.out.println("100-80="+a.func1(100, 80));
}
}
|
運行結果:
100-50=50
100-80=20
後來,我們需要增加一個新的功能:完成兩數相加,然後再與100求和,由類B來負責。即類B需要完成兩個功能:
- 兩數相減。
- 兩數相加,然後再加100。
由於類A已經實現了第一個功能,所以類B繼承類A後,只需要再完成第二個功能就可以了,代碼如下:
class B extends A{
public int func1(int a, int b){
return a+b;
}
public int func2(int a, int b){
return func1(a,b)+100;
}
}
public class Client{
public static void main(String[] args){
B b = new B();
System.out.println("100-50="+b.func1(100, 50));
System.out.println("100-80="+b.func1(100, 80));
System.out.println("100+20+100="+b.func2(100, 20));
}
}
|
類B完成後,運行結果:
100-50=150
100-80=180
100+20+100=220
我們發現原本運行正常的相減功能發生了錯誤。原因就是類B在給方法起名時無意中重寫了父類的方法,造成所有運行相減功能的代碼全部調用了類B重寫後的方法,造成原本運行正常的功能出現了錯誤。在本例中,引用基類A完成的功能,換成子類B之後,發生了異常。在實際編程中,我們常常會通過重寫父類的方法來完成新的功能,這樣寫起來雖然簡單,但是整個繼承體系的可復用性會比較差,特別是運用多態比較頻繁時,程式運行出錯的幾率非常大。如果非要重寫父類的方法,比較通用的做法是:原來的父類和子類都繼承一個更通俗的基類,原有的繼承關係去掉,採用依賴、聚合,組合等關係代替。
里氏替換原則通俗的來講就是:子類可以擴展父類的功能,但不能改變父類原有的功能。它包含以下4層含義:
- 子類可以實現父類的抽象方法,但不能覆蓋父類的非抽象方法。
- 子類中可以增加自己特有的方法。
- 當子類的方法重載父類的方法時,方法的前置條件(即方法的形參)要比父類方法的輸入參數更寬鬆。
- 當子類的方法實現父類的抽象方法時,方法的後置條件(即方法的返回值)要比父類更嚴格。
看上去很不可思議,因為我們會發現在自己編程中常常會違反里氏替換原則,程式照樣跑的好好的。所以大家都會產生這樣的疑問,假如我非要不遵循里氏替換原則會有什麼後果?
後果就是:你寫的代碼出問題的幾率將會大大增加。
定義:高層模塊不應該依賴低層模塊,二者都應該依賴其抽象;抽象不應該依賴細節;細節應該依賴抽象。
問題由來:類A直接依賴類B,假如要將類A改為依賴類C,則必須通過修改類A的代碼來達成。這種場景下,類A一般是高層模塊,負責複雜的業務邏輯;類B和類C是低層模塊,負責基本的原子操作;假如修改類A,會給程式帶來不必要的風險。
解決方案:將類A修改為依賴介面I,類B和類C各自實現介面I,類A通過介面I間接與類B或者類C發生聯繫,則會大大降低修改類A的幾率。
依賴倒置原則基於這樣一個事實:相對於細節的多變性,抽象的東西要穩定的多。以抽象為基礎搭建起來的架構比以細節為基礎搭建起來的架構要穩定的多。在java中,抽象指的是介面或者抽象類,細節就是具體的實現類,使用介面或者抽象類的目的是制定好規範和契約,而不去涉及任何具體的操作,把展現細節的任務交給他們的實現類去完成。
依賴倒置原則的核心思想是面向介面編程,我們依舊用一個例子來說明面向介面編程比相對於面向實現編程好在什麼地方。場景是這樣的,母親給孩子講故事,只要給她一本書,她就可以照著書給孩子講故事了。代碼如下:
class Book{
public String getContent(){
return "很久很久以前有一個阿拉伯的故事……";
}
}
class Mother{
public void narrate(Book book){
System.out.println("媽媽開始講故事");
System.out.println(book.getContent());
}
}
public class Client{
public static void main(String[] args){
Mother mother = new Mother();
