
@ "TOC" JDK1.7:數組+鏈表 JDK1.8:數組+鏈表+紅黑樹 前五個問題環境用的是是JDK1.7,後面全部是1.8 1、Hash的計算規則? 簡單的說是個“擾動函數”,目的是為了使散列分佈的更加均勻。 具體演算法是用key的Hashcode值右移16位,將hashcode高位和低位的值進 ...
目錄
- 1、Hash的計算規則?
- 2、HashMap是怎麼形成環形鏈表的(即為什麼不是線程安全)?(1.7中的問題)
- 3、JDK1.7和1.8的HashMap不同點?
- 4、HashMap和HashTable的區別?
- 5、ConCurrentHashMap?
- 為什麼載入因數是0.75
- HashMap構造函數:
- HashMap數組預設的值
- tableSizeFor(int cap)
- 為什麼HashMap的容量一定是2的冪
- put方法
- resize()方法
- hash()方法
- 為什麼使用(n - 1) & hash而不用 value % n
- put方法中,如果產生衝突除了覆蓋或者不覆蓋還使用了afterNodeAccess
- LinkedHashMap和HashMap的區別
- put方法中的桶的樹型化擴充treeifyBin()
- treeify()方法是TreeNode結點內部的一個方法,實際作用才是將一條鏈表樹化
- remove方法
- get方法
@(HashMap源碼刨析)
JDK1.7:數組+鏈表
JDK1.8:數組+鏈表+紅黑樹
前五個問題環境用的是是JDK1.7,後面全部是1.8
1、Hash的計算規則?
簡單的說是個“擾動函數”,目的是為了使散列分佈的更加均勻。
具體演算法是用key的Hashcode值右移16位,將hashcode高位和低位的值進行混合做異或運算,低位的信息中加入了高位的信息,這樣高位的信息被變相的保留了下來。摻雜的元素多了,那麼生成的hash值的隨機性會增大,得到Hash。最後與table長度進行與運算(indexFor()方法),和取餘是一個結果,不過與運算更加節省電腦資源。
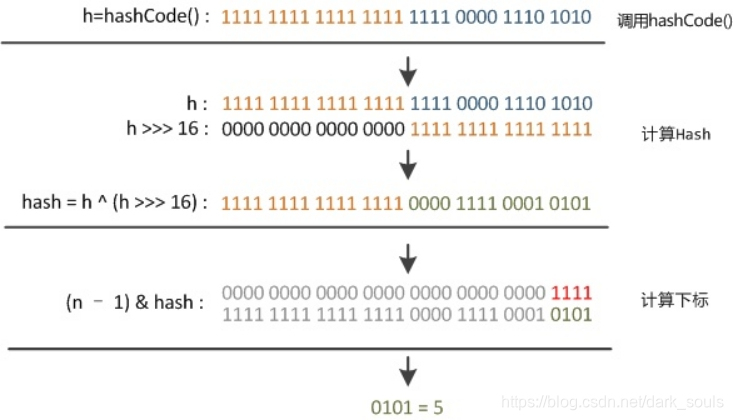
這裡用&運算的原理:n一定是2的次方數(由擴容機制決定),n-1的二進位表示則全為1,而&運算的方式是雙方為1結果才為1,那麼不管hash有多大,結果都取決於n-1的這幾位,大於n-1的那部分全補為0,則不可能越界。
2、HashMap是怎麼形成環形鏈表的(即為什麼不是線程安全)?(1.7中的問題)
在多線程情況下進行擴容容易形成環形鏈表,關鍵點在於resieze()方法中的transfer()方法。
在單線程下代碼執行過程:
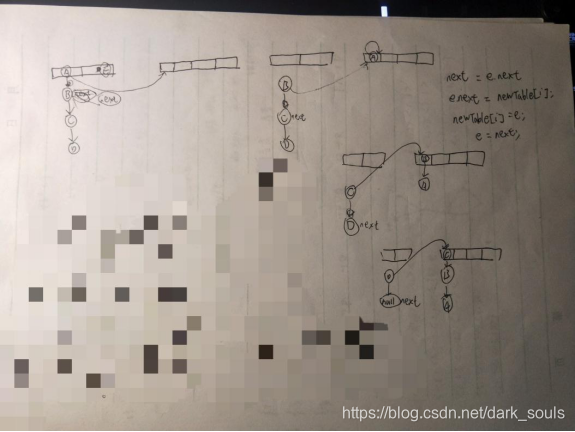
