
網上對於此類的文章已經十分飽和了,那還寫的原因很簡單——作為自己的理解筆記。 前言 此篇文章作為自己學習 的一些個人理解,使用的引擎是 。首先先講講 事務 的概念,在 中其對 事務 的描述是這樣的: 事務就是一組原子性的SQL查詢,或者說一個獨立的工作單元。如果資料庫引擎能夠成功地對資料庫應用該 ...
網上對於此類的文章已經十分飽和了,那還寫的原因很簡單——作為自己的理解筆記。
前言
此篇文章作為自己學習MySQL的一些個人理解,使用的引擎是InnoDb。首先先講講事務的概念,在《高性能MySQL》第三版中其對事務的描述是這樣的:
事務就是一組原子性的SQL查詢,或者說一個獨立的工作單元。如果資料庫引擎能夠成功地對資料庫應用該組查詢的全部語句,那麼就執行該組查詢。如果其中有任何一條語句因為崩潰或其他原因無法執行,那麼所有的語句都不會執行。
換句話說,事務就是一個整體單位,裡面的SQL語句不會單獨執行,就像某些商品一般,由多個組件組成,但是我絕對不單獨賣組件,要買就買整個商品,不然就不賣。
簡單的理解了事務之後,還需要知道事務的目的就是為了保證數據的正確性和一致性,那麼為此則誕生出其4個特性(後面再細講),而為了實現這四個特性又需要許多具體的實現,其中就包括為了隔離性而產生的四個隔離級別,這四種隔離級別又產生了三個問題(臟讀、不可重覆讀和幻讀),這就是其大致的關係,接下來讓我們來看看這些具體到底是個什麼東西。
1 四種特性(ACID)
說起事務的特性,那肯定張口就來ACID,然而除了ACID四個字母之外我們還是需要說點其他東西的。
原子性(Atomicity):意思是說一個事務應當作為一個不可分割的最小單位,整個事務的操作要麼全部執行成功要麼全部不執行,像原子一樣不可分割(別跟我提誇克),這裡的執行是指執行成功,如果有一個操作執行失敗了那麼就全部不執行,這也是我們平時見到的回滾。
一致性(Consistency):書上給出的意思是事務總是從一個一致性的狀態跳到另一個一致性的狀態。