mother.narrate(new Book());
}
}
|
運行結果:
媽媽開始講故事
很久很久以前有一個阿拉伯的故事……
運行良好,假如有一天,需求變成這樣:不是給書而是給一份報紙,讓這位母親講一下報紙上的故事,報紙的代碼如下:
class Newspaper{
public String getContent(){
return "林書豪38+7領導尼克斯擊敗湖人……";
}
}
|
這位母親卻辦不到,因為她居然不會讀報紙上的故事,這太荒唐了,只是將書換成報紙,居然必須要修改Mother才能讀。假如以後需求換成雜誌呢?換成網頁呢?還要不斷地修改Mother,這顯然不是好的設計。原因就是Mother與Book之間的耦合性太高了,必須降低他們之間的耦合度才行。
我們引入一個抽象的介面IReader。讀物,只要是帶字的都屬於讀物:
interface IReader{
public String getContent();
}
|
Mother類與介面IReader發生依賴關係,而Book和Newspaper都屬於讀物的範疇,他們各自都去實現IReader介面,這樣就符合依賴倒置原則了,代碼修改為:
class Newspaper implements IReader {
public String getContent(){
return "林書豪17+9助尼克斯擊敗老鷹……";
}
}
class Book implements IReader{
public String getContent(){
return "很久很久以前有一個阿拉伯的故事……";
}
}
class Mother{
public void narrate(IReader reader){
System.out.println("媽媽開始講故事");
System.out.println(reader.getContent());
}
}
public class Client{
public static void main(String[] args){
Mother mother = new Mother();
mother.narrate(new Book());
mother.narrate(new Newspaper());
}
}
|
運行結果:
媽媽開始講故事
很久很久以前有一個阿拉伯的故事……
媽媽開始講故事
林書豪17+9助尼克斯擊敗老鷹……
這樣修改後,無論以後怎樣擴展Client類,都不需要再修改Mother類了。這隻是一個簡單的例子,實際情況中,代表高層模塊的Mother類將負責完成主要的業務邏輯,一旦需要對它進行修改,引入錯誤的風險極大。所以遵循依賴倒置原則可以降低類之間的耦合性,提高系統的穩定性,降低修改程式造成的風險。
採用依賴倒置原則給多人並行開髮帶來了極大的便利,比如上例中,原本Mother類與Book類直接耦合時,Mother類必須等Book類編碼完成後才可以進行編碼,因為Mother類依賴於Book類。修改後的程式則可以同時開工,互不影響,因為Mother與Book類一點關係也沒有。參與協作開發的人越多、項目越龐大,採用依賴導致原則的意義就越重大。現在很流行的TDD開發模式就是依賴倒置原則最成功的應用。
傳遞依賴關係有三種方式,以上的例子中使用的方法是介面傳遞,另外還有兩種傳遞方式:構造方法傳遞和setter方法傳遞,相信用過Spring框架的,對依賴的傳遞方式一定不會陌生。
在實際編程中,我們一般需要做到如下3點:
- 低層模塊儘量都要有抽象類或介面,或者兩者都有。
- 變數的聲明類型儘量是抽象類或介面。
- 使用繼承時遵循里氏替換原則。
依賴倒置原則的核心就是要我們面向介面編程,理解了面向介面編程,也就理解了依賴倒置。
定義:客戶端不應該依賴它不需要的介面;一個類對另一個類的依賴應該建立在最小的介面上。
問題由來:類A通過介面I依賴類B,類C通過介面I依賴類D,如果介面I對於類A和類B來說不是最小介面,則類B和類D必須去實現他們不需要的方法。
解決方案:將臃腫的介面I拆分為獨立的幾個介面,類A和類C分別與他們需要的介面建立依賴關係。也就是採用介面隔離原則。
舉例來說明介面隔離原則:
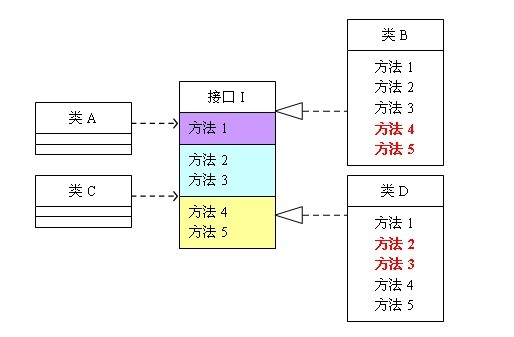
(圖1 未遵循介面隔離原則的設計)
這個圖的意思是:類A依賴介面I中的方法1、方法2、方法3,類B是對類A依賴的實現。類C依賴介面I中的方法1、方法4、方法5,類D是對類C依賴的實現。對於類B和類D來說,雖然他們都存在著用不到的方法(也就是圖中紅色字體標記的方法),但由於實現了介面I,所以也必須要實現這些用不到的方法。對類圖不熟悉的可以參照程式代碼來理解,代碼如下:
interface I {
public void method1();
public void method2();
public void method3();
public void method4();
public void method5();
}
class A{
public void depend1(I i){
i.method1();
}
public void depend2(I i){
i.method2();
}
public void depend3(I i){
i.method3();
}
}
class B implements I{
public void method1() {
System.out.println("類B實現介面I的方法1");
}
public void method2() {
System.out.println("類B實現介面I的方法2");
}
public void method3() {
System.out.println("類B實現介面I的方法3");
}
//對於類B來說,method4和method5不是必需的,但是由於介面A中有這兩個方法,
//所以在實現過程中即使這兩個方法的方法體為空,也要將這兩個沒有作用的方法進行實現。
public void method4() {}
public void method5() {}
}
class C{
public void depend1(I i){
i.method1();
}
public void depend2(I i){
i.method4();
}
public void depend3(I i){
i.method5();
}
}
class D implements I{
public void method1() {
System.out.println("類D實現介面I的方法1");
}
//對於類D來說,method2和method3不是必需的,但是由於介面A中有這兩個方法,
//所以在實現過程中即使這兩個方法的方法體為空,也要將這兩個沒有作用的方法進行實現。
public void method2() {}
public void method3() {}
public void method4() {
System.out.println("類D實現介面I的方法4");
}
public void method5() {
System.out.println("類D實現介面I的方法5");
}
}
public class Client{
public static void main(String[] args){
A a = new A();
a.depend1(new B());
a.depend2(new B());
a.depend3(new B());
C c = new C();
c.depend1(new D());
c.depend2(new D());
c.depend3(new D());
}
}
|
可以看到,如果介面過於臃腫,只要介面中出現的方法,不管對依賴於它的類有沒有用處,實現類中都必須去實現這些方法,這顯然不是好的設計。如果將這個設計修改為符合介面隔離原則,就必須對介面I進行拆分。在這裡我們將原有的介面I拆分為三個介面,拆分後的設計如圖2所示:
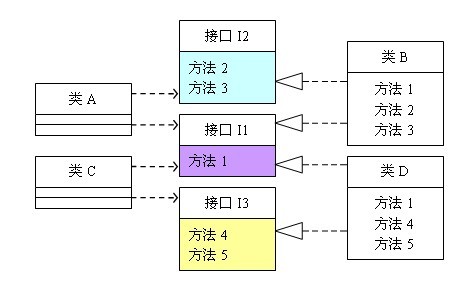
(圖2 遵循介面隔離原則的設計)
照例貼出程式的代碼,供不熟悉類圖的朋友參考:
interface I1 {
public void method1();
}
interface I2 {
public void method2();
public void method3();
}
interface I3 {
public void method4();
public void method5();
}
class A{
public void depend1(I1 i){
i.method1();
}
public void depend2(I2 i){
i.method2();
}
public void depend3(I2 i){
i.method3();
}
}
class B implements I1, I2{
