
C/C++ 預處理元編程 從一個問題開始 以下代碼存在結構性重覆,如何消除? ~~~cpp // EventId.h enum EventId { setupEventId = 0x4001, cfgEventId, recfgEventId, releaseEventId // ... }; ~~ ...
C/C++ 預處理元編程
從一個問題開始
以下代碼存在結構性重覆,如何消除?
// EventId.h
enum EventId
{
setupEventId = 0x4001,
cfgEventId,
recfgEventId,
releaseEventId
// ...
};// EventCounter.h
struct EventCounter
{
U32 setupEventCounter;
U32 cfgEventCounter;
U32 recfgEventCounter;
U32 releaseEventCounter;
// ...
};// EventCounter.c
EventCounter g_counter = {0};// CountEvent.c
void countEvent(U32 eventId)
{
switch(eventId)
{
case setupEventId:
g_counter.setupEventCounter++;
break;
case cfgEventId:
g_counter.cfgEventCounter++;
break;
case recfgEventId:
g_counter.recfgEventCounter++;
break;
case releaseEventId:
g_counter.releaseEventCounter++;
break;
// ...
}
}// PrintCounter.c
void printCounter()
{
printf("setupEventCounter = %d \n", g_Counter.setupEventCounter);
printf("cfgEventCounter = %d \n", g_Counter.cfgEventCounter);
printf("recfgEventCounter = %d \n", g_Counter.recfgEventCounter);
printf("releaseEventCounter = %d \n", g_Counter.releaseEventCounter);
// ...
}上面的例子中除了每個文件內部有結構性重覆,文件之間也有結構性重覆!當我們每增加一個消息的定義,都需要依次在四個文件中增加對應的消息ID定義,計數器定義,計數器累加以及計數器列印的代碼,在整個過程中還要保證所有變數名、字元串等的命名一致性問題。
那麼如何解決上述問題呢?最容易想到的方式就是定義一個元數據文件,然後寫個腳本自動掃描元數據文件,自動生成上述四個文件。
例如可以定義一個xml格式的元數據文件event.xml:
<?xml version = "1.0 ecoding = utf-8>
<event>
<item> setup </item>
<item> cfg </item>
<item> recfg </item>
<item> release </item>
<!-- more event-->
</event>然後再寫一個python腳本,按照規則從這個xml自動生成EventId.h、EventCounter.h, CountEvent.c、PrintEvent.c,如下圖所示:

在大的項目中頻繁使用上述方式,往往導致純業務代碼的技術棧不一致!例如元數據定義可以用xml、yaml、json..., 腳本語言可以用python、ruby、perl..., 將會引起如下問題:
- 需要項目中所有構建代碼的機器上安裝對應腳本語言的解釋器;
- 版本的構建過程管理變得複雜;
- 受限於業務軟體人員能力,對於腳本的修改可能會集中在熟練掌握腳本語言語法的人身上;
- 連貫的代碼開發過程,卻要在不同IDE和工具鏈之間切換;
那麼有沒有辦法利用C/C++語言自身完成上述工作呢? 有!那就是利用預處理元編程技巧!
預處理元編程
對於上述問題,我們回顧利用腳本的解決方法: 先定義一份元數據,然後利用腳本將其解釋成四種不同的展現方式! 一份描述,想要在不同場合下不同含義,如果利用宿主語言解決的手段就是多態!
大多數程式員都知道對於C++語言,可以實施多態的階段分為靜態期和動態期。靜態期指的是編譯器在編譯階段確定多態結果,而動態期是在程式運行期確定!靜態多態的常用手段有函數/符號重載、模板等,動態多態的手段往往就是虛函數。
事實上很少有人關註,C/C++的預處理階段也是實施多態的一個重要階段,而這時可以採用的手段就是巨集!
巨集是一個很強大的工具!簡單來說巨集就是文本替換,正是如此巨集可以用來做代碼生成,我們把利用巨集來做代碼生成的技巧叫做預處理元編程!
