
前言 Hello我又來了,快年底了,作為一個有抱負的碼農,我想給自己攢一個年終總結。索性這次把資料庫中最核心的也是最難搞懂的內容,也就是索引,分享給大家。 這篇博客我會談談對於索引結構我自己的看法,以及分享如何從零開始一層一層向上最終理解索引結構,書接上文。 多頁模式 在多頁模式下,MySQL終於可 ...
前言
Hello我又來了,快年底了,作為一個有抱負的碼農,我想給自己攢一個年終總結。索性這次把資料庫中最核心的也是最難搞懂的內容,也就是索引,分享給大家。
這篇博客我會談談對於索引結構我自己的看法,以及分享如何從零開始一層一層向上最終理解索引結構,書接上文。
多頁模式
在多頁模式下,MySQL終於可以完成多數據的存儲了,就是採用開闢新頁的方式,將多條數據放在不同的頁中,然後同樣採用鏈表的數據結構,將每一頁連接起來。那麼可以思考第四個問題:多頁情況下是否對查詢效率有影響呢?
多頁模式對於查詢效率的影響
針對這個問題,既然問出來了,那麼答案是肯定的,多頁會對查詢效率產生一定的影響,影響主要就體現在,多頁其本質也是一個鏈表結構,只要是鏈表結構,查詢效率一定不會高。
假設數據又非常多條,資料庫就會開闢非常多的新頁,而這些新頁就會像鏈表一樣連接在一起,當我們要在這麼多頁中查詢某條數據時,它還是會從頭節點遍歷到存在我們要查找的那條數據所存在的頁上,我們好不容易通過頁目錄優化了頁中數據的查詢效率,現在又出現了以頁為單位的鏈表,這不是前功盡棄了嗎?
如何優化多頁模式
由於多頁模式會影響查詢的效率,那麼肯定需要有一種方式來優化多頁模式下的查詢。相信有同學已經猜出來了,既然我們可以用頁目錄來優化頁內的數據區,那麼我們也可以採取類似的方式來優化這種多頁的情況。
是的,頁內數據區和多頁模式本質上都是鏈表,那麼的確可以採用相同的方式來對其進行優化,它就是目錄頁。
所以我們對比頁內數據區,來分析如何優化多頁結構。在單頁時,我們採用了頁目錄的目錄項來指向一行數據,這條數據就是存在於這個目錄項中的最小數據,那麼就可以通過頁目錄來查找所需數據。
所以對於多頁結構也可以採用這種方式,使用一個目錄項來指向某一頁,而這個目錄項存放的就是這一頁中存放的最小數據的索引值。和頁目錄不同的地方在於,這種目錄管理的級別是頁,而頁目錄管理的級別是行。
那麼分析到這裡,我們多頁模式的結構就會是下圖所示的這樣:
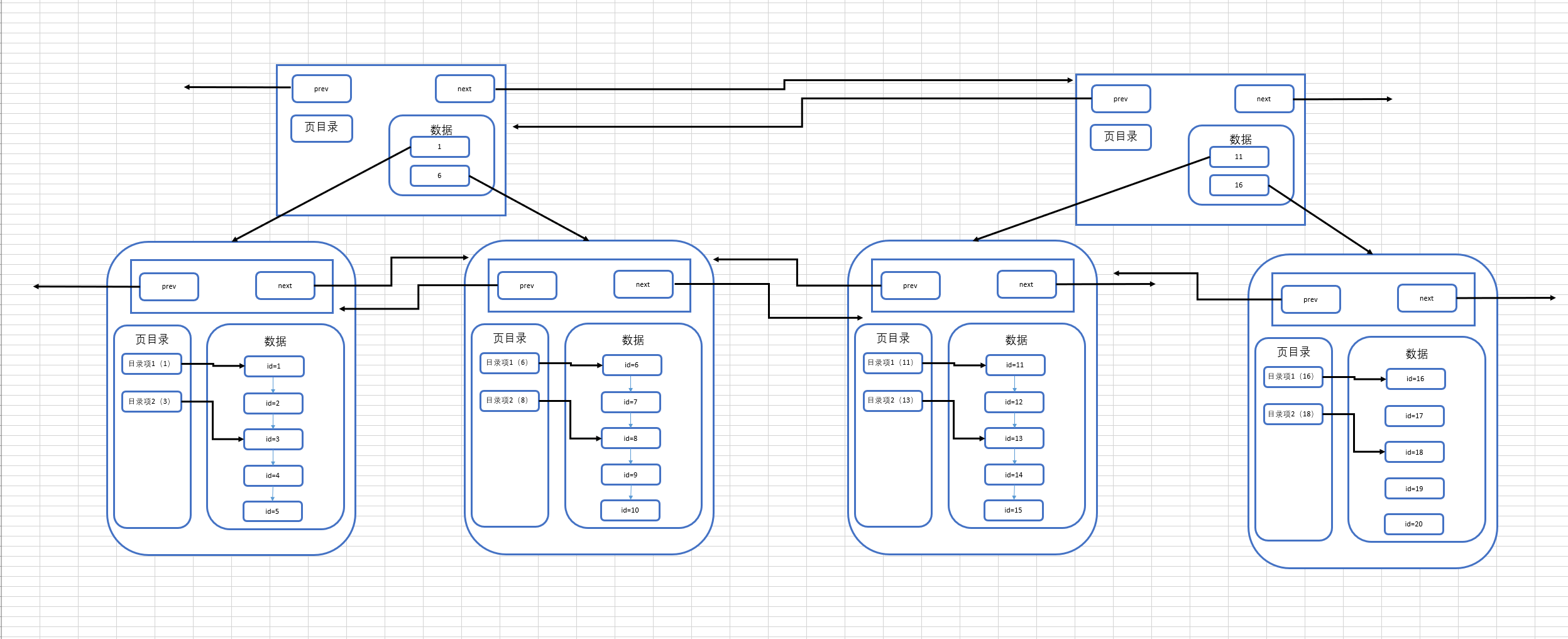
存在一個目錄頁來管理頁目錄,目錄頁中的數據存放的就是指向的那一頁中最小的數據。
這裡要註意的一點是:其實目錄頁的本質也是頁,普通頁中存的數據是項目數據,而目錄頁中存的數據是普通頁的地址。
