
一.索引介紹 1.什麼是索引 1)索引就好比一本書的目錄,它能讓你更快的找到自己想要的內容。 2)讓獲取的數據更有目的性,從而提高資料庫檢索數據的性能。 2.索引類型介紹 1)BTREE:B+樹索引 2)HASH:HASH索引 3)FULLTEXT:全文索引 4)RTREE:R樹索引 Btree索引 ...
一.索引介紹

1.什麼是索引
1)索引就好比一本書的目錄,它能讓你更快的找到自己想要的內容。
2)讓獲取的數據更有目的性,從而提高資料庫檢索數據的性能。
2.索引類型介紹
1)BTREE:B+樹索引
2)HASH:HASH索引
3)FULLTEXT:全文索引
4)RTREE:R樹索引
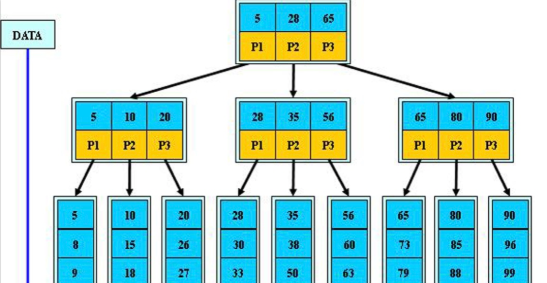
Btree索引
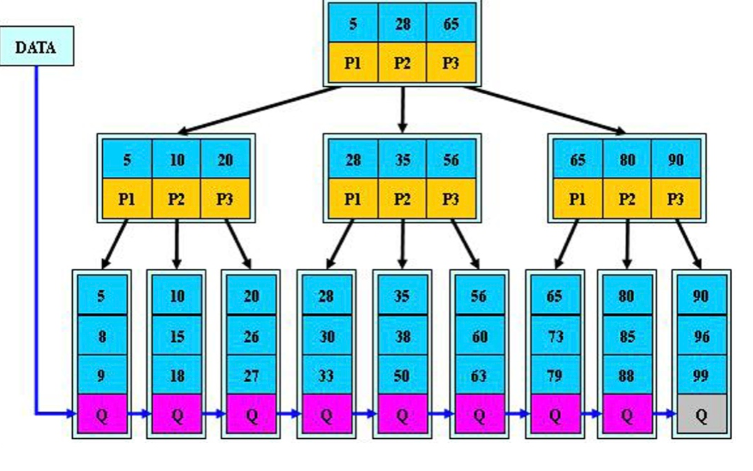
B+tree索引
- 優化了範圍查詢
- 在葉子節點添加了相鄰節點的指針
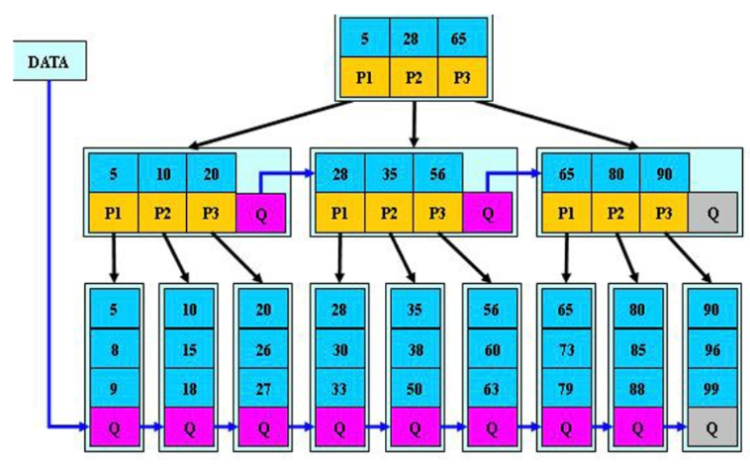
B*tree索引
在枝節點添加了相鄰節點的指針
3.索引管理
索引建立在表的列上(欄位)的。
在where後面的列建立索引才會加快查詢速度。
pages<---索引(屬性)<----查數據。
- 1、索引分類:
主鍵索引(primary key)
普通索引( index key)
唯一索引(unique key)
- 2、添加索引:
#創建索引
alter table test add index index_name(name);
#創建索引
create index index_name on test(name);
#查看索引
desc table;
show create table student;
#查看索引
show index from table;
#刪除索引
alter table test drop key index_name;
#添加主鍵索引
alter table test add primary key pri_id(id);
#添加唯一性索引
alter table student add unique key uni_xxx(xxx);如何判斷該列是否能創建==唯一鍵==
mysql> select count(cname) from course;
+----------+
| count(*) |
+----------+
| 3 |
+----------+
1 row in set (0.00 sec)
mysql> select count(distinct(cname)) from course;
+------------------------+
| count(distinct(cname)) |
+------------------------+
| 3 |
+------------------------+
1 row in set (0.00 sec)
- 3、首碼索引和聯合索引
首碼索引
根據欄位的前N個字元建立索引
alter table test add index idx_name(name(10));避免對大列建索引
如果有,就使用首碼索引
刪除索引
mysql> alter table course drop index cname1;聯合索引
多個欄位建立一個索引
例:
where a.女生 and b.身高 and c.體重 and d.身材好
index(a,b,c)
原則:把最常用來做為條件查詢的列放在最前面
#創建people表
create table people (id int,name varchar(20),age tinyint,money int ,gender enum('m','f'));
#創建聯合索引
alter table people add index idx_gam(gender,age,money);
alter table people add index xxxx_all(a,b,c,d);
select * from people where a b c d
a b c
a b
a c(部分走索引)
不走索引
b c d
c d
b c小結
1.不要在所有欄位上都創建索引
2.如果有需求欄位比較多,選擇聯合索引
3.如果有需求欄位數據比較大,選擇首碼索引
4.如果可以創建唯一索引,一定創建唯一索引
二.explain詳解
explain命令使用方法
mysql> explain select name,countrycode from city where id=1;explain命令應用
查詢數據的方式
1.全表掃描1)在explain語句結果中type為ALL
2)什麼時候出現全表掃描?
