
前言 Hello我又來了,快年底了,作為一個有抱負的碼農,我想給自己攢一個年終總結。索性這次把資料庫中最核心的也是最難搞懂的內容,也就是索引,分享給大家。 這篇博客我會談談對於索引結構我自己的看法,以及分享如何從零開始一層一層向上最終理解索引結構。 從一個簡單的表開始 create table us ...
前言
Hello我又來了,快年底了,作為一個有抱負的碼農,我想給自己攢一個年終總結。索性這次把資料庫中最核心的也是最難搞懂的內容,也就是索引,分享給大家。
這篇博客我會談談對於索引結構我自己的看法,以及分享如何從零開始一層一層向上最終理解索引結構。
從一個簡單的表開始
create table user( id int primary key, age int, height int, weight int, name varchar(32) )engine = innoDb;
相信只要入門資料庫的同學都可以理解這個語句,我們也將從這個最簡單的表開始,一步步地理解MySQL的索引結構。
首先,我們往這個表中插入一些數據。
INSERT INTO user(id,age,height,weight,name)VALUES(2,1,2,7,'小吉'); INSERT INTO user(id,age,height,weight,name)VALUES(5,2,1,8,'小尼'); INSERT INTO user(id,age,height,weight,name)VALUES(1,4,3,1,'小泰'); INSERT INTO user(id,age,height,weight,name)VALUES(4,1,5,2,'小美'); INSERT INTO user(id,age,height,weight,name)VALUES(3,5,6,7,'小蔡');
我們來查一下,看看這些數據是否已經放入表中。
select * from user;
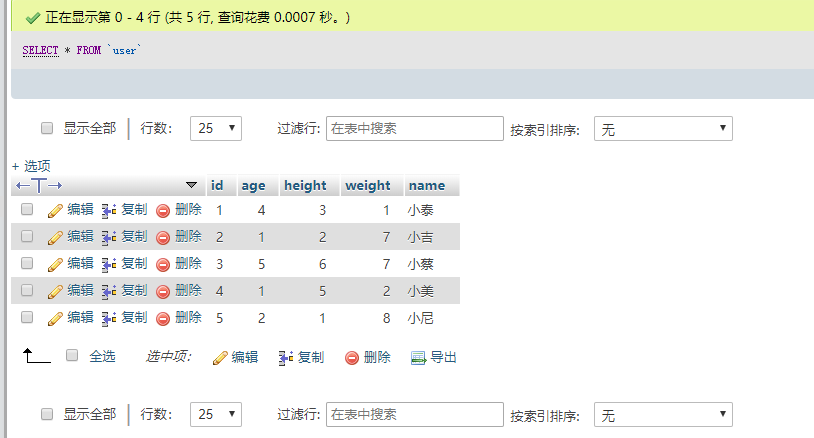
可以看到,數據已經完整地放到了我們創建的user表中。
但是不知道大家發現了什麼沒有,好像發生了一件非常詭異的事情,我們插入的數據好像亂序了…
MySQL好像悄悄的給我們按照id排了個序。
為什麼會出現MySQL在我們沒有顯式排序的情況下,默默幫我們排了序呢?它是在什麼時候進行排序的?
頁的引入
不知道大家畢業多長時間了,作為一個剛複習完操作系統不久的學渣,頁的概念依舊在腦中還沒有變涼。其實MySQL中也有類似頁的邏輯存儲單位,聽我慢慢道來。
在操作系統的概念中,當我們往磁碟中取數據,假設要取出的數據的大小是1KB,但是操作系統並不會只取出這1kb的數據,而是會取出4KB的數據,因為操作系統的一個頁表項的大小是4KB。那為什麼我們只需要1KB的數據,但是操作系統要取出4KB的數據呢?