我的理解是在涉及到的數據範圍內是守恆的,也就是說,整體的數據是不變的,拿萬能的轉錢例子來說,A賬戶轉給B``200元,那麼由A和B組成的這個數據範圍來說數據並沒有發生改變(-200+200=0),只是數據的組成方式變化了,所以是從一個一致性狀態—>另一個一致性狀態。
隔離性(Isolation):通常來說,一個事務的操作對於其他的事務的不可見的,也就是說一般而言事務都是獨立的。但是這跟資料庫的隔離級別有關,除了某個(沒錯,就是你——讀未提交同學)隔離級別之外,其他的都是不可見的,而這種事務可見的級別很少用到,所以說的是'通常來說'。
持久性(Durability):事務一旦完成,那麼該事務引起的數據變化將永久生效,不會改變(除非被另外一個事務改動)。不過書上提到這其實跟實行的策略相關,但這貌似就有點走遠了(是的,我不懂!)。
以上就是事務的四種特性,然而其中隔離性的實現則是要看資料庫的隔離級別。
2 資料庫的隔離級別
在MySQL中隔離級別有四種,每種隔離級別對應的事務體現不同,可能出現的問題也各自不同。
未提交讀(read uncommited):在這個隔離級別中,在一個事務執行的操作就算不提交也能被其他的事務看到。在這個級別中一個事務可能讀到其他事務還沒提交的臟數據,即可能出現臟讀。如下圖所示,序號表示執行的順序。
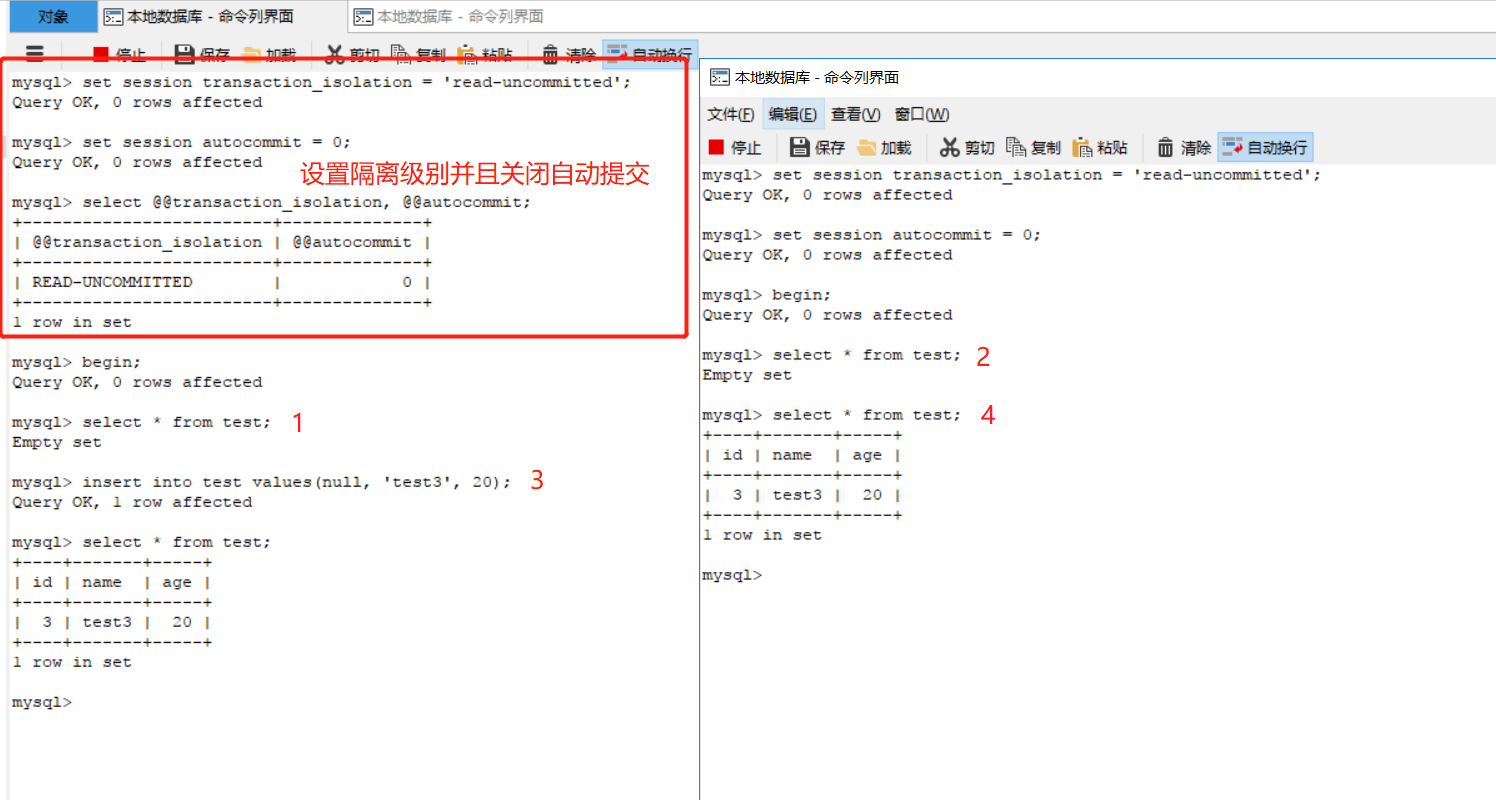
可以看到,在界面1的事務中往test表插入了一條數據,此時就算還沒提交在頁面2的另一個事務中也可以看到提交的數據。
提交讀(read commited):在一個事務提交之後,其他事務才可以看到事務的修改。此隔離級別可能會出現同一個事務中執行相同的查詢卻讀到不同的數據,即不可重覆讀(nonrepeatable read),另未提交讀也可能出現不可重覆讀。例子如下
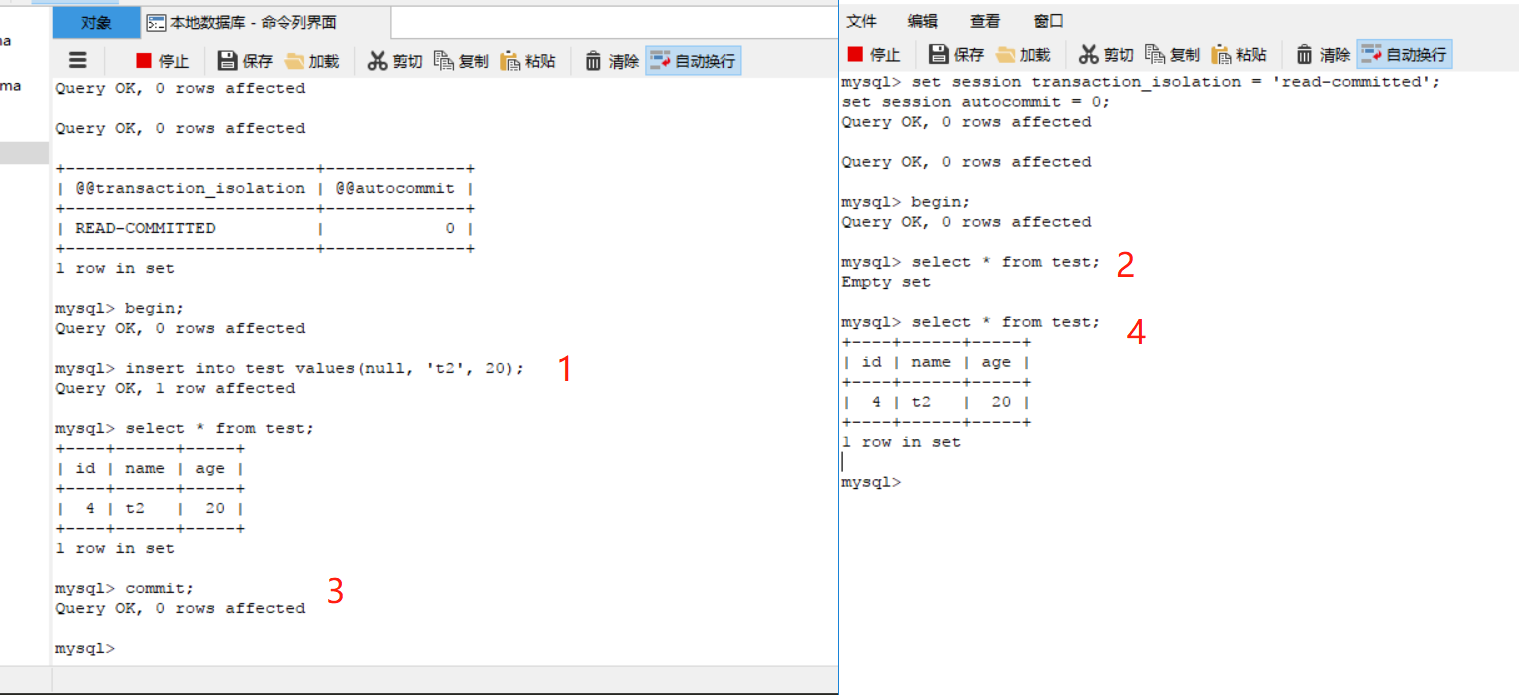
可重覆讀(repeatable read):這是MySQL的預設隔離級別,在事務開始的時候會保存此刻的一個快照(這裡啰嗦一下,實際上是開啟事務後執行第一條語句的時候準備的快照,準備快照的方法則是記錄當前事務的版本號,沒有進行數據的複製,不明白事務版本號或隱藏欄位的可以看看MySQL的MVCC),然後接下來這個事務的所有數據讀取都是從這個快照讀,所以不會出現不可重覆讀的情況,但是還是有可能出現幻讀。