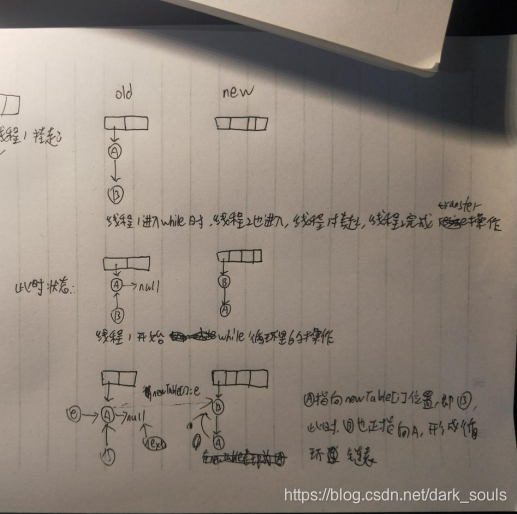
在多線程下代碼執行過程:
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-FNLaBmyb-1579436677465)(file:///C:\Users\李正陽\AppData\Local\Temp\ksohtml17192\wps3.png)]
當一個線程執行完Rehash完之後另一個再在舊map中Rehash,由於鏈表已經逆序,所以next會指回去,再進行Rehash就會形成環形鏈表
3、JDK1.7和1.8的HashMap不同點?
(1) JDK1.7使用的是頭插法,1.8之後是尾插法。其原因在於1.7是用單鏈表進行的縱向延伸,當採用頭插法能提高插入的效率(因為加到尾部還需要遍歷鏈表),但是容易出現逆序和環形鏈表死迴圈的問題。在1.8之後是因為加入了紅黑樹使用尾插法(尾插法要遍歷鏈表,順便判斷鏈表長度是否大於8),能夠避免逆序和鏈表死迴圈問題。紅黑樹能提高查找效率,比鏈表的查找效率高。
(2) 擴容後數據儲存的計算方式不一樣
JDK1.7:直接用hash值和需要擴容的二進位數進行&(這裡就是為什麼擴容的時候為啥一定必須是2的多少次冪的原因所在,因為如果只有2的n次冪的情況時最後一位二進位數才一定是1,這樣能最大程度減少hash碰撞)(hash值 & length-1)。
JDK1.8:直接用了JDK1.7的時候計算的規律,也就是擴容前的原始位置+擴容的大小值=JDK1.8的計算方式,而不再是JDK1.7的那種異或的方法。但是這種方式就相當於只需要判斷Hash值的新增參與運算的位是0還是1就直接迅速計算出了擴容後的儲存方式。(table變為2倍,則左邊增加一位1,和Hash值進行與操作即可)
(3) JDK1.7使用的是數組+單鏈表的數據結構。JDK1.8及以後使用的是數組+鏈表+紅黑樹的數據結構(當鏈表長度到達8的時候,也就是預設閾值,會自動擴容把鏈表轉化成紅黑樹的數據結構)
4、HashMap和HashTable的區別?
(1) HashMap是非線程安全的,並且可以儲存NULL。HashTbale是線程安全(即synchronized),但不能存儲NULL。
(2) HashMap利用HashCode重新計算Hash值,HashTbale直接使用key的HashCode(),再取模算下標。
(3) 內部實現使用的數組初始化和擴容方式不同。HashTable在不指定容量的情況下的預設容量為11,而HashMap為16,Hashtable不要求底層數組的容量一定要為2的整數次冪,而HashMap則要求一定為2的整數次冪。Hashtable擴容時,將容量變為原來的2倍加1,而HashMap擴容時,將容量變為原來的2倍。
5、ConCurrentHashMap?