- 2.1 業務確實要獲取所有數據
- 2.2 不走索引導致的全表掃描
- 2.2.1 沒索引
- 2.2.2 索引創建有問題
- 2.2.3 語句有問題
生產中,mysql在使用全表掃描時的性能是極其差的,所以MySQL儘量避免出現全表掃描
- 2.索引掃描
2.1 常見的索引掃描類型:
1)index
2)range
3)ref
4)eq_ref
5)const
6)system
7)null
從上到下,性能從最差到最好,我們認為至少要達到range級別
index:Full Index Scan,index與ALL區別為index類型只遍歷索引樹。
range:索引範圍掃描,對索引的掃描開始於某一點,返回匹配值域的行。顯而易見的索引範圍掃描是帶有between或者where子句裡帶有<,>查詢。
mysql> alter table city add index idx_city(population);
mysql> explain select * from city where population>30000000;ref:使用非唯一索引掃描或者唯一索引的首碼掃描,返回匹配某個單獨值的記錄行。
mysql> alter table city drop key idx_code;
mysql> explain select * from city where countrycode='chn';
mysql> explain select * from city where countrycode in ('CHN','USA');
mysql> explain select * from city where countrycode='CHN' union all select * from city where countrycode='USA';eq_ref:類似ref,區別就在使用的索引是唯一索引,對於每個索引鍵值,表中只有一條記錄匹配,簡單來說,就是多表連接中使用primary key或者 unique key作為關聯條件A
join B
on A.sid=B.sidconst、system:當MySQL對查詢某部分進行優化,並轉換為一個常量時,使用這些類型訪問。
如將主鍵置於where列表中,MySQL就能將該查詢轉換為一個常量
mysql> explain select * from city where id=1000;NULL:MySQL在優化過程中分解語句,執行時甚至不用訪問表或索引,例如從一個索引列里選取最小值可以通過單獨索引查找完成。
mysql> explain select * from city where id=1000000000000000000000000000;Extra(擴展)
Using temporary
Using filesort 使用了預設的文件排序(如果使用了索引,會避免這類排序)
Using join buffer
如果出現Using filesort請檢查order by ,group by ,distinct,join 條件列上沒有索引
mysql> explain select * from city where countrycode='CHN' order by population;當order by語句中出現Using filesort,那就儘量讓排序值在where條件中出現
mysql> explain select * from city where population>30000000 order by population;
mysql> select * from city where population=2870300 order by population;key_len:(索引的長度) 越小越好
- 首碼索引去控制
rows:(遍歷的行數 ) 越小越好
三.建立索引的原則(規範)
為了使索引的使用效率更高,在創建索引時,必須考慮在哪些欄位上創建索引和創建什麼類型的索引。
那麼索引設計原則又是怎樣的?
