
垃圾收集GC(Garbage Collection)是Java語言的核心技術之一, 在Java中,程式員不需要去關心記憶體動態分配和垃圾回收的問題,這一切都交給了JVM來處理。 一. jvm的記憶體結構 垃圾回收都是基於記憶體去回收的,因此,先要對記憶體結構有一個大概的瞭解 Java記憶體運行時區域大概分了三 ...
垃圾收集GC(Garbage Collection)是Java語言的核心技術之一, 在Java中,程式員不需要去關心記憶體動態分配和垃圾回收的問題,這一切都交給了JVM來處理。
一. jvm的記憶體結構
垃圾回收都是基於記憶體去回收的,因此,先要對記憶體結構有一個大概的瞭解

Java記憶體運行時區域大概分了三部分
- 其中PC寄存器、java虛擬機棧、本地方法棧3個區域是所有線程獨有的一塊區域,隨線程而生,隨線程而滅。棧中的棧幀隨著方法的進入和退出而有條不紊地執行著入棧和出棧操作。每一個棧幀中分配多少記憶體基本上是在類結構確定下來時就已知的,因此這幾個區域的記憶體分配和回收都具備確定性,在這幾個區域內就不需要過多考慮回收的問題,因為方法結束或者線程結束,記憶體自然就跟隨著回收了。
- 而Java堆和方法區則不一樣,一個介面中的多個實現類需要的記憶體可能不一樣,一個方法中的多個實現類需要的記憶體可能不一樣,一個方法中的多個分支需要的記憶體也可能不一樣,只有在程式處於運行期間時才能知道會創建哪些對象,這部分記憶體的分配和回收是動態的,垃圾收集關註的是這部分的記憶體。
二. 記憶體分配
在解垃圾回收之前,得先瞭解JVM是怎麼分配記憶體的,然後識別哪些記憶體是垃圾需要回收,最後才是用什麼方式回收。
Java的記憶體分配原理與C/C++不同,C/C++每次申請記憶體時都要malloc進行系統調用,而系統調用發生在內核空間,每次都要中斷進行切換,這需要一定的開銷,而Java虛擬機是先一次性分配一塊較大的空間,然後每次new時都在該空間上進行分配和釋放,減少了系統調用的次數,節省了一定的開銷,這有點類似於記憶體池的概念;二是有了這塊空間過後,如何進行分配和回收就跟GC機制有關了。
三. 垃圾檢測(標記)演算法
什麼樣的對象才是垃圾?
如果一個對象沒有被其他對象所引用該對象就是無用的,此對象就被稱為垃圾,其占用的記憶體也就要被銷毀。那麼自然而然的就引出了我們的第二個問題,判斷對象為垃圾的演算法都有哪些?
標記垃圾的演算法
Java中標記垃圾的演算法主要有兩種, 引用計數法和可達性分析演算法。我們首先來介紹引用計數法。
-
引用計數法
引用計數法就是給對象中添加一個引用計數器,每當有一個地方引用它,計數器就加 1;當引用失效,計數器就減 1;任何時候計數器為 0 的對象就是不可能再被使用的,可以當做垃圾收集。這種方法實現起來很簡單而且優缺點都很明顯。
-
-
優點 執行效率高,程式執行受影響較小
-
缺點 無法檢測出迴圈引用的情況,導致記憶體泄露
-
什麼是迴圈引用呢?
