
消息中間件 消息的可靠性傳遞 前言 消息中間件的可靠性消息傳遞,是消息中間件領域非常重要的方案落實問題(在這之前的MQ理論,MQ選型是抽象層次更高的問題,這裡不談)。 並且這個問題與日常開發是存在較大的關聯的。可以這麼說,凡是使用了MQ的,機會都要考慮這個問題。當然也有一些原始數據採集,日誌數據收集 ...
消息中間件-消息的可靠性傳遞
前言
消息中間件的可靠性消息傳遞,是消息中間件領域非常重要的方案落實問題(在這之前的MQ理論,MQ選型是抽象層次更高的問題,這裡不談)。
並且這個問題與日常開發是存在較大的關聯的。可以這麼說,凡是使用了MQ的,機會都要考慮這個問題。當然也有一些原始數據採集,日誌數據收集等應用場景對此沒有過高要求。但是大多數的業務場景,對此還是有著較高要求的。比如訂單系統,支付系統,消息系統等,你弄丟一條消息,嘿嘿。
網上對於這方面的博客,大多從單一MQ,或者乾脆就是在論述MQ。我不喜歡這樣的論述,這樣的論述太過局限,也過於拖沓。
這次,主要從理論方面論證消息的可靠性傳遞的落實。具體技術,都是依據這些理論的,具體實現都差不多。不過為了便於大家理解,我在文中會以RabbitMq,Kafka這兩個主流MQ稍作舉例。
在日常開發中,我更傾向於在具體開發前,先整理思路,走通理論,再開始編碼。畢竟,如果連理論都走不同,還談什麼編碼。
另外,我按照消息可靠性層次逐步推進,形成相應的目錄,希望大家喜歡(因為我認為,相較網上這方面現有博客的目錄,這樣的目錄更合理,更人性化)。
概述
這裡簡單談一些有關消息可靠性傳遞的理論。
消息傳遞次數
消息在消息系統(生產者+MQ+消費者),其消費的次數,無非一下三種情況:
- 最多一次
- 最少一次
- 不多不少一次
消息可靠性層次
這也代表著消息系統的消息可靠性的三個層次:
- 最多一次:上游服務的消息發出了,至於下游能不能收到服務,就不管了。結果就是下游服務,可能根本就沒有接收到消息。
- 最少一次:上游服務的消息發出了,並通過某些機制,確保下游服務一定收到了該消息。但是收到了幾次,就不管了。結果就是下游服務,可能多次收到同一條消息。
- 不多不少一次:上游服務的消息發出了,並確保下游服務一定收到了消息。下游服務通過某些機制,確保多次收到該消息與單次收到該消息,對其系統狀態的影響是相同的。
方案落實
實現上述三個層次,需要逐步從三個方面考慮:
- 最多一次:會用消息隊列即可,只要確保消息的連通性即可
- 最少一次:通過MQ提供的確認機制,確保消息的傳遞
- 不多不少一次:通過外部應用程式,確保消息的單次消費與多次消費對系統狀態影響是一致的
上述三個層次,對系統的性能損耗,系統複雜度等都是逐步上升的。
當然,我們首先,需要瞭解這三個層次分別如何實現。
再在實際開發中,根據需要,靈活選取合適方案。
最多一次的消息傳遞
這個方案是最簡單的,只要確保消息系統的正確運作,以及系統的連通性即可。在正常情況下,可以保證絕大部分數據的可靠性傳遞。但是仍舊存在極小數據的丟失,並且數據的丟失會因為消息隊列的選擇,以及消息併發量,而受到影響。
優點
- 實現簡單。只要搭建對應的MQ伺服器,寫出對應的生產者與消費者,以及相應配置,即可正常工作。
缺點
- 無法保證數據的可靠性,會存在一定的數據丟失情況,尤其是在併發量較大時
實際應用
可以應用於日誌上傳這樣對消息可靠性要求低的應用場景。
總結
如果數據量不大的情況下,推薦使用RabbitMQ,其消息可靠性在地數據量下,是最可靠的。但是在達到萬級併發時,會存在消息丟失,丟失的比例可以達到千分之一。
如果數據量較大的情況下,要麼採用集群。要麼就採用Kafk(Kafka可支持十萬級併發)
一般來說,這種消息可靠性多見於項目初建,或類似日誌採集,原始數據採集這樣的特定場景。
最少一次的消息傳遞
這個方案開始利用MQ提供的特定機制,來提高消息傳遞的可靠性。
優點
- 不錯的消息可靠性。確保不會出現消息丟失的情況
- 實現並不複雜。只需要合理使用MQ的API,設置合理參數(如重試次數)即可
缺點
- 會出現消息重覆消費的情況
- 參數的設置需要合理。如重試次數,一般設置為5次,也可根據情況,進行調整
- 資源占用的提升。如帶寬(每次消息成功生產,消費都需要返回一條數據進行確認)等
方案落實
該方案的實現組成,由以下三個方面構成:
- 消息的可靠生產
