[TOC] pandas對象有一個常用數學,統計學方法的集合。大部分屬於歸納或彙總統計。這些方法從DataFrame的行或列中抽取一個Series或一系列的值。 pandas的描述性統計的方法和NumPy的方法相比,內建了處理缺失值的功能,很好地針對於每一個我們需要處理的數據。 一:一些基本方法 1 ...
目錄
pandas對象有一個常用數學,統計學方法的集合。大部分屬於歸納或彙總統計。這些方法從DataFrame的行或列中抽取一個Series或一系列的值。
pandas的描述性統計的方法和NumPy的方法相比,內建了處理缺失值的功能,很好地針對於每一個我們需要處理的數據。
一:一些基本方法
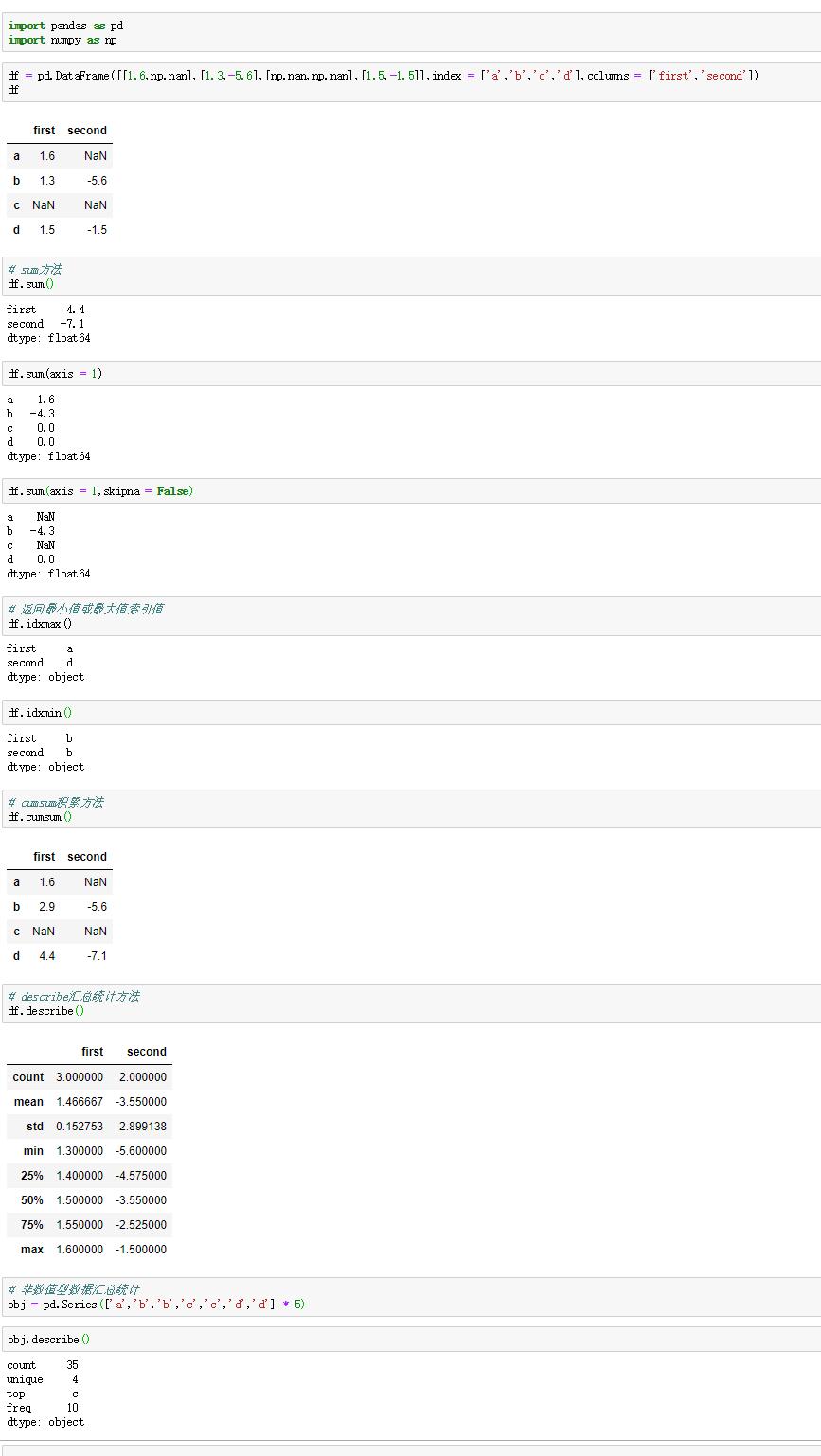
1.歸約方法
sum方法返回一個包含列上加和的Series。 若傳入axis = 'columns'或axis = 1,將會把一行上各個列的值相加。會把缺失值自動排除,可以通過skipna = False設置禁用skipna來實現不排除缺失值。
