
[TOC] 項目地址:https://github.com/gatsbyd/melon 介紹 開發服務端程式的一個基本任務是處理併發連接,現在服務端網路編程處理併發連接主要有兩種方式: 1. 當“線程”很廉價時,一臺機器上可以創建遠高於CPU數目的“線程”。這時一個線程只處理一個TCP連接,通常使用 ...
目錄
項目地址:https://github.com/gatsbyd/melon
介紹
開發服務端程式的一個基本任務是處理併發連接,現在服務端網路編程處理併發連接主要有兩種方式:
- 當“線程”很廉價時,一臺機器上可以創建遠高於CPU數目的“線程”。這時一個線程只處理一個TCP連接,通常使用阻塞IO。例如Go goroutine。這裡的“線程”由語言的runtime自行調度。
- 當線程很寶貴時,一臺機器上只能創建與CPU數目相當的線程。這時一個線程要處理多個TCP連接上的IO,通常使用非阻塞IO和IO multiplexing。C++編程主要採用這種方式。
線上程很寶貴的情況下,常見的伺服器編程模型有如下幾種:
- 每個請求創建一個線程,使用阻塞式IO操作(或者叫thread per connection)。這種模型的優點是可以使用阻塞操作,缺點是伸縮性不強,每台機器能創建的線程是有限的,32位的機器應該不超過400個。
- 非阻塞IO+IO多路復用(或者叫one loop per thread或者Reactor)+ 線程池。
melon是基於Reactor模式的Linux C++網路服務框架,集合了上述兩種方式,實現了協程的概念,對一些函數進行了hook,所以可以像操作阻塞IO一樣進行編程。
使用
在工程主目錄下新建build目錄,進入build目錄,
cmake ..
make all編譯完成後,example和test中的可執行程式分別位於build目錄下的example和test中。
以echo服務端為例,
void handleClient(TcpConnection::Ptr conn){
conn->setTcpNoDelay(true);
Buffer::Ptr buffer = std::make_shared<Buffer>();
while (conn->read(buffer) > 0) {
conn->write(buffer);
}
conn->close();
}
int main(int args, char* argv[]) {
if (args != 2) {
printf("Usage: %s threads\n", argv[0]);
return 0;
}
Logger::setLogLevel(LogLevel::INFO);
Singleton<Logger>::getInstance()->addAppender("console", LogAppender::ptr(new ConsoleAppender()));
IpAddress listen_addr(5000);
