
[TOC] 說明 aaa,又是忙碌而鹹魚的一個月,期間給我的vim配置上了一堆超棒的插件(比如nerdtree,ctags,airline,markdown,etc.),然後有配置了vscode,還用make快樂地實現了奇奇怪怪的功能,本來都寫了一部分了,最後還是沒時間放棄了悲しいです55555 然 ...
目錄
說明
aaa,又是忙碌而鹹魚的一個月,期間給我的vim配置上了一堆超棒的插件(比如nerdtree,ctags,airline,markdown,etc.),然後有配置了vscode,還用make快樂地實現了奇奇怪怪的功能,本來都寫了一部分了,最後還是沒時間放棄了悲しいです55555
然後為了省事直接用英文寫了實驗報告,一如既往的懶得改直接發好了。
(申明:This is the report for pa2 by 曾許曌秋,DII,Nanjing University on Nov 4,2019)
Report for PA 2(writed with vim)
Part i - pa2.1
Pa2.1 just need to realize 5 instr, namely sub,xor,push,call,ret
Since the code frame has done enough and git-book notes provide detailed instruction
It's absolutely easy to realize (with the help of ctags & find|xargs grep)Really recommend ctags(really convenient to understand related codes in a short time)
Steps:
For each instr, mainly(at least as a matter of fact) 4 steps are needed:
1. Fill in opcode_table in /isa/exec/exec.c using macros defined in include/cpu/exec.h:
#define IDEXW(id, ex, w) {concat(decode_, id), concat(exec_, ex), w}
#define IDEX(id, ex) IDEXW(id, ex, 0)
#define EXW(ex, w) {NULL, concat(exec_, ex), w}
#define EX(ex) EXW(ex, 0)
#define EMPTY EX(inv)Each instr in the opcode_table is defined in the form of struct OpcodeEntry which including 2 function pointer(indicating decode-heper func & exec-helper func) and width
When exec_once called, it will first set seq_pc to pc,and call x86 to execute one instr,and then, after finishing, update cpu.pc
For x86, it will dynamically read the instr(i.e. read each part of the instr part by part and update seq_pc every time) and interpret it in the global struct decinfo(such a struct is well organized to different cases)For the first byte,it will store it and use it to find out what-to-do next in the opcode_table.
First set all width(for a large part of instr, 0x66-prefix suggest a width=2 instr, for such instr, opcode_table first set the width to '0' and decide the width by checking decinfo.isa.is_operand_code_16)
then x86 will use the 2 func-pointer obtained to execute decode-helper and exec-helper func separately.
2. Realize decode part with the help of DHeper & DopHeper(decode oprand)
Such kind of multi-level decoding is of significance by making codes easy to read & modify.
Btw most hard part of decoding (ModR/M & SIB) has already been realized.
The only difficulty is deciding which decoding-helper and dop-helper to use
It appears that the best way to find it is searching the key-word and getting familiar to all the x86codes for addressing methodin the appendix-A i386 manual
Codes used(already) including:
- E: ModR/M(reg/opcode -> extent_opcode by default)
- (S)I: (Signed)Imm
- r: register of course
J: offset(jmp as an exam)
Also some instr share the same opcode with different opcode_extent in the reg/opcode field of ModR/M(add & sub for instance)
Code frame realize such instr effectively by making groups(define group EHelper func at the same time)
3. Realize exec part by calling rtl_ & pseudo rtl_ funcs
The code-frame has already realized a great many rtl(short for Register-transfer level) & isa-related funcs.
And most instr can be easily realized by calling them.
Such funcs can be classified as below:
- vaddr_write & vaddr_read :read from or write into particular addr;
rtl_func:
rtl_funcs are all declared by macros in thenemu/include/rtl/rtl-wrapper.h.
such funcs can be devided into 3 part:
- pseude rtl_funcs: realize logic and arithmetic instr(call c_funcs by macros as a matter of fact) defined in
nemu/include/rtl/c_op.h.- rtl_funcs that is not related to isa: defined in
nemu/include/rtl/rtl.h- ftl_funcs related to isa: defined in
include/isa/rtl.h
4. Add exec-func realized to all-instr.h
As a matter of fact, the code-frame realize part of checking if we have realize some particular function by asserting a TODO() func which have an
assert(0)inside.