可用idxmin和idxmax,返回間接統計信息,比如最小值或最大值的索引值。
2.積累型方法
有些方法是積累型方法,比如cumsum是返回積累值。
3.其他方法
還有一些不是歸約方法和積累型的方法,比如describe方法,一次性產生多個彙總統計值。
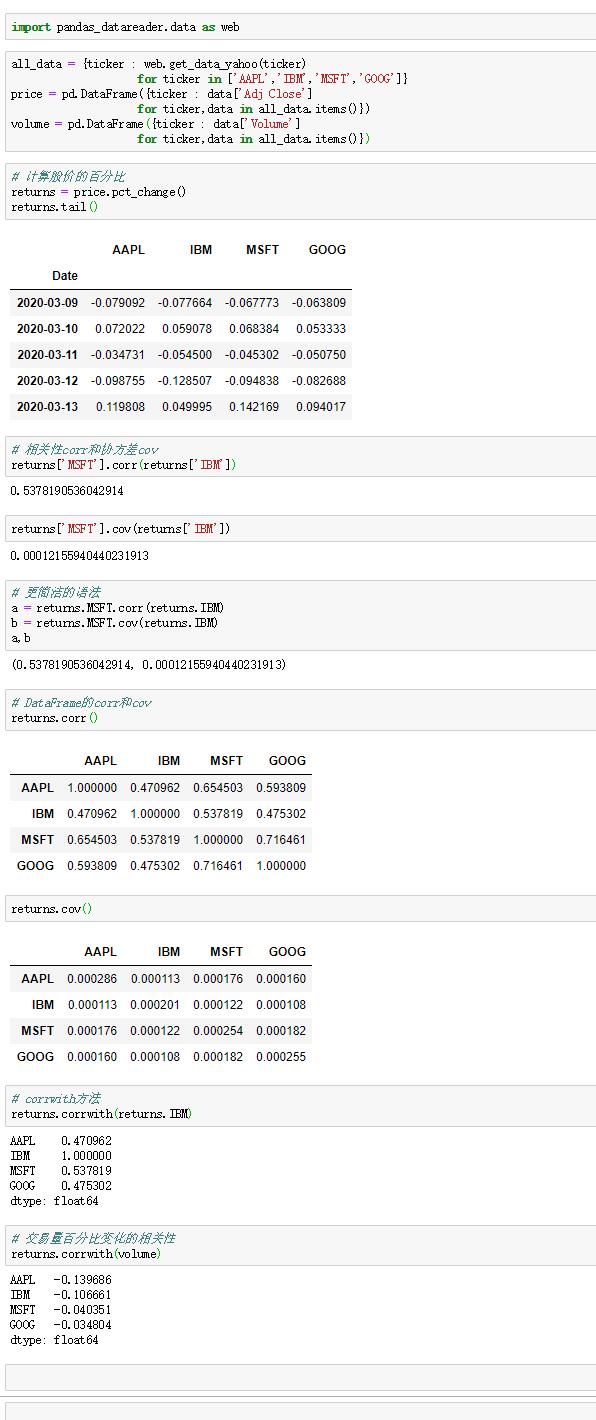
二:相關性和協方差
一些彙總統計,是由多個參數計算出的。與之相關的是一個附加庫,是 pandas-datareader ,可以從Yahoo!Finance上獲取股價和交易量的二維DataFrame數據。
用pct_change和tail獲得股價的百分比。
函數corr方法是計算兩個對象重疊的,非NA的,按索引對其的值的相關性。相應地,cov計算的是協方差。