int threads_num = std::atoi(argv[1]);
Scheduler scheduler(threads_num);
scheduler.startAsync();
TcpServer server(listen_addr, &scheduler);
server.setConnectionHandler(handleClient);
server.start();
scheduler.wait();
return 0;
}只需要為TcpServer設置連接處理函數,在連接處理函數中,參數TcpConnection::Ptr conn代表此次連接,可以像阻塞IO一樣進行讀寫,如果發生阻塞,當前協程會被切出去,直到可讀或者可寫事件到來時,該協程會被重新執行。
性能
硬體環境:Intel Core i7-8550U CPU 1.80GHz,8核,8G RAM
軟體環境:操作系統為Ubuntu 16.04.2 LTS,g++版本5.4.0
測試對象:asio 1.14.0, melon 0.1.0
測試方法:
根據asio的測試方法,用echo協議來測試。客戶端和服務端建立連接,客戶端向服務端發送一些數據,服務端收到後將數據原封不動地發回給客戶端,客戶端收到後再將數據發給服務端,直到一方斷開連接位置。
melon的測試代碼在test/TcpClient_test.cpp和test/TcpServer_test.cpp。
asio的測試代碼在/src/tests/performance目錄下的client.cpp和server.cpp。
測試1:客戶端和伺服器運行在同一臺機器上,均為單線程,測試併發數為1/10/100/1000/10000的吞吐量。
| 吞吐量(MiB/s) | 1 | 10 | 100 | 1000 |
|---|---|---|---|---|
| melon | 202 | 388 | 376 | 327 |
| asio | 251 | 541 | 489 | 436 |
測試2:客戶端和伺服器運行在同一臺機器上,均為開啟兩個線程,測試併發連接數100的吞吐量。
| 吞吐量(MiB/s) | 2個線程 |
|---|---|
| melon | 499 |
| asio | 587 |
從數據看目前melon的性能還不及asio,但是考慮到melon存在協程切換的成本和0.1.0版本沒有上epoll,協程切換也是用的ucontext,總體來說可以接受。
實現
日誌庫
需求
- 有多種日誌級別,DEBUG, INFO, WARN, ERROR, FATAL。
- 可以有多個目的地,比如文件,控制台,可以拓展。
- 日誌文件達到指定大小時自動roll。
- 時間戳精確到微秒。使用gettimeofday(2),在x86-64Linux上不會陷入內核。
- 線程安全。
- 寫日誌過程不能是同步的,否則會阻塞IO線程。
這是個典型的生產者-消費者問題。產生日誌的線程將日誌先存到緩衝區,日誌消費線程將緩衝區中的日誌寫到磁碟。要保證兩個線程的臨界區儘可能小。