假設我們要查找id=19的數據,那麼按照以前的查找方式,我們需要從第一頁開始查找,發現不存在那麼再到第二頁查找,一直找到第四頁才能找到id=19的數據,但是如果有了目錄頁,就可以使用id=19與目錄頁中存放的數據進行比較,發現19大於任何一條數據,於是進入id=16指向的頁進行查找,直接然後再通過頁內的頁目錄行級別的數據的查找,很快就可以找到id為19的數據了。隨著數據越來越多,這種結構的效率相對於普通的多頁模式,優勢也就越來越明顯。
回歸正題,相信有對MySQL比較瞭解的同學已經發現了,我們畫的最終的這幅圖,就是MySQL中的一種索引結構——B+樹。
B+樹的引入
我們將我們畫的存在目錄頁的多頁模式圖巨集觀化,可以形成下麵的這張圖:

這就是我們兜兜轉轉由簡到繁形成的一顆B+樹。和常規B+樹有些許不同,這是一棵MySQL意義上的B+樹,MySQL的一種索引結構,其中的每個節點就可以理解為是一個頁,而葉子節點也就是數據頁,除了葉子節點以外的節點就是目錄頁。
這一點在圖中也可以看出來,非葉子節點只存放了索引,而只有葉子節點中存放了真實的數據,這也是符合B+樹的特點的。
B+樹的優勢
由於葉子節點上存放了所有的數據,並且有指針相連,每個葉子節點在邏輯上是相連的,所以對於範圍查找比較友好。
B+樹的所有數據都在葉子節點上,所以B+樹的查詢效率穩定,一般都是查詢3次。
B+樹有利於資料庫的掃描。
B+樹有利於磁碟的IO,因為他的層高基本不會因為數據擴大而增高(三層樹結構大概可以存放兩千萬數據量。
頁的完整結構
說完了頁的概念和頁是如何一步一步地組合稱為B+樹的結構之後,相信大家對於頁都有了一個比較清楚的認知,所以這裡就要開始說說官方概念了,基於我們上文所說的,給出一個完整的頁結構,也算是對上文中自己理解頁結構的一種補充。

上圖為 Page 數據結構,File Header 欄位用於記錄 Page 的頭信息,其中比較重要的是 FIL_PAGE_PREV 和 FIL_PAGE_NEXT 欄位,通過這兩個欄位,我們可以找到該頁的上一頁和下一頁,實際上所有頁通過兩個欄位可以形成一條雙向鏈表。
Page Header 欄位用於記錄 Page 的狀態信息。接下來的 Infimum 和 Supremum 是兩個偽行記錄,Infimum(下確界)記錄比該頁中任何主鍵值都要小的值,Supremum (上確界)記錄比該頁中任何主鍵值都要大的值,這個偽記錄分別構成了頁中記錄的邊界。
User Records 中存放的是實際的數據行記錄,具體的行記錄結構將在本文的第二節中詳細介紹。Free Space 中存放的是空閑空間,被刪除的行記錄會被記錄成空閑空間。Page Directory 記錄著與二叉查找相關的信息。File Trailer 存儲用於檢測數據完整性的校驗和等數據。
引用來源:https://www.cnblogs.com/bdsir/p/8745553.html
基於B+樹聊聊MySQL的其它知識點
