
1. MapReduce入門 1.1 MapReduce的思想 MapReduce的思想核心是"分而治之" , 適用於大量的複雜的任務處理場景 (大規模數據處理場景) . Map負責"分" , 即把複雜的任務分解為若幹個"簡單的任務"來進行處理. 可以進行拆分的前提是這些小任務並行計算, 彼此間幾乎 ...
1. MapReduce入門
1.1 MapReduce的思想
MapReduce的思想核心是"分而治之" , 適用於大量的複雜的任務處理場景 (大規模數據處理場景) .
Map負責"分" , 即把複雜的任務分解為若幹個"簡單的任務"來進行處理. 可以進行拆分的前提是這些小任務並行計算, 彼此間幾乎沒有依賴關係.
Reduce負責"合" , 即對map階段的結果進行全局彙總.
這兩個階段合起來正是MR思想的體現.
1.2 MapReduce設計構思
MapReduce是一個分部式運算程式的編程框架, 核心功能是將用戶編寫的業務邏輯代碼和自帶預設組件整合成一個完整的分散式運算程式. 併發運行在Hadoop集群上.
既然是做計算的框架, 那麼表現形式就是有個輸入 (input) , MR操作這個輸入, 通過本身定義好的計算模型, 得到一個輸出 (output) .
MR就是一種簡化並行計算的編程模型, 降低了開發並行應用的入門門檻.
Hadoop MapReduce構思體現在三個方面:
-
- 如何對付大數據處理: 分而治之
對相互間不具有計算依賴關係的大數據, 實現並行最自然的方法就是採取分而治之的策略. 並行計算的第一個重要問題是如何劃分計算任務或者計算數據以便對劃分的子任務或數據塊同時進行計算. 不可分拆的計算任務或相互間有依賴關係的數據無法進行並行計算.
-
- 構建抽象模型: Map和Reduce
MR借鑒了函數式語言中的思想, 用Map和Reduce兩個函數提供了高層的並行編程抽象模型.
Map: 對一組數據元素進行某種重覆式的處理.
Reduce: 對Map的中間結果進行某種進一步的結果整理.
MapReduce中定義瞭如下的Map和Reduce兩個抽象的編程介面, 由用戶去編程實現:
Map: (k1, v1) -> [(k2, v2)]
Reduce: (k2, [v2]) -> [(k3, v3)]
Map和Reduce為我們提供了一個清晰的操作介面抽象描述. 通過以上兩個編程介面, 可以看出MR處理的數據類型是<key, value>鍵值對.
-
- 統一架構, 隱藏系統層細節
如何提供統一的計算框架, 如果沒有統一封裝底層細節, 那麼我們則需要考慮諸如數據存儲, 劃分, 分發, 結果手機, 錯誤恢復等諸多細節. 為此, MR設計並提供了統一的計算框架, 隱藏了絕大多數系統層面的處理細節.
MapReduce最大的亮點在於通過抽象模型和計算框架把需要做什麼 (what need to do) 與具體怎麼做 (how to do) 分開了, 為我們提供一個抽象和高層的編程介面和框架. 我們僅需要關心其應用層的具體計算問題, 僅需編寫少量的處理應用本身計算問題的程式代碼. 如何具體完成這個並行計算任務所相關的諸多系統層細節被隱藏起來, 交給計算框架去處理: 從分佈代碼的執行, 到大到數千小到單個節點集群的自動調度使用.
1.3 MapReduce框架結構
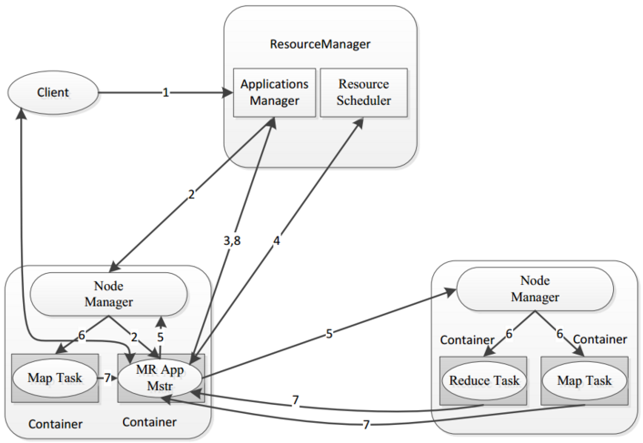
一個完整的MR程式在分散式運行時有三類實例進程:
1) MRAppMaster: 負責整個程式的過程調度及狀態協調.