總體結構如下
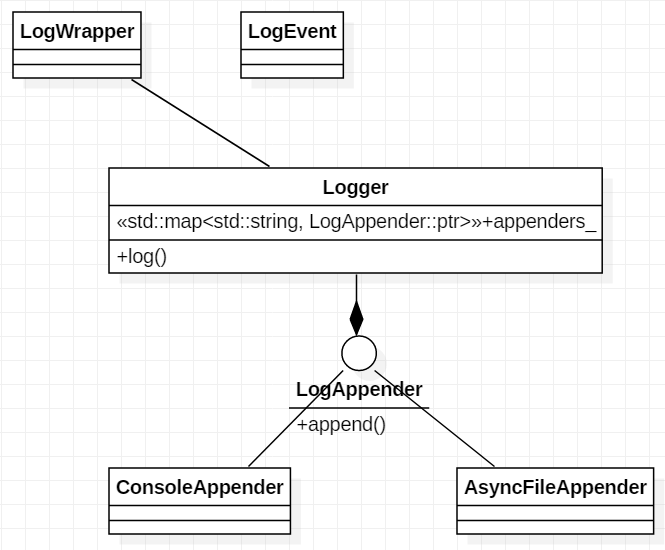
每條LOG_DEBUG等語句對應創建一個匿名LogWrapper對象,同時搜集日誌信息保存到LogEvent對象中,匿名對象創建完畢就會調用析構函數,在LogWrapper析構函數中將LogEvent送到Logger中,Logger再送往不同的目的地,比如控制台,文件等。
非同步文件Appender實現
AsyncFileAppend對外提供append方法,前端Logger只需要調用這個方法往裡面塞日誌,不用擔心會被阻塞。
前端和後端都維護一個緩衝區。
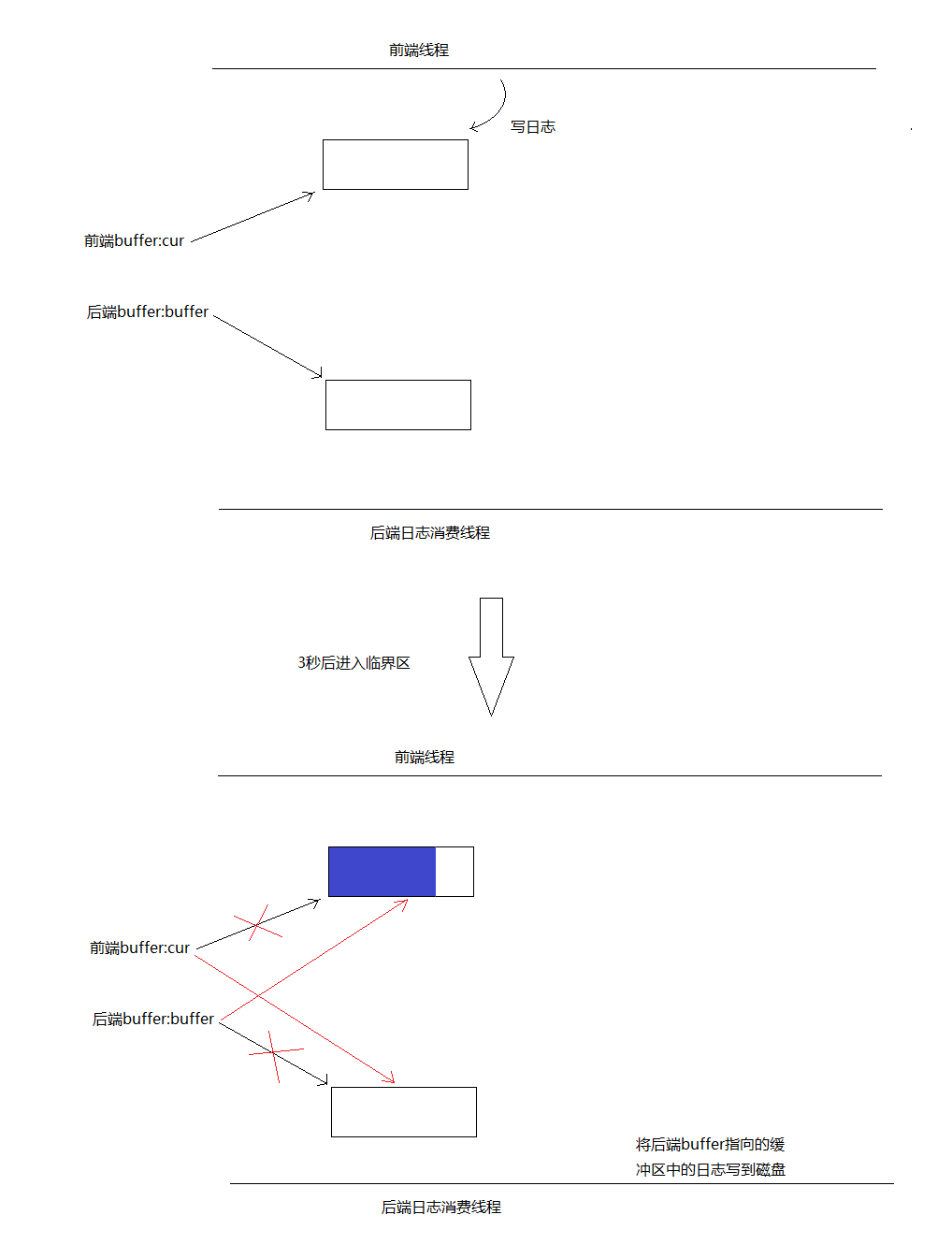
第一種情況:前端寫日誌較慢,三秒內還沒寫滿一個緩衝區。後端線程會被喚醒,進入臨界區,在臨界區內交換兩個buffer的指針,出臨界區後前端cur指向的緩衝區又是空的了,後端buffer指向的緩衝區為剛纔搜集了日誌的緩衝區,後端線程隨後將buffer指向的緩衝區中的日誌寫到磁碟中。臨界區內只交換兩個指針,所以臨界區很小。
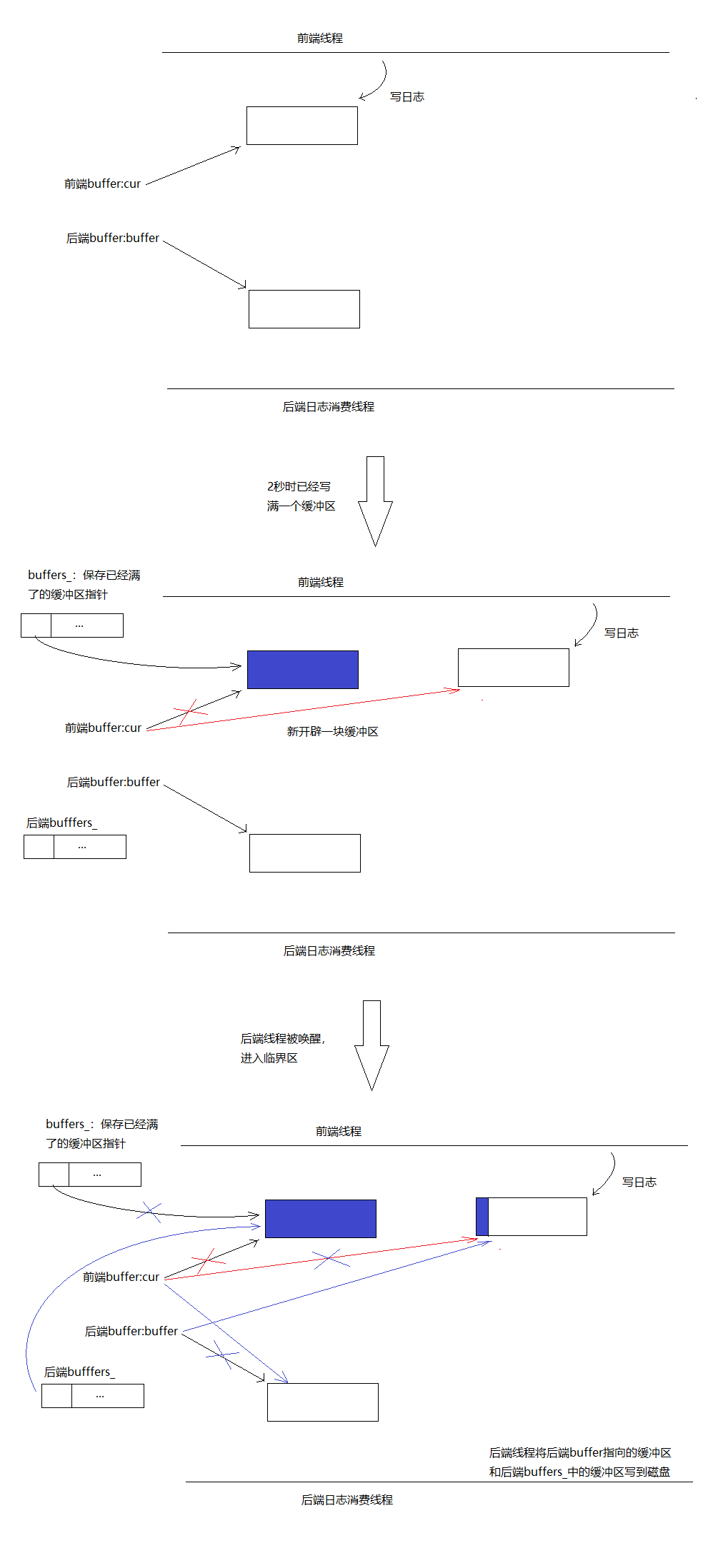
第二種情況:前端寫日誌較快,三秒內已經寫滿了一個緩衝區。比如兩秒的時候已經寫滿了第一個緩衝區,那麼將cur指針保存到一個向量buffers_中,然後開闢一塊新的緩衝區,另cur指向這塊新緩衝區。然後喚醒後端消費線程,後端線程進入臨界區,將cur和後端buffer_指針進行交換,將前端buffers_向量和後端persist_buffers_向量進行swap(對於std::vector也是指針交換)。出了臨界區後,前端的cur始終指向一塊乾凈的緩衝區,前端的向量buffers_也始終為空,後端的persist_buffers_向量中始終保存著有日誌的緩衝區的指針。臨界區同樣很小僅僅是幾個指針交換。
協程
類圖

成員變數:
- c_id_:當前協程id。
- context_:協程上下文。
- cb_:協程執行的函數。
- stack_size_:協程棧大小。
- statck_:協程棧。
- state_:協程狀態。
成員函數:
- swapIn():執行當前協程,只能由主協程調用。
- SwapOut():靜態函數,讓出當前協程的CPU,執行主協程,主協程會進行協程調度,將CPU控制權轉到另一個協程。
- GetCurrentCoroutine():獲取當前線程正在執行的協程。
- GetMainCoroutine():獲取當前線程的的主協程。
原理
ucontext系列函數:
int getcontext(ucontext_t *ucp): 將此刻的上下文保存到ucp指向的結構中。int setcontext(const ucontext_t *ucp): 調用成功後不會返回,執行流轉移到ucp指向的上下文。void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...):重新設置ucp指向的上下文為func函數起始處。ucp結構由getcontext()獲取。後續以ucp為參數調用setcontext()或者swapcontext()執行流將轉到func函數。int swapcontext(ucontext_t *oucp, const ucontext_t *ucp):保存當前上下文到oucp,並激活ucp指向的上下文。
需要考慮的問題
協程棧大小
不能太大:協程多了,記憶體浪費。
不能太小:使用者可能無意在棧上分配一個緩衝區,導致棧溢出。
暫時先固定為128K。
調度策略
目前是非搶占式調度。只能由協程主動或者協程執行完畢,才會讓出CPU。
協程同步
兩個協程間可能需要同步操作,比如協程1需要等待某個條件才能繼續運行,線程2修改條件然後通知協程1。
目前實現了簡陋的wait/notify機制,見CoroutineCondition。
協程調度
類圖

Processer
線程棧上的對象,線程退出後自動銷毀,生命周期大可不必操心。
成員變數:
- poller_:Poller。
- coroutines_:當前線程待執行的協程隊列。
成員函數:
- addTask():添加任務。
- run():開始進行協程調度。
協程調度示意圖
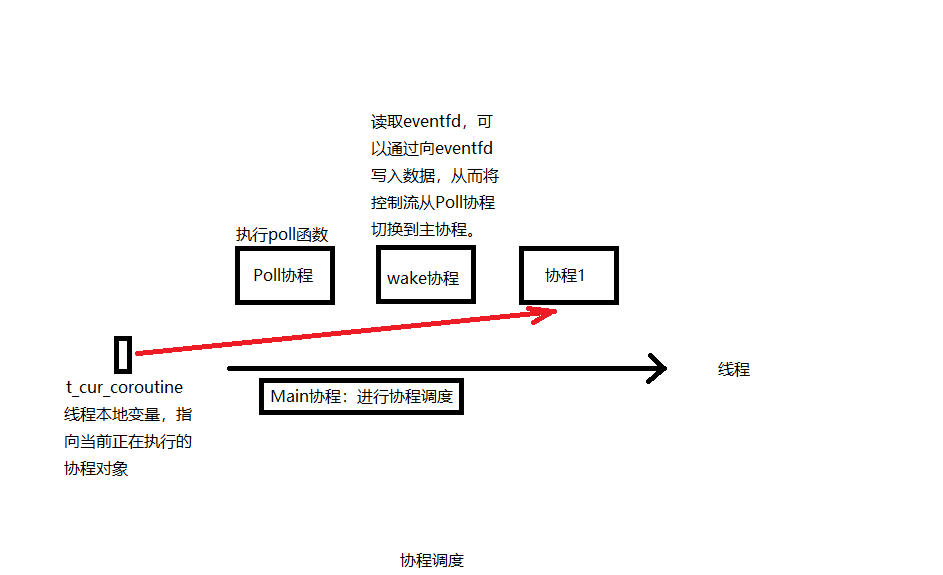
每個線程都有一個本地變數t_cur_cotourine指向當前正在執行的協程對象。
調度過程
Processer.run()函數作為Main協程進行調度,沒有協程在協程隊列時,執行Poll協程,該協程執行poll()函數。以read操作為例,某個協程在執行read的操作時,如果數據沒有準備好,就會將<fd, 當前協程對象>對註冊到Poller中,然後掛起。如果所有協程都阻塞了,那麼會執行Poll協程等待poll()函數返回,poll()函數返回後,如果有事件發生,會根據之前註冊的<fd, 協程對象>,將協程對象重新加入調度隊列,此時read已經有數據可讀了。
Main協程對應的代碼邏輯如下:
void Processer::run() {
if (GetProcesserOfThisThread() != nullptr) {
LOG_FATAL << "run two processer in one thread";
} else {
GetProcesserOfThisThread() = this;
}
melon::setHookEnabled(true);
Coroutine::Ptr cur;
//沒有可以執行協程時調用poll協程
Coroutine::Ptr poll_coroutine = std::make_shared<Coroutine>(std::bind(&Poller::poll, &poller_, kPollTimeMs), "Poll");
while (!stop_) {
{
MutexGuard guard(mutex_);