public void method1() {
System.out.println("類B實現介面I1的方法1");
}
public void method2() {
System.out.println("類B實現介面I2的方法2");
}
public void method3() {
System.out.println("類B實現介面I2的方法3");
}
}
class C{
public void depend1(I1 i){
i.method1();
}
public void depend2(I3 i){
i.method4();
}
public void depend3(I3 i){
i.method5();
}
}
class D implements I1, I3{
public void method1() {
System.out.println("類D實現介面I1的方法1");
}
public void method4() {
System.out.println("類D實現介面I3的方法4");
}
public void method5() {
System.out.println("類D實現介面I3的方法5");
}
}
|
介面隔離原則的含義是:建立單一介面,不要建立龐大臃腫的介面,儘量細化介面,介面中的方法儘量少。也就是說,我們要為各個類建立專用的介面,而不要試圖去建立一個很龐大的介面供所有依賴它的類去調用。本文例子中,將一個龐大的介面變更為3個專用的介面所採用的就是介面隔離原則。在程式設計中,依賴幾個專用的介面要比依賴一個綜合的介面更靈活。介面是設計時對外部設定的“契約”,通過分散定義多個介面,可以預防外來變更的擴散,提高系統的靈活性和可維護性。
說到這裡,很多人會覺的介面隔離原則跟之前的單一職責原則很相似,其實不然。其一,單一職責原則原註重的是職責;而介面隔離原則註重對介面依賴的隔離。其二,單一職責原則主要是約束類,其次才是介面和方法,它針對的是程式中的實現和細節;而介面隔離原則主要約束介面介面,主要針對抽象,針對程式整體框架的構建。
採用介面隔離原則對介面進行約束時,要註意以下幾點:
- 介面儘量小,但是要有限度。對介面進行細化可以提高程式設計靈活性是不掙的事實,但是如果過小,則會造成介面數量過多,使設計複雜化。所以一定要適度。
- 為依賴介面的類定製服務,只暴露給調用的類它需要的方法,它不需要的方法則隱藏起來。只有專註地為一個模塊提供定製服務,才能建立最小的依賴關係。
- 提高內聚,減少對外交互。使介面用最少的方法去完成最多的事情。
運用介面隔離原則,一定要適度,介面設計的過大或過小都不好。設計介面的時候,只有多花些時間去思考和籌劃,才能準確地實踐這一原則。
定義:一個對象應該對其他對象保持最少的瞭解。
問題由來:類與類之間的關係越密切,耦合度越大,當一個類發生改變時,對另一個類的影響也越大。
解決方案:儘量降低類與類之間的耦合。
自從我們接觸編程開始,就知道了軟體編程的總的原則:低耦合,高內聚。無論是面向過程編程還是面向對象編程,只有使各個模塊之間的耦合儘量的低,才能提高代碼的復用率。低耦合的優點不言而喻,但是怎麼樣編程才能做到低耦合呢?那正是迪米特法則要去完成的。
迪米特法則又叫最少知道原則,最早是在1987年由美國Northeastern University的Ian Holland提出。通俗的來講,就是一個類對自己依賴的類知道的越少越好。也就是說,對於被依賴的類來說,無論邏輯多麼複雜,都儘量地的將邏輯封裝在類的內部,對外除了提供的public方法,不對外泄漏任何信息。迪米特法則還有一個更簡單的定義:只與直接的朋友通信。首先來解釋一下什麼是直接的朋友:每個對象都會與其他對象有耦合關係,只要兩個對象之間有耦合關係,我們就說這兩個對象之間是朋友關係。耦合的方式很多,依賴、關聯、組合、聚合等。其中,我們稱出現成員變數、方法參數、方法返回值中的類為直接的朋友,而出現在局部變數中的類則不是直接的朋友。也就是說,陌生的類最好不要作為局部變數的形式出現在類的內部。
舉一個例子:有一個集團公司,下屬單位有分公司和直屬部門,現在要求列印出所有下屬單位的員工ID。先來看一下違反迪米特法則的設計。
//總公司員工
class Employee{
private String id;
public void setId(String id){
this.id = id;
}
public String getId(){
return id;
}
}
//分公司員工
class SubEmployee{
