
聲明: 博文參考1:https://blog.csdn.net/WDJNDY/article/details/79711426 博文參考2:https://www.cnblogs.com/schut/p/8407258.html (1)為什麼要用字元編碼(參照:https://blog.csdn.n ...
聲明: 博文參考1:https://blog.csdn.net/WDJNDY/article/details/79711426
博文參考2:https://www.cnblogs.com/schut/p/8407258.html
(1)為什麼要用字元編碼(參照:https://blog.csdn.net/WDJNDY/article/details/79711426)
早期的電腦使用的是通電與否的特性的真空管,如果通電就是1,沒有通電就是0,後來沿用至今我們稱這種只有0/1的環境為
二進位制,英文稱為binary。但是二進位數據(0/1)怎麼能表示我們所熟知的英文,數字,字元,漢字呢?所以就有了各種編碼,因
為開始電腦只在美國用。八位的位元組一共可以組合出256(2的8次方)種不同的狀態。(可以涵蓋美國人使用的字母,數字和特殊符
號。)所以他們把其中的編號從0開始的32種狀態分別規定了特殊的用途,一但終端、印表機遇上約定好的這些位元組被傳過來時,
就要做一些約定的動作:
遇上0×10, 終端就換行;
遇上0×07, 終端就向人們嘟嘟叫;
遇上0x1b, 印表機就列印反白的字,或者終端就用彩色顯示字母。
他們看到這樣很好,於是就把這些0×20以下的位元組狀態稱為”控制碼”。他們又把所有的空 格、標點符號、數字、大小寫字母分
別用連續的位元組狀態表示,一直編到了第127號,這樣電腦就可以用不同位元組來存儲英語的文字了。大家看到這樣,都感覺很好
,於是大家都把這個方案叫做 ANSI 的”Ascii”編碼(American Standard Code for Information Interchange,美國信息互換標
準代碼)。當時世界上所有的電腦都用同樣的ASCII方案來保存英文文字。
後來,就像建造巴比倫塔一樣,世界各地都開始使用電腦,但是很多國家用的不是英文,他們的字母里有許多是ASCII里沒
有的,為了可以在電腦保存他們的文字,他們決定採用 127號之後的空位來表示這些新的字母、符號,還加入了很多畫表格時需
要用下到的橫線、豎線、交叉等形狀,一直把序號編到了最後一個狀態255。從128 到255這一頁的字元集被稱”擴展字元集“。從此
之後,貪婪的人類再沒有新的狀態可以用了,美帝國主義可能沒有想到還有第三世界國家的人們也希望可以用到電腦吧!
等中國人們得到電腦時,已經沒有可以利用的位元組狀態來表示漢字,況且有6000多個常用漢字需要保存呢。但是這難不倒智
慧的中國人民,我們不客氣地把那些127號之後的奇異符號們直接取消掉, 規定:一個小於127的字元的意義與原來相同,但兩個大
於127的字元連在一起時,就表示一個漢字,前面的一個位元組(他稱之為高位元組)從0xA1用到0xF7,後面一個位元組(低位元組)從
0xA1到0xFE,這樣我們就可以組合出大約7000多個簡體漢字了。在這些編碼里,我們還把數學符號、羅馬希臘的字母、日文的假
名們都編進去了,連在 ASCII 里本來就有的數字、標點、字母都統統重新編了兩個位元組長的編碼,這就是常說的”全形”字元,而原
來在127號以下的那些就叫”半形”字元了。中國人民看到這樣很不錯,於是就把這種漢字方案叫做“GB2312“。GB2312 是對 ASCII
的中文擴展。
因為當時各個國家都像中國這樣搞出一套自己的編碼標準,結果互相之間誰也不懂誰的編碼,誰也不支持別人的編碼,連大陸
和臺灣這樣只相隔了150海裡,使用著同一種語言的兄弟地區,也分別採用了不同的 DBCS 編碼方案——當時的中國人想讓電腦顯
示漢字,就必須裝上一個”漢字系統”,專門用來處理漢字的顯示、輸入的問題,像是那個臺灣的愚昧封建人士寫的算命程式就必須
加裝另一套支持 BIG5 編碼的什麼”倚天漢字系統”才可以用,裝錯了字元系統,顯示就會亂了套!這怎麼辦?而且世界民族之林中
還有那些一時用不上電腦的窮苦人民,他們的文字又怎麼辦?真是電腦的巴比倫塔命題啊!
