
寫在前面 最近在重溫asp.net,找了一本相關的書籍。本書在第一章就講了,在不使用瀏覽器的情況下生成一個web請求,獲取伺服器返回的內容。於是在網上搜索關於Http請求相關的資料,發現了很多資料都是講述基於HttpGet和HttpPost請求伺服器的資源,然根據Get和Post的單詞意思就大概知道 ...
寫在前面
最近在重溫asp.net,找了一本相關的書籍。本書在第一章就講了,在不使用瀏覽器的情況下生成一個web請求,獲取伺服器返回的內容。於是在網上搜索關於Http請求相關的資料,發現了很多資料都是講述基於HttpGet和HttpPost請求伺服器的資源,然根據Get和Post的單詞意思就大概知道Get(得到)意為從服務中獲取資源,而Post(發送)意為先發送數據包返還給伺服器再獲取伺服器資源。當然他們之間還有一些其他的區別,但是本文主要講的不是這個。當知道如何使用Get和Post的請求去訪問伺服器的數據,我就迫不及待找一些網頁來做測試,於是就有了糗事百科的Winform版啦。 下麵給大家看看效果。
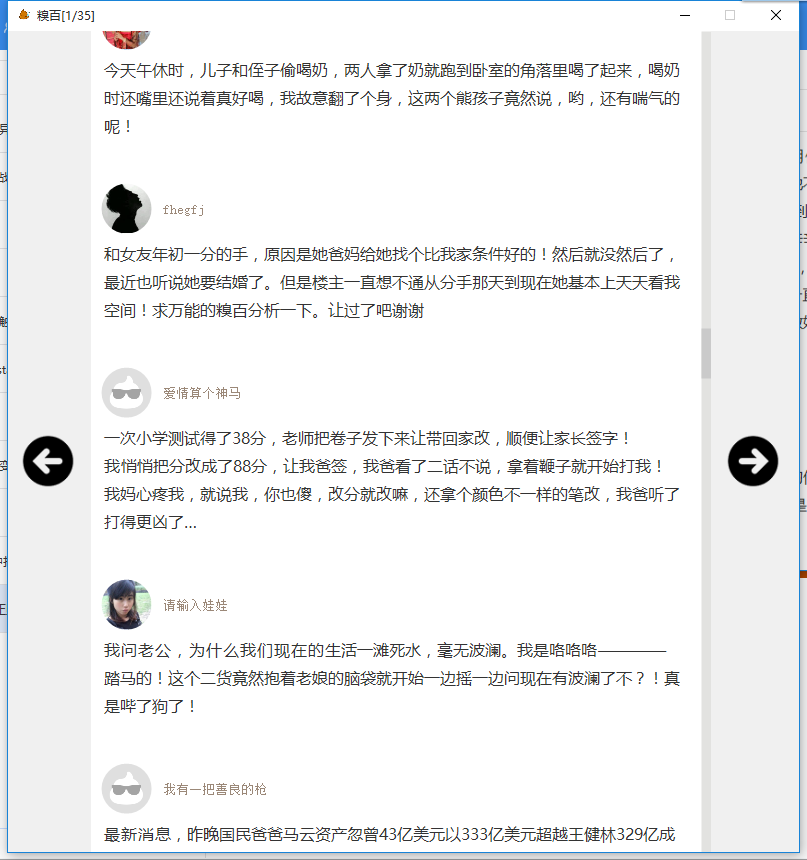 下麵我將這個過程分為以下幾個部分來進行講解,併在文章的最後提供下載鏈接。
1、分析糗事百科的網頁,構造web請求。
2、分析網頁html源代碼,提取需要的信息。
3、數據綁定。
1、分析糗事百科的網頁,構造web請求
下麵我將這個過程分為以下幾個部分來進行講解,併在文章的最後提供下載鏈接。
1、分析糗事百科的網頁,構造web請求。
2、分析網頁html源代碼,提取需要的信息。
3、數據綁定。
1、分析糗事百科的網頁,構造web請求
打開糗事百科笑話的主頁,在這裡我只取糗事笑話中文字這一板塊,點擊文字這一菜單欄。如下圖。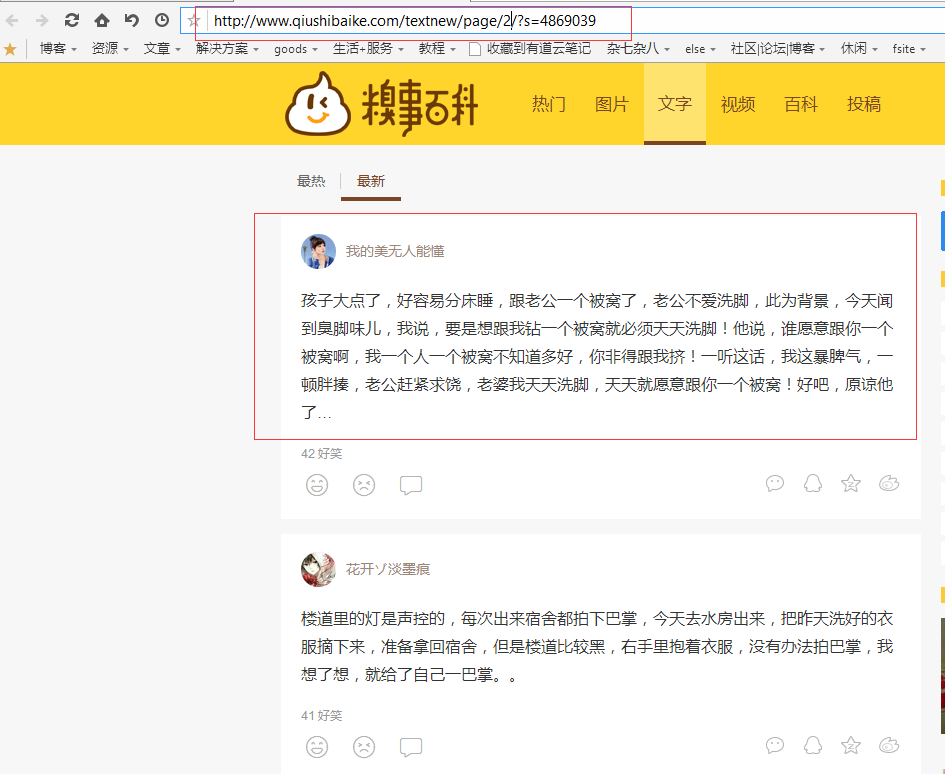
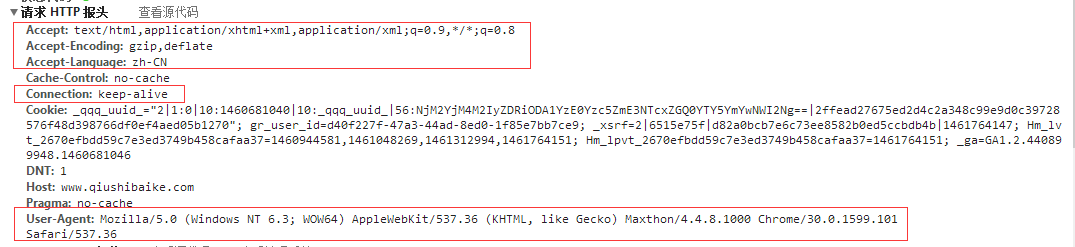 註意:其中紅線標示的部分在實例化一個Http請求類時都需要被設置,否則會得到錯誤的返回結果。
1.3 c#實現糗百網頁的抓取
根據上面的分析,我使用c#語言並利用System.Net程式集中的HttpWebRequest和HttpWebResponse這兩個類去實現網頁內容的抓取。
源代碼如下:
註意:其中紅線標示的部分在實例化一個Http請求類時都需要被設置,否則會得到錯誤的返回結果。
1.3 c#實現糗百網頁的抓取
根據上面的分析,我使用c#語言並利用System.Net程式集中的HttpWebRequest和HttpWebResponse這兩個類去實現網頁內容的抓取。
源代碼如下:
const string qsbkMainUrl = "http://www.qiushibaike.com"; //獲取糗百文字笑話頁的url private static string GetWBJokeUrl(int pageIndex) { StringBuilder url = new StringBuilder(); url.Append(qsbkMainUrl); url.Append ("/textnew/page/"); url.Append(pageIndex.ToString ()); url.Append("/?s=4869039"); return url.ToString(); } //根據網頁的url獲取網頁的html源碼 private static string GetUrlContent(string url) { try { HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url); request.UserAgent = "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.8.1000 Chrome/30.0.1599.101 Safari/537.36"; request.Method = "GET"; request.ContentType = "text/html;charset=UTF-8"; HttpWebResponse response = (HttpWebResponse)request.GetResponse(); Stream myResponseStream = response.GetResponseStream(); StreamReader myStreamReader = new StreamReader(myResponseStream, Encoding.GetEncoding("utf-8"));//因為知道糗百網頁的編碼方式為utf-8 string retString = myStreamReader.ReadToEnd(); myStreamReader.Close(); myResponseStream.Close(); return retString; } catch { return null; } }
2、分析網頁html源代碼,提取需要的信息
在1中我們已經根據page頁索引的不同而獲取不同的頁面內容,而這一步的任務就是如何從返回的html源代碼中獲取我們想要的笑話內容。 我們提取網頁文字的笑話內容包括三個部分:發佈笑話者的頭像,發佈笑話者的昵稱,發佈內容。 2.1 分析網頁構造正則表達式 首先我們對html源碼進行分析並找出我們想要的內容所在的標簽位置,以及它們的html的結構。
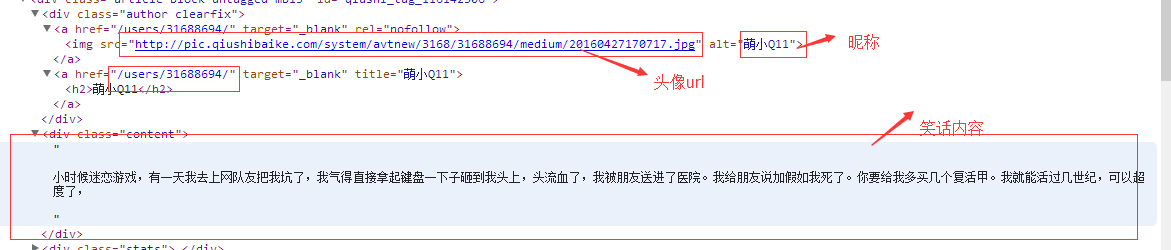 這上面是我分析的我們所需要的內容所在html源碼中的標簽位置,由於一個頁面中每條笑話的html顯示標簽都是一樣的,所以只要能偶提取一條笑話的內容,那麼該頁的其它笑話也可以同樣提取。由於這種結構基本是固定的,每個笑話的各部分內容都是用相同的html標簽表示,並且位置也是相同的,因此在寫正則表達的時候,可以用很多常量字元去固定,這樣能夠加快正則的匹配效率。下麵給出匹配笑話內容的正則表達,(通過分組實現捕獲一個笑話的不同內容)。當然這個正則表達式可能存在一些不能完全精確匹配的情況。
這上面是我分析的我們所需要的內容所在html源碼中的標簽位置,由於一個頁面中每條笑話的html顯示標簽都是一樣的,所以只要能偶提取一條笑話的內容,那麼該頁的其它笑話也可以同樣提取。由於這種結構基本是固定的,每個笑話的各部分內容都是用相同的html標簽表示,並且位置也是相同的,因此在寫正則表達的時候,可以用很多常量字元去固定,這樣能夠加快正則的匹配效率。下麵給出匹配笑話內容的正則表達,(通過分組實現捕獲一個笑話的不同內容)。當然這個正則表達式可能存在一些不能完全精確匹配的情況。