private String id;
public void setId(String id){
this.id = id;
}
public String getId(){
return id;
}
}
class SubCompanyManager{
public List<SubEmployee> getAllEmployee(){
List<SubEmployee> list = new ArrayList<SubEmployee>();
for(int i=0; i<100; i++){
SubEmployee emp = new SubEmployee();
//為分公司人員按順序分配一個ID
emp.setId("分公司"+i);
list.add(emp);
}
return list;
}
}
class CompanyManager{
public List<Employee> getAllEmployee(){
List<Employee> list = new ArrayList<Employee>();
for(int i=0; i<30; i++){
Employee emp = new Employee();
//為總公司人員按順序分配一個ID
emp.setId("總公司"+i);
list.add(emp);
}
return list;
}
public void printAllEmployee(SubCompanyManager sub){
List<SubEmployee> list1 = sub.getAllEmployee();
for(SubEmployee e:list1){
System.out.println(e.getId());
}
List<Employee> list2 = this.getAllEmployee();
for(Employee e:list2){
System.out.println(e.getId());
}
}
}
public class Client{
public static void main(String[] args){
CompanyManager e = new CompanyManager();
e.printAllEmployee(new SubCompanyManager());
}
}
|
現在這個設計的主要問題出在CompanyManager中,根據迪米特法則,只與直接的朋友發生通信,而SubEmployee類並不是CompanyManager類的直接朋友(以局部變數出現的耦合不屬於直接朋友),從邏輯上講總公司只與他的分公司耦合就行了,與分公司的員工並沒有任何聯繫,這樣設計顯然是增加了不必要的耦合。按照迪米特法則,應該避免類中出現這樣非直接朋友關係的耦合。修改後的代碼如下:
class SubCompanyManager{
public List<SubEmployee> getAllEmployee(){
List<SubEmployee> list = new ArrayList<SubEmployee>();
for(int i=0; i<100; i++){
SubEmployee emp = new SubEmployee();
//為分公司人員按順序分配一個ID
emp.setId("分公司"+i);
list.add(emp);
}
return list;
}
public void printEmployee(){
List<SubEmployee> list = this.getAllEmployee();
for(SubEmployee e:list){
System.out.println(e.getId());
}
}
}
class CompanyManager{
public List<Employee> getAllEmployee(){
List<Employee> list = new ArrayList<Employee>();
for(int i=0; i<30; i++){
Employee emp = new Employee();
//為總公司人員按順序分配一個ID
emp.setId("總公司"+i);
list.add(emp);
}
return list;
}
public void printAllEmployee(SubCompanyManager sub){
sub.printEmployee();