這就涉及到一個程式局部性的概念,具體的概念我背不清了,大概就是“一個程式在訪問了一條數據之後,在之後會有極大的可能再次訪問這條數據和訪問這條數據的相鄰數據”,所以索性直接載入4KB的數據到記憶體中,下次要訪問這一頁的數據時,直接從記憶體中找,可以減少磁碟IO次數,我們知道,磁碟IO是影響程式性能主要的因素,因為磁碟IO和記憶體IO的速度是不可同日而語的。
或許看完上面那一大段描述,還是有些抽象,所以我們索性回到資料庫層面中,重新理解頁的概念。
拋開所有東西不談,假設還是我們剛纔插入的那些數據,我們現在要找id = 5的數據,依照最原始的方式,我們一定會想到的就是——遍歷,沒錯,這也是我們剛開始學電腦的時候最常用的尋找數據的方式。那麼我們就來看看,以遍歷的方式,我們找到id=5的數據,需要經歷幾次磁碟IO。
首先,我們得先從id=1的數據開始讀起,然後判斷是否是我們需要的數據,如果不是,就再取id=2的數據,再進行判斷,迴圈往複。毋庸置疑,在MySQL幫我們排好序之後,我們需要經歷五次磁碟IO,才能將5號數據找到並讀出來。
那麼我們再來看看引入頁的概念之後,我們是如何讀數據的。
在引入頁的概念之後,MySQL會將多條數據存在一個叫“頁”的數據結構中,當MySQL讀取id=1的數據時,會將id=1數據所在的頁整頁讀到記憶體中,然後在記憶體中進行遍歷判斷,由於記憶體的IO速度比磁碟高很多,所以相對於磁碟IO,幾乎可以忽略不計,那麼我們來看看這樣讀取數據我們需要經歷幾次磁碟IO(假設每一頁可以存4條數據)。
那麼我們第一次會讀取id=1的數據,並且將id=1到id=4的數據全部讀到記憶體中,這是第一次磁碟IO,第二次將讀取id=5的數據到記憶體中,這是第二次磁碟IO。所以我們只需要經歷2次磁碟IO就可以找到id=5的這條數據。
但其實,在MySQL的InnoDb引擎中,頁的大小是16KB,是操作系統的4倍,而int類型的數據是4個位元組,其它類型的數據的位元組數通常也在4000位元組以內,所以一頁是可以存放很多很多條數據的,而MySQL的數據正是以頁為基本單位組合而成的。
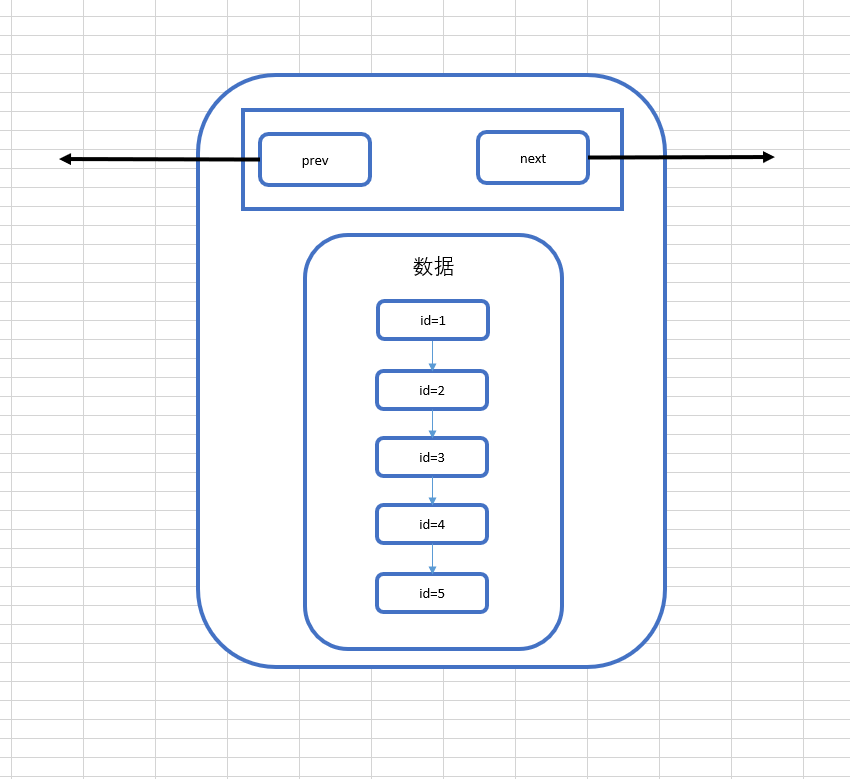
上圖就是我們目前為止所理解的頁的結構,他包含我們的多條數據,另外,MySQL的數據以頁組成,那麼它有指向下一頁的指針和指向上一頁的指針。
那麼說到這裡,其實可以回答第一個問題了,MySQL實際上就是在我們插入數據的時候,就幫我們在頁中排好了序,至於為什麼要排序,這裡先賣個關子,接著往下看。
排序對性能的影響
上文中我們提了一個問題,為什麼資料庫在插入數據時要對其進行排序呢?我們按正常順序插入數據不是也挺好的嗎?