往往越是強大的東西,越容易被誤用,所以很多教科書都在勸大家謹慎使用巨集,語言層面很多原來靠巨集來做的事情逐漸都有替代手段出現,但是唯獨代碼生成這一點卻沒有能夠完全替代巨集的方式。恰當的使用巨集來做代碼生成,可以解決別的技巧很難完成的事情!相信如果有一天C/C++把巨集從語言中剔除掉,整個語言將會變得無趣很多:)
下麵我們看看如何用預處理元編程來解決上述例子中的問題!
第一種做法
和腳本解決方案類似,首先要定義元數據文件,只不過這次元數據文件是一個C/C++頭文件,對元數據的定義使用巨集函數!
//EventMeta.h
EVENTS_BEGIN(Event, 0x4000)
EVENT(setup)
EVENT(cfg)
EVENT(recfg)
EVENT(release)
EVENTS_END()這份元數據如何解釋,完全看其中的EVENTS_BEGIN、EVENT、EVENTS_END巨集函數如何被解釋了!
接下來我們定義四個解釋器文件,分別對上述三個巨集做不同的解釋,最終做到將元數據可以翻譯到消息ID定義,消息計數器定義,計數函數和列印函數。
// StructInterpreter.h
#define EVENTS_BEGIN(name, id_offset) struct name##Counter {
#define EVENT(event) U32 event##EventCounter;
#define EVENTS_END() };// EventIdInterpreter.h
#define EVENTS_BEGIN(name, id_offset) enum name##Id { name##BaseId = id_offset
#define EVENT(event) , event##EventId
#define EVENTS_END() };// CountInterpreter.h
#define EVENTS_BEGIN(name, id_offset) \
void count##name(U32 eventId) \
{ \
switch(eventId){
#define EVENT(event) \
case event##EventId: \
g_counter.event##EventCounter++; \
break;
#define EVENTS_END() }};// PrintInterpreter.h
#define EVENTS_BEGIN(name, id_offset) \
void printCounter() {
#define EVENT(event) \
printf(#event"EventCounter = %d \n", g_counter.event##EventCounter);
#define EVENTS_END() };由於我們給了同一組巨集多份重覆的定義,所以需要定義一個巨集擦除文件,以免編譯器告警!
// UndefInterpreter.h
#ifdef EVENTS_BEGIN
#undef EVENTS_BEGIN
#endif
#ifdef EVENT
#undef EVENT
#endif
#ifdef EVENTS_END
#undef EVENTS_END
#endif這樣我們就完成了類似腳本工具所作的工作! 註意上面的元數據文件、四個解釋器文件以及最後的巨集擦除文件都是頭文件,但是都不要加頭文件include guard!
最後我們用上述定義好的文件來生成最終的消息ID定義、計數器定義、計數函數以及列印函數!
// EventId.h
#ifndef H529C3CEC_F5B5_4E3D_9185_D82AF679C1D4
#define H529C3CEC_F5B5_4E3D_9185_D82AF679C1D4
#include "interpreter/EventIdInterpreter.h"
#include "EventMeta.h"
#include "interpreter/UndefInterpreter.h"
#endif//EventCounter.h
#ifndef HD8D5D593_CCA2_4FE9_9456_4AD69EF8FA54
#define HD8D5D593_CCA2_4FE9_9456_4AD69EF8FA54
#include "BaseTypes.h"
#include "interpreter/StructInterpreter.h"
#include "EventMeta.h"
#include "interpreter/UndefInterpreter.h"
#endif// CountEvent.c
#include "EventId.h"
#include "EventCounter.h"
#include "interpreter/CountInterpreter.h"
#include "EventMeta.h"
#include "interpreter/UndefInterpreter.h"// PrintCounter.c
#include "EventCounter.h"
#include <stdio.h>
#include "interpreter/PrintInterpreter.h"
#include "EventMeta.h"
#include "interpreter/UndefInterpreter.h"可以看到,代碼生成的寫法很簡單,就是依次包含解釋器文件、元數據文件和巨集擦除文件。 生成文件就是最終我們代碼要使用的文件,這時頭文件則需要加include guard,每個文件還要包含自身依賴的頭文件,做到自滿足。
和使用腳本的解決方案效果一樣,我們以後每次增加一個消息定義只用更改元數據文件即可,其它所有地方會自動生成,避免了很多重覆性勞動!重要的是,預處理元編程仍然是使用C/C++技術棧,不會複雜化開發和構建過程!
