
title: Java基礎語法(8) 數組中的常見排序演算法 blog: "CSDN" data: "Java學習路線及視頻" 1.基本概念 排序: 是電腦程式設計中的一項重要操作,其功能是指一個數據元素集合或序列重新排列成一個按數據元素某個數據項值有序的序列. 排序碼(關鍵碼): 排序依據的數據項 ...
title: Java基礎語法(8)-數組中的常見排序演算法
blog: CSDN
data: Java學習路線及視頻
1.基本概念
- 排序: 是電腦程式設計中的一項重要操作,其功能是指一個數據元素集合或序列重新排列成一個按數據元素某個數據項值有序的序列.
- 排序碼(關鍵碼): 排序依據的數據項.
- 穩定排序: 排序前與排序後相同關鍵碼元素間的位置關係,保持一致的排序方法.
- 不穩定排序: 排序前與排序後相同關鍵碼元素間的相對位置發生改變的排序方法.
- 內排序: 指待排序列完全存放在記憶體中所進行的排序.內排序大致可分為五類
- 插入排序
- 交換排序
- 選擇排序
- 歸併排序
- 分配排序
- 外排序: 指排序過程中還需訪問外存儲器的排序.
2.選擇排序
操作方法
第一趟:從n個記錄中找出關鍵碼最小的記錄和第一個記錄交換;
第二趟:從第二個記錄開始的n-1個記錄中再選出關鍵碼最小的記錄與第二個記錄交換
以此類推......
第i趟,則從第i個記錄開始的n-i+1個記錄中選出關鍵碼最小的記錄與第i個記錄交換,直到整個序列按關鍵碼有序。
/**
* 直接選擇排序
* @author BenCoper
* 2020-04-01
*/
public class SelectSort {
public static void selectSort(int[] data) {
System.out.println("開始排序");
int arrayLength = data.length;
for (int i = 0; i < arrayLength - 1; i++) {
for (int j = i + 1; j < arrayLength; j++) {
if (data[i] - data[j] > 0) {
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
}
System.out.println(java.util.Arrays.toString(data));
}
}
public static void main(String[] args) {
int[] data = { 9, -16, 21, 23, -30, -49, 21, 30, 30 };
System.out.println("排序之前:\n" + java.util.Arrays.toString(data));
selectSort(data);
System.out.println("排序之後:\n" + java.util.Arrays.toString(data));
}
}
選擇排序的時間複雜度
| 平均時間複雜度 | 最好情況 | 最壞情況 | 空間複雜度 |
|---|---|---|---|
| O(n²) | O(n²) | O(n²) | O(1) |
3.插入排序
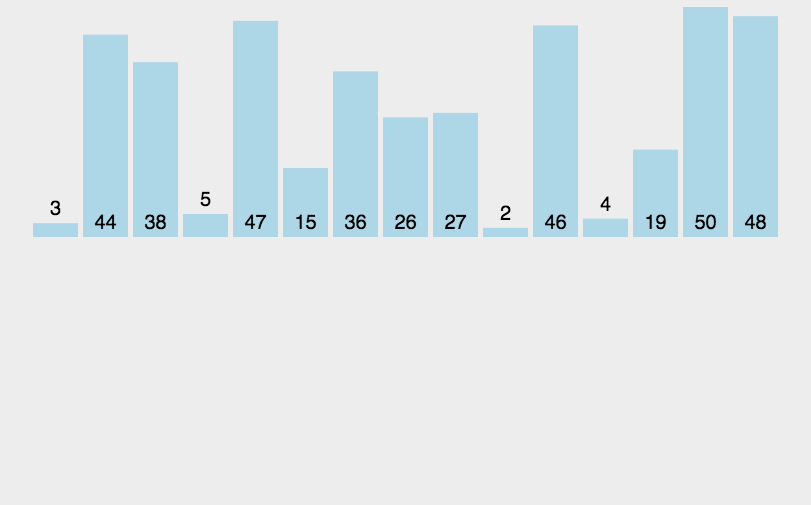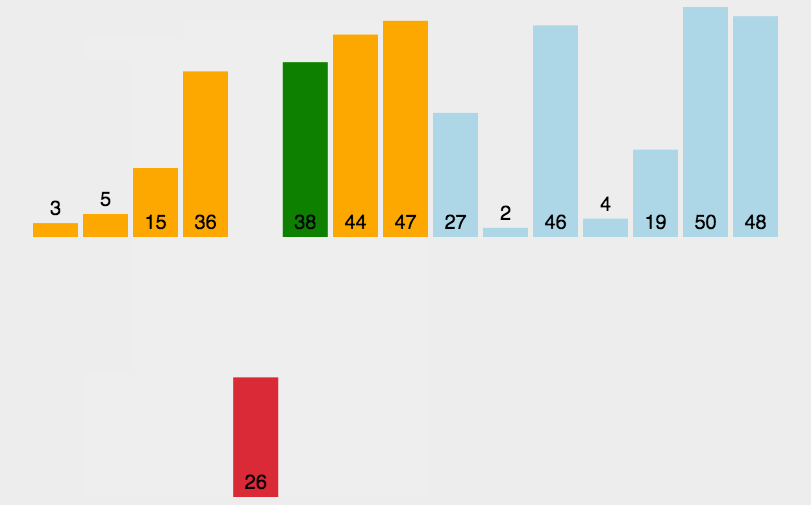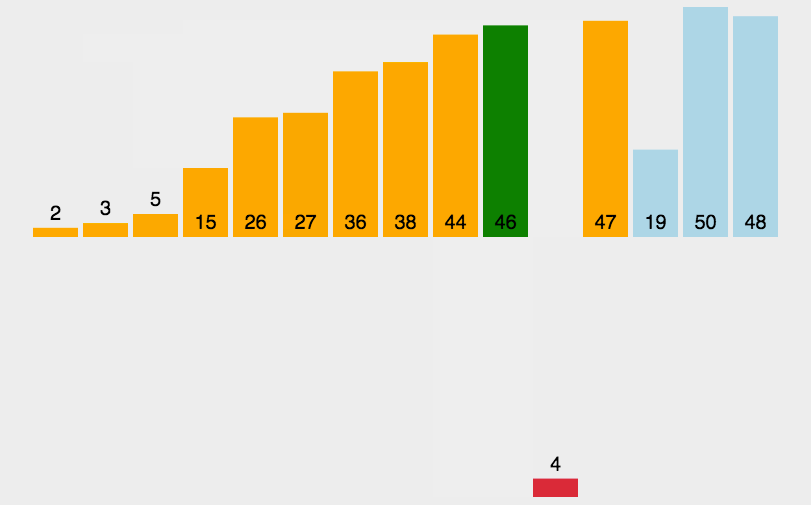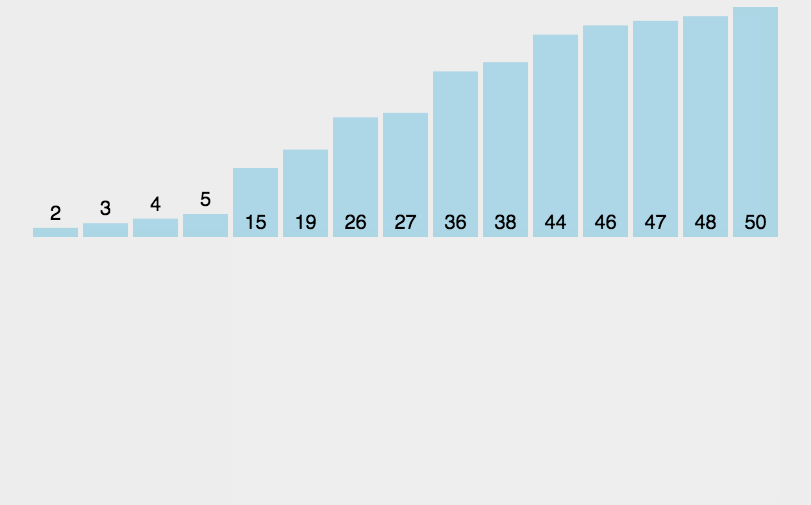
操作方法
一組無序序列{A1,A2,........An} 先取出A1,
然後從A2與A1比較,比較完之後序列狀況是{A1,A2}{A3..........An},
其中{A1,A2}有序, 然後取出A3 ,放到{A1,A2}有序序列合適位置,
導致{A1,A2,A3}{A4........An}。