正在這時,大天使加百列及時出現了——一個叫 ISO(國際標誰化組織)的國際組織決定著手解決這個問題。他們採用的方法
很簡單:廢了所有的地區性編碼方案,重新搞一個包括了地球上所有文化、所有字母和符號的編碼!他們打算叫它”Universal
Multiple-Octet Coded Character Set”,簡稱 UCS, 俗稱“unicode“。
unicode開始制訂時,電腦的存儲器容量極大地發展了,空間再也不成為問題了。於是 ISO 就直接規定必須用兩個位元組,也
就是16位來統一表示所有的字元,對於ASCII里的那些“半形”字元,unicode包持其原編碼不變,只是將其長度由原來的8位擴展為
16位,而其他文化和語言的字元則全部重新統一編碼。由於”半形”英文符號只需要用到低8位,所以其高8位永遠是0,因此這種大
氣的方案在保存英文文本時會多浪費一倍的空間。
這時候,從舊社會裡走過來的程式員開始發現一個奇怪的現象:他們的 strlen 函數靠不住了,一個漢字不再是相當於兩個字元
了,而是一個!是的,從unicode開始,無論是半形的英文字母,還是全形的漢字,它們都是統一的”一個字元“!同時,也都是統一
的”兩個位元組“,請註意”字元”和”位元組”兩個術語的不同,“位元組”是一個8位的物理存貯單元,而“字元”則是一個文化相關的符號。在
unicode中,一個字元就是兩個位元組。一個漢字算兩個英文字元的時代已經快過去了。
unicode同樣也不完美,這裡就有兩個的問題,一個是,如何才能區別unicode和ascii?電腦怎麼知道三個位元組表示一個符號
,而不是分別表示三個符號呢?第二個問題是,我們已經知道,英文字母只用一個位元組表示就夠了,如果unicode統一規定,每個
符號用三個或四個位元組表示,那麼每個英文字母前都必然有二到三個位元組是0,這對於存儲空間來說是極大的浪費,文本文件的大
小會因此大出二三倍,這是難以接受的。
unicode在很長一段時間內無法推廣,直到互聯網的出現,為解決unicode如何在網路上傳輸的問題,於是面向傳輸的眾多 UTF
(UCSTransfer Format)標準出現了,顧名思義,UTF-8就是每次8個位傳輸數據,而UTF-16就是每次16個位。UTF-8就是在互
聯網上使用最廣的一種unicode的實現方式,這是為傳輸而設計的編碼,並使編碼無國界,這樣就可以顯示全世界上所有文化的字
符了。UTF-8最大的一個特點,就是它是一種變長的編碼方式。它可以使用1~4個位元組表示一個符號,根據不同的符號而變化位元組
長度,當字元在ASCII碼的範圍時,就用一個位元組表示,保留了ASCII字元一個位元組的編碼做為它的一部分,註意的是unicode一個
中文字元占2個位元組,而UTF-8一個中文字元占3個位元組)。
從unicode到utf-8並不是直接的對應,而是要過一些演算法和規則來轉換。
7 7 E 5
0111 0111 1110 0101 二進位的77E5
--------------------------
0111 011111 100101 按規則重組後的二進位77E5
1110XXXX 10XXXXXX 10XXXXXX 套用UTF-8模版(固定化模版)
11100111 10011111 10100101 代入模版
E 7 9 F A 5
最後簡單總結一下:
中國人民通過對 ASCII 編碼的中文擴充改造,產生了 GB2312 編碼,可以表示6000多個常用漢字。
漢字實在是太多了,包括繁體和各種字元,於是產生了 GBK 編碼,它包括了 GB2312 中的編碼,同時擴充了很多。
中國是個多民族國家,各個民族幾乎都有自己獨立的語言系統,為了表示那些字元,繼續把 GBK 編碼擴充為 GB18030 編碼。
每個國家都像中國一樣,把自己的語言編碼,於是出現了各種各樣的編碼,如果你不安裝相應的編碼,就無法解釋相應編碼想
表達的內容。
終於,有個叫 ISO 的組織看不下去了。他們一起創造了一種編碼 UNICODE ,這種編碼非常大,大到可以容納世界上任何一
個文字和標誌。所以只要電腦上有 UNICODE 這種編碼系統,無論是全球哪種文字,只需要保存文件的時候,保存成 UNICODE 編
碼就可以被其他電腦正常解釋。
UNICODE 在網路傳輸中,出現了兩個標準 UTF-8 和 UTF-16,分別每次傳輸 8個位和 16個位。於是就會有人產生疑問,
UTF-8 既然能保存那麼多文字、符號,為什麼國內還有這麼多使用 GBK 等編碼的人?因為 UTF-8 等編碼體積比較大,占電腦空間
比較多,如果面向的使用人群絕大部分都是中國人,用 GBK 等編碼也可以。
(2)字元在硬碟上的存儲(參照:https://www.cnblogs.com/schut/p/8407258.html)
首先要明確的一點就是,無論以什麼編碼在記憶體里顯示字元,存到硬碟上都是2進位(0b是說明這段數字是二進位,0x表示是
16進位。0x幾乎所有的編譯器都支持,而支持0b的並不多)。理解這一點很重要。
比如:
ascii編碼(美國):