Therefore, the code-frame only declare and call funcs that have already been realized by adding them to theall-instr.hand includingall-instr.hintoexec.c.
instr(seperately)
0. mov r/m32,r32 & mov r/m32,imm32
Already realized
1. call simm32
Opcode 0xe8 followed with a signed imm indicating the displacement raletive to the addr of next instr.
First call DHelper(J) which will call DopHelper(SI) to fetch the signed imm and then calculate the jmp_pc(jmp addr)
In EHelper(call) call rtl_push to push seq_pc(addr of next instr),and then update seq_pc which will change cpu.pc at update_pc level.
rtl_push & rtl pop can be easily realized using vaddr_ funcs mentioned before:
(push):
cpu.esp=cpu.esp-4;
vaddr_write(cpu.esp,*src1,4);
(pop):
*dest=vaddr_read(cpu.esp,4);
cpu.esp=cpu.esp+4;2. push r32 & push m32
Since rtl_push has already been realized as mentioned before, we just need call proper decode & exec funcs according to instr form.
3. (/5) sub r/m32 imm8
Before we start,let's talk about the ModR/M byte:
Here is the struct of ModR/M byte:(notice Little Endian)
+-----------+------------------+-----------+
| (2bit)mod | (3bit)Reg/Opcode | (3bit)R/M |
+-----------+------------------+-----------+As is clearly illustrated above, ModR/M includes 3 field,:
mod field decide whethe R/M explained as Regisiter number or memory info, to be more specific, if and only if mod==0b11(3),R/M will be recognized as Register number(0-7)
Reg/Opcode indicate either a register number or extend for the opcode(decided by the opcode).
To, even more clearly, illustrate how it works, let's take ec(83 ec 14) as an example:
+----+--------+-----+
| 11 | 10 1 | 100 |
+----+--------+-----+
0b11: indicate r/m(dest operand) is a register
0b101: for opcode83 0b101 is an extend of opcode, indicating this is sub instr(0b000 indicate add instr)
0b100: as is mentioned above, it's a reg-num, i.e.%espThis instr is kind of difficult compared with other ones. However, the most difficult part--decoding the ModR/M byte has already been realized in
decode/modrm.cand the only thing we are supposed to do is RTFSC.
read_ModR_M's function prototype is:
void read_ModR_M(vaddr_t *pc, Operand *rm, bool load_rm_val, Operand *reg, bool load_reg_val) {This function will first fetch the ModR/M byte into an amazing struct ModR_M realized by union.
typedef union {
struct {
uint8_t R_M :3;
uint8_t reg :3;
uint8_t mod :2;
};
struct {
uint8_t dont_care :3;
uint8_t opcode :3;
};
uint8_t val;
} ModR_M;With such a struct, we can easily fetch any field of ModR/M byte by calling different member of ModR_M and fit different code(same RodM/R may have different explaination with different opcode) at the same time.
And right after fetching the byte, read_ModR_M func mainly do the following:
- write the reg/opcode into decinfo.isa.ext_opcode regardless of how to explain such field.
- if the
regargument is not NULL, decode the reg/opcode as a reg number load value to reg->val ifload_reg_val==true(may be used in later calculation).if mod==
0b11, explain R/M field as a reg-num, then decode it intormand decide whether load the relevant val or not according toload_rm_val, else call load_addr to load addr(explain R/M as addr)
Understanding the code, we can finish this instr by call proper Helper funcs.
And here the code-frame does another smart thing:First assign all width to 2/4(according to opcode-prefix 0x66) in the set_width func
Next assign src(simm8) width to 1 and fetch it into 4 byte varible(i.e. signed-extension here)
Lastly, if it's a 16bit instr, &=0xffff
And in the exec step, code frame use c_ func mentioned before to realize relevant rtl_func, we just need to call the func and write the result to relevant addr according to dest->type with switch:
rtl_sub(&id_dest->val,&id_dest->val,&id_src->val);
switch(id_dest->type){
case OP_TYPE_REG:
rtl_sr(id_dest->reg,&id_dest->val,id_dest->width);break;
case OP_TYPE_MEM:
vaddr_write(id_dest->addr,id_dest->val,id_dest->width);break;
default: assert(0);
}4. (/r) xor r/m32 r32
Similar to sub instr, xor also indicate a ModR/M. And the difference is that
/rindicate reg/opcode field will be considered as a reg-num(compared with sub indicate opcode-extend)
Despite this, xor is just the same with sub.