核心數據如 value ,以及鏈表都是 volatile 修飾的,保證了獲取時的可見性。
為什麼載入因數是0.75
在HashMap中,預設創建的數組長度是16,也就是哈希桶個數為16,當添加key-value的時候,會先計算出他們的哈希值(h = hash),然後用return h & (length-1)就可以算出一個數組下標,這個數組下標就是鍵值對應該存放的位置。
但是,當數據較多的時候,不同鍵值對算出來的hash值相同,而導致最終存放的位置相同,這就是hash衝突,當出現hash衝突的時候,該位置的數據會轉變成鏈表的形式存儲,但是我們知道,數組的存儲空間是連續的,所以可以直接使用下標索引來查取,修改,刪除數據等操作,而且效率很高。而鏈表的存儲空間不是連續的,所以不能使用下標 索引,對每一個數據的操作都要進行從頭到尾的遍歷,這樣會使效率變得很低,特別是當鏈表長度較大的時候。為了防止鏈表長度較大,需要對數組進行動態擴容。
數組擴容需要申請新的記憶體空間,然後把之前的數據進行遷移,擴容頻繁,需要耗費較多時間,效率降低,如果在使用完一半的時候擴容,空間利用率就很低,如果等快滿了再進行擴容,hash衝突的概率增大!!那麼什麼時候開始擴容呢???
為了平衡空間利用率和hash衝突(效率),設置了一個載入因數(loadFactor),並且設置一個擴容臨界值(threshold = DEFAULT_INITIAL_CAPACITY * loadFactor),就是說當使用了16*0.75=12個數組以後,就會進行擴容,且變為原來的兩倍
在理想情況下,使用隨機哈希嗎,節點出現的頻率在hash桶中遵循泊松分佈,同時給出了桶中元素的個數和概率的對照表。
從上表可以看出當桶中元素到達8個的時候,概率已經變得非常小,也就是說用0.75作為負載因數,每個碰撞位置的鏈表長度超過8個是幾乎不可能的。
hash容器指定初始容量儘量為2的冪次方。
HashMap負載因數為0.75是空間和時間成本的一種折中。
HashMap構造函數:
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and the default load factor (0.75).
* @param initialCapacity the initial capacity.
* @throws IllegalArgumentException if the initial capacity is negative.
*
* 構造函數,設置基本的載入因數為0.75,意思是當一個 * 表的長度超過
* 臨界值就會再散列然後放回容器,這是十分耗時間的。
* 這個臨界值由負載因數和容量大小來決定,並且我們可以 * 手動初始化這個值
*
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
用戶輸入的容量初始值和負載因數後賦值檢查
public HashMap(int initialCapacity, float loadFactor) {
//初始化數組預設值小於0直接拋出
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//大於最大值就直接預設為最大值
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//負載因數小於0, Float.isNaN或者輸入的不是一個數字拋出異常
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
//賦值操作
this.loadFactor = loadFactor;
//確保你賦值雖然不是2的k次方,也會輸出2的k次方
this.threshold = tableSizeFor(initialCapacity);
}HashMap數組預設的值
數組的初始預設值:
/** * * 數組的預設初始值為16 */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16HashMap的最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;為什麼最大容量是這麼大?
