
pyaudio模塊讀取設備名稱來指定相應的設備進行錄音,涉及操作系統編碼、IDE解碼等問題 ...
一、背景和問題
近期在做一個關於音效卡錄音的項目,開發環境是win10 64位家庭中文版,pycharm2019.1,python3.6(Anaconda3),python模塊pyaudio。因為需要實現內錄音(錄製系統內部聲音,而不是麥克風的聲音),因此需要pyaudio模塊讀取設備名稱來指定相應的設備進行錄製。問題來了,系統是中文的,設備也有中文字元(“立體聲混音”)。試來試去,就是find不到設備,pycharm調試,確實遍歷到有好幾個設備,但是都是亂碼的。問題露出頭來了,果然,又是編碼的問題。為什麼用到果然,因為編碼問題之前在做爬蟲的時候可困擾了很久,網頁爬出來的都是各種二進位流數據。再說了,編碼這個即原始又無法迴避的問題,坑可不小。
問題:中文亂碼、AttributeError: 'str' object has no attribute 'decode'、UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc9、Beta版:使用Unicode utf-8提供全球語言支持。
二、編碼的基礎知識
這裡來學習下有關編碼的一些基本知識。這裡要感謝博主joyfixing寫的《徹底搞懂 python 中文亂碼問題》,來龍去脈寫的很詳細,而且相當感同身受,這裡主要進行引用借鑒。
三、關於亂碼
編碼encode就是將字元轉成二進位流,解碼decode就是把二進位流轉成各種的字元。在這兩個相互轉化的過程中,涉及到操作系統、控制台cmd、IDE、文本保存等等,有一環節出現不相容就會亂碼,亂碼的形式可謂眼花繚亂,一臉懵逼。(黑人問號臉)可以網上搜索,這裡就不闡述了。
四、解決方法
在開發的時候,我把程式的編碼設為了utf-8編碼格式。通過這樣設置。# -*- ecoding: utf-8 -*-
天真的以為應該就可以了吧。發現,沒有那麼簡單。如圖,還是一團糟。
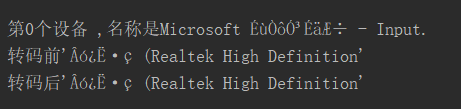
於是乎,就開始了兩天的網上衝浪,而且是手機設的熱點!!!
有人說pycharm設置里要設下文件編碼模式,我就照做了。
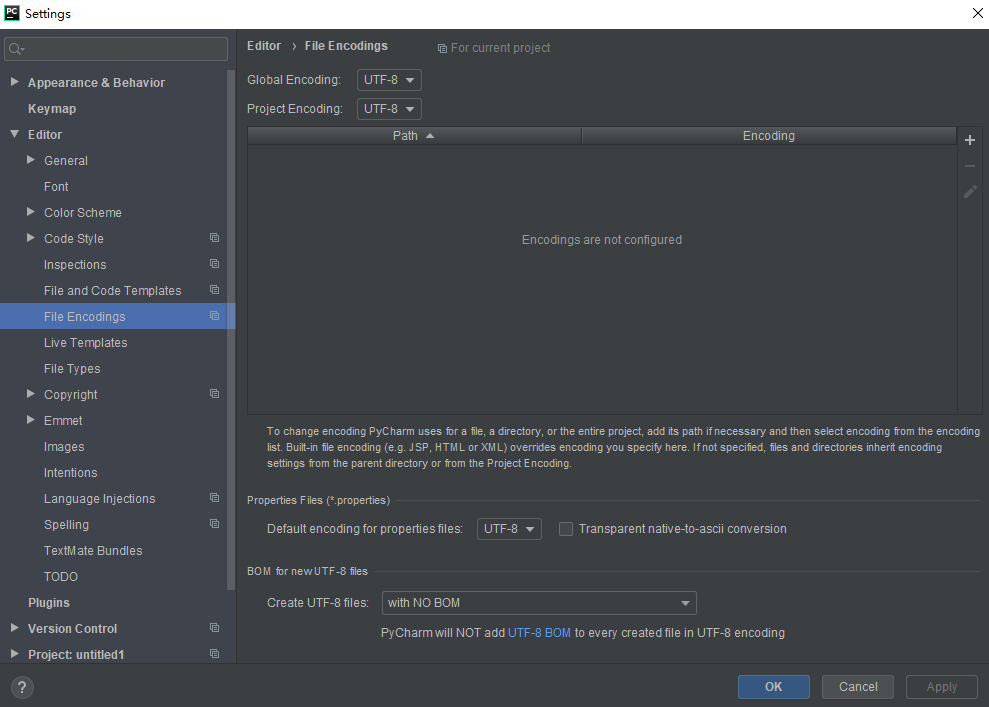
還是沒解決。有人說看下系統預設的編碼模式,我就看了下。返回的都是utf-8啊。
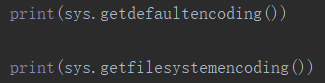

還有人說要decode轉到中間的Unicode字元集,再encode到utf-8.新的問題來了,再搜索,哦,python3和python2不一樣了,3裡面不能這麼用了。(持續黑人問號臉)

又有人說改成這樣,對。在cmd里輸入chcp指令查詢操作系統編碼為936,為gbk。有道理,有些小激動,感覺要出人頭地了呢。

新的問題又來了。UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc9

還有人說加上ignore,把一些沒有的字元集給忽略了,還是亂的!!!
後面就各種編碼方式(utf-8、gb2312、gbk、gb**、utf-8-sig……),各種encode、decode排列組合了,幾乎到了奔潰的邊緣。(我是誰?我在哪?我在乾什麼?)