看到這裡,我們已經瞭解了MySQL從單條數據開始,到通過頁來減少磁碟IO次數,並且在頁中實現了頁目錄來優化頁中的查詢效率,然後使用多頁模式來存儲大量的數據,最終使用目錄頁來實現多頁模式的查詢效率並形成我們口中的索引結構——B+樹。既然說到這裡了,那我們就來聊聊MySQL的其他知識點。
聚簇索引和非聚簇索引
所謂聚簇索引,就是將索引和數據放到一起,找到索引也就找到了數據,我們剛纔看到的B+樹索引就是一種聚簇索引,而非聚簇索引就是將數據和索引分開,查找時需要先查找到索引,然後通過索引回表找到相應的數據。InnoDB有且只有一個聚簇索引,而MyISAM中都是非聚簇索引。
聯合索引的最左首碼匹配原則
在MySQL資料庫中不僅可以對某一列建立索引,還可以對多列建立一個聯合索引,而聯合索引存在一個最左首碼匹配原則的概念,如果基於B+樹來理解這個最左首碼匹配原則,相對來說就會容易很很多了。
首先我們基於文首的這張表建立一個聯合索引:
create index idx_obj on user(age asc,height asc,weight asc)
我們已經瞭解了索引的數據結構是一顆B+樹,也瞭解了B+樹優化查詢效率的其中一個因素就是對數據進行了排序,那麼我們在創建idx_obj這個索引的時候,也就相當於創建了一顆B+樹索引,而這個索引就是依據聯合索引的成員來進行排序,這裡是age,height,weight。
看過我之前那篇博客的同學知道,InnoDB中只要有主鍵被定義,那麼主鍵列被作為一個聚簇索引,而其它索引都將被作為非聚簇索引,所以自然而然的,這個索引就會是一個非聚簇索引。
所以根據這些我們可以得出結論:
-
idx_obj這個索引會根據age,height,weight進行排序
-
idx_obj這個索引是一個非聚簇索引,查詢時需要回表
根據這兩個結論,首先需要瞭解的就是,如何排序?
單列排序很簡單,比大小嘛,誰都會,但是多列排序是基於什麼原則的呢(重點)?
實際上在MySQL中,聯合索引的排序有這麼一個原則,從左往右依次比較大小,就拿剛纔建立的索引舉例子,他會先去比較age的大小,如果age的大小相同,那麼比較height的大小,如果height也無法比較大小, 那麼就比較weight的大小,最終對這個索引進行排序。
那麼根據這個排序我們也可以畫出一個B+樹,這裡就不像上文畫的那麼詳細了,簡化一下:
數據:
B+樹:

註意:此時由於是非聚簇索引,所以葉子節點不在有數據,而是存了一個主鍵索引,最終會通過主鍵索引來回表查詢數據。
B+樹的結構有了,就可以通過這個來理解最左首碼匹配原則了。
我們先寫一個查詢語句
SELECT * FROM user WHERE age=1 and height = 2 and weight = 7
毋庸置疑,這條語句一定會走idx_obj這個索引。
那麼我們再看一個語句:
SELECT * FROM user WHERE height=2 and weight = 7
思考一下,這條SQL會走索引嗎?