int 是32為整數,四個位元組,負數為1
1 << 30 = 1073741824
1 << 31 = -2147483648
1 << 32 = 1
1 << 33 = 2
1 << -1 = -2147483648首位為符號位,正數是0,負數為1
31位存儲的是int型的補碼,所以最大隻能30位
如果我要存的值大於2^30如何處理
有一個resize()方法,這個方法的作用就是當使用的容量到達threshold容量的時候擴容
//但是如果最大容量大於預設的最大容量,會使threshold擴充為 Integer.MAX_VALUE if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; }threshold
int threshold;threshold = 初始容量 * 載入因數相當於擴容的限制值,相當於實際使用量
可以擴充到Integer.MAX_VALUE,還是為了能繼續存儲,因為到2 << 30 就會溢出。
表明不進行擴容了
所以說HashMap的總容量自然是MAXIMUM_CAPACITY
同時這個值沒有在創建的時候初始化,而是在put方法中初始化了。
table
transient Node<K,V>[] table;是一個數組單鏈表結構
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next;
tableSizeFor(int cap)
初始化容量,找到離輸入最近2的冪,因為HashMap要求容量必須是2的冪。
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}int n = cap - 1是為了防止cap已經是2的冪了,一下舉一個例子:
cap = 11
n |= >>> 1:
0000 1011 | 0000 0101 = 0000 1111
n |= >>> 2;
0000 1111 | 0000 0011 = 0000 1111
繼續向下推,也是一樣結果
如果最後值為32個1自然取到最大值MAXIMUM_CAPACITY,如果不是就給n+1,那麼此時n = 16
為什麼HashMap的容量一定是2的冪
- 1.奇數不行的解釋很能被接受,在計算hash的時候,確定落在數組的位置的時候,計算方法是(n - 1) & hash ,奇數n-1為偶數,偶數2進位的結尾都是0,經過&運算末尾都是0,會 增加hash衝突。
- 2.為啥要是2的冪,不能是2的倍數麽,比如6,10? -
- 2.1 hashmap 結構是數組,每個數組裡面的結構是node(鏈表或紅黑樹),正常情況下,如果你想放數據到不同的位置,肯定會想到取餘數確定放在那個數據里, 計算公式: hash % n,這個是十進位計算。在電腦中, (n - 1) & hash,當n為2次冪時,會滿足一個公式:(n - 1) & hash = hash % n,計算更加高效。
- 2.2 只有是2的冪數的數字經過n-1之後,二進位肯定是 ...11111111 這樣的格式,這種格式計算的位置的時候,完全是由產生的hash值類決定,而不受n-1 影響。你可能會想,受影響不是更好麽,又計算了一下 ,hash衝突可能更低了,這裡要考慮到擴容了,2的冪次方*2,在二進位中比如4和8,代表2的2次方和3次方,他們的2進位結構相似,比如4和8 00000100 0000 1000 只是高位向前移了一位,這樣擴容的時候,只需要判斷高位hash,移動到之前位置的倍數就可以了,免去了重新計算位置的運算。
- 取決於操作系統,一般操作系統申請記憶體之列都是2的冪,因為這樣可以有效避免內部碎片
- 會增加hash衝突的概率,詳情看後面為什麼不使用(n - 1) & hash
put方法
put函數不是具體實現,主要是為了方便用戶,就像工廠方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}調用的putVal函數
putVal(hash(key), key, value, false, true);
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) 一共有五個參數,第一個是插入元素的key的hash值,第二個是key本身,第三個是value,onlyIfAbsent true 代表映射存在不替換原值,evict 如果位false就代表HahMap代表正處於創建階段
putVal方法中,衝突之後判斷是不是處於數組的第一位
//確定是p這個位置hash值相同,並且key的值也相同
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//臨時結點e = p
e = p;定理:
equal objects must have equal hash codes.
首先:java.lang.Object.hashCode() 是三條約定是
1、多次運行 hashCode(),其值必須總是一致的(前提:1、 equals() 中用到的信息沒發生變化 2、在同一次 execution 中)
2、obj1.equals(obj2) == true,則必須 obj1.hashCode() == obj1.hashCode() 總是 true
3、obj1.equals(obj2) == false,則 obj1.hashCode() == obj2.hashCode() 最好 false 這是因為 HashMap.containsKey(),HashMap.put() 時
a:由於 hash 不同,則直接就不嘗試了(好。這樣效率高啊)
b:“兩把刷子程式員” 把 hash 弄成相同的(equals()不同,hashCode()相同),還得向下嘗試 equals() (不好)
情況一:
出現hash衝突,同時和數組指定位置第一個元素是一樣的
代碼節選:
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) //臨時結點e = p e = p; .............................................. //如果是第一種情況就,e的值位數組中第一個 if (e != null) { // existing mapping for key //保存結點e中的值 V oldValue = e.value; //如果oldValue(現在在數組中的結點值)或者onlyIfAbsent的值為false if (!onlyIfAbsent || oldValue == null) //覆蓋現有結點的值 e.value = value; //給LinkedHashMap預留的方法位 afterNodeAccess(e); //返回舊的值 return oldValue; }情況二:發現插入位置已經是紅黑樹了,返回紅黑樹的結點
//第二種情況如果是紅黑樹就按照紅黑樹的插入結點的方式 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); ............................................... //如果是第一種情況就,e的值位數組中第一個,第三種情況也要執行接下來的代碼,第二種情況也會執行 if (e != null) { // existing mapping for key //保存結點e中的值 V oldValue = e.value; //如果oldValue(現在在數組中的結點值)或者onlyIfAbsent的值為false if (!onlyIfAbsent || oldValue == null) //覆蓋現有結點的值 e.value = value; //給LinkedHashMap預留的方法位 afterNodeAccess(e); //返回舊的值 return oldValue; }情況3:雖然有衝突但是 不是第一個,遍曆數組之後,找到就替換,沒找到就插入,插入之後大於8執行桶的樹型化
else {
//衝突的第三種情況,不是第一個久開始遍歷
for (int binCount = 0; ; ++binCount) {
//如果已經到達了鏈表的尾端
if ((e = p.next) == null) {
//鏈表的末端插入當前需要插入的值
p.next = newNode(hash, key, value, null);
//如果鏈表長度大於等於7,因為是從0開始的,所以是八個長度
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//就將這個位置的鏈表紅黑樹化,主要是為了提高後續鏈表的查找效率
treeifyBin(tab, hash);
//自然到達鏈尾末端要結束迴圈
break;
}
//如果在鏈表中找到了與插入相同的元素就直接結束迴圈,然後執行後面替換
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
....................................................