l 0b1101100
o 0b1101111
v 0b1110110
e 0b1100101
GBK編碼(中國):
老 0b11000000 0b11001111
男 0b11000100 0b11010000
孩 0b10111010 0b10100010
還要註意的一點是:存到硬碟上時是以何種編碼存的,再從硬碟上讀出來時,就必須以何種編碼讀(開頭聲明或轉換),要不然就亂了。
(3)編碼轉換
雖然有了unicode and utf-8 ,但是由於歷史問題,各個國家依然在大量使用自己的編碼,比如中國的windows,預設編碼依然
是gbk,而不是utf-8。
基於此,如果中國的軟體出口到美國,在美國人的電腦上就會顯示亂碼,因為他們沒有gbk編碼。
所以該怎麼辦呢?
還記得我們講unicode其中一個功能是其包含了跟全球所有國家編碼的映射關係,這時就派上用場了。
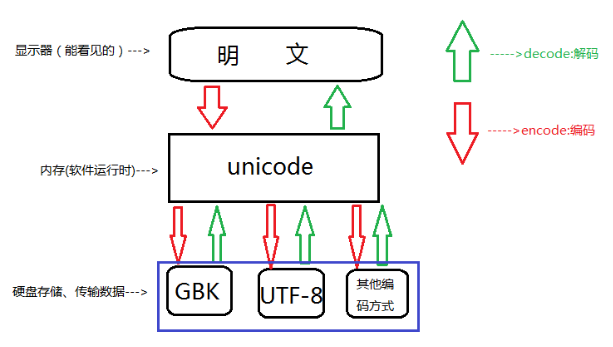
無論你以什麼編碼存儲的數據,只要你的軟體在把數據從硬碟讀到記憶體里,轉成unicode來顯示,就可以了。
由於所有的系統、編程語言都預設支持unicode,那你的gbk軟體放到美國電腦上,載入到記憶體里,變成了unicode,
中文就可以正常展示啦
Python3執行過程
1、解釋器找到代碼文件,把代碼字元串按文件頭定義的編碼載入到記憶體,轉成unicode 2、把代碼字元串按照語法規則進行解釋 3、所有的變數字元都會以unicode編碼聲明
在py3上把你的代碼以utf-8編寫,保存,然後在windows上執行。
發現可以正常執行!
其實utf-8編碼之所以能在windows gbk的終端下顯示正常,是因為到了記憶體里python解釋器把utf-8轉成了unicode , 但是這
只是python3, 並不是所有的編程語言在記憶體里預設編碼都是unicode,比如萬惡的python2 就不是,它是ASCII(龜叔當初設計
Python時的一點缺陷),想寫中文,就必須聲明文件頭的coding為gbk or utf-8, 聲明之後,python2解釋器僅以文件頭聲明的
編碼去解釋你的代碼,載入到記憶體後,並不會主動幫你轉為unicode,也就是說,你的文件編碼是utf-8,載入到記憶體里,你的變
量字元串就也是utf-8, 這意味著什麼?意味著,你以utf-8編碼的文件,在windows是亂碼。
其實亂是正常的,不亂才不正常,因為只有2種情況,你的windows上顯示才不會亂。
1、字元串以GBK格式顯示 2、字元串是unicode編碼
Python2並不會自動的把文件編碼轉為unicode存在記憶體里。
所以我們只有手動轉,Python3 自動把文件編碼轉為unicode必定是調用了什麼方法,這個方法就是,decode(解碼) 和encode
(編碼)
方法如下:
UTF-8/GBK --> decode 解碼 --> Unicode
Unicode --> encode 編碼 --> GBK / UTF-8
例如:
#!/usr/bin/env python3 #-*- coding:utf-8 -*- # write by congcong s = '匆匆' print(s) s1 = s.decode("utf-8") # utf-8 轉成 Unicode,decode(解碼)需要註明當前編碼格式 print(s1,type(s1)) s2 = s1.encode("gbk") # unicode 轉成 gbk,encode(編碼)需要註明生成的編碼格式 print(s2,type(s2)) s3 = s1.encode("utf-8") # unicode 轉成 utf-8,encode(編碼)註明生成的編碼格式 print(s3,type(s3))
文件在 Python2 和 Python3 環境下運行結果的區別,如下所示:
#coding:utf-8 s = "你好,中國!" print(s) # Python2輸出亂碼,Python3正常輸出 print(type(s)) # 均輸出 <type 'str'> #解碼成unicode s1 = s.decode("utf-8") print(s1) # Python2中輸出 “你好,中國!”,Python3顯示'str'對象沒有屬性'decode' print(type(s1)) # Python2中輸出 <type 'unicode'> Python3中輸出 <class 'str'> #編碼成gbk 或 utf-8 s2 = s1.encode('gbk') print(s2) # Python2中輸出 “你好,中國!” print(type(s2)) # Python2中輸出 <type 'str'> s3 = s1.encode('utf-8') print(s3) # Python2輸出亂碼, print(type(s3)) # 輸出 <type 'str'>
編碼相互轉換的規則如下:
(4)如何驗證編碼轉對了呢?