- 消息的可靠存儲
- 消息的可靠消費
通過以上三個方面的落實,確保可消息一定被下游服務消費。
消息的可靠生產
消息的可靠生產,是通過回調確認機制,確保消息一定被消息伺服器接收。
消息生產,發送給消息伺服器後,消息伺服器會返回一個確認信息,表示數據正常接收。
如果生產者在一定時間內沒有接收到確認信息,就會觸發重試機制,進行消息的重發。
如RabbitMq的comfirm機制,Kafka的acks機制等。
RabbitMq的confirm機制存在三個模式:
- 普通模式:channel.waitForConfirms()
- 批量模式:channel.waitForConfirmsOrDie()
- 非同步模式:channel.addConfirmListener()
這三個模式,看名稱就可以知道具體作用了。如果希望瞭解具體代碼落實,詳見RabbitMQ事務和Confirm發送方消息確認——深入解讀,其中確認機制寫得較為簡潔。
至於Kafka的acks機制,同樣存在三個模式:
- acks = 0 :不需要Kafka的任何Partition確認,即確認發送成功(這個之確保消息發送出去了,並不保證消息伺服器是否成功接收)
- acks = 1 :(預設)需要Kafka的Partition Leader確認,即被Kafka的一個Partition(Leader)接收。但是這樣依舊存在極小概率的消息丟失,即Partition Leader獲取了對應消息,並給了acks確認回覆。但是在其他Partition同步前,Partition Leader宕機,數據丟失。那麼這就造成了消息丟失。
- acks = all :需要Kafka對應ISR中的全部Partition確認,才確認消息發送成功(當然,這裡假定Kafka是多節點集群,如果只有一個分區,那就毫無意義了)。
說到這裡,簡單說一下,上述的操作可能造成消息的重覆生產。
最簡單的例子,消息成功發送,但是對應的消息確認信息由於網路波動而丟失。那麼生產者就會重覆發送該消息,所以消息伺服器接收到了兩條相同消息,故產生了消息的重覆生產。
另外,上述的重試,都是存在響應時長判斷(超出1min,就認為數據丟失),以及重試次數限制(超過5次,就不進行重試。否則,大量重試數據可能會拖垮整個服務)。
消息的可靠存儲
消息的可靠存儲,是確保消息在消息伺服器經過,或者說堆積時不會因為宕機,網路等狀況,丟失消息。
網上很多博客在論述消息的可靠性傳遞時,常常把這點遺漏。因為他們理所當然地認為消息隊列已經通過集群等實現了消息隊列服務的可用性,故消息的可靠性存儲也就實現了。
但是這裡存在兩個問題。第一,可靠性不等於可用性。第二,消息的可靠存儲,作為消息可靠性傳遞的一部分,是不可缺失的。
可用性:確保服務的可用。即對應的服務,可以提供服務。
可靠性:確保服務的正確。即對應的服務,提供的是正確的服務。
區別:我瀏覽淘寶,淘寶頁面打不開,這就涉及了可用性問題(可用性計算公式:可用時間/全部時長*100%)。而我瀏覽淘寶,查詢訂單,給我顯示的是別人的訂單,這就涉及了可靠性問題。
另外這裡再糾正一點,可靠性並不依賴於可用性。即使我打不開淘寶頁面,我也不能說淘寶提供訂單查詢就有問題(只是如果沒有了可用性,談論可靠性是非常沒有意義的。畢竟都用不了了,誰還關心其內容是否正確呢,都看不到)
消息隊列的可用性,是通過多個節點構成集群,避免單點故障,從而提升可用性。
消息隊列的可靠存儲,是通過備份實現(這裡不糾結備份如何確保正確)的。如RabbitMq集群的MemNode與DiskNode,又或者Kafka的replication機制等。
消息的可靠消費
消息的可靠消費,就是確保消息被消費者獲取,並被成功消費。避免由於消息丟失,或者消費者宕機而造成消息消費不成功,最終造成消息的丟失(因為RabbitMq伺服器在認為消息被成功消費後,將對應數據刪除或標記為“已消費”)。
至於消息的可靠消費,核心理念還是重試,重試,再重試。不過具體的實現就八仙過海,各顯神通了。
這裡分別說一下RabbitMq,Kafka,Rocket三者對於可靠消費的處理:
RabbitMq
提供ack機制。預設是auto,直接在拿到消息時,直接ack。確保了消息到達了消費者,但是無法解決消費者消費失敗這樣的問題。
