
1.簡介 當一個表數據量很大時候,很自然我們就會想到將表拆分成很多小表,在執行查詢時候就到各個小表去查,最後彙總數據集返回給調用者加快查詢速度。比如電商平臺訂單表,庫存表,由於長年累月讀寫較多,積累數據都是異常龐大的,這時候,我們可以想到表分區這個做法,降低運維和維護成本,提高讀寫性能。比如將前半年 ...
1.簡介
當一個表數據量很大時候,很自然我們就會想到將表拆分成很多小表,在執行查詢時候就到各個小表去查,最後彙總數據集返回給調用者加快查詢速度。比如電商平臺訂單表,庫存表,由於長年累月讀寫較多,積累數據都是異常龐大的,這時候,我們可以想到表分區這個做法,降低運維和維護成本,提高讀寫性能。比如將前半年訂單放一個歷史分區表,不活躍庫存放一個歷史分區表。截止到SQL Server 2016,一張表或一個索引最多可以有15000個分區。
2.表分區
2.1分區範圍
分區範圍是指在要分區的表中,根據業務選擇表中的關鍵欄位做為分區邊界條件,分區後,數據所在的具體位置至關重要,這樣才能在需要時只訪問相應的分區。註意分區是指數據的邏輯分離,不是數據在磁碟上的物理位置,數據的位置由文件組來決定,所以一般建議一個分區對應一個文件組。
2.2分區鍵
分區表中的欄位可以作為分區鍵,比如庫存表中供應商ID。對錶和索引進行分區的第一步就是定義分區的關鍵數據。
2.3索引分區
除了對錶的數據集進行分區之外,還可以對索引進行分區,使用相同的函數對錶及其索引進行分區通常可以優化性能。
3.創建表分區
3.1創建文件組
在這裡演示示例當中,我根據業務場景在TestDB資料庫新增三個文件組,而三個文件組分別對應三個分區。而多個文件組好處是可以按照不同業務場景將數據放在對應文件組當中,優化性能同時好維護數據。文件組數量由硬體決定,最好是一個文件組對應一個分區,好維護。而通常文件組都處於不同磁碟上的,但是由於是演示,我只在一個磁碟中存放。
--創建四個文件組
ALTER DATABASE [TestDB] ADD FILEGROUP SupIDGroup1
ALTER DATABASE [TestDB] ADD FILEGROUP SupIDGroup2