2) MapTask: 負責Map階段的整個數據處理流程.
3) ReduceTask: 負責Reduce階段的整個數據處理流程.

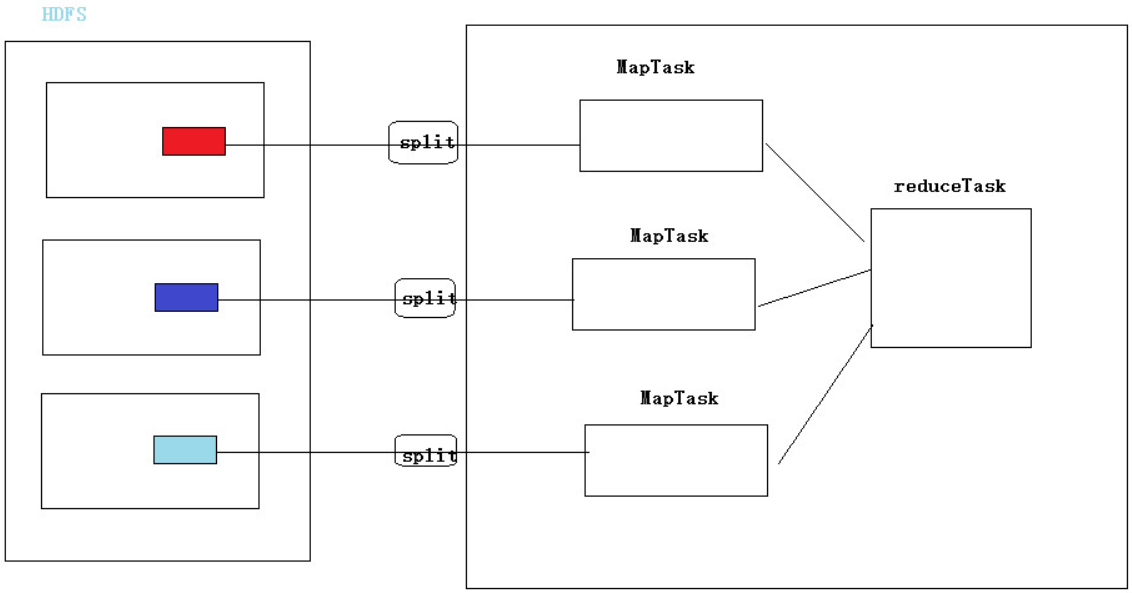
1.4 Map, Reduce, Split總結
2. MapReduce編程規範及示例
2.1 編程規範
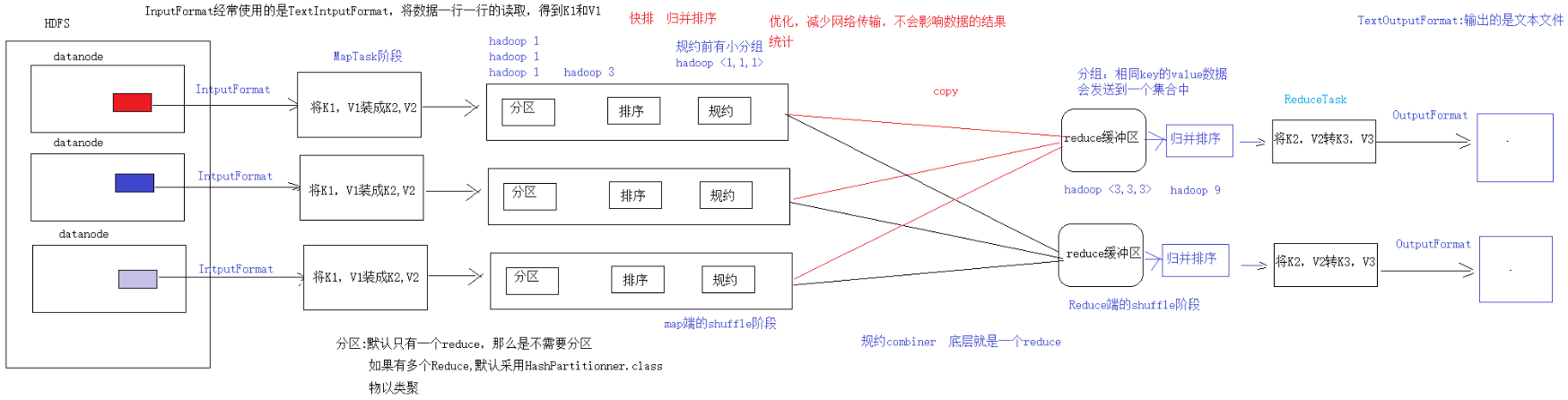
開發步驟一共8步
-
- MapTask階段2步
1) 設置InputFormat (通常使用TextInputFormat) 的類型和數據的路徑 -- 獲取數據的過程 (可以得到K1, V1) .