這就要涉及到一個資料庫查詢流程的問題了,無論如何,我們是絕對不會去平白無故地在插入數據時增加一個操作來讓流程複雜化的,所以插入數據時排序一定有其目的,就是優化查詢的效率。
而我們不難看出,頁內部存放數據的模塊,實質上就是一個鏈表的結構,鏈表的特點也就是增刪快,查詢慢,所以優化查詢的效率是必須的。
基於單頁模式存儲的查詢流程
還是基於我們第一節中的那張頁圖來談,我們插入了五條數據,id分別是從1-5,那麼假設我要找一個表中不存在的id,假設id=-1,那麼現在的查詢流程就是:
將id=1的這一整頁數據取出,進行逐個比對,那麼當我們找到id=1的這條數據時,發現這個id大於我們所需要找的哪個id,由於資料庫在插入數據時,已經進行過排序了,那麼在id=1的數據後面,都是id>1的數據,所以我們就不需要再繼續往下尋找了。
如果在插入時沒有進行排序,那毋庸置疑,我們需要再繼續往下進行尋找,逐條查找直到到結尾也沒有找到這條數據,才能返回不存在這條數據。
當然,這隻是排序優化的冰山一角,接著往下看。
上述頁模式可能帶來的問題
說完了排序,下麵就來分析一下我們在第一節中的那幅圖,對於大數據量下有什麼弊端,或者換一個說法,我們可以怎麼對這個模式進行優化。
我們不難看出,在現階段我們瞭解的頁模式中,只有一個功能,就是在查詢某條數據的時候直接將一整頁的數據載入到記憶體中,以減少硬碟IO次數,從而提高性能。但是,我們也可以看到,現在的頁模式內部,實際上是採用了鏈表的結構,前一條數據指向後一條數據,本質上還是通過數據的逐條比較來取出特定的數據。
那麼假設,我們這一頁中有一百萬條數據,我們要查的數據正好在最後一個,那麼我們是不是一定要從前往後找到這一條數據呢?如果是這樣,我們需要查找的次數就達到了一百萬次,即使是在記憶體中查找,這個效率也是不高的。那麼有什麼辦法來優化這種情況下的查找效率呢?