假設有A和B兩個對象之間互相引用,也就是說A對象中的一個屬性是B,B中的一個屬性時A,這種情況下由於他們的相互引用
我們舉一個簡單的例子。
public class MyObject { public MyObject childNode; } public class ReferenceCounterProblem { public static void main(String[] args) { MyObject object1 = new MyObject(); MyObject object2 = new MyObject(); object1.childNode = object2; object2.childNode = object1; } }
- 可達性分析
可達性分析基本思路是把所有引用的對象想象成一棵樹,從樹的根結點 GC Roots 出發,持續遍歷找出所有連接的樹枝對象,這些對象則被稱為“可達”對象,或稱“存活”對象。不能到達的則被可回收對象。
下麵這張圖就是可達性分析的描述:

我們發現,GC Roots 本身是一個出發點,也就是說我們每次進行可達性分析的時候都要從這個初始點出發。換句話說,初始點我們一定是可達的。那麼,Java 里有哪些對象可以作為GC Roots呢?主要有以下四種:
- 虛擬機棧(幀棧中的本地變數表)中引用的對象。
- 方法區中靜態屬性引用的對象。
- 方法區中常量引用的對象。
- 本地方法棧中 JNI 引用的對象。
總之,JVM在做垃圾回收的時候,會檢查堆中的所有對象是否會被這些根集對象引用,不能夠被引用的對象就會被垃圾收集器回收。
四. 垃圾收集(回收)演算法
已經能夠確定那些對象可以被視為垃圾了。下麵我們可以分析一下,如何去回收這些垃圾,同樣的,有一系列演算法。首先我們定義一個規則確定那些是垃圾、存活對象、空白空間

垃圾收集演算法有四種:
- 標記-清除演算法
- 標記-整理演算法
- 複製演算法
- 分代收集演算法
1、標記-清理
第一步(標記),利用可達性遍歷記憶體,把“存活”對象和“垃圾”對象進行標記。第二步(清理),我們再遍歷一遍,把所有“垃圾”對象所占的空間直接 清空 即可。
結果如下:

特點:
- 簡單方便
- 容易產生記憶體碎片
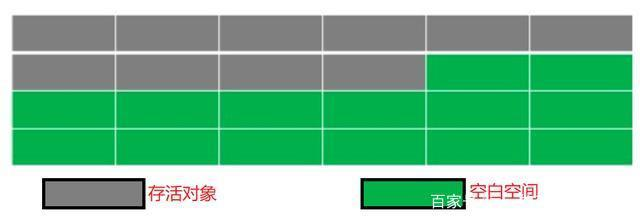
2、標記-整理
上面的方法我們發現會產生記憶體碎片,因此在這個方法中同樣為兩步:
第一步(標記):利用可達性遍歷記憶體,把“存活”對象和“垃圾”對象進行標記。
第二步(整理):把所有存活對象堆到同一個地方,這樣就沒有記憶體碎片了。
結果如下:
特點:
- 適合存活對象多,垃圾少的情況
- 需要整理的過程
3、複製
將記憶體按照容量劃分為大小相等的兩塊,每次只使用其中的一塊。當這一塊用完了,就將還活著的對象複製到另一塊上,然後再把使用過的記憶體空間一次性清理掉
過程如下:

特點:
- 簡單
- 不會產生碎片
- 記憶體利用率太低,只用了一半
4、分代收集演算法
java中的垃圾回收大致在兩部分,第一個就是堆、第二個就是方法區。為此先看方法區是如何進行垃圾回收的。
1、方法區的垃圾回收
方法區又叫做永久代。永久代的垃圾回收主要有兩部分:廢棄常量和無用的類。
- 廢棄常量
第一步:判定一個常量是否是廢棄常量:沒有任何一個地方對這個常量進行引用就表示是廢棄常量。
第二步:垃圾回收
- 無用的類
第一步:判定一個類是否是“無用的類”:需要滿足下麵三個條件:
-
-