1、查看數據類型,python 2 里有專門的unicode 類型
2、查看unicode編碼映射表
unicode字元是有專門的unicode類型來判斷的,但是utf-8,gbk編碼的字元都是str,你如果分辨出來的當前的字元串數據是
何種編碼的呢?
有人說可以通過位元組長度判斷,因為utf-8一個中文占3位元組,gbk一個占2位元組。
看輸出的位元組個數,也能大體判斷是什麼類型。精確的驗證一個字元的編碼呢,就是拿這些16進位的數跟編碼表裡去匹配。
關於 Unicode 與 GBK 等編碼對應關係(以中文“路”為例):

完整的編碼對應表可到這個網站下載:unicode與gbk的映射表 http://www.unicode.org/charts/
(5)Python byte類型
把8個二進位一組稱為一個byte,用16進位來表示。為的就是讓人們看起來更可讀。我們稱之為bytes類型,即位元組類型。
python2的字元串其實更應該稱為位元組串。 通過存儲方式就能看出來, 但python2里還有一個類型是bytes呀,難道又叫bytes
又叫字元串?
嗯 ,是的,在python2里,bytes == str , 其實就是一回事。
除此之外呢, python2里還有個單獨的類型是unicode , 把字元串解碼後,就會變成unicode。
>>> s '\xe8\xb7\xaf\xe9\xa3\x9e' #utf-8 >>> s.decode('utf-8') u'\u8def\u98de' #unicode 在unicode編碼表裡對應的位置 >>> print(s.decode('utf-8')) 路飛 #unicode 格式的字元
Python2的預設編碼是ASCII碼,當後來大家對支持漢字、日文、法語等語言的呼聲越來越高時,Python於是準備引入
unicode,但若直接把預設編碼改成unicode的話是不現實的, 因為很多軟體就是基於之前的預設編碼ASCII開發的,編碼一換
,那些軟體的編碼就都亂了。所以Python 2就直接搞了一個新的字元類型,就叫unicode類型,比如你想讓你的中文在全球
所有電腦上正常顯示,在記憶體里就得把字元串存成unicode類型。
>>> s = "路飛" >>> s '\xe8\xb7\xaf\xe9\xa3\x9e' >>> s2 = s.decode("utf-8") >>> s2 u'\u8def\u98de' >>> type(s2) <type 'unicode'>
註意:
Python3 除了把字元串的編碼改成了unicode, 還把str 和bytes 做了明確區分, str 就是unicode格式的字元, bytes就是單
純二進位啦。
在py3里看字元,必須得是unicode編碼,其它編碼一律按bytes格式展示。
Python只要出現各種編碼問題,無非是哪裡的編碼設置出錯了
常見編碼錯誤的原因有以下這些:
Python解釋器的預設編碼
Python源文件文件編碼
Terminal使用的編碼
操作系統的語言設置
最後總結一下:
python3:文件預設編碼是utf-8 , 字元串編碼是 unicode以utf-8 或者 gbk等編碼的代碼,載入到記憶體,會自動轉為unicode
正常顯示。
python2:文件預設編碼是ascii , 字元串編碼也是 ascii , 如果文件頭聲明瞭是gbk,那字元串編碼就是gbk。以utf-8 或者 gbk
等編碼的代碼,載入到記憶體,並不會轉為unicode,編碼仍然是utf-8或者gbk等編碼。