另一種做法
除了上述做法外,還有另一種做法,就是把元數據文件定義成一個巨集函數,然後將解釋器定義成不同名的巨集函數,傳給元數據對應的巨集函數。這種做法可以避免定義巨集擦除文件。具體如下:
// EventMeta.h
#define EVENT_DEF( __EVENTS_BEGIN \
, __EVENT \
, __EVENTS_END) \
__EVENTS_BEGIN(name, id_offset) \
__EVENT(setup) \
__EVENT(cfg) \
__EVENT(recfg) \
__EVENT(release) \
__EVENTS_END()依然需要寫四個解釋器文件,每個裡面各自實現一份__EVENTS_BEGIN、__EVENT和__EVENTS_END的巨集函數定義。不同的是每個解釋器文件中的巨集函數可以起更合適的名字,定義只要滿足巨集函數介面特征要求即可! 例如”StructInterpreter.h”和“EventIdInterpreter.h"的定義如下:
// StructInterpreter.h
#define STRUCT_BEGIN(name, id_offset) struct name##Counter {
#define FIELD(event) U32 event##EventCounter;
#define STRUCT_END() };// EventIdInterpreter.h
#define EVENT_ID_BEGIN(name, id_offset) enum name##Id { name##BaseId = id_offset
#define EVENT_ID(event) , event##EventId
#define EVENT_ID_END() };最後做代碼生成,只要把解釋器裡面定義的巨集函數註入給元數據文件定義的巨集函數即可:
// EventId.h
#ifndef H529C3CEC_F5B5_4E3D_9185_D82AF679C1D4
#define H529C3CEC_F5B5_4E3D_9185_D82AF679C1D4
#include "interpreter/EventIdInterpreter.h"
#include "EventMeta.h"
EVENT_DEF(EVENT_ID_BEGIN, EVENT_ID, EVENT_ID_END)
#endif//EventCounter.h
#ifndef HD8D5D593_CCA2_4FE9_9456_4AD69EF8FA54
#define HD8D5D593_CCA2_4FE9_9456_4AD69EF8FA54
#include "BaseTypes.h"
#include "interpreter/StructInterpreter.h"
#include "EventMeta.h"
EVENT_DEF(STRUCT_BEGIN, FIELD, STRUCT_END)
#endif該方法中由於沒有重名巨集,所以也就不再需要巨集擦除文件了。計數函數和列印函數的生成,大家可以自行練習!
上述兩種方法,各自適合不同場合:
第一種方法適合於需要定義大量元數據的場合! 優點是元數據的描述比較簡潔,如同在使用內部DSL。 但是這種方法由於解釋器文件之間存在同名巨集,所以你的IDE在自動符號解析時可能會發出抱怨;
第二種方法由於避免了重名巨集,所以元數據和解釋器的定義不受文件約束。這對於IDE比較友好! 但是定義元數據的方式會受到巨集的語法限制(例如以’ \’換行的噪音)。另外當元數據定義用到大量不同的巨集函數時,每次代碼生成做巨集函數註入也很累。
構建內部DSL
在C++語言中,模板元編程是構建內部DSL的常用武器。模板元編程本質上是一種函數式編程,該技術可以讓C++在編譯期做代碼生成。在實際使用中結合預處理元編程和模板元編程,可以簡化彼此的複雜度,讓代碼生成更加靈活,是C++構建內部DSL的強大武器!
以下是一個在真實項目中應用的例子!