5. ret
Just pop() the addr and jmp to it.
6. nemu trap & inv
I was wondering how can ret go back to the caller sometimes while end the progress the other times.
But once I read the code-frame and the .o file, I realize that after ret to the next instr right after the caller in <_trm_init>(i.e. 0xd6), we can caller a special func to change the cpustate, ending the mainloop. And that is NEMU_TRAP.
Another special instr is inv instr, print out the value of pc and logo and abort the mainloop.
Part ii - 2.2
Since it's been detailed enough for how to realize an instr, I would be relatively brief about this topic in the following content.
And btw, thanks to PA principle - " untested code is always wrong", I hit almost no bad trap during all the pa 2(assert(0) is really useful).
//Ques: How to find instr such as 'cltd' in manual?
Since we can realize it until we meet it in the test program, we can use it's code(99) to search in the manual.0. before string:
//problem & solution:
When I was trying to realize functions about all the eflags(including CF,ZF,SF,OF,etc.)
I tried to use a macro like:
#define test_macro(f) concat(cpu.EFLAGS.,f)
i.e.
#define test_macro(f) cpu.EFLAGS.##f
But it just can't get through gcc compilation.
And later I find out that just use:
#define test_macro(f) cpu.EFLAGS.f
is OK.
Because gcc can automatically replace f if it is after a punctuation, which indicate '##' redundant here.1. lib-funcs in string.c:
Easy to realize by reading manual and c reference.
Just notice some of this funcs are dangerous to use.
2. stdio.c
According to PA principle, I just realize the functions that print %s and %d in vsprintf and call it in other stdio funcs to avoide more error.
Here is the code to in vsprintf(core code for stdio):
int vsprintf(char *out, const char *fmt, va_list ap) {
int len=0;
while(*fmt!='\0'){
/* no % */
if(*fmt!='%'){
*out=*fmt;
out++;fmt++;len++;continue;
}
/* if % fmt++ & get type */
fmt++;
switch(*fmt){
case 's':{
char* sp=va_arg(ap,char*);
while(*sp!='\0'){*out=*sp;out++;sp++;len++;}
break;}
case 'd':{
int num=va_arg(ap,int);
if(num==0){*out='0';out++;len++;break;}
if(num<0){*out='-';out++;len++;num=-num;}
assert(num>0);
char numb[12];int i=0;
while(num!=0){numb[i]='0'+num%10;i++;num/=10;}
while(i>0){i--;*out=numb[i];out++;len++;}
break;}
}
fmt++;
}
*out='\0';len++;
return len;
}Here we use macros defined in stdarg.h of clib.
I would use sprintf to illustrate how it works:
int sprintf(char *out, const char *fmt, ...) {
va_list ap;va_start(ap,fmt);
unsigned int i;
i=vsprintf(out,fmt,ap);
va_end(ap);
return i;
}- va_list: announce a list type to stand for args(...);
- va_start: used to initialize the announced va_list(ap), the second ang of va_start is the last arg before where we would ap to start from(i.e. fmt for this case)
- va_arg(ap,type): return an arg of the specified type, and automatically move the head of ap to the next arg(according to type).
- va_end: release a va_list.
//important:
assert(0) in every funcs that has not been realized.3. diff test
//Quse: Why make output error code 1?
