
整型 簡介 # 是否可變類型: 不可變類型 # 作用:記錄年齡、手機號 # 定義: age = 18 # --> 內部操作 age = int(18) # int('sada') # 報錯 int(1.1) # int('1.1') # int() 只能轉純數字的字元串,小數點都不行 a = 111 ...
整型
簡介
# 是否可變類型: 不可變類型
# 作用:記錄年齡、手機號
# 定義:
age = 18 # --> 內部操作 age = int(18)
# int('sada') # 報錯
int(1.1)
# int('1.1') # int() 只能轉純數字的字元串,小數點都不行
a = 11111
print(id(a))
a = 122121
print(id(a))
# 2250375207952
# 2250375207632
# id變了,所以是不可變類型
可變類型不可變類型
''' 可變類型: 值改變的情況下,id不變,說明你改的是原值 不可變類型:值改變的情況下,id一定變 '''
進位轉換
十進位轉其他進位
1 # -------------- 十進位 --> 其他進位 ------------- 2 # 》》》 十進位轉二進位 《《《 3 print(bin(12)) # 0b1100 0b表示後面的數字是二進位數 4 5 # 》》》 十進位轉八進位 《《《 6 print(oct(12)) # 0o14 0o表示後面的數字是八進位14 >>> 1*(8**1) + 4*(8**0) 7 8 # 》》》 十進位轉十六進位 《《《 9 print(hex(12)) # 0xC 0x表示後面的數字是十六進位數 10 11 # 0b1100 12 # 0o14 13 # 0xc
其他進位轉十進位
1 # -------------- 其他進位 --> 十進位 -------------
2 # 》》》二進位轉十進位《《《
3 10 # 1*(2**1) + 0*(2**0) 2
4 print(int('1100', 2))
5 # 12
6
7 # 》》》八進位轉十進位《《《
8 235 # 2*(8**2) + 3*(8**1) + 5*(8**0)
9 print(int('14', 8))
10 # 12
11
12 # 》》》十六進位轉十進位 0-9 A-F《《《
13 217 # 2*(16**2) + 1*(16**1) + 7*(16**0)
14 print(int('c', 16))
15 # 12
浮點型
簡介
# 作用: 薪資、身高、體重
# 是否可變類型:不可變類型
res = float('1.11')
print(type(res))
# <class 'float'>
print(id(res))
res = 1.2 # --> res = float(1.2)
print(id(res))
# 2955868840344
# 2955868840320
字元串
簡介
# 用途:存放描述性信息
# 雖然它可以用索引取值,但其本質上只有一個值
# 有序(有序: 但凡有索引的數據都是有序的)
# 是否可變類型:不可變類型
# 定義方式: '內容', "內容", '''內容''', """內容"""
# 之所以提供這麼多定義方式(引號)是因為引號可能會用到
s = 'hello world' # s = str('hello world')
s1 = str([1, 2, 3, 4]) # 等同於在其兩邊套上了引號
print(s1, type(s1))
# [1, 2, 3, 4] <class 'str'>
s1 = str({'name': 'jason', 'age': 18})
print(s1, type(s1))
# {'name': 'jason', 'age': 18} <class 'str'>
按索引取值
string = 'hello world.' print(string[0]) # h # string[0] = 'H' # 直接報錯,str 字元串類型只能按索引取值,不能通過索引改
len獲取字元個數與in/not判斷是否存在
# len 統計字元串中字元的個數
s = 'hello big baby~'
print(len(s))