在重構某一遺留系統代碼時,發現該系統包含一個模塊,用來接收另一個控制器子系統傳來的配置消息,然後根據配置消息中攜帶的參數值進行領域對象建立、修改、刪除等操作。該模塊可以接收的配置消息有幾十種,消息均採用結構體定義,每個消息裡面可以嵌套包含其它子結構體,對於消息中的每個子結構體可以有一個對應的present欄位指示該子結構體內的所有參數值在這次配置中是否有效。消息中的每個參數欄位都有一個合法範圍,以及一個預先定義好的錯誤碼。對一個消息的合法性校驗就是逐個檢查消息裡面每一個欄位以及對應present為true的子結構體內的每個欄位是否在其預定的合法範圍內,如果某一個欄位不在合法範圍內,就做錯誤log記錄,然後函數結束並返回對應的錯誤碼!如下是一條配置消息的校驗函數的代碼原型:
Status XxxMsgCheck(const XxxMsg& msg)
{
// ...
if((MIN_VLAUE1 > msg.field1) || (msg.field1 > MAX_VALUE1))
{
ERR_LOG("XxxMsg : field1 is error, expect range[%d, %d], actual value(%d)", MIN_VALUE1, MAX_VALUE1, msg.field1);
return XXX_MSG_FIELD1_ERRCODE;
}
// ...
if(msg.subMsg1Present)
{
if(msg.subMsg1.field1 > MAX_VALUE2)
{
ERR_LOG("XxxMsg->subMsg1 : field1 is error, expect range[0, %d], actual value(%d)", MAX_VALUE2, msg.subMsg1.field1);
return XXX_MSG_FIELD2_ERRCODE;
}
// ...
}
if(msg.subMsg2Present)
{
//...
}
// ...
return SUCCESS;
}可以看到消息校驗函數內的代碼存在大量的結構性重覆,而這樣的函數在該模塊中一共存在幾十個。模塊中最大的一個消息包含四十多個子結構體,展開後一共有800多個參數欄位,僅對這一個消息的校驗函數就達三千多行。該模塊一共不足三萬行,而類似這樣的消息校驗代碼就占了一萬多行,還不算為每個欄位定義錯誤碼、合法範圍邊界值等巨集帶來的頭文件開銷。對這樣一個模塊,消息校驗並不是其領域核心,但是結構性重覆導致其占用了相當大的代碼比例,核心的領域邏輯代碼反而被淹沒在其中。
另一個由此引入的問題在於測試,在對該模塊進行包圍測試的時候發現需要構造一條合法的消息很累。大多數測試僅需關註消息中的幾個參數欄位,但是為了讓消息通過校驗,需要把消息中所有的欄位都賦上合法的值,否則就不能通過校驗。於是有的開發人員在測試的時候,乾脆採用一種侵入式的做法,通過預處理巨集或者全局變數的方式把消息校驗函數關閉。
上述問題可能是類似系統中的一個通用問題,根據不同的場景可以在不同的層面上去解決。例如我們可以追問這種參數校驗是否有價值,以引起防禦式編程風格的爭辯;或者在不考慮性能的時候引入一種數據字典的解決方案;或者為了保持相容來做代碼生成...
在這裡我們給出利用預處理元編程構造內部DSL做代碼生成的解決方式!