頁目錄的引入
我們可以打個比方,我們在看書的時候,如果要找到某一節,而這一節我們並不知道在哪一頁,我們是不是就要從前往後,一節一節地去尋找我們需要的內容的頁碼呢?答案是否定的,因為在書的前面,存在目錄,它會告訴你這一節在哪一頁,例如,第一節在第1頁、第二節在第13頁。在資料庫的頁中,實際上也使用了這種目錄的結構,這就是頁目錄。
那麼引入頁目錄之後,我們所理解的頁結構,就變成了這樣:
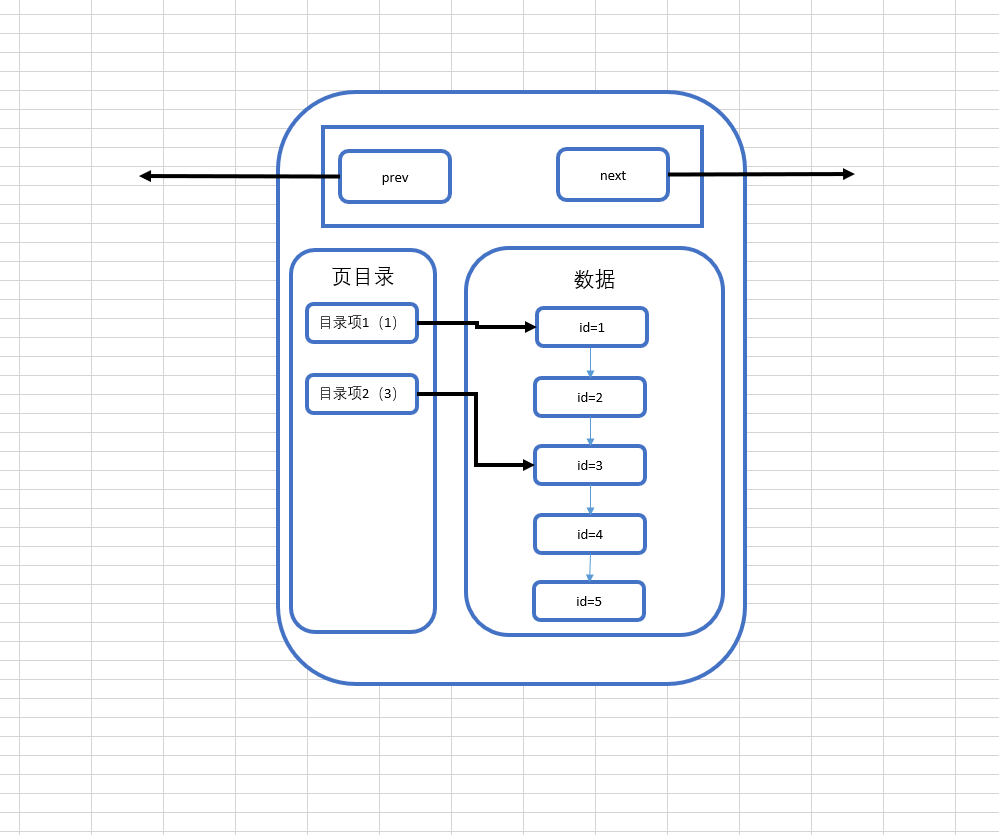
分析一下這張圖,實際上頁目錄就像是我們在看書的時候書本的目錄一樣,目錄項1就相當於第一節,目錄項2就相當於第二節,而每一條數據就相當於書本的每一頁,這張圖就可以解釋成,第一節從第一頁開始,第二節從第三頁開始,而實際上,每個目錄項會存放自己這個目錄項當中最小的id,也就是說,目錄項1中會存放1,而目錄項2會存放3。
那麼對比一下資料庫在沒有頁目錄時候的查找流程,假設要查找id=3的數據,在沒有頁目錄的情況下,需要查找id=1、id=2、id=3,三次才能找到該數據,而如果有頁目錄之後,只需要先查看一下id=3存在於哪個目錄項下,然後直接通過目錄項進行數據的查找即可,如果在該目錄項下沒有找到這條數據,那麼就可以直接確定這條數據不存在,這樣就大大提升了資料庫的查找效率,但是這種頁目錄的實現,首先就需要基於數據是在已經進行過排序的的場景下,才可以發揮其作用,所以看到這裡,大家應該明白第二個問題了,為什麼資料庫在插入時會進行排序,這才是真正發揮排序的作用的地方。
頁的擴展
在上文中,我們基本上說明白了MySQL資料庫中頁的概念,以及它是如何基於頁來減少磁碟IO次數的,以及排序是如何優化查詢的效率的。
那麼我們現在再來思考第三個問題:在開頭說頁的概念的時候,我們有說過,MySQL中每一頁的大小隻有16KB,不會隨著數據的插入而自動擴容,所以這16KB不可能存下我們所有的數據,那麼必定會有多個頁來存儲數據,那麼在多頁的情況下,MySQL中又是怎麼組織這些頁的呢?