# 15
# 使用內置的方法統一採用 句點符(.)
# in , not in 判斷一個子字元串是否存在於一個大的字元串中
s = 'hello big baby~'
print('big' in s)
print('big' not in s)
print('bigger' in s)
print('bigger' not in s)
# True
# False
# False
# True
切片操作
詳見列表類型中的切片部分推薦文章。
# 切片(顧頭不顧尾,步長):從一個大的字元串中截取一段新的小字元串 s = 'hello big baby~' print(s[0: 10]) print(s[0: 10: 2]) # hello big # hlobg print(s[-1]) # -1 取最後一個字元 print(s[-2]) # -2 取倒數第二個字元 # 切片取值預設是從左往右的 print(s[5: 0: -1]) # 從5 開始 到0 (顧頭不顧尾,顧5 不顧 0) # olle print(s[-1: -10]) print(s[-1: -10: -1]) # # ~ybab gib
切片個人小總結
# 關於切片取值的新思路(切片是顧頭不顧尾的) string = '這不過只是一個切片的測試案例而已啦!' # 想要反向截取部分,步長一定是負的 # 想要正常(順序不變)截取字元串前面部分,步長一定是 正的, 起始值用索引正的(0是第一位,第幾位到第幾位) # 前五個字元 print(string[0:5]) # 這不過只是 # 第六到第十三個字元 print(string[5:14]) # 一個切片的測試案例 # 想要正常(順序不變)截取字元串後面部分,步長一定是 正的, 起始值用索引負的(-1倒數第一位, -2倒數第二位,依次類推) # 最後四個字元(寫-1 最後一個取不到。。。 如果終止值寫0,就什麼都去不到了,取值的方向就不對了) # 終止值不寫預設是到最後一個值 print(string[-4: ]) # 而已啦 print(string[-4: -1]) # 而已啦! # 反向截取的不常用,也就不舉例了
內置函數
去除首尾指定字元(串) strip(), lstrip(), rstrip()
# strip() 預設去除字元串左右兩端的指定字元(預設為空,去除左右兩端空格)
name = 'jason'
name2 = ' jason '
print(name == name2, name.strip() == name2.strip())
# False True
# 去除兩端的指定字元
name = '$$$$egon$A$$$'
print(name.strip('$'))
# egon$A
# 去除多字元也可以
name = '$%@ jason*&^('
print(name.strip('$%@ &('))
# jason*&^
# lstrip() 去除字元串左側指定字元
name = '$$jason##$$'
print(name.lstrip('$')) # left 左
# jason##$$
# rstrip() 去除字元串右側指定字元
print(name.rstrip('$')) # right 右
# $$jason##
字元串切割 split(), rsplit()
# split 將字元串按照指定字元切割成列表,可指定切割次數
# split:針對按照某種分隔符組織的字元串,可以用split將其切分成 [列表] ,進而進行取值
# 切割順序是從左往右的
data = 'jason|123|handsome'
name, age, description = data.split('|')
print(data.split('|'))
print(name, age, description)
# ['jason', '123', 'handsome']
# jason 123 handsome
data = 'jason|123|handsome'
print(data.split('o', 1)) # 通過參數指定切割次數
print(data.split('o'))
print(data.rsplit('o'))
# ['jas', 'n|123|handsome']
# ['jas', 'n|123|hands', 'me']
# ['jas', 'n|123|hands', 'me']
# 如果不指定,rsplit() 和 split() 是一樣的
將字元串以指定字元(串)作為分隔拼接起來
# join 將列表以指定字元串作為分隔拼接起來
data = 'jason|123|handsome'
res_list = data.split('|')
res_str = ' '.join(res_list)
print(res_str)
# jason 123 handsome
# l = [1, 'a', 'b']
# res = '|'.join(l) # ----》報錯,不同類型不能相加(拼接)《----
# print(res)
作為迭代器對象迴圈遍歷 for 變數 in 字元串對象
# 在for 迴圈中遍歷
data = 'jason|123|handsome beatiful'
for i in data:
print(i, end='--')