通過分析,上述代碼中一共存在四種明顯的結構性重覆。試想每當你為某一個消息增加一個欄位,需要做的事情有:1)在消息結構體中增加欄位定義;2)為該欄位定義錯誤碼;3)在校驗函數中增加該欄位的合法性校驗代碼;4)修改所有使用該消息的測試,將該欄位設置成合法值,以便讓原測試中的消息能夠通過校驗。
那麼採用預編譯元編程的解決思路就是:定義一份元數據描述規則,然後寫四個解釋器文件;通過解釋器文件對元數據進行解釋自動生成上述四種代碼。用戶後續就只用按照規則定義元數據文件,在裡面描述消息結構特征、以及每個欄位的合法範圍特征即可。
考慮到消息的結構體定義往往是介面文件,一般修改受限;而且別的子系統也要使用,需要考慮相容別人的使用習慣,所以對於消息結構體的定義暫不修改,下麵只用代碼生成來解決其它三種重覆。
在本場景中,由於可預期元數據數量很多,而且會經常發生變更,所以我們採用前面介紹的第一種預處理元編程的方式來做。在這裡元數據的描述規則設計很重要,它決定了用戶將來使用是否方便,是否易於理解。事實上其本質就是在定義一種DSL,需要斟酌其中每一個關鍵字的含義和用法。
例如對於下麵的消息:
// XxxMsg.h
struct XxxMsg
{
U8 field1;
U32 field2;
U16 field3;
U16 field4;
U16 field5;
U16 field6;
};按照我們設計的DSL,對其元數據描述文件如下:
// XxxMsgMeta.h
__def_msg_begin(XxxMsg)
__field(field1, LT(3))
__field(field2, NE(3))
__field(field3, GE(1))
__field(field4, BT(2, 128))
__field(field5, __())
__field(field6, OR(LE(2), EQ(255)))
__def_msg_end()可以看到通過__def_msg_begin和__def_msg_end來進行消息的描述。其中需要描述每一個消息欄位的名稱和合法範圍。合法範圍的定義通過下麵幾種關鍵字:
- EQ : ==
- NE : !=
- LE : =<
- LT : <
- GE : >=
- GT : >
- BT : between[min, max]
- OR : || , 即用來組合兩個條件式,滿足其一即可。
- **__** : omit, 即對該欄位不校驗
- OP : user-defined special operation, 即用戶自定義的欄位校驗方式
所有的靜態範圍描述,使用上面的關鍵字組合就夠了;對於動態規則,用戶需要通過關鍵字OP來擴展自定義的校驗方式。
例如對於下麵這個消息SpecialOpMsg,其中的field2欄位的校驗是動態的,它必須大於field1欄位的值才是合法的:
// SpecialOpMsg.h
struct SpecialOpMsg
{
U8 field1;
U8 field2;
};這時對於field2欄位需要按照如下方式自定義一個Operation類,其中使用DECL_CHECK來定義一個方法,描述field2欄位的校驗規則;如果該消息要被測試用例使用的話則還需要用DECL_CONSTRUCT來定義一個field2欄位的創建函數。
在定義方法的時候,消息的名字msg,field2欄位的錯誤碼error都是預定義好的,直接使用即可。
// Field2Op.h
#include "FieldOpCommon.h"
struct Field2Op
{
DECL_CHECK()
{
return (field2 > msg.field1) ? 0 : error;
}
DECL_CONSTRUCT()
{
field2 = msg.field1 + 1;
}
};// SpecialOpMsgMeta.h
__def_msg_begin(SpecialOpMsg)
__field(field1, GE(10))
__field(field2, OP(Field2Op))
__def_msg_end()當有消息結構嵌套的時候,需要逐個描述每個子結構,最後用子結構拼裝最終的消息描述。
例如對於如下消息結構:
// SimpleMsg.h
struct SubMsg1
{
U8 field1;
U32 field2;
};
struct SubMsg2
{
U16 field1;
};
struct SimpleMsg
{
U32 field1;
SubMsg1 subMsg1;
U16 subMsg2Present;
SubMsg2 subMsg2;