實際開發中,為了確保消息的可靠消費,一般會設置為munal,只有在程式正確運行後,才會調用對應api,表示消息正確消費。
Kafka
由於Kafka的消息是落地到硬碟文件的,而且Kafka的消息分發方式是pull的,所以消息的拉取是通過offset機制去確認對應位置消息的。
當然,Kafka的offset預設是自動提交的(可通過nable_auto_commit與auto_commit_interval_ms控制)。
所以消費者調用服務失敗等原因,可以通過手動offset提交,來實現對數據的重覆消費(甚至是歷史數據的消費),也就可以在消費失敗時對同一消息進行再消費。
如果是消費者宕機等原因,由於Kafka伺服器沒有收到對應的offset提交,所以認為那條消息沒有被消費成功,故返回的依舊是那條消息。
RocketMq
其實RocketMq的處理有些類似Kafka確認機制+RabbitMq死信隊列的感覺。
首先,消費者從RocketMq拉取消息,如果成功消費,就返回確認消息。
如果未成功消費,就嘗試重新消費。
嘗試消費一定次數後(如5次),就會將該消息發送之RocketMq中的重試隊列。
如果遇到消費者宕機的情況,RocketMq會認為該消息未成功消費,會被其他消費者繼續消費。
其實在RabbitMq的可靠性消費時,我們也會將多次消費失敗的數據保存下來,便於後期修複等。不過保存的方式由很多種,日誌,資料庫,消息隊列等。而RocketMq則給出了具體的落實方案。
上述的操作,可能造成消息的重覆消費。
最簡單的例子,消息成功被消費者消費,但是消費者還沒來得及發送確認信息,就宕機了。
消息隊列由於沒有收到確認消息,認為該條消息尚未被消息,就將該消息交由其他消費者繼續消費。
不多不少一次的消息傳遞
這個方案,就是通過MQ以外的應用程式,來進行擴展,最終達到消息準確消費的目的。
那麼為什麼不將這個功能,囊括在MQ中呢?
個人認為有四個方面的考慮:
- 消息中間件,應該明確其功能域,而消息生產與消息消費往往涉及業務,所以避免與業務的耦合。所以消息中間件只完善了可靠存儲。
- 準確消費,往往涉及MQ以外的部分,需要其他部分的配合。就類似與XA介面一樣。這樣會帶來編碼的約束,系統的耦合性等。
- 準確消費的實現可以通過一個工具,模塊去實現,但是不該硬編碼。畢竟現有的處理方案並不一定就是最優解(尤其是在調控中心,TCC框架展現的現在)。
- 性能影響。為了一個不通用的功能,會帶來消息中間件的性能大幅下降
優勢
- 確保消息被準確消費(不多不少一次)
缺點
- 實現複雜(生產者與消費者都需要建立對應資料庫)
- 需要建立對應規範(但是通用規範確定後,實現就會變得快速)
- 資源占用的提升。如帶寬(每次消息成功生產,消費都需要返回一條數據進行確認)等
存在的問題
消息存儲部分的準確存儲,不該我們來操心,所以只闡述消息生產與消息消費兩個部分。
消息的重覆生產
- 消息發給了消息隊列伺服器,消息隊列伺服器的確認信息由於網路波動等,沒有及時到達生產者
- 消息發送給了消息隊列伺服器,生產者在接收消息前,宕機
- 消息發送給了消息隊列伺服器,生產者在接收消息後,還沒來得及進行確認邏輯,宕機
綜上來看,就是消息發出後,到生產者消息確認信息的處理之間,出現各種意外,導致重覆生產。
消息的重覆消費
- 消息已經被消費,消費者還沒來得及發送確認信息,就宕機了
- 消息已經被消費,消費者發出確認信息,確認信息由於網路波動等,沒有及時到達消息隊列伺服器
- 消息已經被消費,消費者發出確認信息,消息隊列伺服器對應實例在接收到確認信息前,宕機
- 消息已經被消費,消費者發出確認信息,消息隊列伺服器接受到了確認信息,還沒來得及進行確認邏輯,宕機
綜上來看,就是消息已經被消費後,到消息隊列伺服器進行確認消息處理之間,出現各種意外,導致重覆消費。
解決方案
解決方案:messageId+冪等
準確來說,解決方案的核心是冪等,而messageId是作為輔助手段的。
冪等
冪等,簡單說明一下,就是多次操作與單次操作對系統狀態的影響是一致的。
如
i = 1; 就是冪等操作,因為無論進行幾次,i的值都沒有變化。
而
i++;則不是冪等操作,因為i的值與執行次數息息相關。
故通過冪等操作來確保同一條消息,不被執行多次。
messageId
但是,消費者如何確定是否為同一條消息呢?