答案是否定的,那麼我們分析的方向就是,為什麼這條語句不會走索引。
上文中我們提到了一個多列的排序原則,是從左到右進行比較然後排序的,而我們的idx_obj這個索引從左到右依次是age,height,weight,所以當我們使用height和weight來作為查詢條件時,由於age的缺失,那麼就無法從age來進行比較了。
看到這裡可能有小伙伴會有疑問,那如果直接用height和weight來進行比較不可以嗎?顯然是不可以的,可以舉個例子,我們把缺失的這一列寫作一個問號,那麼這條語句的查詢條件就變成了?27,那麼我們從這課B+樹的根節點開始,根節點上有127和365,那麼以height和weight來進行比較的話,走的一定是127這一邊,但是如果缺失的列數字是大於3的呢?比如427,527,627,那麼如果走索引來查詢數據,將會丟失數據,錯誤查詢。所以這種情況下是絕對不會走索引進行查詢的。這就是最左首碼匹配原則的成因。
- 最左首碼匹配原則,MySQL會一直向右匹配直到遇到範圍查詢(>、<、between、like)就停止匹配,比如 a=3 and b=4 and c>5 and d=6,如果建立(a,b,c,d)順序的索引,d是無法使用索引的,如果建立(a,b,d,c)的索引則都可以使用到,a、b、d的順序可以任意調整。
- =和in可以亂序,比如 a=1 and b=2 and c=3 建立(a,b,c)索引可以任意順序,MySQL的查詢優化器會幫你優化成索引可以識別的形式。
根據我們瞭解的可以得出結論:
只要無法進行排序比較大小的,就無法走聯合索引。
可以再看幾個語句:
SELECT * FROM user WHERE age=1 and height = 2
這條語句是可以走idx_obj索引的,因為它可以通過比較 (12?<365)。
SELECT * FROM user WHERE age=1 and weight=7
這條語句也是可以走ind_obj索引的,因為它也可以通過比較(1?7<365),走左子樹,但是實際上weight並沒有用到索引,因為根據最左匹配原則,如果有兩頁的age都等於1,那麼會去比較height,但是height在這裡並不作為查詢條件,所以MySQL會將這兩頁全都載入到記憶體中進行最後的weight欄位的比較,進行掃描查詢。
SELECT * FROM user where age>1
這條語句不會走索引,但是可以走索引。這句話是什麼意思呢?這條SQL很特殊,由於其存在可以比較的索引,所以它走索引也可以查詢出結果,但是由於這種情況是範圍查詢並且是全欄位查詢,如果走索引,還需要進行回表,MySQL查詢優化器就會認為走索引的效率比全表掃描還要低,所以MySQL會去優化它,讓他直接進行全表掃描。
SELECT * FROM user WEHRE age=1 and height>2 and weight=7
這條語句是可以走索引的,因為它可以通過age進行比較,但是weight不會用到索引,因為height是範圍查找,與第二條語句類似,如果有兩頁的height都大於2,那麼MySQL會將兩頁的數據都載入進記憶體,然後再來通過weight匹配正確的數據。
為什麼InnoDB只有一個聚簇索引,而不將所有索引都使用聚簇索引?
因為聚簇索引是將索引和數據都存放在葉子節點中,如果所有的索引都用聚簇索引,則每一個索引都將保存一份數據,會造成數據的冗餘,在數據量很大的情況下,這種數據冗餘是很消耗資源的。
補充兩個關於索引的點
這兩個點也是上次寫關於索引的博客時漏下的,這裡補上。
1.什麼情況下會發生明明創建了索引,但是執行的時候並沒有通過索引呢?
科普時間:查詢優化器 一條SQL語句的查詢,可以有不同的執行方案,至於最終選擇哪種方案,需要通過優化器進行選擇,選擇執行成本最低的方案。
在一條單表查詢語句真正執行之前,MySQL的查詢優化器會找出執行該語句所有可能使用的方案,對比之後找出成本最低的方案。這個成本最低的方案就是所謂的執行計劃。
優化過程大致如下:
1、根據搜索條件,找出所有可能使用的索引
2、計算全表掃描的代價
3、計算使用不同索引執行查詢的代價
4、對比各種執行方案的代價,找出成本最低的那一個 。
參考:https://juejin.im/post/5d23ef4ce51d45572c0600bc
根據我們剛纔的那張表的非聚簇索引,這條語句就是由於查詢優化器的作用,造成沒有走索引:
SELECT * FROM user where age>1
2.在稀疏索引情況下通常需要通過葉子節點的指針回表查詢數據,什麼情況下不需要回表?
科普時間:覆蓋索引 覆蓋索引(covering index)指一個查詢語句的執行只用從索引中就能夠取得,不必從數據表中讀取。也可以稱之為實現了索引覆蓋。
當一條查詢語句符合覆蓋索引條件時,MySQL只需要通過索引就可以返回查詢所需要的數據,這樣避免了查到索引後再返回表操作,減少I/O提高效率。
如,表covering_index_sample中有一個普通索引 idx_key1_key2(key1,key2)。當我們通過SQL語句:select key2 from covering_index_sample where key1 = 'keytest';的時候,就可以通過覆蓋索引查詢,無需回表。
參考:https://juejin.im/post/5d23ef4ce51d45572c0600bc
例如:
SELECT age FROM user where age = 1
這句話就不需要進行回表查詢。
結語
本篇文章著重聊了一下關於MySQL的索引結構,從零開始慢慢構建了一個B+樹索引,並且根據這個過程談了B+樹是如何一步一步去優化查詢效率的。
簡單地歸納一下就是:
排序:優化查詢的根本,插入時進行排序實際上就是為了優化查詢的效率。
頁:用於減少IO次數,還可以利用程式局部性原理,來稍微提高查詢效率。
頁目錄:用於規避鏈表的軟肋,避免在查詢時進行鏈表的掃描。
多頁:數據量增加的情況下開闢新頁來保存數據。
目錄頁:“特殊的頁目錄”,其中保存的數據是頁的地址。查詢時可以通過目錄頁快速定位到頁,避免多頁的掃描。
END


