
模塊安裝 Windows 安裝scrapy 需要安裝依賴環境twisted,twisted又需要安裝C++的依賴環境 pip install scrapy 時 如果出現twisted錯誤 在https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下載對應的Twiste ...
模塊安裝
Windows
安裝scrapy 需要安裝依賴環境twisted,twisted又需要安裝C++的依賴環境
pip install scrapy 時 如果出現twisted錯誤
在https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下載對應的Twisted的版本文件(cp36代表python3.6版本)

再cmd進入到Twisted所在的目錄 執行pip install 加Twisted文件名
最後執行pip install scrapy
Ubuntu安裝註意事項
不要使用 python-scrapyUbuntu提供的軟體包,它們通常太舊而且速度慢,無法趕上最新的Scrapy
要在Ubuntu(或基於Ubuntu)系統上安裝scrapy,您需要安裝這些依賴項
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
如果你想在python3上安裝scrapy,你還需要Python3的開發頭文件
sudo apt-get install python3-dev
在virtualenv中,你可以使用pip安裝Scrapy:pip install scrapy
簡單使用
新建項目
scrapy startproject project_name
編寫爬蟲
第一種方式:創建單個文件
創建一個類,它必須繼承scrapy.Spider類,需要定義三個屬性
name: spider的名字,必須且唯一
start_urls: 初始的url列表
parse(self, response) 方法:每個初始url完成之後被調用
這個parse函數要完成兩個功能
1、解析響應,封裝成item對象並返回這個對象
2、提取新的需要下載的url,創建新的request,並返回它
單個文件的運行命令 scrapy runspider demo.py
第二種方式:通過命令創建
scrapy genspider 爬蟲名 功能變數名稱
運行爬蟲
scrapy list 查看可以運行的爬蟲文件
scrapy crawl 爬蟲名(name屬性的值)
追蹤鏈接
創建一個類變數page_num用來記錄當前爬取到的頁碼,在parse函數中提取信息,然後通過爬蟲對象給變數page__num自加1,構造下一頁的url,然後創建scrapy.Request對象並返回
如果response中提取不到信息,我們判斷已經到了最後一頁,parse函數直接return結束
定義item管道
parse函數在解析出我們需要的信息之後,可以將這些信息打包成一個字典對象或scray.Item對象,然後返回
這個對象會被髮送到item管道,該管道會通過順序執行幾個組件處理它。每個item管道組件是一個實現簡單方法的Python類
它們收到一個item並對其執行操作,同時決定該item是否應該繼續通過管道或者被丟棄並且不再處理
item管道的典型用途:
清理HTML數據
驗證已刪除的數據(檢查項目是否包含某些欄位)
檢查重覆項(並刪除它們)
將已爬取的item進行數據持久化
編寫管道類
#在爬蟲啟動時執行 def open_ spider(self, spider)
#在爬蟲關閉時,執行 def close_ spider(self, spider)
#對傳遞過來的item處理並return處理完的item def process_ item(self, item, spider)
要激活這個管道組件,必須將其添加到ITEM_PIPELINES設置中,在settings文件中設置
在此設置中為類分配的整數值決定了它們運行的順序:按照從較低值到較高值的順序進行
定義item
Scrapy提供了Item類
編輯項目目錄下的items.py文件
在爬蟲中導入我們定義的Item類,實例化後用它進行數據結構化
運行流程
數據流
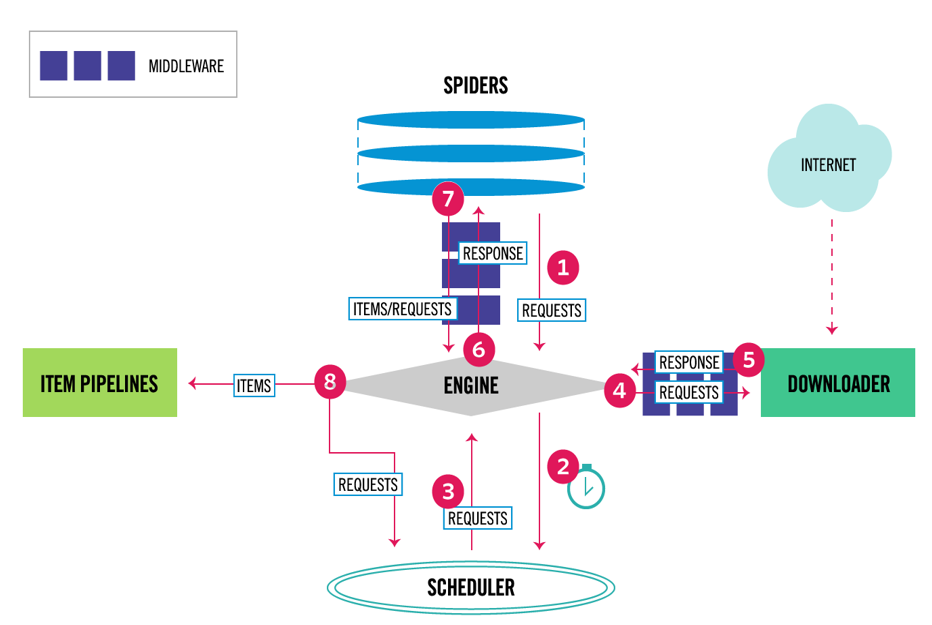
首先從爬蟲獲取初始的請求
將請求放入調度模塊,然後獲取下一個需要爬取的請求
調度模塊返回下一個需要爬取的請求給引擎
引擎將請求發送給下載器,依次穿過所有的下載中間件
一旦頁面下載完成,下載器會返回一個響應包含了頁面數據,然後再依次穿過所有的下載中間件
引擎從下載器接收到響應,然後發送給爬蟲進行解析,依次穿過所有的爬蟲中間件
爬蟲處理接收到的響應,然後解析出item和生成新的請求,併發送給引擎
引擎將已經處理好的item發送給管道組件,將生成好的新的請求發送給調度模塊,並請求下一個請求
該過程重覆,直到調度程式不再有請求為止
組件
spiders 爬蟲程式 處理response 提取需要的數據 或其他要抓取的請求
engine 引擎 引擎負責控制系統所有組件之間的數據流,併在發生某些操作時觸發事件
scheduler調度器 接收request請求 排隊加入隊列
download下載器 負責引擎發送過來的request請求 進行下載
item pipelines 管道 負責spider返回的數據 進行存儲
中間件
下載中間件
下載中間件是位於引擎和下載器之間的特定的鉤子,它們處理從引擎傳遞到下載器的請求,以及下載器傳遞到引擎的響應
使用Downloader中間件執行以下操作
在請求發送到下載程式之前處理請求(即在scrapy將請求發送到網站之前)
在響應發送給爬蟲之前
直接發送新的請求,而不是將收到的響應傳遞給蜘蛛
將響應傳遞給爬行器而不獲取web頁面
默默的放棄一些請求
爬蟲中間件
爬蟲中間件是位於引擎和爬蟲之間的特定的鉤子,能夠處理傳入的響應和傳遞出去的item和請求
使用爬蟲中間件執行以下操作
處理爬蟲回調之後的 請求或item
處理start_requests
處理爬蟲異常
根據響應內容調用errback而不是回調請求
事件驅動的網路
scrapy是用Twisted編寫的,Twisted是一個流行的事件驅動的Python網路框架。它使用非阻塞(也稱為非同步)代碼實現併發