有的消息體存在唯一性欄位,如orderId等。但有的消息並沒有這樣的唯一性欄位。
所以需要一個專門的欄位,來表示唯一性,並且與業務消息解耦。這就是messageId。
既可以採用消息體的唯一性欄位(可以是單一欄位,也可以是組合欄位),也可以通過特定方式生成對應標識(分散式系統,需要註意不同實例生產者產生相同標識的可能,詳見分散式全局唯一ID的實現)。
具體的生成情況,就不在這裡贅述了。
方案落實
先來一張大圖(這種事情,圖片展示最直觀了),展示一下流程:
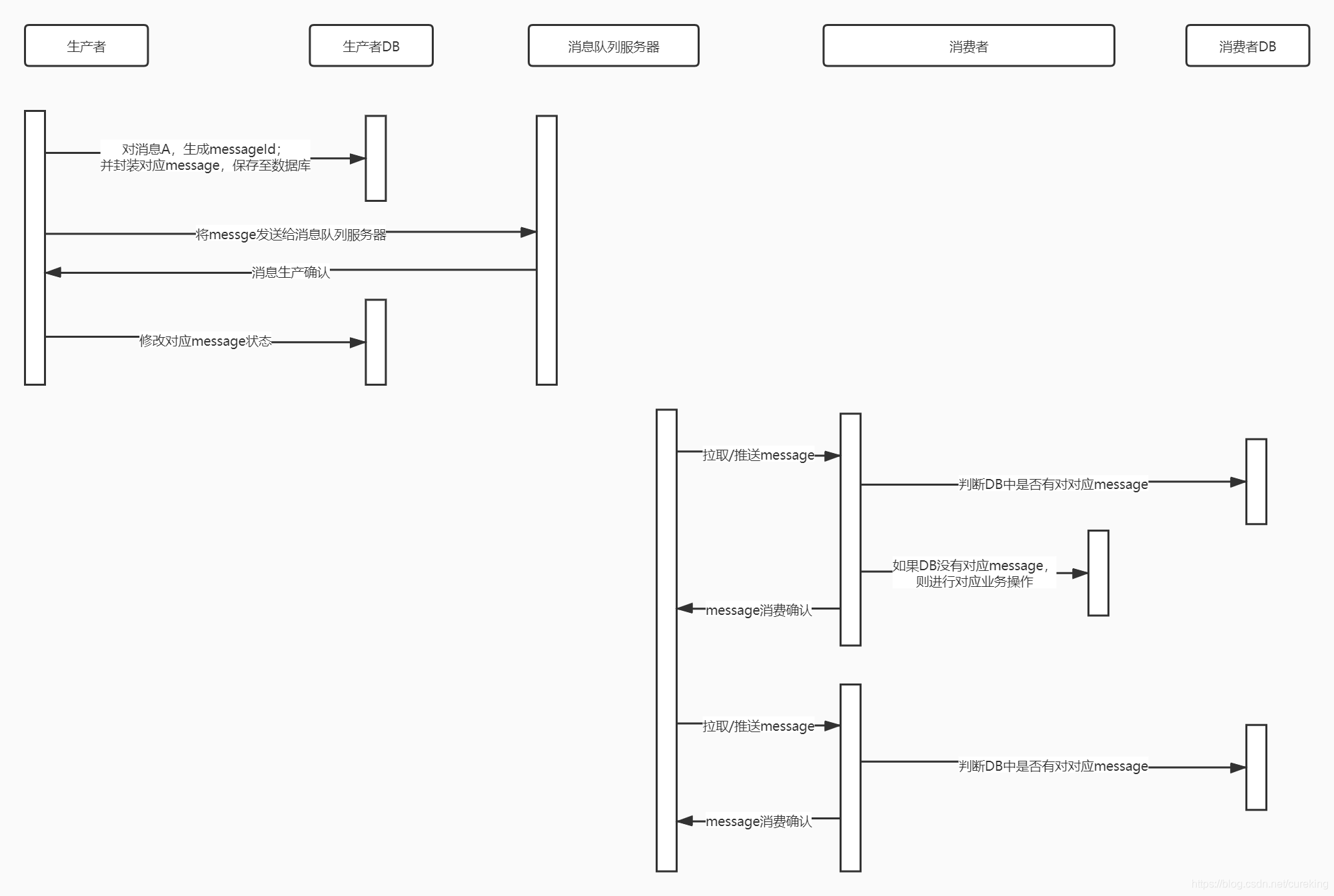
(圖片是絕對清晰的。看不清圖片的朋友,請將圖片在新頁面打開,或下載。說實話,來到新公司,首先提升的就是畫圖能力。囧)
簡單說一下流程,大家可以對照著上圖,看一下:
生產者到消息中間件伺服器
- 生產者根據需要發送的消息,生成對應messageId。並封裝對應message至生產者資料庫(該操作應該利用事務性,確保生產者事件處理與message保存至資料庫的原子性),同時標註message狀態為sending(發送中狀態)
- 將對應message發送給消息隊列伺服器
- 如果沒有收到生產確認信息,則重新發送message(如果這個時候遇到生產者實例宕機,也不用擔心。因為後續會有補償程式,進行補償重發操作)
- 當收到消息中間件伺服器的消息生產確認消息(即確定消息已經達到消息中間件伺服器),將資料庫中對應message的狀態修改為sended(已發送狀態)
上述中提到的補償機制,其實是類似事務中的一個操作。通過一個定時任務,定時巡檢資料庫處於sending狀態的message,並通過生產者極性發送(所以message一般都保存source,target等信息)。