};定義的元數據描述如下:
// SimpleMsgMeta.h
/////////////////////////////////////////////
__def_msg_begin(SubMsg1)
__field(field1, LT(3))
__field(field2, NE(3))
__def_msg_end()
/////////////////////////////////////////////
__def_msg_begin(SubMsg2)
__field(field1, GE(3))
__def_msg_end()
/////////////////////////////////////////////
__def_msg_begin(SimpleMsg)
__field(field1, BT(3,5))
__sub_msg(SubMsg1, subMsg1)
__opt_sub_msg(SubMsg2, subMsg2, subMsg2Present)
__def_msg_end()可以看到,可以用__sub_msg來指定包含的子結構;如果某個子結構是由present欄位指明是否進行校驗的話,那麼就使用__opt_sub_msg,指明子結構體類型,欄位名以及present對應的欄位名稱。
對消息描述方式的介紹就到這裡!事實上還有很多實現上的細節,例如:如果欄位或者子結構是數組的情況;如果是數組,數組大小可以是靜態的或者由某一個欄位指明大小的;整個消息中可以包含一個開關欄位,如果開關關閉的話則本消息整體都不用校驗,等等。以下是目前支持的所有描述方式:
- **__field** : 描述一個欄位,需要指明欄位的合法範圍;
- **__opt_field**:描述一個可選欄位,除了給出可選範圍,還要給出對應的present欄位;
- **__switch_field** : 開關欄位,當該欄位關閉態的話,整個消息不做校驗;
- **__fix_arr_field** : 靜態數組欄位,需要指明欄位合法範圍,還需要指明數組靜態大小;
- **__dyn_arr_field** : 動態數組欄位,需要指明欄位的合法範圍,還需要給出指示數組大小的欄位;
- **__fix_arr_opt_field**: 可選的靜態數組欄位,在__fix_arr_field的基礎上給出對應的present欄位;
- **__dyn_arr_opt_field**: 可選的動態數組欄位,在__dyn_arr_field的基礎上給出對應的present欄位;
- **__sub_msg**: 描述一個包含的子結構;
- **__opt_sub_msg**:描述一個包含的可選子結構體;在__sub_msg的基礎上還需給出對應的present欄位;
- **__fix_arr_sub_msg**:靜態數組子結構;在__sub_msg的基礎上還需給出靜態數組的大小;
- **__dyn_arr_sub_msg**:動態數組子結構;在__sub_msg的基礎上還需給給出指示該數組大小的欄位;
- **__fix_arr_opt_sub_msg**:可選的靜態數組子結構;在__fix_arr_sub_msg的基礎上還需給出對應的present欄位;
- **__dyn_arr_opt_sub_msg**:可選的動態數組子結構;在__dyn_arr_sub_msg的基礎上還需給出對應的present欄位;
當利用上述規則描述好一個消息後,我們就可以用寫好的預處理解釋器來生成最終我們想要的代碼了。例如對上面的SimpleMsg, 我們定義如下文件:
#include "SimpleMsg.h"
#include "ErrorCodeInterpret.h"
#include "SimpleMsgMeta.h"
#include "ConstrantInterpret.h"
#include "SimpleMsgMeta.h"
#include "ConstructInterpret.h"
#include "SimpleMsgMeta.h"
const U32 SIMPLE_MSG_ERROR_OFFSET = 0x4001;