//make[1]: *** [run] Error 1
Here is what make manual say:
(for the 1st '1' right after make)
0 The exit status is zero if make is successful.
2 The exit status is two if make encounters any errors. It will print messages describing the particular errors.
1 The exit status is one if you use the ‘-q’ flag and make determines that some target is not already up to date.
(for tht 2nd '1' after error)
‘[foo] Error NN’
‘[foo] signal description ’
These errors are not really make errors at all. They mean that a program that make invoked as part of a recipe returned a non-0 error code (‘ Error NN’), which make interprets as failure, or it exited in some other abnormal fashion (with a signal of some type). See Section 5.5 [Errors in Recipes], page 49. If no *** is attached to the message, then the sub-process failed but the rule in the makefile was prefixed with the - special character, so make ignored the error.How does 'diff-test' work?
As a matter of fact, diff-test(for x86) announce a struct for ref cpu-state as below:
union isa_gdb_regs {
struct {
uint32_t eax, ecx, edx, ebx, esp, ebp, esi, edi;
uint32_t eip, eflags;
uint32_t cs, ss, ds, es, fs, gs;
};
struct {
uint32_t array[77];
};
};What diff-test does is using memcpy to directly copy cpu-state into a CPU-state type structure(written by us), and we just need to compare 2 CPU-states.
This indicate that our struct should be similar to this one(illustrated as above).
Part iii - pa2.3
In this section, we are suppose to realize four device, namely:
serial, timer, keyboard, vga
//Ques:Understanding 'volatile'
Here I would append my result below:
(with 'volatile')
0000000000001160 <fun>:
1160: c6 05 c9 2e 00 00 00 movb $0x0,0x2ec9(%rip) # 4030 <_end>
1167: 48 8d 15 c2 2e 00 00 lea 0x2ec2(%rip),%rdx # 4030 <_end>
116e: 66 90 xchg %ax,%ax
1170: 0f b6 02 movzbl (%rdx),%eax
1173: 3c ff cmp $0xff,%al
1175: 75 f9 jne 1170 <fun+0x10>
1177: c6 05 b2 2e 00 00 33 movb $0x33,0x2eb2(%rip) # 4030 <_end>
117e: c6 05 ab 2e 00 00 34 movb $0x34,0x2eab(%rip) # 4030 <_end>
1185: c6 05 a4 2e 00 00 86 movb $0x86,0x2ea4(%rip) # 4030 <_end>
118c: c3 retq
118d: 0f 1f 00 nopl (%rax)
(without 'volatile')
0000000000001140 <fun>:
1140: c6 05 e9 2e 00 00 00 movb $0x0,0x2ee9(%rip) # 4030 <_end>
1147: eb fe jmp 1147 <fun+0x7>
1149: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)
Thus, the result illustrate that adding volatile will avoid gcc's over-optimization0. pio(port-mapped I/O) & mmio(memory-mapped I/O)
Since x86 use both pio(serial, timer, keyboard, vga) & mmio(vga),
different device ought to be realized differently.
(pio)
For the former one, we realize it by using in & out x86 instr.
To be more specific, nemu simulate devices in nemu/src/device, and use IOMAP struct to store relevant info. in & out instr directly call pio-funcs(such as pio_read_[l|w|b] ()).
AM, as a matter of fact, provide these functions by directly transform into in & out instr(use macro defined in AM/include/x86.h)
(mmio)
For mmio, paddr_[read|write] view real/virtual addr the same. When calling paddr_[read|write], it will first check if the addr is device's addr, and call different funcs accordingly.
1. serial
serial define putc() in nemu-common/trm.c:
void _putc(char ch) {
outb(SERIAL_PORT, ch);
}2. timer
When timer is called, it use inl instr to call relevant handler funcs in nemu/device, which will return the time.
The only thing to pay attention to is that timer should store the time when initialing to provide proper time.