# j--a--s--o--n--|--1--2--3--|--h--a--n--d--s--o--m--e-- --b--e--a--t--i--f--u--l--
print()
轉換字元串的大小寫(隻影響字母) lower upper capitalize swapcase title
# lower upper 函數統一轉換字元串的大小寫 s = 'HAfaganGA' print(s.lower()) print(s.upper()) print(s) # hafaganga ————> 全轉換成小寫 # HAFAGANGA ————> 全轉換成大寫 # HAfaganGA ————> s 本身沒有發生改變 # 調用方法並不改變字元串本身 # captallize swapcase titlle 大小寫轉換意義化 s = 'hElLo WoRLD10' print(s.capitalize()) # 整個字元串首字母大寫,其他都變小寫(全大寫文章轉換成句子) print(s.swapcase()) # 大小寫交換 print(s.title()) # 單詞之間首字母大寫 (全大寫單詞轉換成首字母大寫的單詞) # Hello world10 # HeLlO wOrld10 # Hello World10
判斷字元串否與以指定字元開頭/結尾 startwith endwith
# startswith 判斷字元串是否以...開頭
# endswith 判斷字元串是否以...結尾
s = 'jason dsb'
print(s.startswith('jas'))
print(s.endswith('sb'))
# True
# True
字元串格式化 format
# format 字元串格式化 (python推薦使用format 做替換,做格式化輸出)
# 三種玩法
# 1.按位置占位 --> 與 %s 原理一樣
name = 'jason'
age = 18
str1 = 'my name is {} my age is {}'.format(name, age)
print(str1)
# my name is jason my age is 18
# 2.按索引占位 --> 支持一個變數多個位置調用
str1 = 'my name is {0} my age is {0}'.format("egon", 18)
print(str1)
# my name is egon my age is egon # {0} {0}都用的第一個參數
# 3.指名道姓(關鍵字傳參)占位,同樣支持一個(關鍵字)變數多個位置調用
name = 'jason'
age = 18
str1 = 'my name is {name} my age is {age} name = {name}'.format(name=name, age=age)
print(str1)
# my name is jason my age is 18 name = jason
將字元串的指定字元(串)替換成新的指定字元(串),可以指定次數
# replace 替換指定字元(串)成新的指定字元(串),可指定次數
string = 'egon is dsb and egon is sb and egon has a BENZ'
res = string.replace('egon', 'kevin', 2)
print(res)
# kevin is dsb and kevin is sb and egon has a BENZ
# replace('要替換的舊字元串', '新的字元串', 替換個數)
字元串是否是數字 isnumeric isdecimal isdigit
# is 數字系列
# isnumeric() 只要是數字都識別,不能識別二進位
# isdecimal() 只能識別普通的阿拉伯數字 0123456789
# isdigit() 數字都能識別(包括二進位) --> 通常情況下使用它就能滿足需求了
# 在python3中
num1 = b'4' # bytes
num2 = u'4' # unicode,python3中無需加u就是unicode
num3 = '壹' # 中文數字
num4 = 'Ⅳ' # 羅馬數字
# ''.isnumeric(): unicode,中文數字,羅馬數字
# print(num1.isnumeric()) # 直接就會報錯,num1 根本就沒有isnumeric 這個方法
print(num2.isnumeric())
print(num3.isnumeric())
print(num4.isnumeric())
# True
# True
# True
# ''.isdecimal(): unicode
# print(num1.isdecimal()) # 直接報錯,num1 根本就沒有isdecimal 這個方法
print(num2.isdecimal())
print(num3.isdecimal())
print(num4.isdecimal())
# True
# False
# False
# ''.isdigit() :bytes,unicode
print(num1.isdigit())
print(num2.isdigit())
print(num3.isdigit())