2) 自定義Mapper -- 將K1, V1轉為K2, V2.
-
- shuffle階段4步
3) 分區的動作, 如果有多個Reduce才去考慮分區, 預設只有一個Reduce, 分區可以省略.
4) 排序, 預設對K2進行排序 (字典序) -- 管好K2就行.
5) 規約, combiner是一個局部的Reduce, Map端的合併, 是對MR的優化操作, 不會影響任何結果, 減少網路傳輸, 預設可以省略.
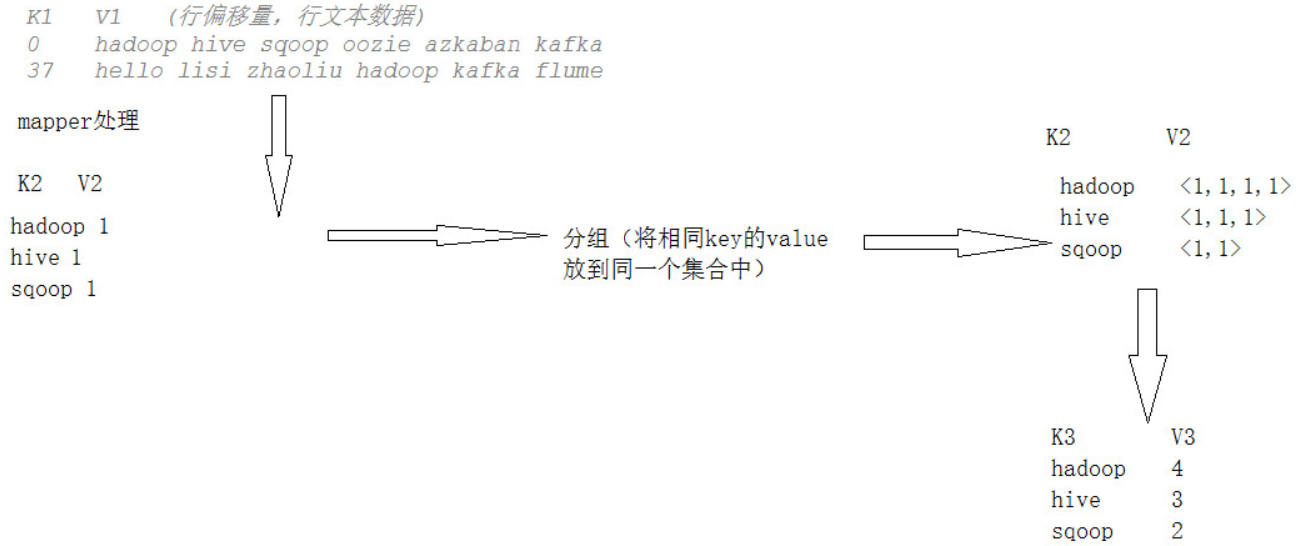
6) 分組, 相同的K (K2) 對應的V會放到同一個集合中 -- 將Map傳遞的K2, V2變成新的K2, V2.
-
- Reduce階段2步
7) 自定義Reducer得到K2, V2轉為K3, V3.
8) 設置OutputFormat和數據的路徑 -- 生成結果文件.
2.2 WordCount案例
3. MapReduce程式運行模式
3.1 本地運行模式
1) MR程式是被提交給LocalJobRunner在本地以單進程的形式運行.
2) 而處理的數據及輸出結果可以在本地文件系統, 也可以在HDFS上.
3) 怎麼樣實現本地運行? 寫一個程式, 不要帶集群的配置文件
本質是程式的conf中是否有mapreduce.framework.name=local以及yarn.resourcemanager.hostname參數
4) 本地模式非常便於進行業務邏輯的debug, 只要打斷點即可.