- 1、選擇唯一性索引
唯一性索引的值是唯一的,可以更快速的通過該索引來確定某條記錄。
例如:
學生表中學號是具有唯一性的欄位。為該欄位建立唯一性索引可以很快的確定某個學生的信息。
如果使用姓名的話,可能存在同名現象,從而降低查詢速度。
主鍵索引和唯一鍵索引,在查詢中使用是效率最高的。
select count(*) from world.city;
select count(distinct countrycode) from world.city;
select count(distinct countrycode,population ) from world.city;註意:如果重覆值較多,可以考慮採用聯合索引
- 2.為經常需要排序、分組和聯合操作的欄位建立索引
例如:
經常需要ORDER BY、GROUP BY、DISTINCT和UNION等操作的欄位,排序操作會浪費很多時間。
如果為其建立索引,可以有效地避免排序操作
3.為常作為查詢條件的欄位建立索引
如果某個欄位經常用來做查詢條件,那麼該欄位的查詢速度會影響整個表的查詢速度。
因此,為這樣的欄位建立索引,可以提高整個表的查詢速度。
- 3.1 經常查詢
- 3.2 列值的重覆值少
註:如果經常作為條件的列,重覆值特別多,可以建立聯合索引
- 4.儘量使用首碼來索引
如果索引欄位的值很長,最好使用值的首碼來索引。例如,TEXT和BLOG類型的欄位,進行全文檢索
會很浪費時間。如果只檢索欄位的前面的若幹個字元,這樣可以提高檢索速度。
----------------------------------------------------------------------------- 我是華麗的分割線 --------------------------------------------------
- 5.限制索引的數目
索引的數目不是越多越好。每個索引都需要占用磁碟空間,索引越多,需要的磁碟空間就越大。
修改表時,對索引的重構和更新很麻煩。越多的索引,會使更新表變得很浪費時間。 - 6.刪除不再使用或者很少使用的索引
表中的數據被大量更新,或者數據的使用方式被改變後,原有的一些索引可能不再需要。資料庫管理
員應當定期找出這些索引,將它們刪除,從而減少索引對更新操作的影響。
---------------------------------------------------------------------------- 是的,沒錯,又是我 --------------------------------------------
重點關註:
- 1.沒有查詢條件,或者查詢條件沒有建立索引
#全表掃描
select * from table;
select * from tab where 1=1;在業務資料庫中,特別是數據量比較大的表,是沒有全表掃描這種需求。
1)對用戶查看是非常痛苦的。
2)對伺服器來講毀滅性的。
3)SQL改寫成以下語句:
#情況1
#全表掃描
select * from table;
#需要在price列上建立索引
selec * from tab order by price limit 10;
#情況2
#name列沒有索引
select * from table where name='zhangsan';
1、換成有索引的列作為查詢條件
2、將name列建立索引- 2.查詢結果集是原表中的大部分數據,應該是25%以上
mysql> explain select * from city where population>3000 order by population;1)如果業務允許,可以使用limit控制。
2)結合業務判斷,有沒有更好的方式。如果沒有更好的改寫方案就儘量不要在mysql存放這個數據了,放到redis裡面。
3.索引本身失效,統計數據不真實
索引有自我維護的能力。
對於表內容變化比較頻繁的情況下,有可能會出現索引失效。
重建索引就可以解決4.查詢條件使用函數在索引列上或者對索引列進行運算,運算包括(+,-,*等)
#例子
錯誤的例子:select * from test where id-1=9;
正確的例子:select * from test where id=10;- 5.隱式轉換導致索引失效.這一點應當引起重視.也是開發中經常會犯的錯誤
mysql> create table test (id int ,name varchar(20),telnum varchar(10));
mysql> insert into test values(1,'zs','110'),(2,'l4',120),(3,'w5',119),(4,'z4',112);
mysql> explain select * from test where telnum=120;
mysql> alter table test add index idx_tel(telnum);
mysql> explain select * from test where telnum=120;
mysql> explain select * from test where telnum=120;
mysql> explain select * from test where telnum='120';- 6. <> ,not in 不走索引
mysql> select * from tab where telnum <> '1555555';
mysql> explain select * from tab where telnum <> '1555555';單獨的>,<,in 有可能走,也有可能不走,和結果集有關,儘量結合業務添加limit
or或in儘量改成union (去重) + all (不去重)
EXPLAIN SELECT * FROM teltab WHERE telnum IN ('110','119');
#改寫成
EXPLAIN SELECT * FROM teltab WHERE telnum='110'
UNION ALL
SELECT * FROM teltab WHERE telnum='119'- 7.like "%_" 百分號在最前面不走,後面用limit優化,前面Elasticsearch
#走range索引掃描
EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '31%';
#不走索引
EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '%110';%linux%類的搜索需求,可以使用Elasticsearch -------> ELK
- 8.單獨引用聯合索引里非第一位置的索引列
CREATE TABLE t1 (id INT,NAME VARCHAR(20),age INT ,sex ENUM('m','f'),money INT);
ALTER TABLE t1 ADD INDEX t1_idx(money,age,sex);
DESC t1
SHOW INDEX FROM t1
#走索引的情況測試
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money=30 AND age=30 AND sex='m';
#部分走索引
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money=30 AND age=30;
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money=30 AND sex='m';
#不走索引
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE age=20
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE age=30 AND sex='m';
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE sex='m';補充: 若出現慢查詢,怎麼辦
1.有沒有創建索引
2.查看數據類型,和查詢語句是否一致,
3.查詢語句中是否使用欄位做用算
4.查詢出來的結果集很大,limit
5.查詢語句中是否使用<>或者not in
6.查詢語句是否使用模糊查詢,且'%*'在前面
7.如果使用聯合索引,請安裝創建索引的順序
8.索引損壞