//沒有協程時執行poll協程
if (coroutines_.empty()) {
cur = poll_coroutine;
poller_.setPolling(true);
} else {
for (auto it = coroutines_.begin();
it != coroutines_.end();
++it) {
cur = *it;
coroutines_.erase(it);
break;
}
}
}
cur->swapIn();
if (cur->getState() == CoroutineState::TERMINATED) {
load_--;
}
}
}Poll協程對應的代碼邏輯如下:
void PollPoller::poll(int timeout) {
while (!processer_->stoped()) {
is_polling_ = true;
int num = ::poll(&*pollfds_.begin(), pollfds_.size(), timeout);
is_polling_ = false;
if (num == 0) {
} else if (num < 0) {
if (errno != EINTR) {
LOG_ERROR << "poll error, errno: " << errno << ", error str:" << strerror(errno);
}
} else {
std::vector<int> active_fds;
for (const auto& pollfd : pollfds_) {
if (pollfd.revents > 0) {
--num;
active_fds.push_back(pollfd.fd);
if (num == 0) {
break;
}
}
}
for (const auto& active_fd : active_fds) {
auto coroutine = fd_to_coroutine_[active_fd];
assert(coroutine != nullptr);
removeEvent(active_fd);
processer_->addTask(coroutine);
}
}
Coroutine::SwapOut();
}
}
}為什麼需要一個wake協程
可能出現這種情況:正在執行Poll協程,並且沒有事件到達,這時新加入一個協程,如果沒有機制將Poll協程從poll()函數中喚醒,那麼這個新的協程將無法得到執行。wake協程會read eventfd,此時會將<eventfd, wake協程>註冊到Poller中,如果有新的協程加入,會往eventfd寫1位元組的數據,那麼poll()函數就會被喚醒,從而Poll協程讓出CPU,新加入的協程被調度。
定時器
原理
#include <sys/timerfd.h>