//如果是第一種情況就,e的值位數組中第一個,第三種情況也要執行接下來的代碼,第二種情況也會執行
if (e != null) { // existing mapping for key
//保存結點e中的值
V oldValue = e.value;
//如果oldValue(現在在數組中的結點值)或者onlyIfAbsent的值為false
if (!onlyIfAbsent || oldValue == null)
//覆蓋現有結點的值
e.value = value;
//給LinkedHashMap預留的方法位
afterNodeAccess(e);
//返回舊的值
return oldValue;
}
put的流程:
①.判斷鍵值對數組table[i]是否為空或為null,否則執行resize()進行擴容;
②.根據鍵值key計算hash值得到插入的數組索引i,如果table[i]==null,直接新建節點添加,轉向⑥,如果table[i]不為空,轉向③;
③.判斷table[i]的首個元素是否和key一樣,如果相同直接覆蓋value,否則轉向④,這裡的相同指的是hashCode以及equals;
④.判斷table[i] 是否為treeNode,即table[i] 是否是紅黑樹,如果是紅黑樹,則直接在樹中插入鍵值對,否則轉向⑤;
⑤.遍歷table[i],判斷鏈表長度是否大於8,大於8的話把鏈表轉換為紅黑樹,在紅黑樹中執行插入操作,否則進行鏈表的插入操作;遍歷過程中若發現key已經存在直接覆蓋value即可;
⑥.插入成功後,判斷實際存在的鍵值對數量size是否超多了最大容量threshold,如果超過,進行擴容。
put方法的完整代碼:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//如果數組為空,由於創建的時候沒有初始化,看resize()做了什麼操作
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//檢查數組的這個位置是不是已經有了元素,p為這個位置的元素
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
//已經有了元素執行這部分內容
Node<K,V> e; K k;
//衝突的第一種情況確定是p這個位置第一個hash值相同,並且key的equals值也相同,如果hash值不相等就不用繼續運行了
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//臨時結點e = p
e = p;
//第二種情況如果是紅黑樹就按照紅黑樹的插入結點的方式
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//衝突的第三種情況,不是第一個久開始遍歷
for (int binCount = 0; ; ++binCount) {
//如果已經到達了鏈表的尾端
if ((e = p.next) == null) {
//鏈表的末端插入當前需要插入的值
p.next = newNode(hash, key, value, null);
//如果鏈表長度大於等於7,因為是從0開始的,所以是八個長度
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//就將這個位置的鏈表紅黑樹化,主要是為了提高後續鏈表的查找效率
treeifyBin(tab, hash);
//自然到達鏈尾末端要結束迴圈
break;
}
//如果在鏈表中找到了與插入相同的元素
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//如果是第一種情況就,e的值位數組中第一個,第三種情況也要執行接下來的代碼
if (e != null) { // existing mapping for key
//保存結點e中的值
V oldValue = e.value;
//如果oldValue(現在在數組中的結點值)或者onlyIfAbsent的值為false
if (!onlyIfAbsent || oldValue == null)
//覆蓋現有結點的值
e.value = value;
//給LinkedHashMap預留的方法位
afterNodeAccess(e);
//返回舊的值
return oldValue;
}
}
//修改計數增加
++modCount;
//添加結點之後檢查時候已經到達了擴容界限
if (++size > threshold)
//擴容
resize();
//為linkedHashMap服務
afterNodeInsertion(evict);
return null;
}resize()方法
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
//如果數組為空,就將0賦值給oldCap,不為空則返回,表的大小
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//之前的擴容界限,初始化的時候oldThr不會是0,因為有tableSizeFor()方法,確保oldThr至少是1
int oldThr = threshold;
//新的容量和新的擴容界限
int newCap, newThr = 0;
//如果是已經初始化的數組,並且數組裡面還有元素,就會直接進入這個分支
if (oldCap > 0) {
//但是如果最大容量大於預設的最大容量,會使threshold擴充為nteger.MAX_VALUE,表明不在進行擴容
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
//直接返回舊的表
return oldTab;
}
//新的容量為舊容量的2倍,這是向左移一位,由於本來就是2的冪次,向左移動自然是2倍,並且新容量要小於最大值,舊容量要大於初始值16