ALTER DATABASE [TestDB] ADD FILEGROUP SupIDGroup3
3.2指定文件組存放路徑
在創建文件組之後,指定文件組存放磁碟位置,文件大小。
--創建四個ndf文件,對應到各文件組中,FILENAME文件存儲路徑 ALTER DATABASE [TestDB] ADD FILE( NAME='SupIDGroupFile1', FILENAME='D:\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\SupIDGroupFile1.ndf', SIZE=10MB, FILEGROWTH=10MB) TO FILEGROUP SupIDGroup1 ALTER DATABASE [TestDB] ADD FILE( NAME='SupIDGroupFile2', FILENAME='D:\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\SupIDGroupFile2.ndf', SIZE=10MB, FILEGROWTH=10MB) TO FILEGROUP SupIDGroup2 ALTER DATABASE [TestDB] ADD FILE( NAME='SupIDGroupFile3', FILENAME='D:\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\SupIDGroupFile3.ndf', SIZE=10MB, FILEGROWTH=10MB) TO FILEGROUP SupIDGroup3
註(附上刪除文件組T-SQL):
ALTER DATABASE [TestDB] REMOVE FILE SupIDGroupFile3
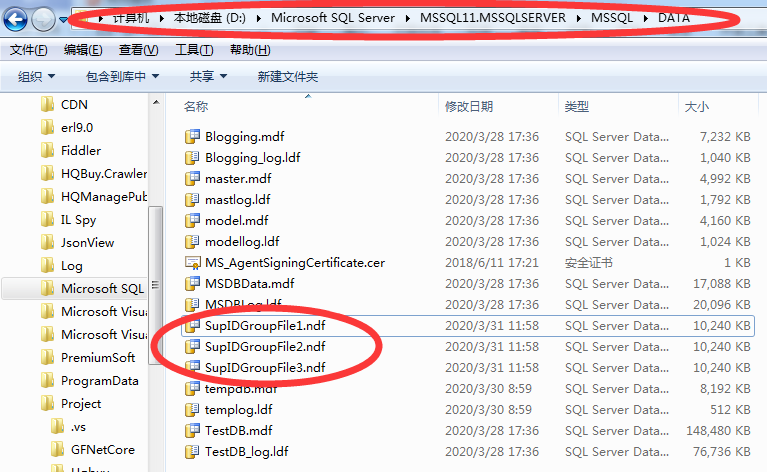
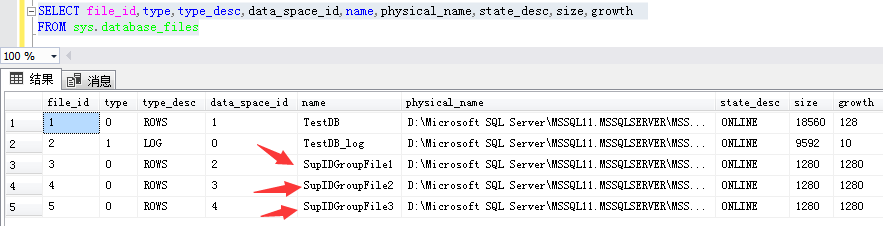
可以通過以下T-SQL語句查看文件組存放相關信息:
SELECT file_id,type,type_desc,data_space_id,name,physical_name,state_desc,size,growth