3.2 集群運行模式
1) 將MR程式提交給yarn集群, 分發到很多的節點上併發執行.
2) 處理的數據和輸出結果應該位於HDFS文件系統.
3) 提交集群的實現步驟:
將程式打成jar包, 然後在集群的任意一個節點上用Hadoop命令啟動:
hadoop jar wordcount.jar cn.itcast.mr.wordcount.WordCountRunner args
4. 深入MapReduce
4.1 MapReduce的輸入和輸出
MR框架運轉在<key, value>鍵值對上, 也就是說, 框架把作業的輸入看成是一組<key, value>鍵值對, 同樣也產生一組<key, value>鍵值對作為作業的輸出, 這兩組鍵值對可能是不同的.
一個MR作業的輸入和輸出類型如下圖所示: 可以看出在整個標準流程中, 會有三組<key, value>鍵值對類型的存在.

4.2 Mapper任務執行過程詳解
第一階段: 把輸入目錄下文件按照一定的標準逐個進行邏輯切片, 形成切片規劃. 預設情況下, Split size = Block size. 每一個切片由一個MapTask處理. (getSplits)
第二階段: 對切片中的數據按照一定的規則解析成<key, value>對. 預設規則是把每一行文本內容解析成鍵值對. key是每一行的起始位置 (單位是位元組) , value是本行的文本內容. (TextInputFormat)
第三階段: 調用Mapper類中的map方法, 上階段中每解析出來的一個<k, v>, 調用一次map方法. 每次調用map方法會輸出零個或多個鍵值對.
第四階段: 按照一定的規則對第三階段輸出的鍵值對進行分區. 預設是只有一個區. 分區的數量就是Reducer任務運行的數量. 預設只有一個Reducer任務.
第五階段: 對每個分區中的鍵值對進行排序. 首先, 按照鍵進行排序, 對於鍵相同的鍵值對, 按照值進行排序. 比如三個鍵值對<2, 2>, <1, 3>, <2, 1>, 鍵和值分別是整數. 那麼排序後的結果是<1, 3>, <2, 1>, <2, 2>. 如果有第六階段, 那麼進入第六階段, 如果沒有, 直接輸出到文件中.
第六階段: 對數據進行局部聚合處理, 也就是combiner處理. 鍵相等的鍵值對會調用一次reduce方法. 經過這一階段, 數據量會減少. 本階段預設是沒有的.
4.3 Reducer任務執行過程詳解
第一階段: Reducer任務會主動從Mapper任務複製其輸出的鍵值對. Mapper任務可能會有很多, 因此Reducer會複製多個Mapper的輸出.
第二階段: 把複製到Reducer本地數據, 全部進行合併, 即把分散的數據合併成一個大的數據. 再對合併後的數據排序.
第三階段: 對排序後的鍵值對調用reduce方法. 鍵相等的鍵值對調用一次reduce方法, 每次調用會產生零個或者多個鍵值對. 最後把這些輸出的鍵值對寫入到HDFS文件中.
在整個MR程式的開發過程中, 我們最大的工作是覆蓋map函數和覆蓋reduce函數.
5. MapReduce的序列化
5.1 概述
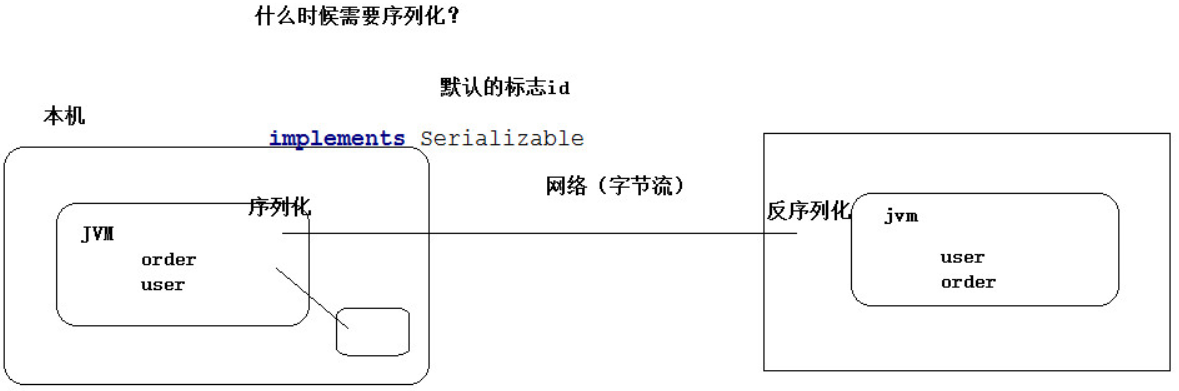
序列化是指把結構化對象轉化為位元組流.
