
前言 Redis 並沒有直接使用數據結構來實現鍵值對資料庫, 而是基於這些數據結構創建了一個對象系統, 這個系統包含字元串對象、列表對象、哈希對象、集合對象和有序集合對象這五種類型的對象, 每種對象都用到了至少一種我們前面所介紹的數據結構。 通過這五種不同類型的對象, Redis 可以在執行命令之前 ...
前言
Redis 並沒有直接使用數據結構來實現鍵值對資料庫, 而是基於這些數據結構創建了一個對象系統, 這個系統包含字元串對象、列表對象、哈希對象、集合對象和有序集合對象這五種類型的對象, 每種對象都用到了至少一種我們前面所介紹的數據結構。
通過這五種不同類型的對象, Redis 可以在執行命令之前, 根據對象的類型來判斷一個對象是否可以執行給定的命令。 使用對象的另一個好處是, 我們可以針對不同的使用場景, 為對象設置多種不同的數據結構實現, 從而優化對象在不同場景下的使用效率。
除此之外, Redis 的對象系統還實現了基於引用計數技術的記憶體回收機制: 當程式不再使用某個對象的時候, 這個對象所占用的記憶體就會被自動釋放; 另外, Redis 還通過引用計數技術實現了對象共用機制, 這一機制可以在適當的條件下, 通過讓多個資料庫鍵共用同一個對象來節約記憶體。
對象的類型與編碼
Redis 使用對象來表示資料庫中的鍵和值, 每次當我們在 Redis 的資料庫中新創建一個鍵值對時, 我們至少會創建兩個對象, 一個對象用作鍵值對的鍵(鍵對象), 另一個對象用作鍵值對的值(值對象)。
Redis 中的每個對象都由一個 redisObject 結構表示, 該結構中和保存數據有關的三個屬性分別是 type 屬性、 encoding 屬性和 ptr 屬性:
1 typedef struct redisObject { 2 3 // 類型 4 unsigned type:4; 5 6 // 編碼 7 unsigned encoding:4; 8 9 // 指向底層實現數據結構的指針 10 void *ptr; 11 12 // ... 13 14 } robj;
我們可以看到一個對象中主要包含了三種欄位。
type: 表示對象的類型。比如String,List,Hash等等
encoding:表示對象底層用的是什麼數據結構。如INT(整數),EMBSTR(簡潔版sds),RAW(sds),HT(map)等等
ptr:ptr是一個指針,指向對象所用的數據結構。
如下圖所示:
set k v
k是String類型,embstr數據結構,也就是簡潔版的sds,後續講。
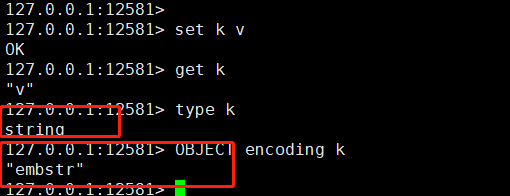
embstr與sds區別
之前我們講數據結構,都沒有見到過embStr,是的,我也是看到這一節才知道有這個東西的。
Redis為了優化,搞了一個embStr,他是為了專門存短字元串的一種編碼優化方式。
embstr編碼將創建字元串對象所需的記憶體分配次數從raw編碼的兩次降低為一次。raw編碼會調用兩次記憶體分配函數來分別創建redisObject結構和sdshdr結構, 而embstr編碼則通過調用一次記憶體分配函數來分配一塊連續的空間, 空間中依次包含redisObject和sdshdr兩個結構。因為一個連續,一個不連續。
- 釋放
embstr編碼的字元串對象只需要調用一次記憶體釋放函數, 而釋放raw編碼的字元串對象需要調用兩次記憶體釋放函數。理由同上
- 因為
embstr編碼的字元串對象的所有數據都保存在一塊連續的記憶體裡面, 所以這種編碼的字元串對象比起raw編碼的字元串對象能夠更好地利用緩存帶來的優勢。
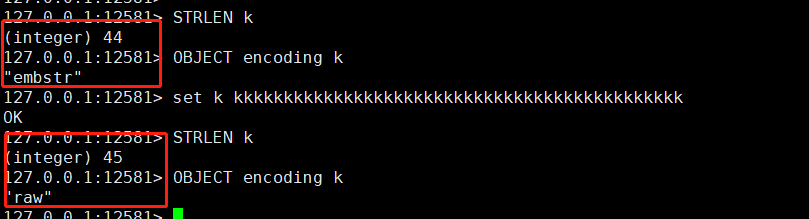
總的來說,因為embstr分配的是一段連續的記憶體,使得它分配釋放記憶體都是一次,所以效率會有所提高。同時embste <==> sds 為44個位元組。
從下圖中,我們可以明確看到。 len <= 44 都是embster的數據結構,如果len > 44 則轉變為raw。至於為啥44。
大家可以去算一下。參考文章:
https://zhuanlan.zhihu.com/p/67876900
https://xiaoyue26.github.io/2019/01/19/2019-01/redis%E7%9A%84embstr%E4%B8%BA%E4%BB%80%E4%B9%88%E6%98%AF39B/
記憶體
Redis為了節省記憶體,真的是操碎了心。
c語言不像Java,Go等語言,本身不具備自動回收記憶體機制。Java的記憶體回收導致STW一直被人詬病,最近看了ZGC的數據,Java真的是崛起了。
因此Redis 在自己的對象系統中構建了一個引用計數(reference counting)技術實現的記憶體回收機制, 通過這一機制, 程式可以通過跟蹤對象的引用計數信息, 在適當的時候自動釋放對象併進行記憶體回收。
但熟悉JVM的都知道,引用計數他有一種缺陷就是,解決不了迴圈引用的問題。
如 A <==> B 但已經沒有其他任何節點引用AB了,但AB由於相互引用,計數為1,永遠不會被回收。所以Java用了GC ROOT。
但Redis不知道為啥不存在這個問題,找了資料,也沒找出什麼原因。大多都說Redis沒有複雜的結構,所以?有大佬能解答下不?
引用計數我們可以通過 OBJECT refcount token 命令,查詢到token被引用了幾次,如果為0,那麼則可以回收了。
還有最重要的一點是,Redis對整數 0-9999(共1W個整數)做了緩存。類似於Java對-128-127做緩存一樣。
但是沒有對值的字元串,如aaaaa的這種緩存,畢竟判斷一個字元串是否在庫裡面,需要掃整個庫,非常耗時,並且cpu壓力非常的大。
處於優化,折中的考慮,也就緩存了0-9999吧。其實看看淘寶商品的價格,緩存0-100足矣,畢竟0-100占據了99%的商品。
具體可看:http://redisbook.com/preview/object/share_object.html
後言
- Redis 資料庫中的每個鍵值對的鍵和值都是一個對象。
- Redis 共有字元串、列表、哈希、集合、有序集合五種類型的對象, 每種類型的對象至少都有兩種或以上的編碼方式, 不同的編碼可以在不同的使用場景上優化對象的使用效率。
- 伺服器在執行某些命令之前, 會先檢查給定鍵的類型能否執行指定的命令, 而檢查一個鍵的類型就是檢查鍵的值對象的類型。
- Redis 的對象系統帶有引用計數實現的記憶體回收機制, 當一個對象不再被使用時, 該對象所占用的記憶體就會被自動釋放。
- Redis 會共用值為 0 到 9999 的整數對象。
- 對象會記錄自己的最後一次被訪問的時間, 這個時間可以用於計算對象的空轉時間。
參考:


