
今天找到一片電影,想把它下載下來。 先開Networks工具分析一下: 初步分析發現,視頻載入時會拉取TS格式的文件,推測這是一個m3u8的索引,記錄著幾百段TS文件,這樣方便快進時載入。 但是實際分析m3u8文件時,發現這並不是一個有效的索引文件,應該只是載入一個形式,實際的handler在其他地 ...
今天找到一片電影,想把它下載下來。
先開Networks工具分析一下:

初步分析發現,視頻載入時會拉取TS格式的文件,推測這是一個m3u8的索引,記錄著幾百段TS文件,這樣方便快進時載入。
但是實際分析m3u8文件時,發現這並不是一個有效的索引文件,應該只是載入一個形式,實際的handler在其他地方:

但這樣分析js太麻煩了。通過幾次嘗試,發現了規律:視頻文件名是由y8TL59oh4680xxx.ts組成的,xxx是序號,這樣就簡單多了!
把之前爬音樂文件的爬蟲改一改,得到這樣一個程式:
import requests import os import re from tkinter import Tk from tkinter.simpledialog import askinteger, askfloat, askstring from tkinter.filedialog import askopenfilename, askopenfilenames, asksaveasfilename, askdirectory from tkinter.messagebox import showinfo, showwarning, showerror def downloadSong(SongID, FileName): headers = {"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36"} r = requests.get("https://www.mmicloud.com/20190406/I1RrJf8s/2000kb/hls/y8TL59oh" + str(SongID) + ".ts",headers=headers); #print("State:") #print(r) filepath=os.path.join(str(SongID) + ".ts") with open(filepath,"wb") as file: file.write(r.content) print(SongID) for i in range(4680000, 4680900): downloadSong(i, str(i))
這個程式迴圈爬取文件名從y8TL59oh4680000.ts到y8TL59oh4680899.ts的900個視頻文件。
程式中的迴圈最大值之所以定在4680900,是因為我發現影片有860多段,於是就多下載一些,如果下載不了就是下完了,出錯倒也無所謂。
讓他開始運行,看起來工作良好,有在順利的下載文件:
於是我就放下手頭的事,先休息去了。過了大約半個小時,他已經下載了300多個文件了:
我就放下心來,這個爬蟲應該是沒什麼問題了,於是我就用VSCode寫了一些代碼。當我再次看到任務欄時,爬蟲已經不見了!
我再次啟動爬蟲,過了一會又會有同樣的問題!難道是變數i溢出了?試著debug一下,把i的範圍縮小試試:
import requests import os import re from tkinter import Tk from tkinter.simpledialog import askinteger, askfloat, askstring from tkinter.filedialog import askopenfilename, askopenfilenames, asksaveasfilename, askdirectory from tkinter.messagebox import showinfo, showwarning, showerror def downloadSong(SongID, FileName): headers = {"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36"} r = requests.get("https://www.mmicloud.com/20190406/I1RrJf8s/2000kb/hls/y8TL59oh4680" + str(SongID) + ".ts",headers=headers); #print("State:") #print(r) filepath=os.path.join(str(SongID) + ".ts") with open(filepath,"wb") as file: file.write(r.content) print(SongID) for i in range(566, 900): downloadSong(i, str(i))
經過debug,發現程式應該是沒有問題,只是因為控制台視窗最小化時,爬蟲會被記憶體回收掉,所以導致了程式退出。
折騰了半天!
我換成用IDLE編輯器自帶的Run Modules,有普通視窗的話就不容易被回收掉把:

過了一陣子,爬蟲終於把文件爬完了。一看文件夾,又出問題了:

文件名不一致!
還記得之前我們debug的時候把變數i的範圍改小了嗎?這就是原因!
那好吧,選中所有名字長的文件,右鍵,重命名,命名成a,然後文件就可以自動命名為a (1), a (2), a (3), a (4), a (5), ...這樣。
問題。。解決了?
我拿著這些命名為a (1), a (2), a (3), a (4), a (5), ...的文件去轉碼,合併,來來回回整了一個小時多。當合併之後,才發現,
文件順序全是亂的!!!
啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊天煞的Windows!!!!!!!!!!
沒辦法,有氣出不來,只好繼續寫代碼。。。
還好我留了一份沒有重命名過的文件夾,那就用python寫一個批量重命名程式吧:
import os PROJECT_DIR_PATH = os.path.dirname(os.path.abspath(os.path.abspath(__file__))) DIR_PATH = os.path.join(PROJECT_DIR_PATH, 'data') files = os.listdir(DIR_PATH) for filename in files: name, suffix = os.path.splitext(filename) new_name = os.path.join(DIR_PATH, name[4:7]) old_name = os.path.join(DIR_PATH, filename) os.rename(old_name, new_name)
把文件目錄改成這樣,就可以使用上面的程式了:
爽爽快快的運行完程式,發現命名是成功了,但尾碼名沒有了。。。
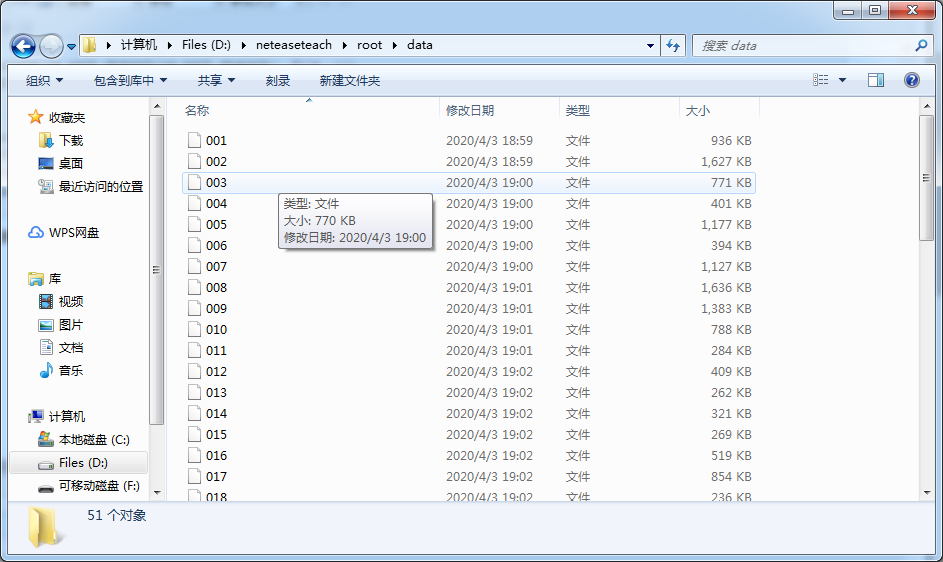
失誤失誤!再寫一個補救程式:
import os PROJECT_DIR_PATH = os.path.dirname(os.path.abspath(os.path.abspath(__file__))) DIR_PATH = os.path.join(PROJECT_DIR_PATH, 'data') files = os.listdir(DIR_PATH) for filename in files: name, suffix = os.path.splitext(filename) new_name = os.path.join(DIR_PATH, filename + ".ts") old_name = os.path.join(DIR_PATH, filename) os.rename(old_name, new_name)
心驚膽戰的運行完,目錄終於正常了:
然後又是轉碼、合併,又是一個多小時。最後,總算拿到了勝利的果實:

太難了!
下載這篇電影花費了我一整天的時間。上午和中午找片源,下午寫代碼+寫爬蟲+爬資源,晚上還得操心重命名和轉碼的問題,這中間都夠我看6-7片電影了。ε=(´ο`*)))唉。。。
不多說了,電影只能明天看了。各位,晚安!