__def_default_msg(SimpleMsg, SIMPLE_MSG_ERROR_OFFSET);上面分別用ErrorCodeInterpret.h、ConstrantInterpret.h和ConstructInterpret.h把SimpleMsg消息的元數據描述生成了對應的錯誤碼、供消息校驗用的verify方法以及供測試用例使用的construct方法。在實際中,我們往往會把上面幾個代碼生成放在不同文件中,對於construct的生成只放在測試中。註意最後需要用__def_default_msg描述,給出消息的錯誤碼起始偏移值。另外,可以將__def_default_msg替換成__def_msg,這樣還可以在消息中增加其它自定義方法。在自定義方法中可以直接使用消息的所有欄位。例如:
__def_msg(SimpleMsg, ERROR_OFFSET)
{
bool isXXX() const
{
return (field1 + subMsg1.field1) == 10;
}
};經過上述代碼生成後,就可以把原來的plain msg轉變成一個method-ful msg。它的每個欄位都自動定義了一個從起始值遞增的錯誤碼。它包含一個verify方法,這個方法會根據規則對每個欄位做校驗,在錯誤的時候記錄log並且返回對應的錯誤碼。它還可以包含用戶自定義的其它成員方法。
例如對於SimpleMsg我們可以這樣使用:
TEST(MagCc, should_return_the_error_code_correctly)
{
SimpleMsg msg;
msg.field1 = 3; // OK : __field(field1, BT(3,5))
msg.subMsg1.field1 = 2; // OK : __field(field1, LT(3))
msg.subMsg1.field2 = 1; // OK : __field(field2, NE(3))
msg.subMsg2Present = 1;
msg.subMsg2.field1 = 2; // ERROR:__field(field1, GE(3))
ASSERT_EQ(0x4004, MSG_WRAPPER(SimpleMsg)::by(msg).verify());
}如果生成了construct方法的話,那麼測試用例就可以直接調用其生成一個所有欄位都在合法範圍內的消息碼流:
TEST(MagCc, should_construct_msg_according_the_range_description_correctly)
{
SimpleMsg msg;
MSG_CTOR(SimpleMsg)::construct(msg);
ASSERT_EQ(3, msg.field1);
ASSERT_EQ(2, msg.subMsg1.field1);
ASSERT_NE(3, msg.subMsg1.field2);
ASSERT_EQ(1, msg.subMsg2Present);
ASSERT_EQ(3, msg.subMsg2.field1);
}對於錯誤碼、verify和construct的具體生成實現,主要定義在幾個解釋器文件裡面。對verify和construct的實現使用了一些模板的技巧。利用預處理元編程,可以將對應的巨集翻譯到不同的模板實現上去,所以每組模板可以只用關註一個方面,簡化了模板的使用複雜度。對於預處理元編程在構造內部DSL上的使用就介紹到這裡,本例中的其它細節不再展開,具體的源代碼放在msgcc,可自行下載閱讀。
工程實踐
由於預處理元編程主要在使用巨集的技巧,所以在工程實踐中,使用可以自動巨集展開提示的IDE,會使這一技巧的使用變得容易很多! 例如eclipse-cdt中使用快捷鍵“ctr+=”,可以直接在IDE中看到巨集展開後的效果。
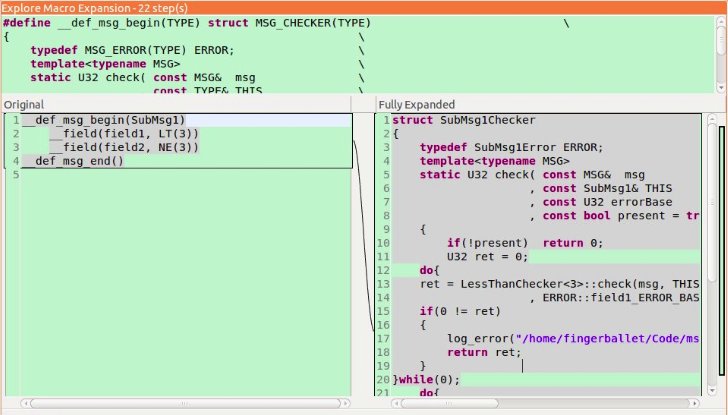
另外,也可以給makefile中增加預處理文件的構建目標,在出問題的時候可以構建出預處理後的源代碼文件,以方便問題定位。
# makefile example
$(TARGET_PATH)%.i : $(SOURCE_PATH)%.cpp
$(CXX) -E -o $@ -c $<總結
預處理元編程利用了巨集的文本替換原理,給一組巨集不同的解釋,做到可以將一份元數據解釋成不同的形式。預處理元編程相比用腳本做代碼生成的方案,和內部DSL相比較外部DSL的優缺點基本一致,優點是可以保持技術棧一致,缺點是代碼生成會受限於宿主語言的語法約束。
預處理元編程是一項很罕用的技術,但是使用在恰當的場合,將會是一項解決結構性重覆的有效技巧! 在C++語言中預處理元編程和模板元編程的結合使用,是構造內部DSL的強大武器! 由於受限於巨集本身的種種限制(難以調試、難以重構),該技巧最好用在結構模式大量重覆,而每個變化方向都相對穩定的情況下! 預處理元編程千萬不要濫用,使用前需要先評估其帶來的複雜度和收益!