重覆這個過程,直到取出An{A1,A2........An-1}有序序列中。
/**
* 直接插入排序
* @author BenCoper
* 2020-04-01
*/
public class InsertSort {
public static void insertSort(int[] data) {
System.out.println("開始排序");
int arrayLength = data.length;
for (int i = 1; i < arrayLength; i++) {
int temp = data[i];
if (data[i] - data[i - 1] < 0) {
int j = i - 1;
for (; j >= 0 && data[j] - temp > 0; j--) {
data[j + 1] = data[j];
}
data[j + 1] = temp;
}
System.out.println(java.util.Arrays.toString(data));
}
}
public static void main(String[] args) {
int[] data = { 9, -16, 21, 23, -30, -49, 21, 30, 30 };
System.out.println("排序之前:\n" + java.util.Arrays.toString(data));
insertSort(data);
System.out.println("排序之後:\n" + java.util.Arrays.toString(data));
}
}
插入排序的時間複雜度
| 平均時間複雜度 | 最好情況 | 最壞情況 | 空間複雜度 |
|---|---|---|---|
| O(n²) | O(n) | O(n²) | O(1) |
4.堆排序

操作方法
構建初始堆,將待排序列構成一個大頂堆(或者小頂堆),升序大頂堆,降序小頂堆;
將堆頂元素與堆尾元素交換,並斷開(從待排序列中移除)堆尾元素。
重新構建堆。
重覆2~3,直到待排序列中只剩下一個元素(堆頂元素)。
/**
* 堆排序
* @author BenCoper
* 2020-04-01
*/
public class HeapSort {
public static void heapSort(int[] data) {
System.out.println("開始排序");
int arrayLength = data.length;
// 迴圈建堆
for (int i = 0; i < arrayLength - 1; i++) {
// 建堆
buildMaxdHeap(data, arrayLength - 1 - i);
// 交換堆頂和最後一個元素
swap(data, 0, arrayLength - 1 - i);
System.out.println(java.util.Arrays.toString(data));
}
}
// 對data數組從0到lastIndex建大頂堆
private static void buildMaxdHeap(int[] data, int lastIndex) {
// 從lastIndex處節點(最後一個節點)的父節點開始
for (int i = (lastIndex - 1) / 2; i >= 0; i--) {
// k保存當前正在判斷的節點
int k = i;
// 如果當前k節點的子節點存在
while (k * 2 + 1 <= lastIndex) {
// k節點的左子節點的索引
int biggerIndex = 2 * k + 1;
// 如果biggerIndex小於lastIndex,即biggerIndex +1
// 代表k節點的右子節點存在
if (biggerIndex < lastIndex) {