針對這個問題,我們繼續來畫出我們現在所瞭解的多頁的結構圖:
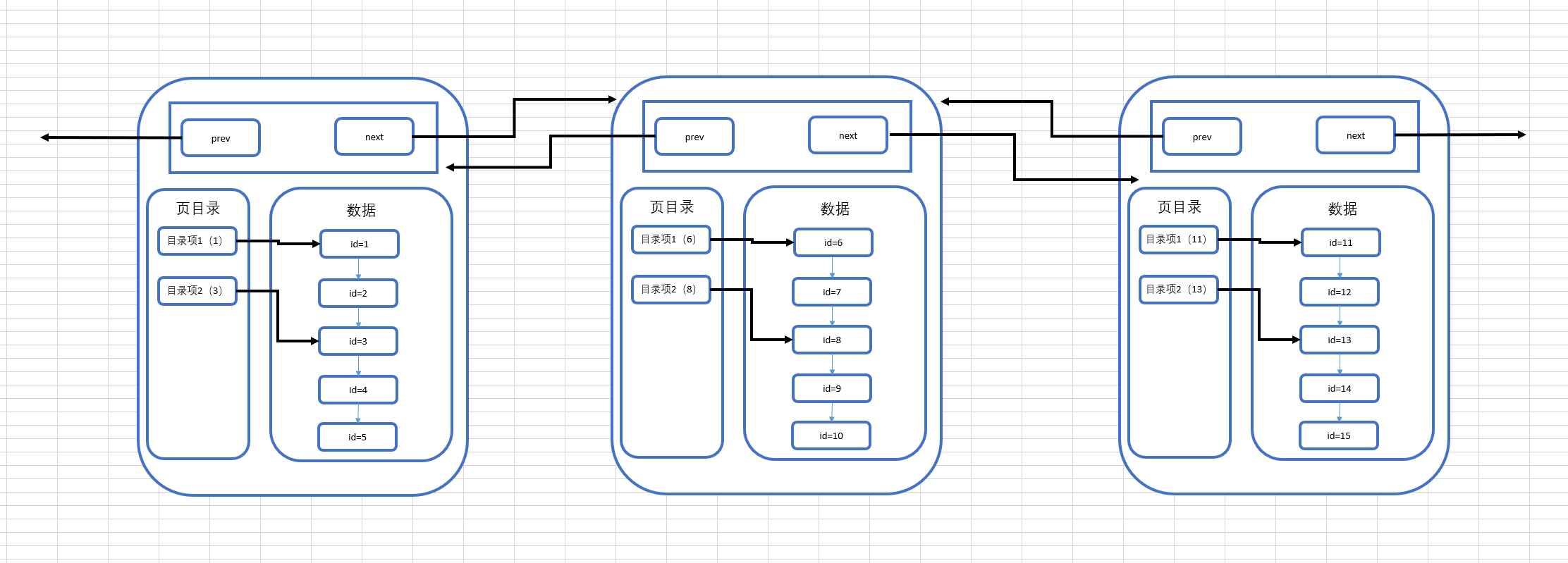
可以看到,在數據不斷變多的情況下,MySQL會再去開闢新的頁來存放新的數據,而每個頁都有指向下一頁的指針和指向上一頁的指針,將所有頁組織起來,第一頁中存放id為1-5的數據,第二頁存放id為6-10的數據,第三頁存放id為11-15的數據,需要註意的是在開闢新頁的時候,我們插入的數據不一定是放在新開闢的頁上,而是要進行所有頁的數據比較,來決定這條插入的數據放在哪一頁上,而完成數據插入之後,最終的多頁結構就會像上圖中畫的那樣。