FROM sys.database_files
3.3創建分區函數
如何創建表分區邊界值,我們肯定要根據業務場景來決定。比如我測試庫庫存表有36萬左右數據,而有些供應商的庫存數據遠遠比其他供應商大,那麼我可以考慮使用供應商ID欄位作為邊界值分區。例如:根據T-SQL統計,18080供應商庫存數據最大,那麼我可以根據18080供應商上下分為三個區。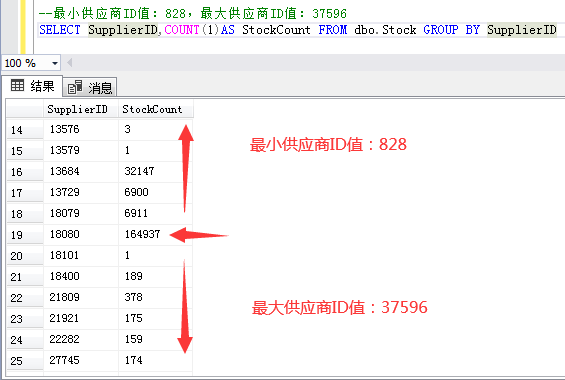
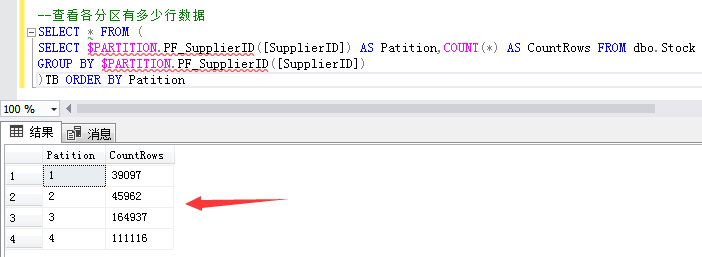
第一個分區範圍記錄:供應商ID小於等於13570的39097條庫存數據。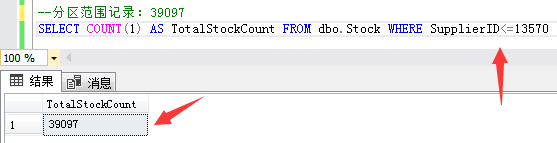
第二個分區範圍記錄:供應商ID大於13570和小於等於18079的45962條庫存數據。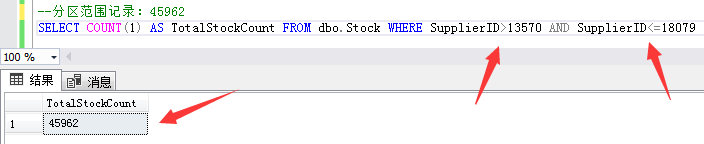
第三個分區範圍記錄:供應商ID大於18079小於等於18080的164937條庫存數據。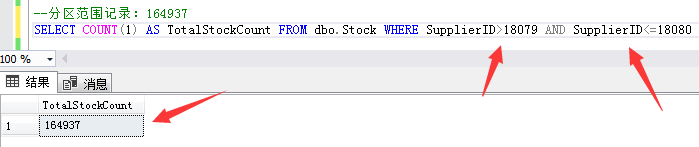
第四個分區範圍記錄:供應商ID大於18080的111116條庫存數據。
根據上述分區範圍記錄,我們可以將供應商ID作為邊界值設置,執行以下T-SQL語句設置邊界值:
--設置邊界值 CREATE PARTITION FUNCTION PF_SupplierID(int) AS RANGE LEFT FOR VALUES (13570,18079,18080)
執行完畢後如圖所示:
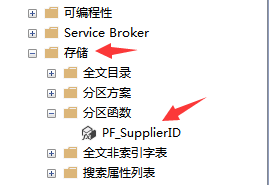
3.4創建分區方案
執行以下T-SQL語句創建分區方案:
--創建分區方案
CREATE PARTITION SCHEME PS_SupplierID
AS PARTITION PF_SupplierID TO ([PRIMARY], [SupIDGroup1],[SupIDGroup2],[SupIDGroup3])
執行完畢後如圖所示:

3.5創建分區表
