
2.1 關係資料庫的結構 關係資料庫由表(table)的集合構成,每個表有唯一的名字。例如,instructor表記錄了有關教師的信息,它有四個列首:ID、name、dept_name和salary。該表中每一行記錄了一位教師的信息,包括該教師的ID、name、dept_name以及salary。類 ...
2.1 關係資料庫的結構
關係資料庫由表(table)的集合構成,每個表有唯一的名字。例如,instructor表記錄了有關教師的信息,它有四個列首:ID、name、dept_name和salary。該表中每一行記錄了一位教師的信息,包括該教師的ID、name、dept_name以及salary。類似的,course表存放了關於課程的信息,包括每門課程的course_id、title、dept_name和credits。註意,每位教師通過ID列的取值進行標識,而每門課程則通過course_id列的取值來標識。
第三個表是prereq,它存放了每門課程的先修課程信息。該表具有course_id和prereq_id兩列,每一行由一個課程對組成,這個課程對錶示了第二門課程是第一門課程的先修課。
由此,prereq表中的每行標識了兩門課程之間的聯繫:其中一門課程是另一門課程的先修課。作為另一個例子,我們考察instructor表,表中的行可被認為是代表了從一個特定的ID到相應的name、dept_name和salary值之間的聯繫。
一般來說,表中一行代表了一組值之間的一種聯繫。由於一個表就是這種聯繫的一個集合,表這個概念和教學上的關係這個概念是密切相關的,這也正是關係數據模型名稱的由來。在數學術語中,元組(tuple)只是一組值的序列(或列表)。在n個值之間的一種聯繫可以在數學上用關於這些值的一個n元組(n-tuple)來表示,換言之,n元組就是一個有n個值的元組,它對應於表中的一行。
| ID | name | dept_name | salary |
| 10101 | Srinivasan | Comp. Sci. | 65000 |
| 12121 | Wu | Finance | 90000 |
| 15151 | Mozart | Music | 40000 |
| 22222 | Einstein | Physics | 95000 |
| 32343 | El Said | History | 60000 |
| 33456 | Gold | Physics | 87000 |
| 45565 | Katz | Comp. Sci. | 75000 |
| 58583 | Califieri | History | 62000 |
| 76543 | Singh | Finance | 80000 |
| 76766 | Crick | Biology | 72000 |
| 83821 | Brandt | Comp. Sci. | 92000 |
| 98345 | Kim | Elec. Eng. | 80000 |
| course_id | title | dept_name | credits |
| BIO-101 | Intro. to Biology | Biology | 4 |
| BIO-301 | Genetics | Biology | 4 |
| BIO-399 | Compultational Biology | Biology | 3 |
| CS-101 | Intro. to Computer Science | Comp. Sci. | 4 |
| CS-190 | Game Design | Comp. Sci. | 4 |
| CS-315 | Robotics | Comp. Sci. | 3 |
| CS-319 | Image Processing | Comp. Sci. | 3 |
| CS-347 | Database System Concepts | Comp. Sci. | 3 |
| EE-181 | Intro. to Digital Systems | Elec. Eng. | 3 |
| FIN-201 | Investment Banking | Finance | 3 |
| HIS-351 | World History | History | 3 |