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
//新的限制也要變成原來的兩倍
newThr = oldThr << 1; // double threshold
}
//這個分支代表的是創建map使用的是帶參構造函數,初始容量無論是輸入多少,都會返回2 ^n,同時這個值存在threshold 中
else if (oldThr > 0) // initial capacity was placed in threshold
//給新的容量賦值
newCap = oldThr;
else { // zero initial threshold signifies using defaults
//這是第一次初始化新的容量,並且調用的是無參構造函數,新的newCap為16,新的擴容界限為12
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//這是第一次初始化擴容限制,新的擴容限製為16 * 0.75 = 12
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
//如果容量已經大於MAXIMUM_CAPACITY,就給賦值為Integer.MAX_VALUE
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//將新的擴容界限給threshold
threshold = newThr;
//初始化數組
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
//將newtable賦值給table
table = newTab;
//如果這個表不為空的時候
if (oldTab != null) {
//遍歷一遍表
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//如果j這個位置的元素不為null
if ((e = oldTab[j]) != null) {
//先賦值為null
oldTab[j] = null;
//如果e.next為null就代表的是數組之中有值,且只有一個,直接賦值就行
if (e.next == null)
//重新計算hash之後,向新表中直接插入e
newTab[e.hash & (newCap - 1)] = e;
//檢查是不是已經是紅黑樹,調用紅黑樹中的方法
else if (e instanceof TreeNode)
//做一個拆分
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
//保持單鏈表原來的順序
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
//為0走這個分支
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
//第一次進入這個迴圈一般會走這個分支如果不為0走這個分支
else {
if (hiTail == null)
//然後hiHead得到值,相當於初始化鏈表,頭節點和尾結點一樣
hiHead = e;
else
hiTail.next = e;
//hiTail也會得到值
hiTail = e;
}
} while ((e = next) != null);
//計算出hash和原容量為0才走這個分支
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
//當不為0時候走這一點,將新鏈錶鏈接到新的坐標底下
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
//放回新的數組
return newTab;
}當鏈表的結點數大於8,就將這個結點轉化為紅黑樹
擴容進行到最後,發現數組不為空,並且迴圈遍歷的時候發現這個位置不是單單數組中一個值,還有一個單鏈表這個時候為什麼要e.hash & oldCap?不應該是e.hash & newCap
do {
next = e.next;
if ((e.hash & oldCap) == 0) {這個是e.hash & oldCap != 0的情況舉個例子:
擴容之前的容量 :0001 0000
n - 1 0000 11111
新容量: 0010 0000
n - 1: 00001 1111
k1-hash: 0001 0100
與原容量& 0001 0000
newTab[j + oldCap] = hiHead;原下標: 0000 0100
原下標加原容量 0001 0100
K1-hash與新的n - 1& 0001 0100
這個結果和原下表加原容量的結果是一樣的
e.hash & oldCap 等於0的情況
K2-hash: 0000 0100
與原容量n-1& 0000 0100
計算出來:新下標和原下標是一樣的,下麵是計算與新容量n-1計算
K2-HASH : 0000 0100
n-1 0001 1111
& 0000 0100
與原容量n-1和新容量n-1&其實結果是一樣的
這些只是為了證明,擴容中,鏈表中的很多元素的新數組下標有兩種可能,一種是還在元素數組下標,還有一種就是元素組加舊的容量的位置
為什麼可以這樣,因為在兩種情況中,計算他們所處位置其實直接和新容量n-1&是一樣的,上面的兩個例子分別為兩種情況,也證明瞭這一點。
hash()方法
static final int hash(Object key) {
int h;
//如果輸入的鍵是null,hash就為0,否則計算hashcode
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}計算出hashcode的值然後和 h >>> 16位的值異或這個是為什麼?