正則:<img src="([^"]*")\s*alt="([^"]*)"/>\s</a>\s<a href="([^"]*)"[^>]*>\s<h2>[^>]*>\s</a>\s</div>\s*<div class="content">\s*((.*|<br/>)*)其中,第一個括弧裡面的內容代表“頭像地址”,第二個括弧裡面的內容代表“昵稱”,第三個括弧裡面的內容代表“笑話內容” 2.2 編碼獲取頁面的所有笑話 a、首先建一個笑話的實體類
public class JokeItem { private string nickName; /// <summary> /// 昵稱 /// </summary> public string NickName { get { return nickName; } set { nickName = value; } } private Image headImage; /// <summary> /// 頭像 /// </summary> public Image HeadImage { get { return headImage; } set { headImage = value; } } private string jokeContent; /// <summary> /// 笑話內容 /// </summary> public string JokeContent { get { return jokeContent; } set { jokeContent = value; } } private string jokeUrl; /// <summary> /// 笑話地址 /// </summary> public string JokeUrl { get { return jokeUrl; } set { jokeUrl = value; } } }
b、利用正則獲取笑話內容
/// <summary> /// 獲取笑話列表 /// </summary> /// <param name="htmlContent"></param> public static List<JokeItem> GetJokeList(int pageIndex) { string htmlContent=GetUrlContent(GetWBJokeUrl(pageIndex)); List<JokeItem> jokeList = new List<JokeItem>(); Regex rg = new Regex(@"<img src=""([^""]*"")\s*alt=""([^""]*)""/>\s</a>\s<a href=""([^""]*)""[^>]*>\s<h2>[^>]*>\s</a>\s</div>\s*<div class=""content"">\s*((.