| MU-199 | Music Video Production | Music | 3 |
| PHY-101 | Physical Principles | Physics | 4 |
| course_id | prereq_id |
| BIO-301 | BIO-101 |
| BIO-399 | BIO-101 |
| CS-190 | CS-101 |
| CS-315 | CS-101 |
| CS-319 | CS-101 |
| CS-347 | CS-101 |
| EE-181 | PHY-101 |
這樣,在關係模型的術語中,關係相當於表,而元組相當於行,類似的,屬性相當於列。可見instructor關係有四個屬性:ID、name、dept_name和salary。
我們用關係實例這個術語來表示一個關係的特定實例,也就是所包含的一組特定的行。可見instructor的實例有12個元組,對應於12個教師。
由於關係是元組集合,所以元組在關係中出現的順序是無關緊要的,也就是說,無論怎麼排序,它們都是同樣的元組集合。
對於關係的每個屬性,都存在一個允許取值的集合,稱為該屬性的域。這樣instructor關係的salary屬性的域就是所有可能的工資值的集合,而name屬性的域是所有可能的教師名字的集合。
我們要求對所有關係 r 而言,r 的所有屬性的域都是原子的。如果域中元素被看作是不可再分的單元,則域是原子的。例如,假設instructor表有一個屬性phone_number,它存放教師的一組電話號碼,那麼phone_number就不是原子的,因為一組電話號碼還可以細分出單個電話號碼。
空(null)值是一個特殊的值,標識值未知或不存在。如果某個教師沒有電話號碼,或者不提供,那麼我們只能使用空值來強調該值未知或不存在。
2.2 資料庫模式
談論資料庫時,我們必須區分資料庫模式和資料庫實例,前者是資料庫的邏輯設計,後者是給定時刻資料庫中數據的一個快照。
關係的概念對應於程式設計語言中變數的概念,而關係模式的概念對應於程式設計語言中類型定義的概念。關係實例的概念對應於程式設計語言中變數的值的概念。給定變數的值可能隨事件發生變化;類似的,當關係被更新時,關係實例的內容也隨事件發生了變化。相反,關係的模式是不常變化的。
儘管知道關係模式和關係實例的區別非常重要,我們常常使用同一個名字,比如instructor,既指代模式,也指代實例。在需要的時候,我們會顯式地指明模式或實例。例如“instructor模式”或“instructor關係的一個實例”。然而,在模式或實例的含義清楚的情況下,我們就簡單的使用關係的名字。
考察department關係,該關係的模式是:
department(dept_name, building, budget)
| dept_name | building | budget |
| Biology | Watson | 90000 |
| Comp. Sci. | Taylor | 100000 |
| Elec. Eng. | Taylor | 85000 |
| Finance | Painter | 120000 |
| History | Painter | 50000 |
| Music | Packard | 80000 |
| Physics | Watson | 70000 |
請註意屬性dept_name既出現在instructor模式中,又出現在department模式中。這樣的重覆並非一種巧合。實際上,在關係模式中使用相同屬性正是將不同關係的元組聯繫起來的一種方法。例如,假設我們希望找出Watson大樓工作的所有教師的相關信息。我們首先在department關係中找出所有位於Watson的系的dept_name。接著,對每一個這樣的系,我們在instructor關係中找出與dept_name對應的教師信息。
2.3 碼(主碼-外碼)
我們必須有一種能區分給定關係中不同元組的方法。這用它們的屬性來表明。也就是說,一個元組的屬性值必須是能夠唯一區分元組的。
超碼(superkey)是一個或多個屬性的集合,它可以唯一地標識一個元組。例如,ID是instructor的一個超碼,它可以唯一地標識instructor的一個元組。