(h = key.hashCode()) ^ (h >>> 16),為什麼需要異或?
例子:
原值1: 10010001 10010101 10110000 11110001
右移動16位: 00000000 00000000 10010001 10010101
異或: 10010001 10010101 00100001 01100100
進入put函數中比較代碼段
數組大小: 00000000 00000001 00000000 00000000
n - 1: 00000000 00000000 11111111 11111111
原值1與後: 00000000 00000000 10110000 11110001
異或後再與: 00000000 00000000 00100001 01100100
目前看不出什麼,再來看一個原值2與原值1只差第一位
原值2: 00010001 10010101 10110000 11110001
右移動16位: 00000000 00000000 00010001 10010101
異或: 00010001 10010101 10100001 01100100
原值2與後: 00000000 00000000 10110000 11110001
異或後再與: 00000000 00000000 10100001 01100100
可見如果不先異或直接與兩個數相差不大等情況下的,與之後的情況是一樣的,如果先進行異或就可以提高hash值得散列度,可以避免衝突。
為什麼使用(n - 1) & hash而不用 value % n
其實(n - 1) & hash 和 value % n 是相等的,但是需要n為2的冪,同時電腦更加習慣用 & 運算這種而不是這種取餘運算,可以加快電腦計算的速度。
舉個例子:(只有當n = 2的冪次的時候,才和value % n 相同
n = 16
0000 1111 n - 1
0000 0001 hash
-> 0000 0001
1 % 16 = 1
0000 1111
0000 0101
-> 0000 0101 = 8
n = 15
0000 1110 n -1
0000 0001 hash
-> 0000 0000
同時也會導致hash衝突增加
put方法中,如果產生衝突除了覆蓋或者不覆蓋還使用了afterNodeAccess
afterNodeAccess實現方法是LinkedHashMap類中的方法
LinkedHashMap和HashMap的區別看下一個問題
HashMap.afterNodeAccess()中說道,“是為LinkedHashMap留的後路”。如今行至於此,當觀賞一方。首先需要瞭解的是LinkedHashMap相比HashMap多了有序性,由雙向鏈表(before,after)實現。源碼出現了一些全局變數:
accessOrder:true:按訪問順序排序(LRU),false:按插入順序排序;
head、tail:存放鏈表首尾;
可見僅有accessOrder為true時,且訪問節點不等於尾節點時,該方法才有意義。通過before、after重定向,將新訪問節點鏈接為鏈表尾節點。
這些方法都是為了實現LinkedHashMap類的記錄的插入順序
LinkedHashMap和HashMap的區別
一般情況下,我們用的最多的是HashMap,在Map 中插入、刪除和定位元素,HashMap 是最好的選擇。但如果您要按自然順序或自定義順序遍歷鍵,那麼TreeMap會更好。如果需要輸出的順序和輸入的相同,那麼用LinkedHashMap 可以實現,它還可以按讀取順序來排列.