// 如果右子節點的值較大
if (data[biggerIndex] - data[biggerIndex + 1] < 0) {
// biggerIndex總是記錄較大子節點的索引
biggerIndex++;
}
}
// 如果k節點的值小於其較大子節點的值
if (data[k] - data[biggerIndex] < 0) {
// 交換它們
swap(data, k, biggerIndex);
// 將biggerIndex賦給k,開始while迴圈的下一次迴圈
// 重新保證k節點的值大於其左、右節點的值
k = biggerIndex;
} else {
break;
}
}
}
}
// 交換data數組中i、j兩個索引處的元素
private static void swap(int[] data, int i, int j) {
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
public static void main(String[] args) {
int[] data = { 9, -16, 21, 23, -30, -49, 21, 30, 30 };
System.out.println("排序之前:\n" + java.util.Arrays.toString(data));
heapSort(data);
System.out.println("排序之後:\n" + java.util.Arrays.toString(data));
}
}
插入排序的時間複雜度
| 平均時間複雜度 | 最好情況 | 最壞情況 | 空間複雜度 |
|---|---|---|---|
| O(nlogn) | O(nlogn) | O(nlogn) | O(1) |
5.歸併排序
操作方法
歸併排序是先將數組進行拆分,拆分到剩餘一個關鍵字,這是一個從大到小的過程。
然後再進行治理,治理的過程也就是進行合併的過程,合併時會保證左右兩邊的數組內部各自有序。
然後將兩個有序的數組合併到一個數組中,且合併後的數組有序。總結就是:遞歸拆分,回溯合併,合併時左右兩個數組內部有序。
/**
* 堆排序
* @author BenCoper
* 2020-04-01
*/
public class MergeSort {
public static void mergeSort(int[] data) {
// 歸併排序
sort(data, 0, data.length - 1);
}
// 將索引從left到right範圍的數組元素進行歸併排序
private static void sort(int[] data, int left, int right) {
if(left < right){
//找出中間索引
int center = (left + right)/2;
sort(data,left,center);
sort(data,center+1,right);
//合併
merge(data,left,center,right);
}
}
// 將兩個數組進行歸併,歸併前兩個數組已經有序,歸併後依然有序
private static void merge(int[] data, int left, int center, int right) {
int[] tempArr = new int[data.length];
int mid = center + 1;
int third = left;
int temp = left;
while (left <= center && mid <= right) {
if (data[left] - data[mid] <= 0) {
tempArr[third++] = data[left++];
} else {
tempArr[third++] = data[mid++];