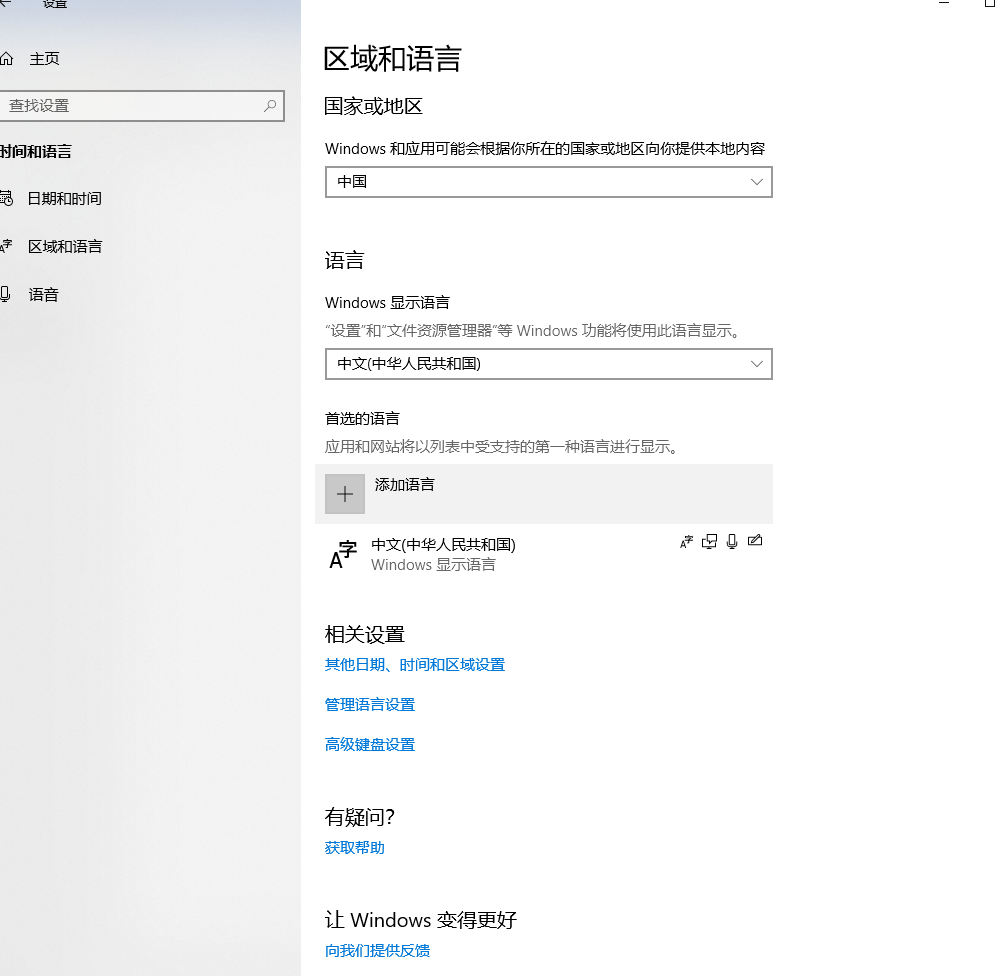
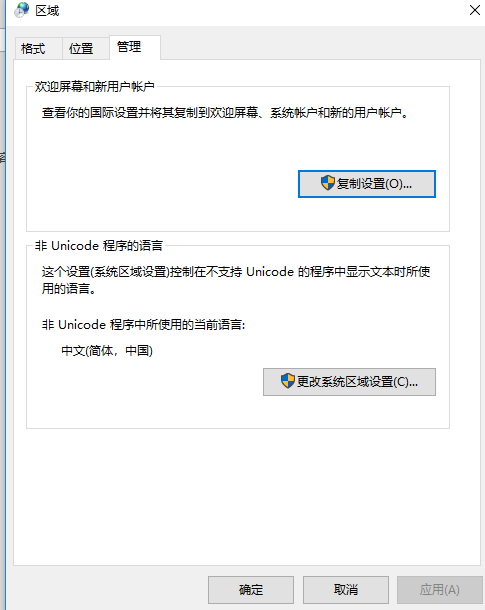
直到看到有人說更改操作系統的語言設置。


 |
 |
 |
 |
時間和語言-管理語言設置-更改系統區域設置-中文(簡體、中國),沒錯啊!!!我也是這樣的啊。重啟。好噠,使出我的殺手鐧—重啟下!!!
稍等片刻,啟動pycharm,調試程式……還!是!亂!碼!啊!啊!啊!
等下,等下,剛纔更改區域語言的時候,下麵有一行字是什麼來著。Beta版:使用Unicode utf-8提供全球語言支持。

操作系統沒有預設的嗎???好噠,勾上,重啟。期待的大眼睛!!!
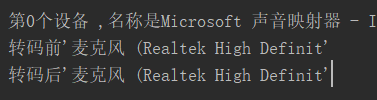
天啊,解決了,困擾了兩天的問題解決了,真的嗎,喜出望外。(我是誰?我在哪?我在乾什麼?)
五、總結
當然,關於編碼問題,還是那句話,即原始,又避不開。這樣設置後,可能有一些軟體會不相容的。
我們站在巨人的肩上,享受時光靜好的同時,適當瞭解原理和前輩走過的路。希望代碼且調且珍惜,bug漸行漸遠。
Ps:
大家在coding的時候,項目文件開始會留下逼格滿滿的註釋,每創建一個就寫一次嗎?不存在的。

在 File | Settings | Editor | File and Code Templates 設置就可以了。
# -*- ecoding: utf-8 -*-
# @ModuleName: ${NAME}
# @FileName : ${NAME}.py
# @Software : ${PRODUCT_NAME}
# @Function :
# @Author : ***
# @blog : https://www.cnblogs.com/imu-ai/
# @E-mail : ***
# @Time : ${DATE} ${TIME}