(test result:)
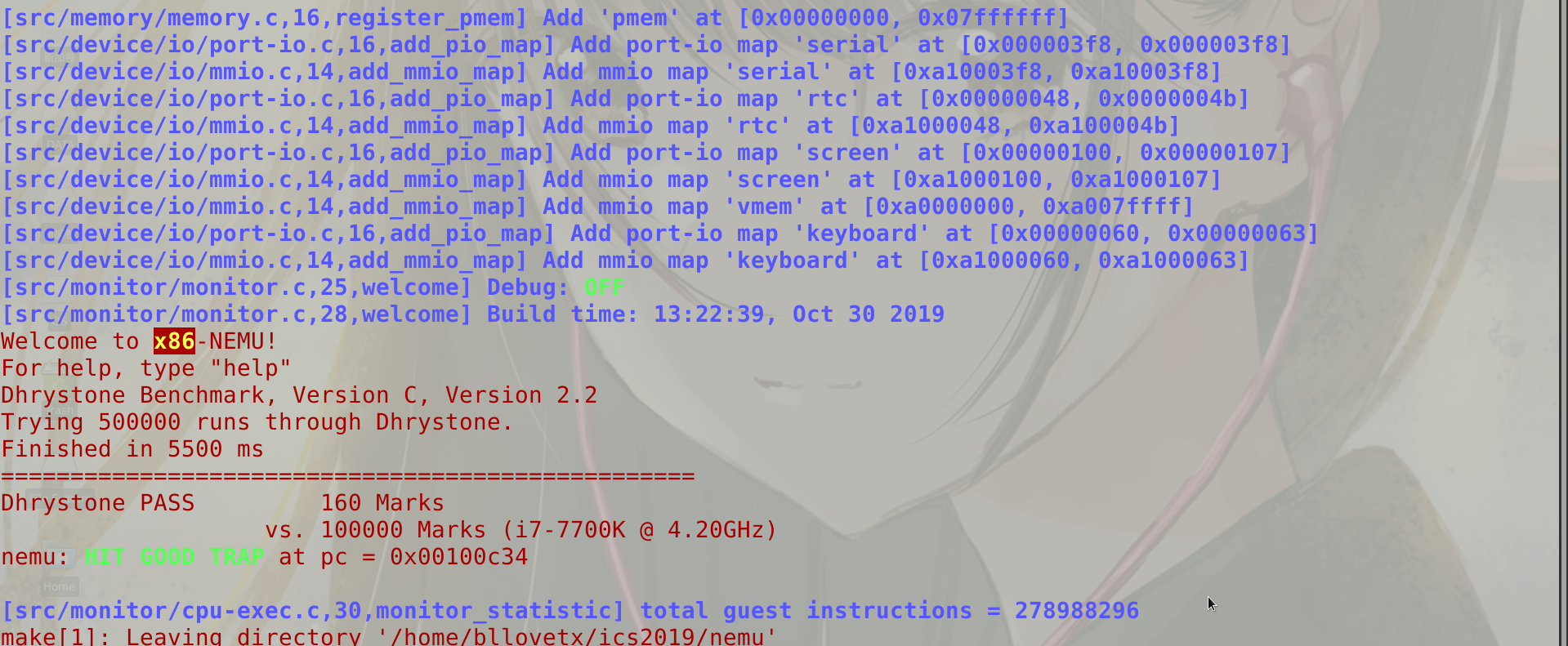
- Dhrystone Benchmark:
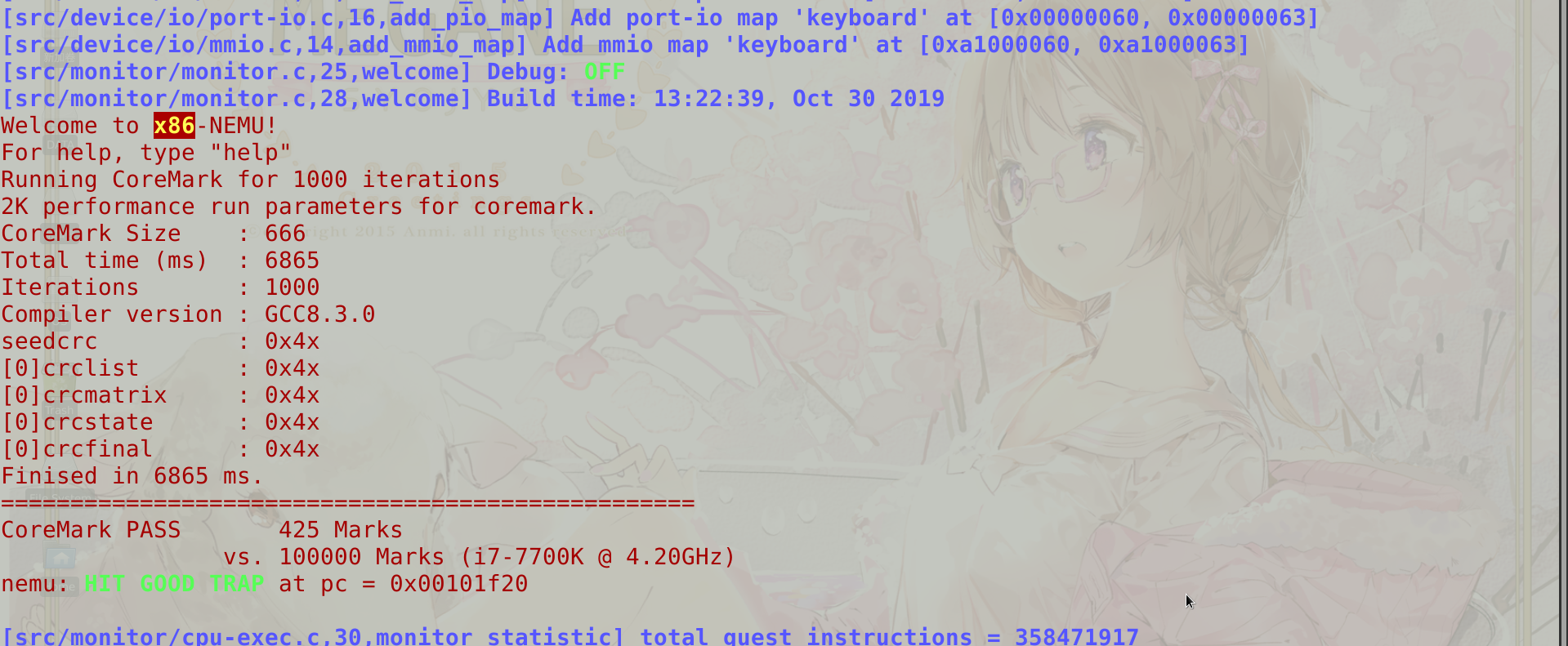
- CoreMark
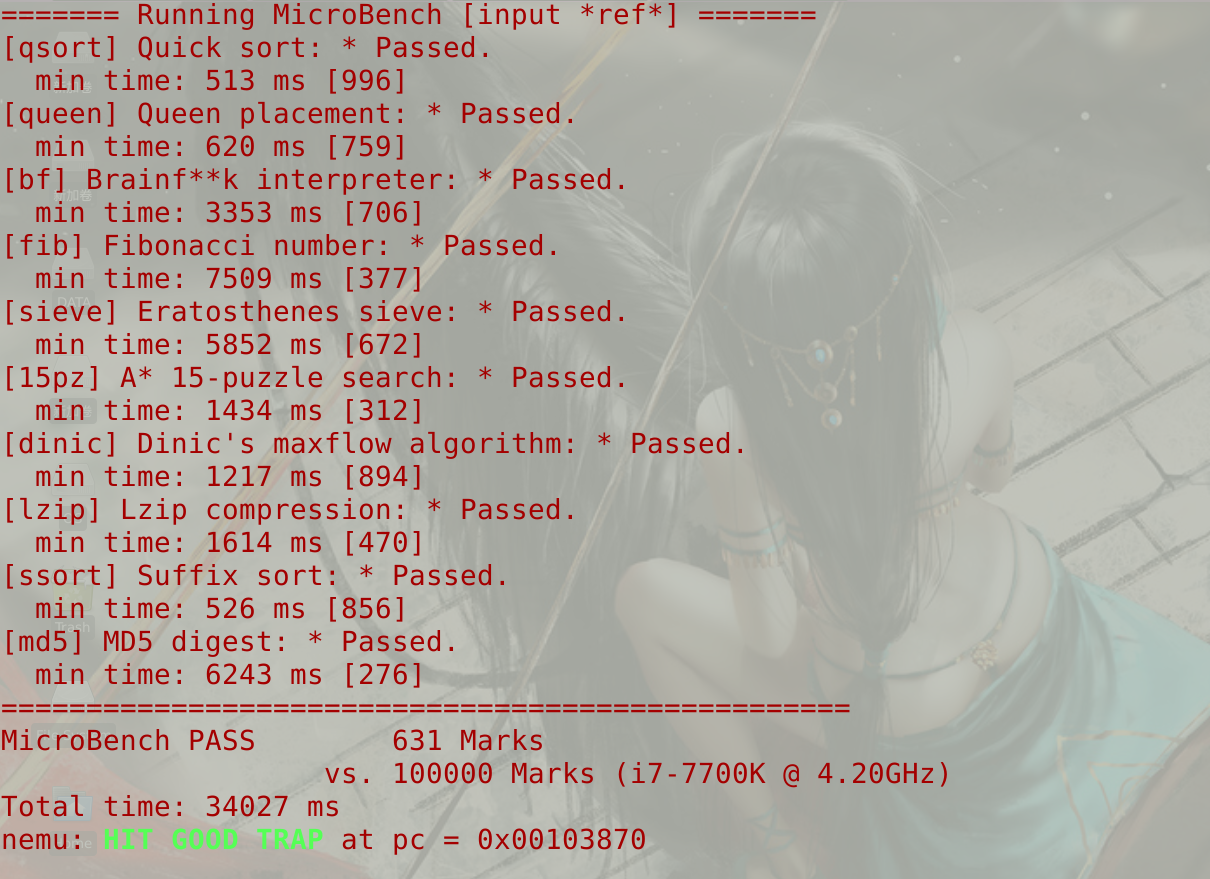
- Microbench
3. keyboard
Keyboard has two forms to store keydown
keydown==1key_scancode & KEYDOWN_MASK ==1(KEYDOWN_MASK=0x8000)
What we are suppose to do is just transform these two forms into the other again and again.
Append core code here:
key_scancode = inl(KBD_ADDR);