print(num4.isdigit())
# True
# True
# False
# False
# isdigit() 字元串是否是數字, 直接 int() 非數字的字元串會直接報錯
# 用來判斷字元串是否是純數字
age = input('>>>:')
if age.isdigit():
print(f"age = {age}")
else:
print("請好好輸入")
# 後續代碼待完善,用pass 頂一下,後續再寫
pass # 在if、while、for中不知道寫什麼了,可以暫時用 pass 補全python代碼塊結構(搭框架,然後慢慢補充)不報錯
其他主瞭解部分
查找指定元素的在字元串中的索引 find rfind index rindex
# find index
s = '"kevin is dsb and kevin is sb"'
# find('dsb') # 返回的是d字元所在的索引值,找不到的時候不報錯,返回的是 -1
# find('dsb', 0, 3) # 在 0 - 2(3, 顧頭不顧尾) 的索引中查找字元(0, 3)限制查找範圍
print(s.find('vin'))
print(s.rfind('vin'))
# 3
# 20
# index('0') # 返回所傳字元所在的索引值,找不到的時候會在直接報錯
# find('dsb', 0, 3) # 在 0 - 2(3, 顧頭不顧尾) 的索引中查找字元(0, 3)限制查找範圍
print(s.index('vin'))
# 3
print(s.rindex('vin'))
# 20
統計某個字元(串)在字元串中出現的次數 count
# count
# 統計所傳參數在字元串中出現了幾次
s = '"kevin is dsb and kevin is sb"'
print(s.count('vin'))
# 2
字元串格式化填充(對齊功能) center ljust rjust zfill 可指定填充符
# 字元串格式化填充(對齊) center ljust rjust zfill s = 'jason' # center 把現在的字元串居中,其他的用指定字元在兩遍填充,使其達到指定長度 print(s.center(40, '$')) # 不能左右平分的時候,右邊會比左邊多一個 print(s.ljust(40, '$')) print(s.rjust(40, '$')) print(s.rjust(40, ' ')) # 可以用在左對齊右對齊上 print(s.zfill(40)) # zfill z 表示zero 零 # $$$$$$$$$$$$$$$$$jason$$$$$$$$$$$$$$$$$$ # jason$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$ # $$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$jason # 00000000000000000000000000000000000jason
製表符擴展成指定個數 expandtabs
# expandtabs 擴展tab 成..指定個數..個空格 (\t 製表符) s = 'a\tbc' s2 = 'abc' print(s, '---', s2) print(s.expandtabs(), '---', s2.expandtabs()) print(s.expandtabs(6)) # a bc --- abc # a bc --- abc # a bc
轉義字元知識擴展(Python中 '\r' 的實際應用 ——>該文章中利用 '\r' 實現了命令行中實現倒計時、轉圈、百分比進度條的案例,厲害)
# \n 表示回車
string1 = '-a-\n-b-'
string2 = '-a-\r-b-'
print(string1)
print('--------------')
print(string2)
# -a-
# -b-
# --------------
# -b-
print()
# \r 表示將游標的位置回退到本行的開頭位置(將控制台當前行刪除)
print('-----------------', end='')
print('-a-', end='')
print('\r', end='')
print('-b-', end='')
# -b-
print()
# \b 表示將游標的位置回退一位(在控制台當前行最後刪除一個字元)
print('-----------------***', end='')
print('\b\b|||')
# -----------------*|||
列表
簡介
# 作用:記錄多組數據,愛好
# 是否可變類型: 可變類型,可以通過索引改值(l[1] = 2)
# 是否有序:有序
# 定義:list內部原理就是for 迴圈取值,然後一個個塞到列表中去
list_a = [1, 2, 3, 4] # list_a = list([1, 2, 3, 4])
list_a = list('[1, 2, 3, 4]')
print(list_a)
# ['[', '1', ',', ' ', '2', ',', ' ', '3', ',', ' ', '4', ']']
list_a = list('1,2,3,4')