HashMap是一個最常用的Map,它根據鍵的hashCode值存儲數據,根據鍵可以直接獲取它的值,具有很快的訪問速度。HashMap最多只允許一條記錄的鍵為NULL,允許多條記錄的值為NULL。
HashMap不支持線程同步,即任一時刻可以有多個線程同時寫HashMap,可能會導致數據的不一致性。如果需要同步,可以用Collections的synchronizedMap方法使HashMap具有同步的能力。
Hashtable與HashMap類似,不同的是:它不允許記錄的鍵或者值為空;它支持線程的同步,即任一時刻只有一個線程能寫Hashtable,因此也導致了Hashtable在寫入時會比較慢。
LinkedHashMap保存了記錄的插入順序,在用Iterator遍歷LinkedHashMap時,先得到的記錄肯定是先插入的。
在遍歷的時候會比HashMap慢TreeMap能夠把它保存的記錄根據鍵排序,預設是按升序排序,也可以指定排序的比較器。當用Iterator遍歷TreeMap時,得到的記錄是排過序的。
put方法中的桶的樹型化擴充treeifyBin()
***TREEIFY_THRESHOLD***** = 8;
當鏈表長度大於此值時,將鏈表轉化為紅黑樹。
***UNTREEIFY_THRESHOLD***** = 6;
當紅黑樹小於此值時又會轉回鏈表
擴充的實際操作不是放在這裡
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//進行樹型化的閾值為64,如果小於64就沒必要樹化,會選擇先擴容
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
//進行擴容
resize();
//找到需要擴容的位置
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
//將鏈表結點轉為樹狀結點
TreeNode<K,V> p = replacementTreeNode(e, null);
//初始化hd,hd為鏈表的第一個
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
//tl在剛進入 = hd = p ,然後之後的作用為遍歷鏈表然後將他們鏈接起來
tl = p;
} while ((e = e.next) != null);
//hd為鏈表的頭節點,先將他賦值給表的固定位置,然後對hd這個鏈表進行樹化
if ((tab[index] = hd) != null)
//將這條鏈表樹化
hd.treeify(tab);
}
}treeify()方法是TreeNode結點內部的一個方法,實際作用才是將一條鏈表樹化
還未研究紅黑樹,暫且不做解析
remove方法
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}調用了removeNode這個方法,然後介紹一下這個方法的五個參數。
- @param hash hash for key
- @param key the key
- @param value the value to match if matchValue, else ignored
- @param matchValue if true only remove if value is equal
- @param movable if false do not move other nodes while removing
第一個是hash,自然是計算key的hash
第二個就是key值
第三個是value值
第四個是 是否匹配value,如果值為true,只刪除值相同的,預設為false
第五個為如果為false,在刪除的時候不移動其他結點,預設為true
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
//如果這個數組已經初始化了,並且這個位置不為空
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
//檢查數組這個位置第一個是否為所要刪除的結點
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
//這個數組不止有一個元素
else if ((e = p.next) != null) {
//鏈表已經紅黑樹化,調用紅黑樹獲取結點的方法
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
//數組情況
else {
//迴圈遍歷
do {
//找到需要刪除的值就賦值,然後結束迴圈
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
//p為需要刪除元素的前一個元素
p = e;
} while ((e = e.next) != null);
}
}
//在hash表中找到了node,並且node不為空,並且值相同
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
//結點是樹形結點調用紅黑樹刪除方法
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
//node和p結點一樣的情況,只有在刪除鏈表第一個結點的情況下
else if (node == p)
tab[index] = node.next;
//直接將p.next指向需要刪除的結點的下一個
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}get方法
public V get(Object key) {
Node<K,V> e;
//找到了就直接返回value,沒找到就直接返回null
return (e = getNode(hash(key), key)) == null ? null : e.value;
}具體操作是在getNode中
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//前一個條件是表已經初始化了
if ((tab = table) != null && (n = tab.length) > 0 &&
//並且這個位置的數組鏈表不為null
(first = tab[(n - 1) & hash]) != null) {
//先檢查第一個結點是否一樣,一樣就直接返回
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//檢查如果是一個鏈表,進入這個分支
if ((e = first.next) != null) {
//如果檢查出已經是樹結點了,就調用樹結點的獲取結點方法
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//檢查鏈表中有沒有相等的key,找到就直接返回e
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
//找不到就返回null
return null;
}這部分沒有什麼好說的,紅黑樹部分後續再講解。
後記:
前五個問題,感謝我的同學ZR,剩下中有些解釋是我網上找的資料,因為寫的好就直接摘錄了。其餘均為自己的分析和理解,有錯希望指出。