*|<br/>)*)", RegexOptions.IgnoreCase); JokeItem joke; MatchCollection matchResults = rg.Matches(htmlContent); foreach (Match result in matchResults) { joke = new JokeItem(); joke.HeadImage = GetWebImage(result.Groups[1].Value); joke.HeadImage = joke.HeadImage != null ? new Bitmap(GetWebImage(result.Groups[1].Value), 50, 50) : null; joke.NickName = result.Groups[2].Value; joke.JokeUrl = qsbkMainUrl + "/" + result.Groups[3].Value; ; joke.JokeContent = result.Groups[4].Value.Replace("<br/>", "\r\n").Replace("<br>", "\r\n"); joke.JokeContent = Regex.Replace(joke.JokeContent, @"(\r\n)+", "\r\n");//去掉多餘的空行 jokeList.Add(joke); } return jokeList; }
c、根據頭像url地址獲取頭像
private static Image GetWebImage(string webUrl) { try { Encoding encode = Encoding.GetEncoding("utf-8");//網頁編碼==Encoding.UTF8 HttpWebRequest req = (HttpWebRequest)WebRequest.Create(new Uri(webUrl)); HttpWebResponse ress = (HttpWebResponse)req.GetResponse(); Stream sstreamRes = ress.GetResponseStream(); return System.Drawing.Image.FromStream(sstreamRes); } catch { return null; } }
3、數據綁定
數據都獲取了,數據綁定是最容易的一步,由於數據獲取這一步牽涉到web請求,會發生幾秒的網路延遲,因此需要使用一個後臺的工作線程去請求數據。在此處採用backgroundWorker控制項來實現非同步請求數據。其中UI部分借用了兩個第三方控制項,一個是載入的等待條,另一個是數據綁定控制項。數據綁定代碼就不貼出來了。可以在下麵下載我的源碼。 4、總結
在這個過程中,我對http的請求方式有了進一步的理解,也終於把平常學習的正則表達式發揮了用處。 把平常學習到的技術綜合起來再結合一個好的想法就會做出讓自己意想不到的小程式,希望自己以後能多把自己學習的技術與實踐結合起來。 開發環境:vs2013,.net2.0 源碼地址:http://download.csdn.net/detail/mingge38/9504931