- Java堆中不存在該類的任何實例,也就是該類的所有實例都被回收
- 載入該類的ClassLoader已經被回收
- 該類對應的Class對象在任何地方沒有引用了,也不能通過反射訪問該類的方法。
-
第二步:滿足上面三個條件就可以回收了,但不是強制的。
註意:《java虛擬機規範》裡面曾經說到過,不要求虛擬機對方法區進行垃圾回收。而且方法區進行垃圾回收性價比比較低。
2、Java 堆的垃圾回收:
先來看一下 Java 堆的結構。

Java 堆空間分成了三部分,這三部分用來存儲三類數據:
- 剛剛創建的對象。
- 存活了一段時間的對象。
- 永久存在的對象。
也就是說,常規的 Java 堆至少包括了 新生代 和 老年代 兩塊記憶體區域,而且這兩塊區域有很明顯的特征:
- 新生代:存活對象少、垃圾多
- 老年代:存活對象多、垃圾少
針對這種特點,我們有以下兩種方案;
(1)新生代-複製 回收機制
對於新生代區域,由於每次 GC 都會有大量新對象死去,只有少量存活。因此採用 複製 回收演算法,GC 時把少量的存活對象複製過去即可。但是從上面我們可以看到,新生代也劃分了三個部分比例:Eden:S1:S2=8:1:1。
“其中 Eden 意為伊甸園,形容有很多新生對象在裡面創建;S1和S2中的S表示Survivor,為幸存者,即經歷 GC 後仍然存活下來的對象。”
工作原理如下:
1. 首先,Eden對外提供堆記憶體。當 Eden區快要滿了,觸發垃圾回收機制,把存活對象放入 Survivor A 區,清空 Eden 區;
2. Eden區被清空後,繼續對外提供堆記憶體;
3. 當 Eden 區再次被填滿,對 Eden區和 Survivor A 區同時進行垃圾回收,把存活對象放入 Survivor B區,同時清空 Eden 區和Survivor A 區;
4. 當某個 Survivor區被填滿,把多餘對象放到Old 區;
5. 當 Old 區也被填滿時,進行 下一階段的垃圾回收。
(2)老年代-標記整理 回收機制
老年代的特點是:存活對象多、垃圾少。因此,根據老年代的特點,這裡僅僅通過少量地移動對象就能清理垃圾,而且不存在記憶體碎片化。也就是標記整理的回收機制。既然是標記整理演算法,而且老年代內部也不存在著記憶體劃分,所以只需要根據標記整理的具體步驟進行垃圾回收就好了。
五. 垃圾回收器
如果說收集演算法是記憶體回收的方法論,那麼垃圾收集器就是記憶體回收的具體實現。
在瞭解 垃圾回收器之前,首先得瞭解一下垃圾回收器的幾個名詞。
1. 吞吐量
CPU 用於運行用戶代碼的時間與 CPU 總消耗時間的比值。比如說虛擬機總運行了 100 分鐘,用戶代碼時間 99 分鐘,垃圾回收 時間 1 分鐘,那麼吞吐量就是 99%。
2. 停頓時間
停頓時間 指垃圾回收器正在運行時,應用程式 的 暫停時間。
3. GC的名詞
新生代GC:Minor GC
老年代GC:Major GC
4. 併發與並行
(1)串列(Parallel)
垃圾回收線程 進行垃圾回收工作,但此時 用戶線程 仍然處於 等待狀態。
(2)併發(Concurrent)
這裡的併發指 用戶線程 與 垃圾回收線程 交替執行。
(3)並行(Parallel)
這裡的並行指 用戶線程 和多條 垃圾回收線程 分別在不同 CPU 上同時工作。
下麵其中垃圾回收器是基於HotSpot虛擬機。先給一張圖看一下
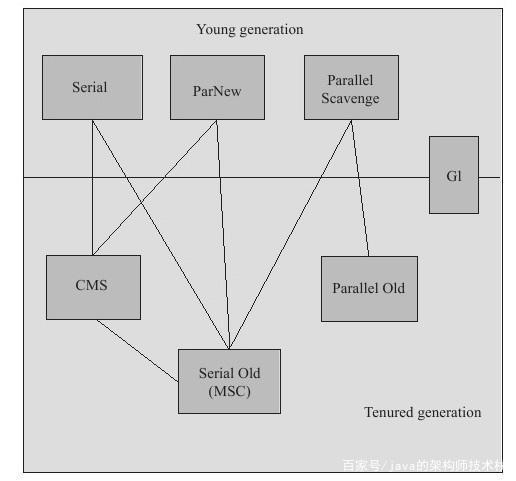