kbd->keydown = (key_scancode & KEYDOWN_MASK) ? 1 : 0 ;
kbd->keycode = (key_scancode & (~KEYDOWN_MASK))4. vga
video_read is almost the same.
Nevertheless, since video_write use mmio, we call memcpy to realize.
(when compiled, memcpy will be transformed into move instr, which will then call paddr_write to call relevant handler funcs to store the message)
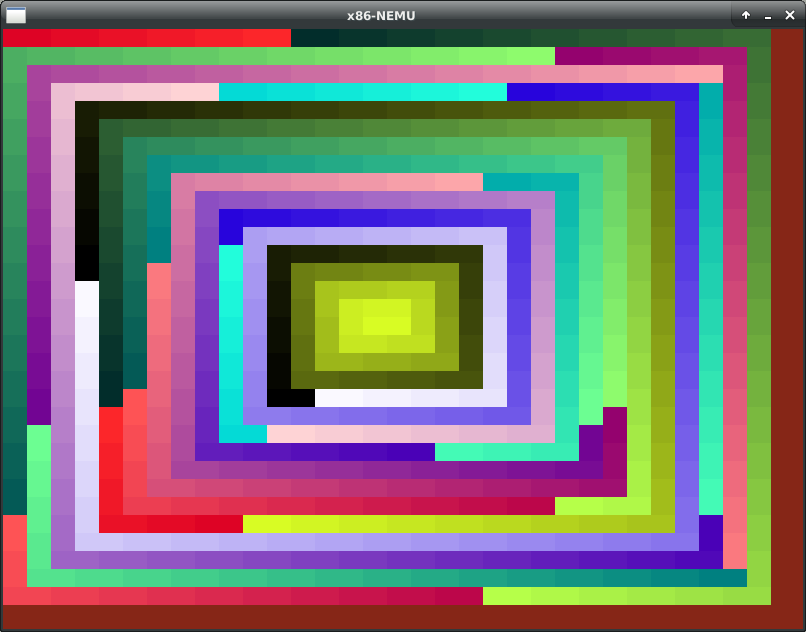
As can be seen from the pic, I change the back ground color into red in
vga_init
Part iv - QUSETIONS to answer
1. steps for instr
see part i(already include detailed steps)
2. static inline
(remove static):
error:none
explanation:let's first talk about whatinlinemeans and how it work:
Let's takertl_notas an example, which just means*dest=~*src, but in order to make the code more clear and, more importantly, realize hierarchical abstraction, we define an extra func calledrtl_not.