超碼中可能包含無關緊要的屬性。例如,ID和name的組合是instructor的一個超碼,但是name是無關緊要的,倒是它的真子集ID也是一個超碼,而且ID集合的任意真子集都不再是instructor的超碼了。我們通常值對這樣的一些超碼感興趣,他們的任何真子集都不能稱為超碼,這樣的最小超碼就被稱為候選碼。
我們用主碼這個術語來代表被資料庫設計者選中的、主要用來在一個關係中區分不同元組的候選碼。碼是整個關係的一種性質,而不是單個元組的性質。關係中的任意兩個不同的元組都不允許同時在碼屬性上具有相同的值。
一個關係模式(如r1)可能在它的屬性中包括另一個關係模式(如r2)的主碼。這個屬性在r1上稱作參照r2的外碼。關係r1也稱為外碼依賴的參照關係,r2叫做外碼的被參照關係。例如,instructor中的dept_name屬性在instructor上是外碼,它參照department,因為dept_name是department的主碼。
現在考察section和teaches關係。如下需求是合理的:如果一門課程是分段授課的,那麼它必須至少由一位教師來講授;當然它可能由不止一位教師來講授。為了施加這種約束,我們需要保證如果一個特定的(course_id, sec_id, semester, year)組合出現在section中,那麼該組合也必須出現在teaches中。可是,這組值並不構成teaches的主碼,因為不止一位教師可能講授同一個這樣的課程段。其結果是,我們不能聲明從section到teaches的外碼約束。從section到teaches的約束是參照完整性約束。
2.4 模式圖
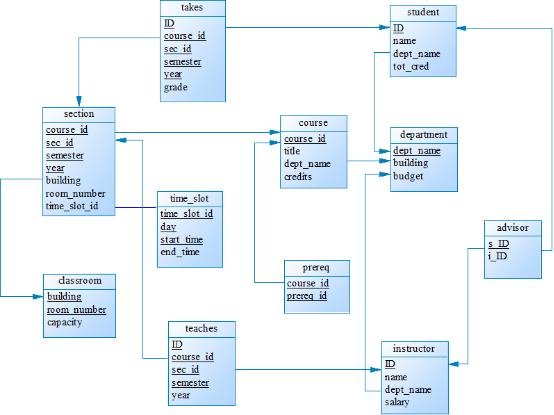
一個含有主碼和外碼依賴的資料庫模式可以用模式圖來標識。下圖展示了我們大學組織的模式圖。每一個關係用一個矩形來標識,關係的名字顯示在矩形上方,矩形內列出各屬性。主碼屬性用下劃線標註。外碼依賴用從參照關係的外碼屬性到被參照關係的主碼屬性之間的箭頭來標識。
2.5 關係查詢語言
查詢語言是用戶從資料庫中請求獲取信息的語言。這些語言通常比標準的程式設計語言層次更高。查詢語言可以分為過程化的和非過程化的。在過程化語言中,用戶知道系統對資料庫執行一些列操作以計算出所需的結果。在非過程化語言中,用戶只需描述所需信息,而不用給出獲取信息的具體過程。
2.6 關係運算
所有的過程化關係查詢語言都提供了一組運算,這些運算要麼施加於單個關係上,要麼施加於一對關係上。這些運算具有一個很好的,並且也是所需的性質:運算結果總是單個關係。這個性質使得人們可以用模塊化的方式來組合幾種這樣的運算。特別是,由於關係查詢的結果本身也是關係,所以關係運算可施加到查詢結果上,正如施加到給定關係集上一樣。
過濾元組:最常用的關係運算是從單個關係(如instructor)中選出滿足一些特定謂詞(如salary>85 000美元)的特殊元組,其結果是一個新的關係,它是原始關係(instructor)的一個子集,而不滿足謂詞的元組就被過濾掉了。
選擇屬性:另一個常用的運算是從一個關係中選出特定的屬性(列)。其結果是一個只包含哪些被選中屬性的新的關係。例如,假設我們只要查出instructor關係的ID和工資,那麼教師的名字和系的名字都不會被查出來。
連接運算可以通過下述方式來結合兩個關係:把分別來自兩個關係的元組對合併成單個元組。有好幾種不同的方式來對關係進行連接。例如,在查出教師信息的同時,也查詢出教師所在系的信息,這樣就把instructor和department連接在一起了。笛卡爾積運算倒是不同了,它的運算結果是包含來自兩個關係元組的所有對,無論它們的屬性值是否匹配,比如一個關係總共有3個元組,另一個關係總共有5個元組,笛卡爾積運算後共有15個元組。
並運算適合在兩個“相似結構”的表上執行,比如一個訂單表和歷史訂單表,我們要查詢出過去和現在所有的訂單,那麼我們就可以將這兩張表並起來。
關係運算的對象不僅僅是已建立的表,還可以是元算的結果。例如,如果我們向找出工資超過85 000美元的教師的ID和salary,我們可以先從instructor關係中選出salary值大於85 000美元的元組,然後從結果中選出ID和salary兩個屬性。
去重:有時候查詢結果包含了重覆的元組,我們要去掉重覆的,例如我們只想找出instructor關係所有的教師的名字,因為教師中可能會有相同的姓名,那麼我們可以在查詢的同時把重覆的名字去掉。