用DataFrame的corrwith方法,可以計算出DataFrame中的行或列與另一個序列或DataFrame的相關性。 這個方法是一個歸約方法 ,傳入axis = 'columns'或者axis = 1則會對逐行進行操作。
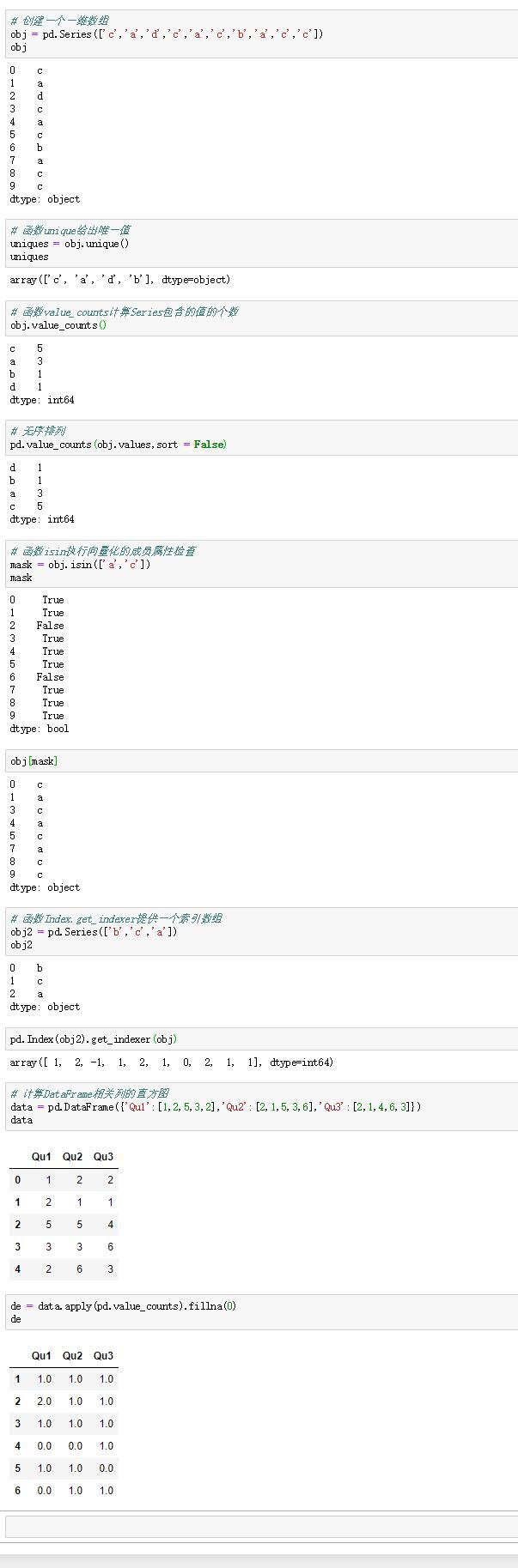
三:唯一值,計數和成員屬性
有些方法可以從數據中提取信息,如下:
函數unique會給出唯一值,可以用uniques.sort()進行排序。
函數value_counts會計算數據中包含值的個數,預設會按照數量降序排列,可以通過設置sort = False不進行降序排列。
函數isin可以檢查數據成員是否和參數匹配,併進行過濾,即去除未匹配的數據。
而與之相關的Index.get_indexer方法,可以提供一個索引數組,將可能非唯一數組轉換為另一個唯一值數組。
函數pandas.value_counts可以計算DataFrame多個相關列的直方圖,得到的直方圖的行標簽是所有列出現的不同值,數值是不同值在每個列中出現的次數。