
環境: Sql Server2012 SP3企業版,Windows Server2008 標準版 問題由來: 最近在做DB優化的時候,發現一個存儲過程有非常嚴重的性能問題, 由於整個SP整體邏輯是一個多表關聯的複雜的查詢,整體結構比較複雜的,通過的分析和嘗試, 最後發現問題出在其中一個大表的查詢上實 ...
環境:
Sql Server2012 SP3企業版,Windows Server2008 標準版
問題由來:
最近在做DB優化的時候,發現一個存儲過程有非常嚴重的性能問題,
由於整個SP整體邏輯是一個多表關聯的複雜的查詢,整體結構比較複雜的,通過的分析和嘗試,
最後發現問題出在其中一個大表的查詢上實現方式上,
因為這個大表上的意外的執行方式,導致其他表無法被驅動,其他表也是表掃描的方式參與join
導致後面整個表之間join以及查詢編譯出來一系列極其低效的執行效果(不合理的執行計劃)
這裡單獨將這個大表的查詢提取出來作分析
下麵就是我說的大表的這一步在預設情況下的執行情況,
這個表當時數據量是3000W條,符合查詢條件的數據在50W左右(一個月的數據量),
不加強制索引提示下的執行情況(測試之前都DBCC dropcleanbuffer 清理緩存):
因為考慮到結果集比較大,SSMS結果視窗載入數據耗時比較長
我將結果Insert到臨時表的目的是減少SSMS載入數據的時間,更註重查詢內部計算
如下是sql查詢執行信息
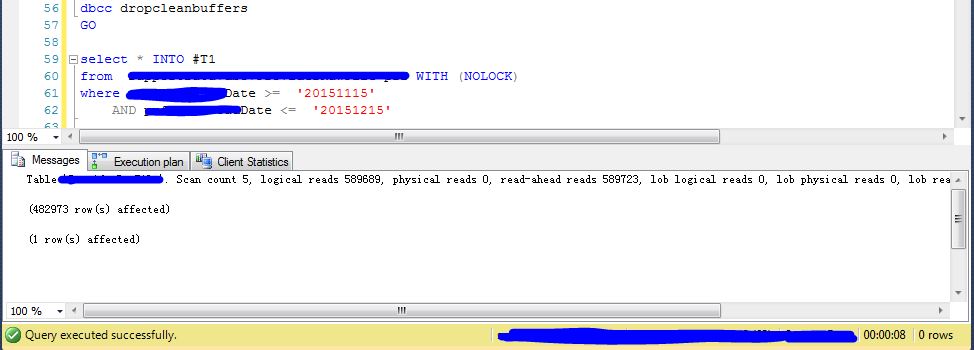
執行計劃情況

可以看到它走了一個跟查詢欄位無關的普通索引的index scan的執行計劃,
加上查詢列上的強制索引提示的執行情況:
如果加一個查詢列上的索引的查詢提示,會發現性能上有一個比較明顯的提升
當加上查詢索引提示之後,2s中就完成了,比上面預設沒有索引提示的方式提高了4倍

執行計劃信息

這裡就有一個問題,預設情況下為什麼沒有採用查詢列所在的索引進行index seek的查找方式,而採用了另外一個索引進行index scan的方式?
如果沒猜錯的話,很可能有人跟我一樣,是認為統計信息沒有更新,索引碎片之類導致的
這個查詢非常簡單,到底是不是索引統計信息,或者索引碎片之類的引起的呢?
這個倒是好辦,對這個表上的所有索引全部重建(rebuild),同時也會促使統計信息的更新。
然後繼續測試,問題依舊!!!
基本上可以認為,外界條件沒有額外干擾的情況下,Sql Server 始終沒有選擇一個執行速度較快的執行計劃,
之所以說Sql Server沒有選擇執行速度較快的執行計劃,而不是說最優的,是因為這個執行計劃是沒辦法直接去評判的,
如果你註意的話,會發現:
不加索引提示的時候:邏輯讀是:589689,物理讀是589723
加了索引提示的時候,邏輯讀是:1992328,但是真正的物理讀並不多,只有11229+2042
邏輯讀的增加是在記憶體中作計算的時候產生的
但是這並不影響後者執行時間更短,
因為後者還有一個記憶體授予(Memory Grant),通過授予一個211M的物理記憶體用來暫存中間結果集來以更高效的方式來執行
所以我前面說Sqlserver沒有選擇“執行速度較快”的執行計劃,而不是說最優化的執行計劃,
因為後者執行更快,但是耗費了更多的伺服器資源,前者執行較慢,但是沒有耗費很多系統資源。
最優化的執行計劃是一個很難用一棒子打死的方式去界定的,到底是以執行時間為評判,還是以資源消耗為評判?
我想sqlserver是以綜合考量去評價的吧,出現這種情況,我只能推斷:預設情況下,評估執行計劃代價的時候,IO的繫數在計算中的權重更大
如果伺服器資源充足的情況下:
肯定寧願為其提供充足資源去讓其更快地執行以相應應用程式的請求
如果伺服器資源不夠充足的情況下:
這個SQl的運行需要這麼多記憶體,
可能就需要為了申請到(比第一種執行方式)足夠多的記憶體而造成更長時間的等待(這裡不細說,比如memory grants pending)
此時,還不如讓他慢慢執行,好歹還能跑出來結果。
這種究竟哪種方式好,哪種方式不好,很難有一個定論,一切都要根據具體情況來定,
資料庫自身不太可能在任何情況下都作出最最明智的選擇,這大概也就是各種關係資料庫預留給用戶一些查詢提示的原因吧。
總結:
以上粗淺地根據一個遇到的實例案例,通過認為改變預設情況下的執行計劃來觀察對比sql的執行效率,在我們對資料庫進行性能調優時提供一種可參考的方法
也能夠幫助我們認識Sql Server在選擇執行計劃時候的一些特點,以幫助我們更加有效地使用Sql Server資料庫。