之所以會有sending狀態的message,就是因為存在生產者消息發送出去了,還沒收到生產確認信息,結果生產者實例自己宕機的情況。
至於補償機制的定時任務,是一個非常簡單的實現,這裡就不再贅述了。
消息中間件到消費者
這裡進行的操作是針對非冪等的操作。
如果是冪等操作,則可以直接進行。畢竟多次執行與單次執行對資料庫的影響是一致的。
但是註意冪等操作在部分場景下無效的問題(時間影響上),如“餘額 = 1k”的操作對於資料庫而言是冪等的,但是在兩次“餘額 = 1k”操作間,有一個“餘額 = 2k”的操作,則會發生問題(丟失了“餘額 = 2k”操作)。當然,這種類似ABA問題,完全可以引入版本號,來進行解決。
綜上,還是推薦採用以下解決方法,流程較為簡單:
- 消費者獲取數據
- 消費者判斷資料庫是否有對應message
- 如果存在對應message,則放棄執行(因為這是一個重覆操作)
- 如果不存在,則進行相關消息處理。並通過事務控制,在消費者資料庫中添加message(確保消息的處理與資料庫添加message是原子操作)
至此,消息的準確傳遞就完成了。
總結
消息可靠性傳遞的發展過程,也體現了人們對消息中間件功能的一步步追求,更是體現了工程師們解決問題的思路。
很多時候,我們會遇到很多問題,甚至令人感到雜亂不堪,無從下手。這個時候,最好的辦法就是靜下心來,對它們進行劃分(按照重要程度,緊迫度,實現難度),再進行一個長期規劃,一步步來解決。往往這個時候,動動筆,在筆記上列下清單,會是一個不錯的辦法。
其中消息的準確傳遞,涉及一些事務相關的內容。也許有人已經聯想到,消息隊列是否可以作為分散式事務的一種手段呢?我會在之後的博客中,來闡述分散式事務這一重要主題。
如果有什麼問題或想法,可以私信或@我。
願與諸君共進步。