上面那些分區步驟都是為了接下來創建分區表這一步驟而準備的。廢話不多說,現在我們來看看如何創建分區表。右鍵需要分區的表->儲存->創建分區,具體步驟如下圖所示:

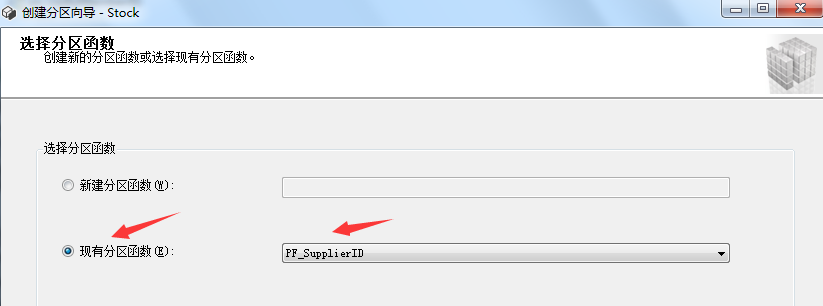
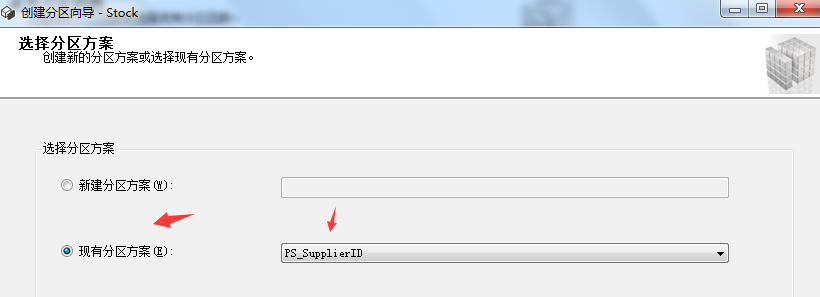
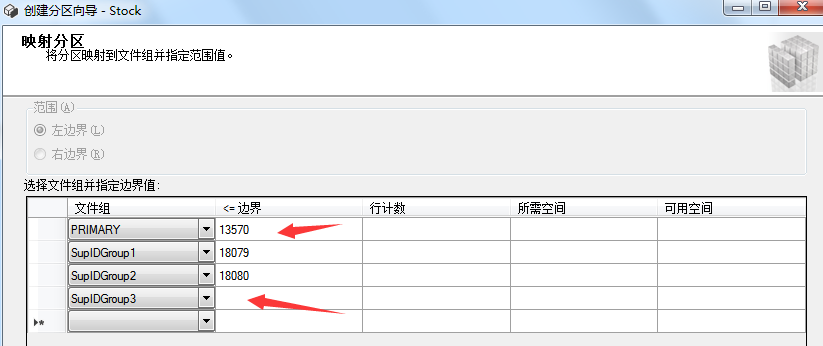

3.6創建分區索引
--創建分區索引 CREATE NONCLUSTERED INDEX [NCI_SupplierID] ON dbo.Stock ( SupplierID ASC ) INCLUDE ( [Model],[Brand],[Encapsulation]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) GO
或者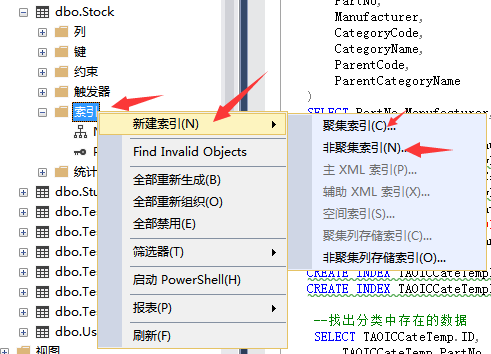
執行完畢後如圖所示:
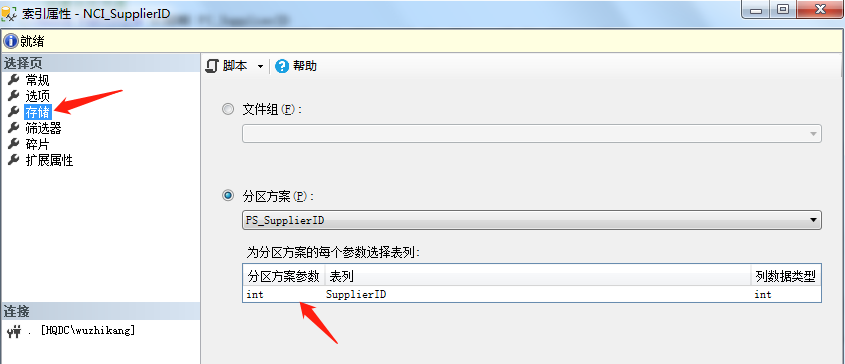
創建好索引之後,我們來看看分區情況:
--查看各分區有多少行數據 SELECT * FROM ( SELECT $PARTITION.PF_SupplierID([SupplierID]) AS Patition,COUNT(*) AS CountRows FROM dbo.Stock GROUP BY $PARTITION.PF_SupplierID([SupplierID]) )TB ORDER BY Patition
最後我們來看看加了索引之後表數據查詢情況: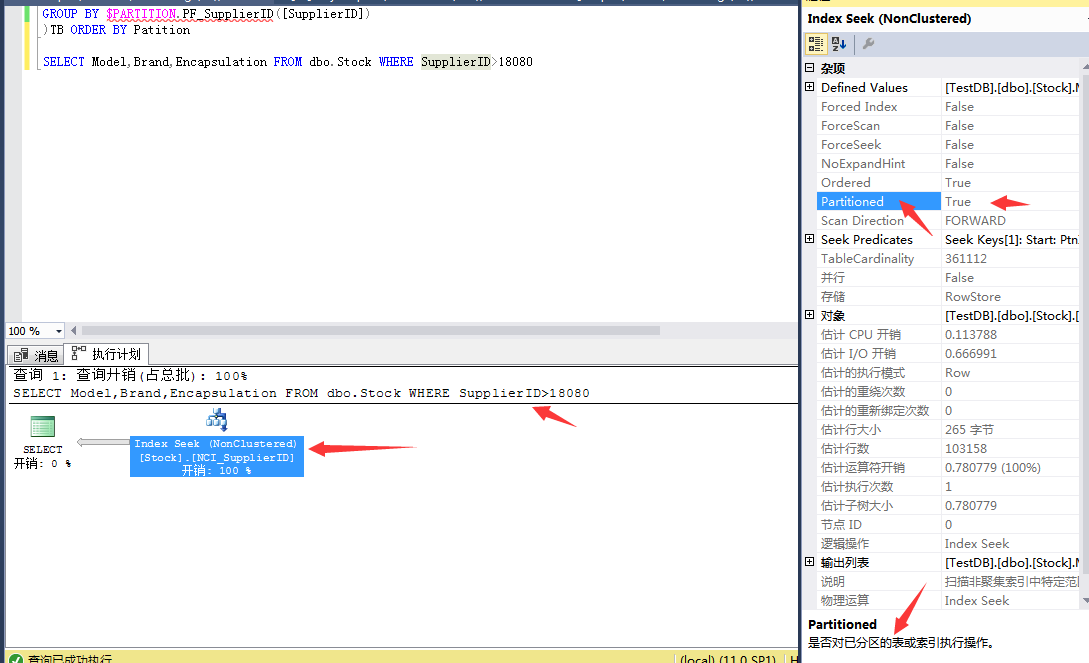
4.表分區的優缺點
優點:
●改善查詢性能:對分區對象的查詢可以僅搜索自己關心的分區,提高檢索速度。
●增強可用性:如果表的某個分區出現故障,表在其他分區的數據仍然可用。
●維護方便:如果表的某個分區出現故障,需要修複數據,只修複該分區即可。
●均衡I/O:可以把不同的分區映射到不同磁碟以平衡I/O,改善整個系統性能。
缺點:
分區表相關:已經存在的表沒有方法可以直接轉化為分區表。