}
}
while (mid <= right) {
tempArr[third++] = data[mid++];
}
while (left <= center) {
tempArr[third++] = data[left++];
}
while (temp <= right) {
data[temp] = tempArr[temp++];
}
}
public static void main(String[] args) {
int[] data = { 9, -16, 21, 23, -30, -49, 21, 30, 30 };
System.out.println("排序之前:\n" + java.util.Arrays.toString(data));
mergeSort(data);
System.out.println("排序之後:\n" + java.util.Arrays.toString(data));
}
}
插入排序的時間複雜度
| 平均時間複雜度 | 最好情況 | 最壞情況 | 空間複雜度 |
|---|---|---|---|
| O(nlogn) | O(nlogn) | O(nlogn) | O(1) |
6.基數排序

操作方法
將所有待比較數值統一為同樣的數位長度,數位較短的數前面補零。
然後,從最低位開始,依次進行一次排序。
這樣從最低位排序一直到最高位排序完成以後, 數列就變成一個有序序列。
/**
* 基數排序
* @author BenCoper
* 2020-04-01
*/
public class MultiKeyRadixSort {
public static void radixSort(int[] data, int radix, int d) {
System.out.println("開始排序:");
int arrayLength = data.length;
int[] temp = new int[arrayLength];
int[] buckets = new int[radix];
for (int i = 0, rate = 1; i < d; i++) {
// 重置count數組,開始統計第二個關鍵字
Arrays.fill(buckets, 0);
// 當data數組的元素複製到temp數組中進行緩存
System.arraycopy(data, 0, temp, 0, arrayLength);
for (int j = 0; j < arrayLength; j++) {
int subKey = (temp[j] / rate) % radix;
buckets[subKey]++;
}
for (int j = 1; j < radix; j++) {
buckets[j] = buckets[j] + buckets[j - 1];
}
for (int m = arrayLength - 1; m >= 0; m--) {
int subKey = (temp[m] / rate) % radix;
data[--buckets[subKey]] = temp[m];
}
System.out.println("對" + rate + "位上子關鍵字排序:"
+ java.util.Arrays.toString(data));
rate *= radix;
}
}
public static void main(String[] args) {
int[] data = { 1100, 192, 221, 12, 13 };
System.out.println("排序之前:\n" + java.util.Arrays.toString(data));
radixSort(data, 10, 4);
System.out.println("排序之後:\n" + java.util.Arrays.toString(data));
