
前言 索引的主要作用是起到約束和加速查找,ORM框架(sqlalchemy)是用類和對象對資料庫進行操作 索引的種類 按種類去分 1.普通索引:能夠加速查找 2.主鍵索引:能夠加速查找、不能為空、不能重覆 3.唯一索引:加速查找、可以為空、不能重覆 4.聯合索引(多列): ①聯合主鍵索引 ②聯合唯一 ...
前言
索引的主要作用是起到約束和加速查找,ORM框架(sqlalchemy)是用類和對象對資料庫進行操作
索引的種類
按種類去分
1.普通索引:能夠加速查找
2.主鍵索引:能夠加速查找、不能為空、不能重覆
3.唯一索引:加速查找、可以為空、不能重覆
4.聯合索引(多列):
①聯合主鍵索引
②聯合唯一索引
③聯合普通索引
按數據結構去分
1.hash索引:哈希索引。創建一個索引表,把這些數據(下麵用到的'name')轉化成哈希值,再把這些哈希值放入表中,並加上這個數據的存儲地址。在索引表中的順序和數據表中的數據不一定會一致,因為它裡面的順序是無序的,如果在數據表中按一個範圍去找值那效能不一定會高,但是如果只找單值的時候它就會很快的查找出結果。
2.btree索引(常用):也就是binary tree索引、二元樹索引。在innodb引擎中它創建btree索引。在範圍內找值效率高。
索引的加速查找
首先創建一個表
create table dataset( id int not null auto_increment primary key, name varchar(32), data int, )engine = innodb default charset = utf8;
再創建一個存儲過程,當我們執行的存儲過程時往表裡插入10w筆數據
delimiter // create procedure inserdatapro() begin declare i int default 1; -- 定義一個計數器i declare t_name varchar(16); -- 臨時名字變數 declare t_data int; -- 臨時數據變數 while i <= 100000 do -- 如果i小於10W就執行下麵的操作 set t_name = CONCAT('aaa',i); -- 讓'aaa'和i相連接變成字元串'aaa1','aaa2'...的形式 set t_data = CEIL(RAND()*100); -- 產生一個0-100的亂數 insert into dataset(name,data) values(t_name,t_data); -- 將t_name,t_data插入dataset內 set i = i + 1; -- 將i加一 end while; -- 結束迴圈 end // delimiter ;
執行存儲過程,往表中插入數據完成要花一定的時間,具體還需要看電腦的性能
call inserdatapro();
比較兩種語句的執行速度:
select * from dataset where name = 'aaa94021';
select * from dataset where id = 94021;
結果:
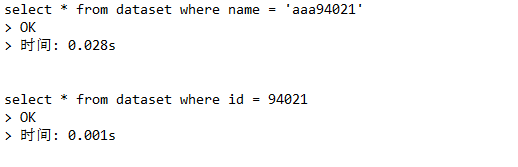
通過比較可以看出用索引(id)去查數據會比較快,像第一種查詢方式因為沒有索引,所以它必須要逐個去翻找出我們要的結果,因此我們可以再創建一個索引去查找數據。
create index nindex on dataset(name); -- 創建名字的索引
再去執行第一個查詢語句:

可以看出效能得到了很顯著的提升
查找方式:
1.無索引
從前到後依次查找
2.有索引
會創建一個數據結構或創建額外的文件,它按照某種格式去進行存儲。所以它的查找方式會從這個索引文件中查詢這個數據在這張表的什麼位置。
查詢快,但插入更行刪除慢
當我們在使用索引查找資料時要命中索引,比如說:
select * from dataset where name like 'aaa94021';
索引相關操作:
1.普通索引
①創建表
create table t( nid int not null auto_increment primary key, name varchar(32), data int, index index_name(name) )
②創建索引
create index index_name on t(name);
③刪除索引
drop index index_name on t;
④查看索引
show index from t;
2.唯一索引
①創建表
create table t2( id int not null auto_increment primary key, name varchar(32) not null, data int, unique index_name(name) )
②創建唯一索引
create unique index index_name on t2(name);
③刪除唯一索引
drop unique index index_name on t2;
3.主鍵索引
①創建表
-- 寫法一 create table t3( id int not null auto_increment primary key, name varchar(32) not null, int data, index index_name(name) ) -- 寫法二 craete table t4( id int not null auto_increment, name varchar(32) not null, int data, primary key(id), index index_name(name) )
②創建主鍵
alter table t3 add primary key(id);
③刪除主鍵
alter table t3 modify id int,drop primary key; alter table t3 drop primary key;
4.聯合索引
①創建表
create table mtable( id int not null auto_increment, name varchar(32) not null, data int, gender varchar(16), primary key(id,name) )engine=innodb default charset=utf8;
②創建聯合索引
create index index_id_name on mtable(id,name,gender);
最左首碼匹配:只支持最左邊與其他索引之間的匹配方式,如:(id,name)、(id,gender)、(id,name,gender),如果用(name,gender)等就不能達到我們想要的查找效果
-- 符合最左首碼匹配 select * from mtable id = 15 and name = 'aaa15'; select * from mtable id = 15 and gender = 'male'; -- 不符合最左首碼匹配 select * from mtable name = 'aaa20' and id = 20;
組合索引的效率大於索引合併
覆蓋索引和索引合併
不是真實存在,只是一個名詞
覆蓋索引:在索引文件中直接獲取數據
比方說從表dataset去找'name = aaa12456'的存儲數據
select * from dataset where name = 'aaa12456';
那我們如果想要取它的ID或data就可以通過這種方式拿到:
select id,data from dataset where name = 'aaa12456';
索引合併:把多個單列索引合併使用
例:
select * from dataset where name = 'aaa12456' and id = 12456;
命中索引
當我們需要在一個列中頻繁的查找我們才需要創建索引,之後我們就要去命中索引,下麵是命中索引的情況
1.like '%xx'(模糊查詢)
select * from t where name like '%cn';
2.使用函數(速度慢,可以在程式級別中使用函數避免效能降低)
select * from t where reverse(name) = '3215aaa';
3.or
當這裡id是索引,name不是索引的時候
select * from dataset where id = 15 or name = 'aaa20169';
特殊情況:
當這裡id、name是索引,data不是索引,語句在執行時會把不是索引的部分給去掉把是索引的兩端給連起來
select * from dataset where id = 15 or data = 98 and name = 'aaa20169';
4.類型不一致
當查詢的類型為字元串和非字元串的類型時,兩邊所執行的時間會不大相同
select * from dataset where data = '98'; select * from dataset where data = 98;
效能比較:

5.!=
非主鍵情況:
select * from dataset where data != 98; select * from dataset where data = 98;
效能比較:

主鍵情況,還是會走索引:
select * from dataset where id != 12345; select * from dataset where id = 12345;
效能比較:

6.>
非數字類型(效能不是很高):
select * from dataset where name > 'aaa1345'; -- name不是主鍵
數字類型(如果是主鍵的話,還會走索引)
select * from dataset where id > 1345;
7.order by
索引排序的時候,選擇的映射如果不是索引,則不走索引
select data from dataset order by data desc; select name from dataset order by data desc;
效能比較:

特殊情況,當對主鍵進行排序那還是走索引:
select * from dataset order by id desc;
8.聯合索引最左首碼
執行計劃
讓Mysql去預估執行操作(一般情況下預估結果是正確的),語法:explain + MySQL查詢語句
例一:
explain select * from dataset;
執行結果:

type等於All表示全表掃描,執行速度慢
例二:
explain select * from dataset where id = 9; -- id為主鍵
執行結果:

type等於const表示常數
例三:
explain select * from dataset where name = 'aaa17849'; -- name為索引
執行結果:

type等於ref表示按索引查詢,執行速度快
select_type為查詢類型:
SIMPLE 簡單查詢 PRIMARY 最外層查詢 SUBQUERY 映射為子查詢 DERIVED 子查詢 UNION 聯合 UNION RESULT 使用聯合的結果
table為表名
possible_keys為可能使用的索引
key為真正使用的索引
key_len為MySQL中使用的索引位元組長度
rows為預估讀取長度
extra為包含MySQL解決查詢的詳細信息
type表示查詢時的訪問類型,下麵性能的快慢順序:
ALL < INDEX < RANGE < INDEX_MERGE < REF_OR_NULL < REF < EQ_REF < SYSTEM/CONST
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#jointype_system
索引註意事項
1.避免使用select *去查詢
2.count(1)或count(列)代替count(*)
3.創建表時儘量用char代替varchar
4.表的欄位順序固定長度的欄位優先
5.組合索引代替多個單列索引(經常使用多個條件查詢時)
6.儘量使用短索引
7.使用連接(JOIN)來替代子查詢(SUB-QUERIES)
8.連表時註意條件和類型需一致
9.索引散列值(重覆少)不適合建索引,比如:性別
慢日誌
用於記錄執行時間長的SQL、未命中索引把它們放到一個日誌文件路徑
記憶體中配置慢日誌
查看當前配置信息
show variables like '%query%';
執行結果:
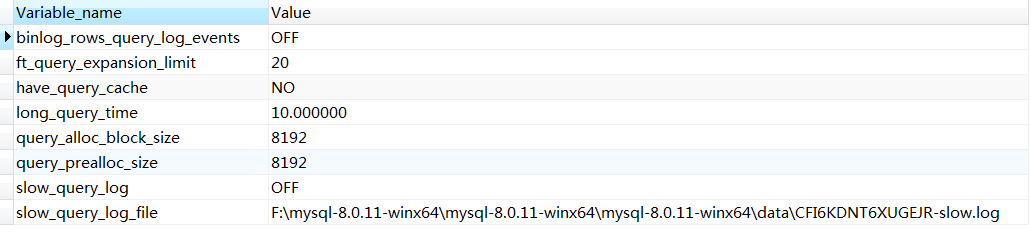
這裡的long_query_time = 10 表示時間超過十秒的都會被記錄下來、slow_query_log = OFF 表示是否開啟慢日誌、slow_query_log_file 表示日誌文件路徑
除此之外
show variables like '%queries%';
也可以查詢到配合信息,執行結果:

這裡的log_queries_not_using_indexed = OFF 表示使用的索引的搜索是否記錄
若想要修改當前配置:
set global 變數名 = 值;
啟動慢日誌:
set global slow_query_log = ON;
配置文件
通過啟動服務端
mysqld --default-file=配置文件路徑
這樣我們就可以在一個'my.conf'文件中去看這些日誌記錄
那這些記錄內容就是相關的SQL執行操作。
除了新建一個'my.conf'去記錄日誌,也可以通過使用Mysql的'my-default.ini'去記錄日誌
註意:在修改了配置文件之後要記得備份和重啟服務
分頁
當一個數據的量很大時,作為用戶不可能一下就去閱覽上千條的量,所以我們要設計一個量,方便用戶去閱讀
首先我們先獲得前十條數據:
select * from dataset limit 0,10;
執行結果:

那以此類推我們可以再去獲得後十條,再後十條的數據從而達到分頁的效果,但是其實我們使用limit它會去將數據進行掃描,當從0-10分10條數據時,它會掃10條數據,而當10-20分十條數據時,它會掃20條的數據...那如果在一個很大的數據量中掃描再去獲取十條數據,那麼它的效能就會非常的慢
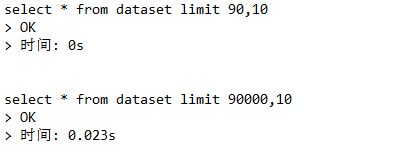
因此這種分頁的方式實不可取的,那如何去解決?
方式一:隱藏分頁
方式二:索引表掃描(用到覆蓋索引)
但其實用這種方法和全掃相比也不會快到哪裡去
select * from dataset where id in(select id from dataset limit 90000,10);
方式三:制定方案(記錄當前頁最大ID和最小ID)
如果要找後十條數據:
select * from dataset where id > 90000 limit 10;
查詢速度:

如果要找前十條數據:
select * from dataset where id < 90001 order by id desc limit 10 ;
查詢速度:

那如果要實現一個很大的跨度的話,比如說直接跳10000頁,在資料庫上是沒法實現的,不過可以通過其他的方法像緩存等。between..and..不能實現問題在於資料庫中ID是不是連續的,因為這些ID會因為一些增刪改的操作出現變動。
在記錄當前頁的最大ID和最小ID還有兩種實現方法:
①頁面只有上一頁或下一頁
假設max_id為當前頁最大ID、min_id為當前頁最小ID
實現下一頁功能:
select * from dataset where id > max_id limit 10;
實現上一頁功能:
select * from dataset where id < min_id order by id desc limit 10;
②在上一頁和下一頁中間有很多頁碼

當前頁(196):cur_page
目標頁(199):tar_page
當前頁最大ID:max_id
select * from dataset where id in (select id from (select id from dataset where id > max_id limit (tar_page-cur_page)*10) as T order by T.id desc limit 10);
當前頁(196):cur_page
目標頁(193):tar_page
當前頁最小ID:min_id
select * from dataset where id in (select id from (select id from dataset where id < min_id limit (cur_page - tar_page)*10) as T order by T.id desc limit 10);