意思就是讀取的是快照表數據不會變化,但是進行寫操作如更新的時候更新的數量可能會跟預期的不同。如圖
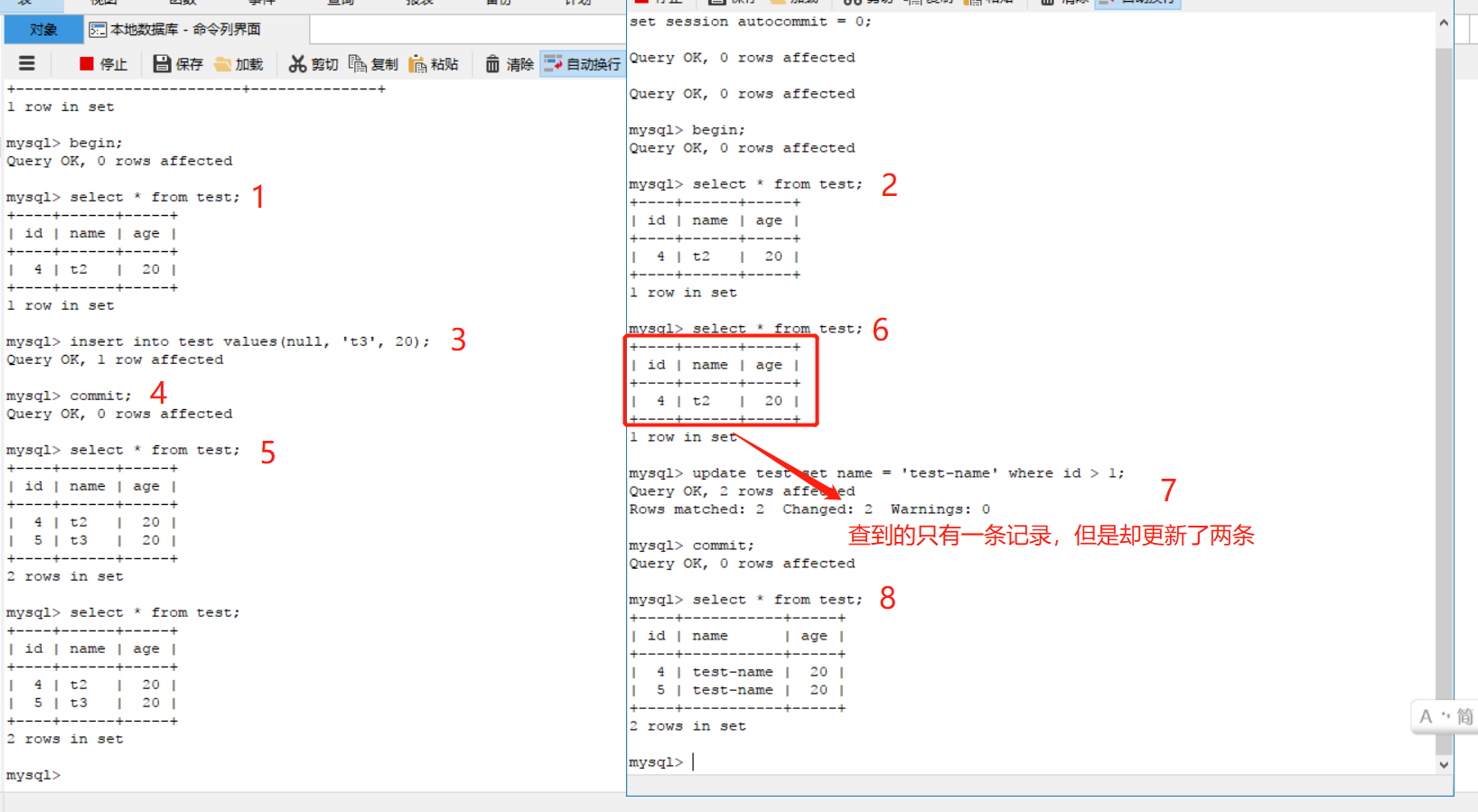
可以看到,在界面1插入一條記錄並且提交之後,界面2還是沒有讀到這個提交的數據,因為他是從事務開始時的快照表讀取的所以自然是讀不到的,但是在進行更新操作的時候則是更新了意料之外的記錄,這就是一種幻讀的現象。
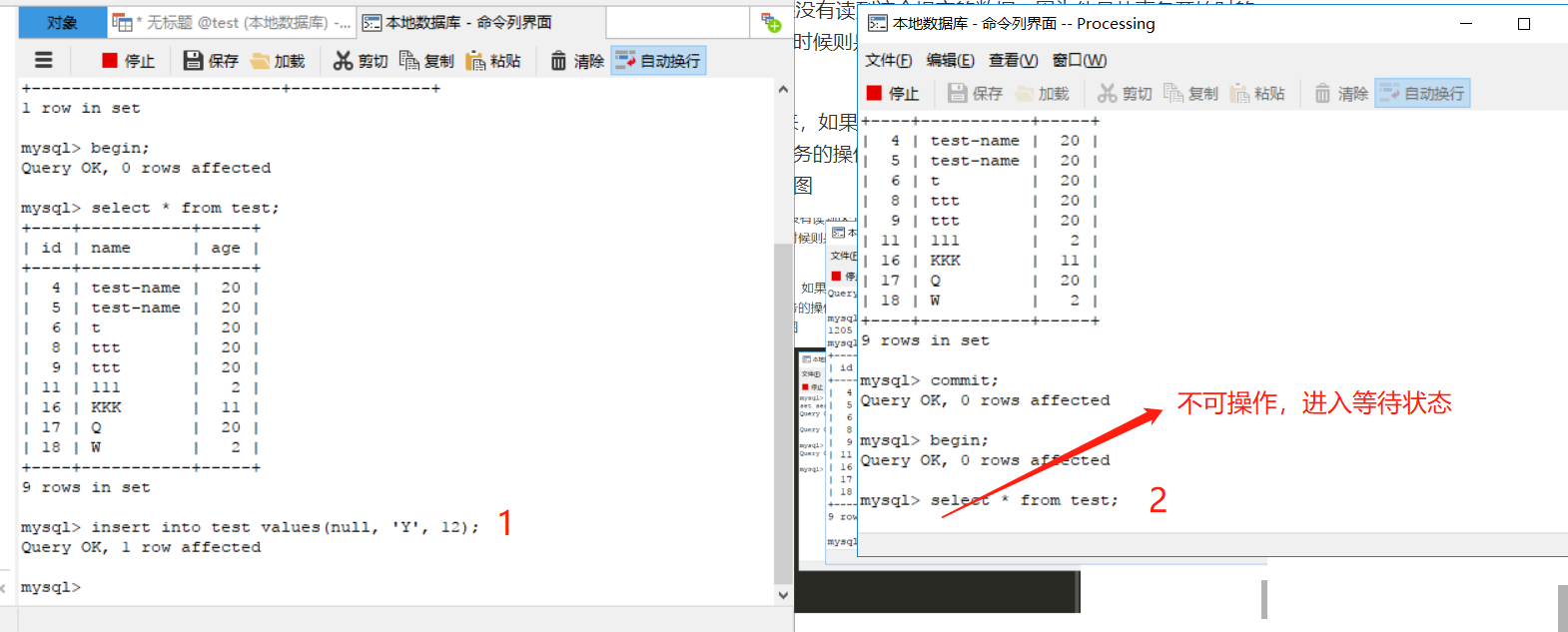
可串列化(serializable):意思就是事務要一個一個來,如果在一個事務中進行讀操作,那麼其他事務在該事務完成前只能進行讀操作;如果進行寫操作,那麼其他事務的操作都進入等待(直到當前事務提交)。這種級別就可以防範目前出現的臟讀、不可重覆讀、幻讀等現象。如圖
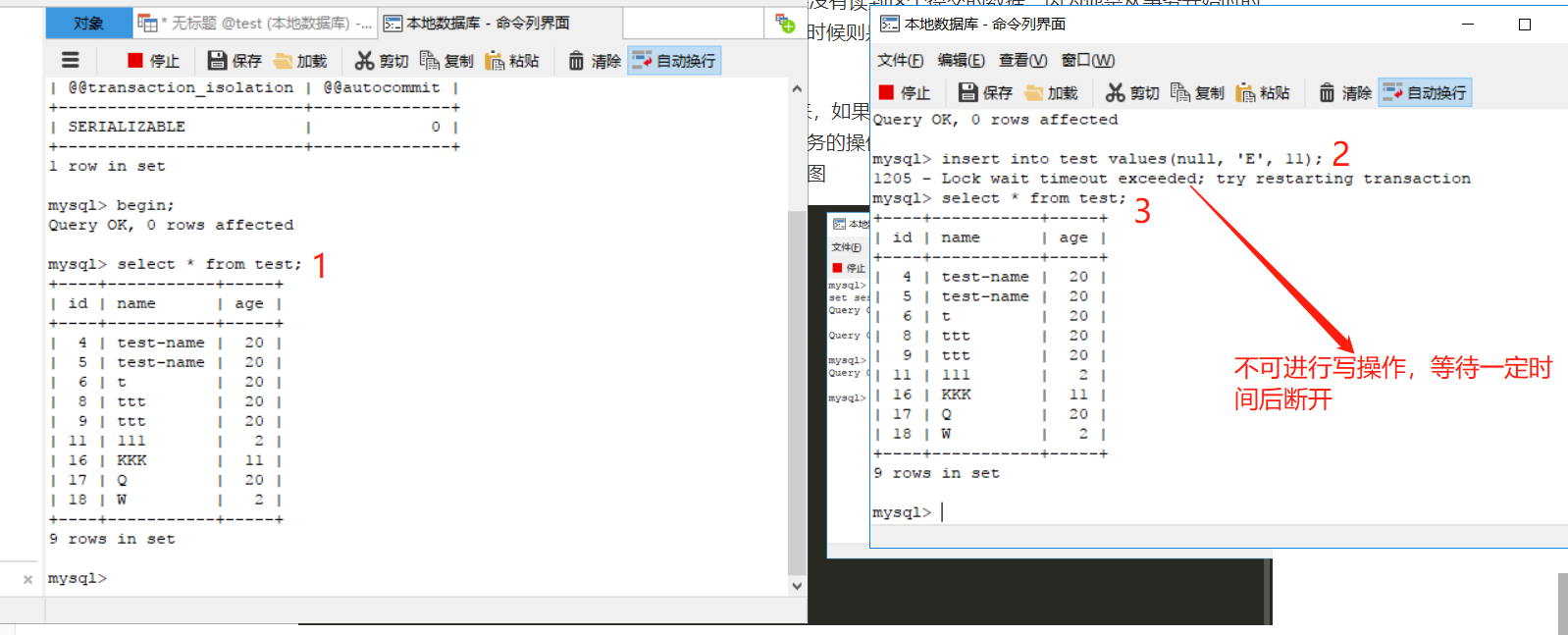
上圖演示的是事務讀時,其他事務不可寫,下圖是寫時不可操作。
3 三個問題—臟讀、不可重覆讀、幻讀。
這是採取事務的不同隔離級別可能產生的幾個問題,在上面隔離級別已經提及到了,但是為了避免混淆還是單獨拿出來。
臟讀:指在一個事務中讀到了其他事務還沒提交的臟數據,發生在讀未提交級別。不可重覆讀:在一個事務中同樣的查詢可能出現不同的結果,發生在讀未提交、讀提交級別。(個人覺得沒必要特意去理解為叫什麼叫不可重覆,容易混淆)幻讀:在一個事務中進行寫操作的時候修改的數量跟預期的數量不同,例如修改到了之前查詢不出來的數據。
再啰嗦一些不可重覆讀和幻讀的區別:可以理解為不可重覆讀是那條記錄的欄位值改變了,例如id為1的記錄中name的兩次值都不同;而幻讀則是數量上的不同,例如我查詢的時候共有2條記錄,但是執行修改操作的時候卻更新了3條。
參考:《高性能MySQL》,http://www.zsythink.net/archives/1233/
或許我只是簡單的想被認可。