在 JVM 中,具體實現有 Serial、ParNew、Parallel Scavenge、CMS、Serial Old(MSC)、Parallel Old、G1 等。在上圖中,你可以看到 不同垃圾回收器 適合於 不同的記憶體區域,如果兩個垃圾回收器之間 存在連線,那麼表示兩者可以 配合使用。
下麵對這其中垃圾回收器有一個瞭解。
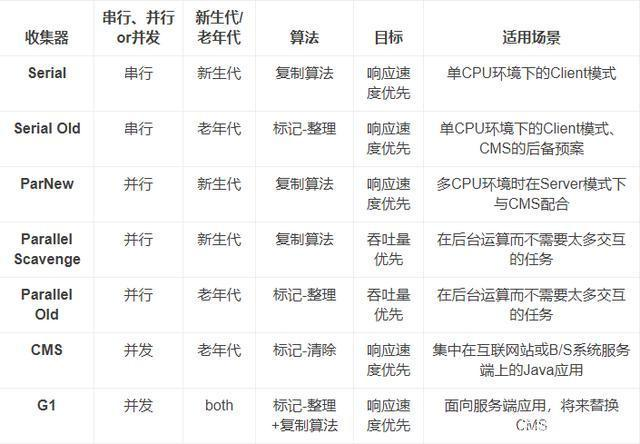
第一種:Serial(單線程)
Serial 回收器是最基本的 新生代垃圾回收器,是單線程的垃圾回收器。採用的是 複製演算法。垃圾清理時,Serial回收器不存線上程間的切換,因此,在單 CPU` 的環境下,垃圾清除效率比較高。
第二種:Serial Old(單線程)
Serial Old回收器是 Serial回收器的老生代版本,單線程回收器,使用 標記-整理演算法。在 JDK1.5 及其以前,它常與Parallel Scavenge回收器配合使用,達到較好的吞吐量,另外它也是 CMS 回收器在Concurrent Mode Failure時的後備方案。
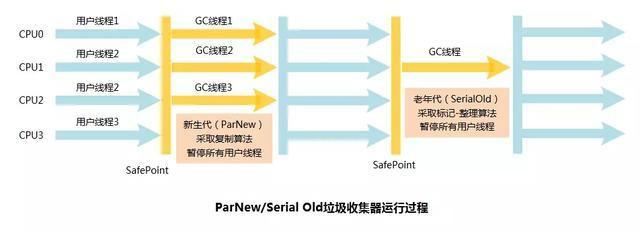
第三種:ParNew(多線程)
ParNew回收器是在Serial回收器的基礎上演化而來的,屬於Serial回收器的多線程版本,採用複製演算法。運行在新生代區域。在實現上,兩者共用很多代碼。在不同運行環境下,根據CPU核數,開啟不同的線程數,從而達到最優的垃圾回收效果。
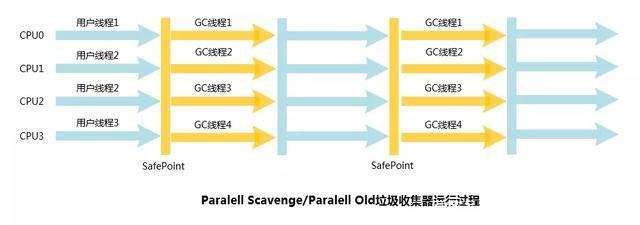
第四種:Parallel Scavenge(多線程)
Parallel Scavenge回收器也是運行在新生代區域,屬於多線程的回收器,採用複製演算法。與ParNew不同的是,ParNew回收器是通過控制垃圾回收的線程數來進行參數調整,而Parallel Scavenge回收器更關心的是程式運行的吞吐量。即一段時間內用戶代碼運行時間占總運行時間的百分比。
第五種:Parallel Old(多線程)
Parallel Old回收器是Parallel Scavenge回收器的老生代版本,屬於多線程回收器,採用標記-整理演算法。Parallel Old回收器和Parallel Scavenge回收器同樣考慮了吞吐量優先這一指標,非常適合那些註重吞吐量和CPU資源敏感的場合。
第六種:CMS(多線程回收)
CMS回收器是在最短回收停頓時間為前提的回收器,屬於多線程回收器,採用標記-清除演算法。
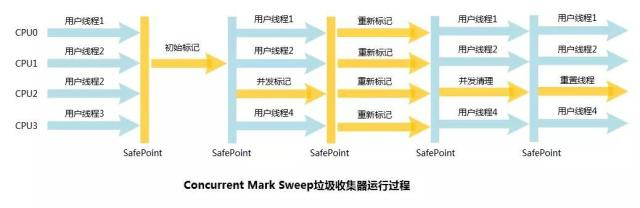
第七種:G1回收器
G1是 JDK 1.7中正式投入使用的用於取代CMS的壓縮回收器。它雖然沒有在物理上隔斷新生代與老生代,但是仍然屬於分代垃圾回收器。G1仍然會區分年輕代與老年代,年輕代依然分有Eden區與Survivor區。
G1首先將堆分為大小相等的 Region,避免全區域的垃圾回收。G1的分區示例如下圖所示:
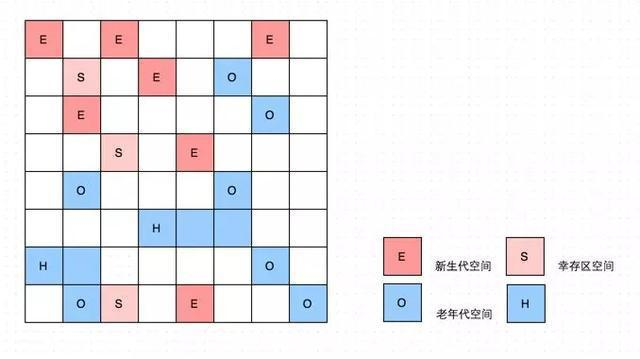
這種使用區域劃分記憶體空間以及有優先順序的區域回收方式,保證G1回收器在有限的時間內可以獲得儘可能高的回收效率。
下麵對這幾種垃圾回收機制進行一個總結:
參考:https://baijiahao.baidu.com/s?id=1636852721632353675&wfr=spider&for=pc