List<Employee> list2 = this.getAllEmployee();
for(Employee e:list2){
System.out.println(e.getId());
}
}
}
|
修改後,為分公司增加了列印人員ID的方法,總公司直接調用來列印,從而避免了與分公司的員工發生耦合。
迪米特法則的初衷是降低類之間的耦合,由於每個類都減少了不必要的依賴,因此的確可以降低耦合關係。但是凡事都有度,雖然可以避免與非直接的類通信,但是要通信,必然會通過一個“中介”來發生聯繫,例如本例中,總公司就是通過分公司這個“中介”來與分公司的員工發生聯繫的。過分的使用迪米特原則,會產生大量這樣的中介和傳遞類,導致系統複雜度變大。所以在採用迪米特法則時要反覆權衡,既做到結構清晰,又要高內聚低耦合。
定義:一個軟體實體如類、模塊和函數應該對擴展開放,對修改關閉。
問題由來:在軟體的生命周期內,因為變化、升級和維護等原因需要對軟體原有代碼進行修改時,可能會給舊代碼中引入錯誤,也可能會使我們不得不對整個功能進行重構,並且需要原有代碼經過重新測試。
解決方案:當軟體需要變化時,儘量通過擴展軟體實體的行為來實現變化,而不是通過修改已有的代碼來實現變化。
開閉原則是面向對象設計中最基礎的設計原則,它指導我們如何建立穩定靈活的系統。開閉原則可能是設計模式六項原則中定義最模糊的一個了,它只告訴我們對擴展開放,對修改關閉,可是到底如何才能做到對擴展開放,對修改關閉,並沒有明確的告訴我們。以前,如果有人告訴我“你進行設計的時候一定要遵守開閉原則”,我會覺的他什麼都沒說,但貌似又什麼都說了。因為開閉原則真的太虛了。
在仔細思考以及仔細閱讀很多設計模式的文章後,終於對開閉原則有了一點認識。其實,我們遵循設計模式前面5大原則,以及使用23種設計模式的目的就是遵循開閉原則。也就是說,只要我們對前面5項原則遵守的好了,設計出的軟體自然是符合開閉原則的,這個開閉原則更像是前面五項原則遵守程度的“平均得分”,前面5項原則遵守的好,平均分自然就高,說明軟體設計開閉原則遵守的好;如果前面5項原則遵守的不好,則說明開閉原則遵守的不好。
其實筆者認為,開閉原則無非就是想表達這樣一層意思:用抽象構建框架,用實現擴展細節。因為抽象靈活性好,適應性廣,只要抽象的合理,可以基本保持軟體架構的穩定。而軟體中易變的細節,我們用從抽象派生的實現類來進行擴展,當軟體需要發生變化時,我們只需要根據需求重新派生一個實現類來擴展就可以了。當然前提是我們的抽象要合理,要對需求的變更有前瞻性和預見性才行。
說到這裡,再回想一下前面說的5項原則,恰恰是告訴我們用抽象構建框架,用實現擴展細節的註意事項而已:單一職責原則告訴我們實現類要職責單一;里氏替換原則告訴我們不要破壞繼承體系;依賴倒置原則告訴我們要面向介面編程;介面隔離原則告訴我們在設計介面的時候要精簡單一;迪米特法則告訴我們要降低耦合。而開閉原則是總綱,他告訴我們要對擴展開放,對修改關閉。
最後說明一下如何去遵守這六個原則。對這六個原則的遵守並不是是和否的問題,而是多和少的問題,也就是說,我們一般不會說有沒有遵守,而是說遵守程度的多少。任何事都是過猶不及,設計模式的六個設計原則也是一樣,制定這六個原則的目的並不是要我們刻板的遵守他們,而需要根據實際情況靈活運用。對他們的遵守程度只要在一個合理的範圍內,就算是良好的設計。我們用一幅圖來說明一下。

圖中的每一條維度各代表一項原則,我們依據對這項原則的遵守程度在維度上畫一個點,則如果對這項原則遵守的合理的話,這個點應該落在紅色的同心圓內部;如果遵守的差,點將會在小圓內部;如果過度遵守,點將會落在大圓外部。一個良好的設計體現在圖中,應該是六個頂點都在同心圓中的六邊形。
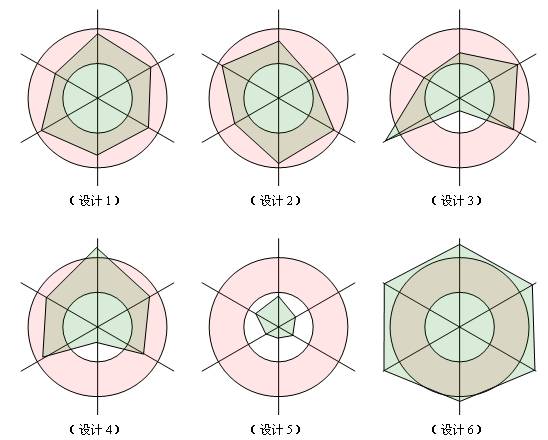
在上圖中,設計1、設計2屬於良好的設計,他們對六項原則的遵守程度都在合理的範圍內;設計3、設計4設計雖然有些不足,但也基本可以接受;設計5則嚴重不足,對各項原則都沒有很好的遵守;而設計6則遵守過渡了,設計5和設計6都是迫切需要重構的設計。
到這裡,設計模式的六大原則就寫完了。主要參考書籍有《設計模式》《設計模式之禪》《大話設計模式》以及網上一些零散的文章,但主要內容主要還是我本人對這六個原則的感悟。寫出來的目的一方面是對這六項原則系統地整理一下,一方面也與廣大的網友分享,因為設計模式對編程人員來說,的確非常重要。正如有句話叫做一千個讀者眼中有一千個哈姆雷特,如果大家對這六項原則的理解跟我有所不同,歡迎留言,大家共同探討。