But this may cause another drawback, i.e. decrease the efficient of nemu.
To solve such kind of problem(common since we always need to define such kind of funcs to make code more readable and maintainable), we use the prefixinlineto suggest gcc optimize it(as quoted from gcc.gnu.org):By declaring a function inline, you can direct GCC to integrate that function's code into the code for its callers.
Therefore, on one hand, since the func(rtl_not here), with inline prefix, doesn't actually exist at all, static prefix is of no use. But on the other hand, there are still times when func can not be optimized in this way. So in order to avoid error, we should still use static inline.
- (remove inline):
error: In file included from ./include/cpu/exec.h:6
from src/cpu/cpu.c:1
./include/rtl/rtl.h:133:13: error: ‘rtl_not’ defined but not used [-Werror=unused-function]
explanation : Here we see thatrtl_notis included by exec.h & cpu.c(not just these two file), but not used in this file. Since we use-Werror, this is not allowed.
But withinline, there is in fact 'no' such a func. Therefore, if it's not used, it will not be included neither. - (remove static inline):
error: multiple definition ofrtl_not
explanation: I wonder, at first, why this would happen since we have use#ifndef. But later I found out that#ifndefcan only solve repeated definition in the same file. Since every file will be first compiled into.ofile respectively and the link together,#ifndefcan not solve the problem across files.
But static can!staticindicate the func is defined locally, somultiple definedproblem will never happan.
3. dummy? dummy!
(1)To find out how many dummy in all, I first compile x86 nemy and then use -D(found in manual, which will disassemble all) into a temp file and search key word '<dummy>' in the file with grep and count with wc:
(before adding dummy in common.h)
➜ build git:(pa2) objdump -D x86-nemu >temp
➜ build git:(pa2) find . -name "temp" | xargs grep "<dummy>"| wc -l
0
(after adding dummy in common.h)
➜ build git:(pa2) objdump -D x86-nemu >temp
➜ build git:(pa2) find . -name "temp" | xargs grep "<dummy>"| wc -l
37Here I search '<dummy>' instead of 'dummy' in order to avoid dummy funcs
(2)By repeating instrs as above, I get:
|case|result with above instrs|
|----|------------------------|
|no dummy|0 |
|only dummy in common.h|37 |
|only dummy in debug.h|37 |
|both dummy in debug.h & common.h|37|
This result is no surprising, since common.h include debug.h and debug.h include common.h(when debug is defined)
(3)
cause error: redefinition
This is also no surprising since, as mentioned above, debug.h and common.h include each other. Although, with static, they can be announced twice, they can not be initialized twice.
4. Makefile
Makefile is really useful. Not just compiling, I use it(combined with .vscode) to open 4 vscode windows with 4 different theme and status-bar color for 4 different workspace, which really save me lots of time(though it's really easy to do) with just one instr:
- make is used in the form:
dest/instr: src
contentsrc can be omitted sometimes(especially when this is an instr)
- if it's not specified, make will automatically execute the first one and all src 'recursively'.
- gcc use -I & -L to obtain include/lib dir
In our makefile, we first define the include path, and then use addprefix func to add -I for each of the path, which is used as part of the arguments when compiling the nemu. - $@ and $^ can be used to replace all dest/src
- .PHONY avoid an instr have the same name with a file
- makefile in nemu first copile all .c into .o at build/ ,and then link .o together to obtain x86-nemu.
$(OBJ_DIR)/%.o: src/%.c
@echo + CC $<
@mkdir -p $(dir $@)
@$(CC) $(CFLAGS) $(SO_CFLAGS) -c -o $@ $<
$(BINARY): $(OBJS)
$(call git_commit, "compile")
@echo + LD $@
@$(LD) -O2 -rdynamic $(SO_LDLAGS) -o $@ $^ -lSDL2 -lreadline -ldl 