int timerfd_create(int clockid, int flags); //創建一個timer對象,返回一個文件描述符timer fd代表這個timer對象。
int timerfd_settime(int fd, int flags,
const struct itimerspec *new_value,
struct itimerspec *old_value); //為timer對象設置一個時間間隔,倒計時結束後timer fd將變為可讀。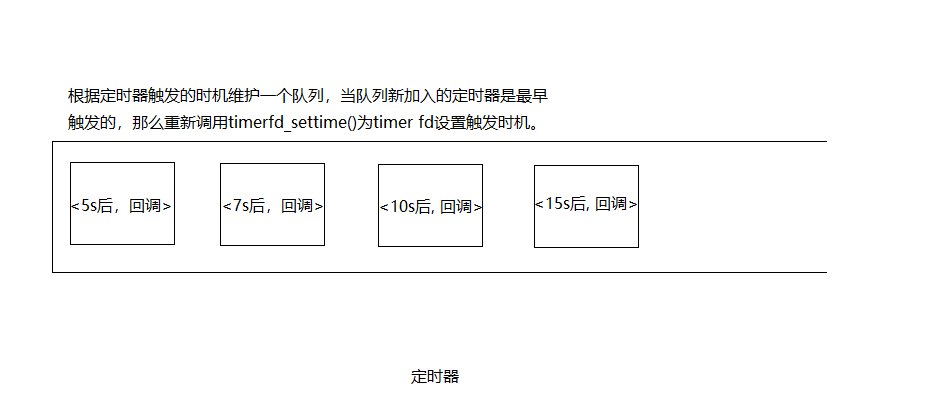
- 定時器專門占用一個線程。這個線程中加入一個定時器協程,該協程會去讀取timer fd,可讀後說明有定時器超時,然後執行定時器對應的任務。
- TimerManager維護一個定時器隊列。每一項包含定時器觸發時間和對應的回調。
- TimerManager.addTimer()將新的<timer, 回調>加入到隊列中。如果這個定時器是最先到期的那麼調用timerfd_settime()重新設置timer fd的到期時間。timer fd到期後,將從Poll協程中返回,然後執行定時器協程,該協程中讀取timer fd,然後根據現在的時間,將定時器隊列中超時的項刪除,並將超時的項的回調作為新的協程執行。
- 這個隊列可以由multimap來實現,multimap由紅黑樹實現,內部是有序的。紅黑樹本質就是一顆二叉樹,只不過為了防止多次的操作變得不平衡,增加了一些維持平衡的操作。
- 如何刪除定時器,每個定時器分配一個id,TimerManager內部維護一個id到定時器時間戳的映射sequence_2_timestamp_。cancel()時,根據id去sequence_2_timestamp_中找有沒有對應的定時器,如果有,將這個時間戳從時間戳隊列中刪除,必要時重新調用timerfd_settime()。
Hook
要想實現在協程中遇到耗時操作不阻塞當前IO線程,需要對一些系統函數進行hook。
- 可以用dlsym(3)來獲取想要hook的函數的函數指針,先保存起來,如果想要用到原函數,可以通過保存的函數指針進行調用。
- 定義自己的同名函數,覆蓋想要hook的函數。以sleep(3)為例。
unsigned int sleep(unsigned int seconds) {
melon::Processer* processer = melon::Processer::GetProcesserOfThisThread();
if (!melon::isHookEnabled()) {
return sleep_f(seconds);
}
melon::Scheduler* scheduler = processer->getScheduler();
assert(scheduler != nullptr);
scheduler->runAt(melon::Timestamp::now() + seconds * melon::Timestamp::kMicrosecondsPerSecond, melon::Coroutine::GetCurrentCoroutine());