print(list_a)
# ['1', ',', '2', ',', '3', ',', '4']
list_a = list('1234')
print(list_a)
# ['1', '2', '3', '4']
切片
推薦一篇寫得非常好的文章,其切片用列表舉例(徹底搞懂Python切片操作)
列表對象[起點索引: 終點索引: 步長]
起點索引代表開始位置的索引值(可以為負數,負幾就是從右往左數第幾)
終點索引代表結束位置的索引值(可以為負數,負幾就是從右往左數第幾)
步長正負代表方向,預設值為1代表從左往右
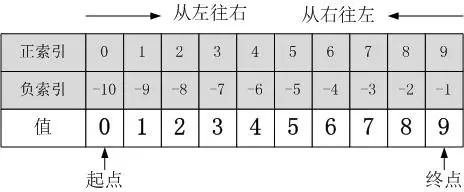

l = [1, 2, 3, 4] print(l[0::]) # [1, 2, 3, 4] # 第二參數不寫預設到 最後一個,第三個參數不寫預設是1 print(l[5::-1]) # [4, 3, 2, 1]
添加元素 (.append() .insert() .extend())
# append l = [1, 2, 3, 4] l.append(5) print(l) l = [1, 2, 3, 4] l.append([5, 6, 7]) # 尾部添加元素,被添加的數據會被當做一個元素 print(l) # [1, 2, 3, 4, [5, 6, 7]] # insert(索引, 要添加的元素) -->通過索引往指定位置(索引處)添加 l = [1, 2, 3, 4] l.insert(3, 'hello') print(l) # [1, 2, 3, 'hello', 4] l = [1, 2, 3, 4] l.insert(-1, [5, 6, 7]) # insert 意思是在某個索引前添加元素 # 被添加的數據會被當做一個元素 print(l) # [1, 2, 3, [5, 6, 7], 4] l = [1, 2, 3, 4] l.insert(len(l), [5, 6, 7]) # 利用insert特點在列表最後追加元素 print(l)
# [1, 2, 3, 4, [5, 6, 7]] # extend 將列表與另一個容器對象拼接 l = [1, 2, 3, 4] l2 = ['hello', 'world'] l.extend(l2) # 將列表與另一個列表拼接,在後面追加 ---> 原理就是for迴圈一個個動態 append # l.extend([1]) # 要用extand 添加單個元素,需要將其寫成 容器類型(extend原理迴圈的對象必須是 容器類型) # l.extend(1) # 會直接報錯,因為 1 不是容器類型數據對象 print(l) # [1, 2, 3, 4, 'hello', 'world'] l = [1, 2, 3, 4] l2 = {'name': 'jason', 'age': 18} l.extend(l2) # extend 字典對象,會將字典的key 作為元素添加與列表合併(list本質for迴圈,而字典在迴圈時暴露出來的是key ) print(l) # [1, 2, 3, 4, 'name', 'age'] l = [1, 2, 3, 4] l.extend('helloworld') # extend str字元串類型,會將字元串每一個字元都單獨作為一個元素與列表合併(str可以被for 迴圈迭代遍歷) print(l) # [1, 2, 3, 4, 'h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd']
刪除元素(del 對象, .pop(可選參數-->索引) .remove(參數-->元素對象))
del 刪除
# del 適用於所有的刪除操作 l = [1, 2, 3, 4] # print(del l[2]) # 會報錯, del 沒有返回值 del l[2] print(l) # [1, 2, 4] # 刪除其他類型舉例 s = 'cvnm' # print(del s) # 會報錯, del 沒有返回值 # del s # print(s) # 會報錯,因為s 已經被刪掉了,現在s 是未定義的
pop 與 remove
# pop 彈出,尾部彈出 pop有返回值,會列印當前彈出對象的值 ---> 可以用在註銷登錄時,可以獲取到用戶的用戶名 l = [1, 2, 3, 4] print(l.pop()) print(l) # 4 # [1, 2, 3] l = [1, 2, 3, 4] print(l.pop(0)) # 可以指定彈出索引處的元素 print(l) # 1 # [2, 3, 4] # remove l = [1, 2, 3, 4] print(l.remove(1)) # 刪除了已存在的元素返回 None, 不存在的元素會直接報錯(ValueError: list.remove(x): x not in list) # print(l.remove(6)) # remove一個不存在的值,直接報錯 # print(l.remove()) # 直接報錯,remove 必須傳入一個要刪除的元素 print(l) # None # [1, 3, 4]
模擬隊列、堆棧操作
# 隊列: 先進先出,後進後出
demo_list = ['first', 'second', 'third']