}
}
插入排序的時間複雜度
| 平均時間複雜度 | 最好情況 | 最壞情況 | 空間複雜度 |
|---|---|---|---|
| O(n²) | O(n) | O(n²) | O(1) |
7.冒泡排序
操作方法
比較相鄰的元素。如果第一個比第二個大,就交換他們兩個。
對每一對相鄰元素作同樣的工作,從開始第一對到結尾的最後一對。在這一點,最後的元素應該會是最大的數。
針對所有的元素重覆以上的步驟,除了最後一個。
持續每次對越來越少的元素重覆上面的步驟,直到沒有任何一對數字需要比較
/**
* 冒泡排序
* @author BenCoper
* 2020-04-01
*/
public static void bubbleSort1(int[] data) {
System.out.println("開始排序");
int arrayLength = data.length;
for (int i = 0; i < arrayLength - 1; i++) {
boolean flag = false;
for (int j = 0; j < arrayLength - 1 - i; j++) {
if (data[j] > data[j + 1]) {
int temp = data[j + 1];
data[j + 1] = data[j];
data[j] = temp;
flag = true;
}
}
System.out.println(java.util.Arrays.toString(data));
if (!flag)
break;
}
}
public static void main(String[] args) {
int[] data = { 9, -16, 21, 23, -30, -49, 21, 30, 30 };
System.out.println("排序之前:\n" + java.util.Arrays.toString(data));
bubbleSort(data);
System.out.println("排序之後:\n" + java.util.Arrays.toString(data));
}
}
插入排序的時間複雜度
| 平均時間複雜度 | 最好情況 | 最壞情況 | 空間複雜度 |
|---|---|---|---|
| O(n²) | O(n) | O(n²) | O(1) |
8.快速排序
操作方法
通過一趟排序將待排序記錄分割成獨立的兩部分,其中一部分記錄的關鍵字均比另一部分關鍵字小,
則分別對這兩部分繼續進行排序,直到整個序列有序。
/**
* 快速排序
* @author BenCoper
* 2020-04-01
*/
public class QuickSort {
private static void swap(int[] data, int i, int j) {
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
private static void subSort(int[] data, int start, int end) {
if (start < end) {
int base = data[start];
int low = start;
int high = end + 1;
while (true) {
while (low < end && data[++low] - base <= 0)
;
while (high > start && data[--high] - base >= 0)
;
if (low < high) {
swap(data, low, high);
} else {
break;
}
}
swap(data, start, high);
subSort(data, start, high - 1);//遞歸調用
subSort(data, high + 1, end);