反序列化是序列化的逆過程. 把位元組流轉化為結構化對象.
當要在進程間傳遞對象或持久化對象的時候, 就需要序列化對象成位元組流, 反之當要將接收到或從磁碟讀取的位元組流轉換成對象, 就要進行反序列化.
Java序列化是一個重量級序列化框架, 一個對象被序列化後, 會附帶很多額外的信息, 不便於在網路中高效傳輸. 所以, Hadoop自己開發了一套序列化機制 (Writable) , 不用像Java對象類一樣傳輸多層的父子關係, 需要哪個屬性就傳輸哪個屬性值, 大大的減少網路傳輸的開銷.
Writable是Hadoop的序列化格式, Hadoop定義了這樣一個Writable介面. 一個類要支持可序列化只需要實現這個介面即可.
public interface Wriable {
void wirte (DataOutput out) throws IOException;
void readFields (DataInput in) throws IOException;
}
5.2 Writable序列化介面
如需將自定義的bean放在key中傳輸, 則還需要實現comparable介面, 因為MR框中的shuffle過程一定會對key進行排序, 此時, 自定義的bean實現的介面應該是:
public class FlowBean implements WritableComparable<FlowBean>
compareTo方法用於將當前對象與方法的參數進行比較:
-
- 如果指定的數與參數相等返回 0
- 如果指定的數小於參數返回 -1
- 如果指定的數大於參數返回 1
例如: o1.compareTo(o2)
返回正數的話, 當前對象 (調用compareTo方法的對象o1) 要排在比較對象 (compareTo傳參對象o2) 後面, 返回負數的話, 放在前面.
6. MapReduce的排序初步
6.1 需求
在得出統計每一個用戶 (手機號) 所耗費的總上行流量, 下行流量, 總流量結果的基礎之上再加一個需求: 將統計結果按照總流量倒序排序.
6.2 分析
基本思路: 實現自定義的bean來封裝流量信息, 並將bean作為map輸出的key來傳輸.
MR程式在處理數據的過程中會對數據排序 (map輸出的kv對傳輸到reduce之前, 會排序), 排序的依據是map輸出的key. 所以, 我們如果要實現自己需要的排序規則, 則可以考慮將排序因素放到key中, 讓key實現介面: WritableComparable, 然後重寫key的compareTo方法.
7. MapReduce的分區Partitioner
7.1 需求
將流量彙總統計結果按照手機歸屬地不同省份輸出到不同文件中.
7.2 分析
Mapreduce中會將map輸出的kv對, 按照相同key分組, 然後分發給不同的reducetask.
預設的分發規則為: 根據key的hashcode%reducetask數來分發.
所以: 如果要按照我們自己的需求進行分組, 則需要改寫數據分發 (分組) 組件Partitioner, 自定義一個CustomPartitioner繼承抽象類: Partitioner, 然後在job對象中, 設置自定義partitioner: job.setPartitionerClass(CustomPartitioner.class) .
8. MapReduce的Combiner
每一個map都可能會產生大量的本地輸出, Combiner的作用就是對map端的輸出先做一次合併, 以減少在map和reduce節點之間的數據傳輸量, 以提高網路IO性能, 是MR的一種優化手段之一.
-
- Combiner是MR程式中Mapper和Reducer之外的一種組件.
- Combiner組件的父類就是Reducer.
- Combiner和reducer的區別在於運行的位置:
Combiner是在每一個maptask所在的節點運行.
Reducer是接收全局所有Mapper的輸出結果.
-
- Combiner的意義就是對每一個maptask的輸出進行局部彙總, 以減小網路傳輸量.
- 具體實現步驟:
1) 自定義一個combiner繼承Reducer, 重寫reduce方法
2) 在job中設置: job.setCombinerClass(CustomCombiner.class) .
-
- Combiner能夠應用的前提是不能影響最終的業務邏輯, 而且, Combiner的輸出kv應該跟reducer的輸入kv類型要對應起來.