print(demo_list)
# ['first', 'second', 'third']
# 進隊
demo_list.append('fourth')
print(demo_list)
# ['first', 'second', 'third', 'fourth']
# 出隊
demo_list.pop(0) # 將第一個元素刪除(第一個出列 --> 先進先出,後進後出)
print(demo_list)
# ['second', 'third', 'fourth']
# 堆棧: 先進後出,後進先出
demo_list = ['first', 'second', 'third']
print(demo_list)
# ['first', 'second', 'third']
# 進棧
demo_list.append('fourth')
print(demo_list)
# ['first', 'second', 'third', 'fourth']
# 出棧
# demo_list.pop() # 預設參數 -1
demo_list.pop(-1) # 將最後一個元素刪除(最後一個出列 --> 先進後出,後進先出)
print(demo_list)
# ['first', 'second', 'third']
列表與字元串互轉
# ------------- 利用 str字元串的內置函數 split 與 join 完成 列表與字元串的互轉 ----------- l = ['hello', 'thank', 'you', 'thank', 'you', 'very', 'much'] print(l) # ['hello', 'thank', 'you', 'thank', 'you', 'very', 'much'] connect = '-我是連接符-' print(connect.join(l)) # hello-我是連接符-thank-我是連接符-you-我是連接符-thank-我是連接符-you-我是連接符-very-我是連接符-much ''' # 使用字元串的 join 方法將列表轉成字元串 # 調用 .join 方法的對象就是 列表元素連接的連接符 ''' split_string = connect.join(l) print(split_string) print(split_string.split(connect)) # ['hello', 'thank', 'you', 'thank', 'you', 'very', 'much'] print(split_string.split(connect) == l) # True
向python 列表尾部追加元素的幾種方式(目前已知)
# 向python 列表尾部追加元素的幾種方式(目前已知) # 1.append l = [1, 2, 3, 4] l.append([5, 6, 7]) print(l) # [1, 2, 3, 4, [5, 6, 7]] # 2.insert l = [1, 2, 3, 4] l.insert(len(l), [5, 6, 7]) # 利用insert 在列表最後追加元素 print(l) # [1, 2, 3, 4, [5, 6, 7]] # 3.extend 可一次性追加多個元素 l = [1, 2, 3, 4] l.extend([5, 6, 7]) print(l) # [1, 2, 3, 4, 5, 6, 7] # 追加單個元素 l = [1, 2, 3, 4] l.extend([5]) # 這裡不能寫成 5, 會報錯, 應該寫成 容器對象(列表) print(l) # [1, 2, 3, 4, 5] # 4.切片 可一次性追加多個元素 l = [1, 2, 3, 4] l[len(l): len(l)] = [5, 6, 7] print(l) # [1, 2, 3, 4, 5, 6, 7] # 追加單個元素 l = [1, 2, 3, 4] l[len(l): len(l)] = [5] # 這裡不能直接寫成 5, 會報錯, 應該寫成 容器對象(列表) print(l) # [1, 2, 3, 4, 5]
# 關於套用對象的補充(深拷貝淺拷貝) l = [1, 2, 3, 4] l2 = [5, 6, 7] l.append(l2) print(l, l2) print(id(l), id(l2)) # [1, 2, 3, 4, [5, 6, 7]] [5, 6, 7] # 1894310619272 1894311439560 l2[0] = 6 # 在l append l2 之後, 改變l2 的第一個元素 print(l, l2) print(id(l), id(l2)) # [1, 2, 3, 4, [6, 6, 7]] [6, 6, 7] # 1894310619272 1894311439560 # 比較結果發現 l2內部改變了 並且 l1的內部元素也發生了改變 # --> 所以這是淺拷貝,賦值完成後改變了l2的值 l1受到了影響 --> [1, 2, 3, 4, [6, 6, 7]] [6, 6, 7] # 如果是深拷貝,賦值完成後改變l2 的值 l1 不會受到影響 --> [1, 2, 3, 4, [5, 6, 7]] [6, 6, 7]