}
}
public static void quickSort(int[] data){
subSort(data,0,data.length-1);
}
public static void main(String[] args) {
int[] data = { 9, -16, 30, 23, -30, -49, 25, 21, 30 };
System.out.println("排序之前:\n" + java.util.Arrays.toString(data));
quickSort(data);
System.out.println("排序之後:\n" + java.util.Arrays.toString(data));
}
}
插入排序的時間複雜度
| 平均時間複雜度 | 最好情況 | 最壞情況 | 空間複雜度 |
|---|---|---|---|
| O(nlogn) | O(nlogn) | O(n²) | O(1) |
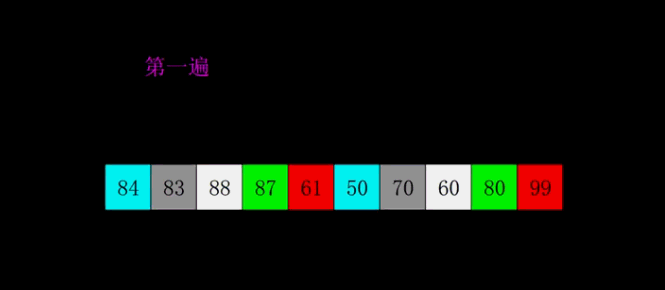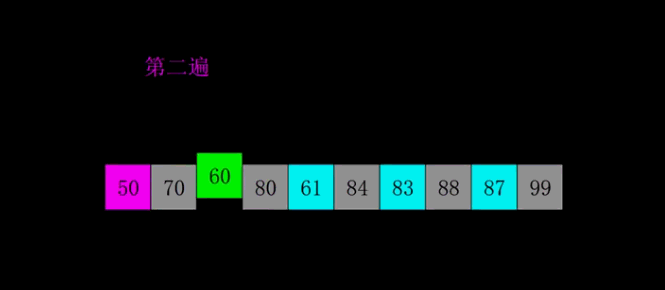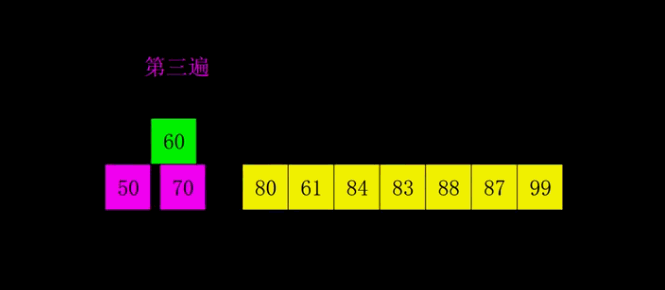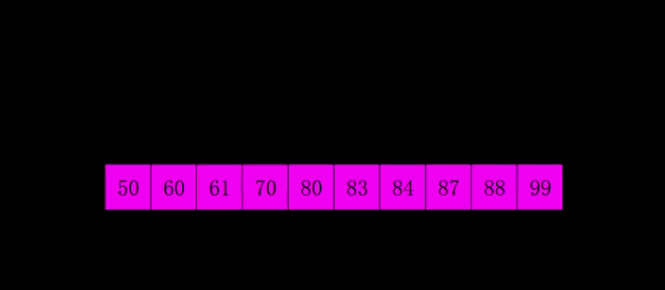
9.希爾排序
操作方法
希爾排序是把記錄按下標的一定增量分組,對每組使用直接插入排序演算法排序;隨著增量逐漸減少,每組包含的關鍵詞越來越多,當增量減至1時,整個文件恰被分成一組,演算法便終止。
/**
* Shell排序
* @author BenCoper
* 2020-04-01
*/
public class ShellSort {
public static void ShellSort(int[] data) {
System.out.println("開始排序");
int arrayLength = data.length;
int h = 1;
while (h <= arrayLength / 3) {
h = h * 3 + 1;
}
while (h > 0) {
System.out.println("===h的值:" + h + "===");
for (int i = h; i < arrayLength; i++) {
int temp = data[i];
if (data[i] - data[i - h] < 0) {
int j = i - h;
for (; j >= 0 && data[j] - temp > 0; j -= h) {
data[j + h] = data[j];
}
data[j + h] = temp;
}
System.out.println(java.util.Arrays.toString(data));
}
h = (h - 1) / 3;
}
}
public static void main(String[] args) {
int[] data = { 9, -16, 21, 23, -30, -49, 21, 30, 30 };
System.out.println("排序之前:\n" + java.util.Arrays.toString(data));
ShellSort(data);
System.out.println("排序之後:\n" + java.util.Arrays.toString(data));
}
}
插入排序的時間複雜度
| 平均時間複雜度 | 最好情況 | 最壞情況 | 空間複雜度 |
|---|---|---|---|
| O(n^(1.3—2)) | O(n) | O(n²) | O(1) |
10.結語

2020-3-31: Java基礎語法(6)-註釋
2020-3-31: Java基礎語法(7)-數組
-
今日好文推薦
-
今日資料推薦