melon::Coroutine::SwapOut();
return 0;
}我們自己定義的sleep不會阻塞線程,而是將當前協程切出去,讓CPU執行其它協程,等時間到了再執行當前協程。這樣就模擬了sleep的操作,同時不會阻塞當前線程。
RPC實現
參數序列化及反序列化
rpc說簡單點就是將參數傳給服務端,服務端根據參數找到對應的函數執行,得出一個響應,再將響應傳回給客戶端。客戶端的參數對象如何通過網路傳到服務端呢?這就涉及到序列化和反序列化。
melon選擇Protobuf,Protobuf具有很強的反射能力,在僅知道typename的情況下就能創建typename對應的對象。
google::protobuf::Message* ProtobufCodec::createMessage(const std::string& typeName) {
google::protobuf::Message* message = nullptr;
const google::protobuf::Descriptor* descriptor =
google::protobuf::DescriptorPool::generated_pool()->FindMessageTypeByName(typeName);
if (descriptor) {
const google::protobuf::Message* prototype =
google::protobuf::MessageFactory::generated_factory()->GetPrototype(descriptor);
if (prototype) {
message = prototype->New();
}
}
return message;
}上述函數根據參數typename就能創建一個Protobuf對象,這個新建的對象結合序列化後的Protobuf數據就能在服務端生成一個和客戶端一樣的Protobuf對象。
數據格式
|-------------------|
| total byte | 總的位元組數
|-------------------|
| typename | 類型名
|-------------------|
| typename len | 類型名長度
|-------------------|
| protobuf data | Protobuf對象序列化後的數據
|-------------------|
| checksum | 整個消息的checksum
|-------------------|某次rpc的過程如下:
客戶端包裝請求併發送 ----------------> 服務端接收請求
服務端解析請求,找到並執行對應的service::method
客戶端接收響並解析 <---------------- 服務端將響應發回給客戶端

