
併發容器 一、ConcurrentHashMap 【1】引入ConcurrentHashMap的目的 ConcurrentHashMap從JDK1.5開始隨java.util.concurrent包一起引入JDK中,主要為瞭解決HashMap線程不安全和Hashtable效率不高的問題。眾所周知 ...
併發容器
一、ConcurrentHashMap
【1】引入ConcurrentHashMap的目的
ConcurrentHashMap從JDK1.5開始隨java.util.concurrent包一起引入JDK中,主要為瞭解決HashMap線程不安全和Hashtable效率不高的問題。眾所周知,HashMap在多線程編程中是線程不安全的,而Hashtable由於使用了synchronized修飾方法而導致執行效率不高;因此,在concurrent包中,實現了ConcurrentHashMap以使在多線程編程中可以使用一個高性能的線程安全HashMap方案。
【2】ConcurrentHashMap的實現——JDK7
2.1 分段鎖機制
Hashtable效率低下的主要原因是其實現使用了synchronized關鍵字對put等操作進行加鎖,而synchronized關鍵字加鎖是對整個對象進行加鎖,也就是說在進行put等修改Hash表的操作時,鎖住了整個Hash表,從而使得其表現的效率低下;因此,在JDK1.5~1.7版本,Java使用了分段鎖機制實現ConcurrentHashMap.
2.2 數據結構
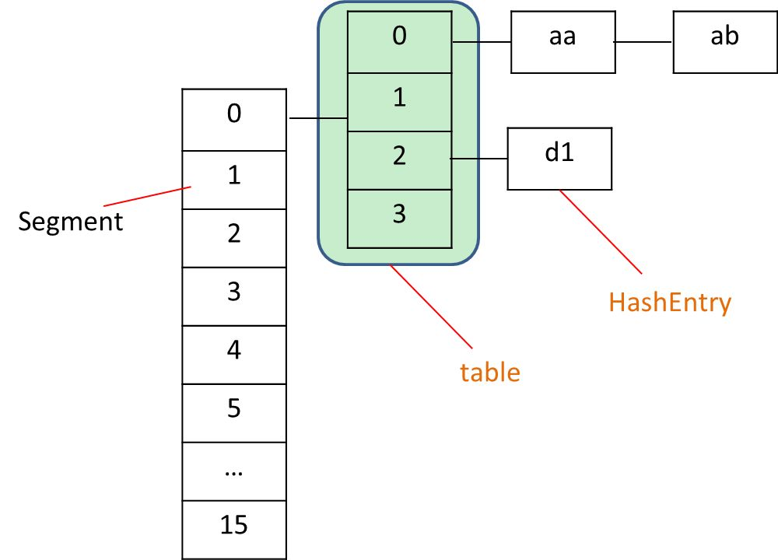
在ConcurrentHashMap中,定義了一個Segment<K, V>[]數組來將Hash表實現分段存儲,從而實現分段加鎖;而麽一個Segment元素則與HashMap結構類似,其包含了一個HashEntry數組,用來存儲Key/Value對。Segment繼承了ReetrantLock,表示Segment是一個可重入鎖,因此ConcurrentHashMap通過可重入鎖對每個分段進行加鎖。
2.3 初始化
ConcurrentHashMap初始化時,計算出Segment數組的大小ssize和每個Segment中HashEntry數組的大小cap,並初始化Segment數組的第一個元素;其中ssize大小為2的冪次方,預設為16,cap大小也是2的冪次方,最小值為2,最終結果根據根據初始化容量initialCapacity進行計算
ConcurrentHashMap包含多個構造函數,而所有的構造函數最終都調用瞭如下的構造函數:
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}2.4 相關操作
put實現
當執行put方法插入數據時,根據key的hash值,在Segment數組中找到相應的位置,如果相應位置的Segment還未初始化,則通過CAS進行賦值,接著執行Segment對象的put方法通過加鎖機制插入數據,實現如下:
場景:線程A和線程B同時執行相同Segment對象的put方法
1、線程A執行tryLock()方法成功獲取鎖,則把HashEntry對象插入到相應的位置;
2、線程B獲取鎖失敗,則執行scanAndLockForPut()方法,在scanAndLockForPut方法中,會通過重覆執行tryLock()方法嘗試獲取鎖,在多處理器環境下,重覆次數為64,單處理器重覆次數為1,當執行tryLock()方法的次數超過上限時,則執行lock()方法掛起線程B;
3、當線程A執行完插入操作時,會通過unlock()方法釋放鎖,接著喚醒線程B繼續執行;
size實現
因為ConcurrentHashMap是可以併發插入數據的,所以在準確計算元素時存在一定的難度,一般的思路是統計每個Segment對象中的元素個數,然後進行累加,但是這種方式計算出來的結果並不一樣的準確的,因為在計算後面幾個Segment的元素個數時,已經計算過的Segment同時可能有數據的插入或則刪除,在1.7的實現中,採用瞭如下方式:
1、先採用不加鎖的方式,連續計算元素的個數,最多計算3次:
2、如果前後兩次計算結果相同,則說明計算出來的元素個數是準確的;
3、如果前後兩次計算結果都不同,則給依次每個Segment進行加鎖,再計算一次元素的個數,然後再依次釋放鎖;
【3】ConcurrentHashMap的實現——JDK8
在JDK1.7之前,ConcurrentHashMap是通過分段鎖機制來實現的,所以其最大併發度受Segment的個數限制。因此,在JDK1.8中,ConcurrentHashMap的實現原理摒棄了這種設計,而是選擇了與HashMap類似的數組+鏈表+紅黑樹的方式實現,而加鎖則採用CAS和synchronized實現。
3.1 數據結構

JDK1.8的ConcurrentHashMap數據結構比JDK1.7之前的要簡單的多,其使用的是HashMap一樣的數據結構:數組+鏈表+紅黑樹。ConcurrentHashMap中包含一個table數組,其類型是一個Node數組;而Node是一個繼承自Map.Entry<K, V>的鏈表,而當這個鏈表結構中的數據大於8,則將數據結構升級為TreeBin類型的紅黑樹結構。另外,JDK1.8中的ConcurrentHashMap中還包含一個重要屬性sizeCtl,其是一個控制標識符,不同的值代表不同的意思:其為0時,表示hash表還未初始化,而為正數時這個數值表示初始化或下一次擴容的大小,相當於一個閾值;即如果hash表的實際大小>=sizeCtl,則進行擴容,預設情況下其是當前ConcurrentHashMap容量的0.75倍;而如果sizeCtl為-1,表示正在進行初始化操作;而為-N時,則表示有N-1個線程正在進行擴容。
3.2 初始化
只有在執行第一次put方法時才會調用initTable()初始化Node數組,實現如下:
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}3.3 相關操作
put實現
當執行put方法插入數據時,根據key的hash值,在Node數組中找到相應的位置,實現如下:
1、如果相應位置的Node還未初始化,則通過CAS插入相應的數據;
2、如果相應位置的Node不為空,且當前該節點不處於移動狀態,則對該節點加synchronized鎖,如果該節點的hash不小於0,則遍歷鏈表更新節點或插入新節點;
3、如果該節點是TreeBin類型的節點,說明是紅黑樹結構,則通過putTreeVal方法往紅黑樹中插入節點;
4、如果binCount不為0,說明put操作對數據產生了影響,如果當前鏈表的個數達到8個,則通過treeifyBin方法轉化為紅黑樹,如果oldVal不為空,說明是一次更新操作,沒有對元素個數產生影響,則直接返回舊值;
5、如果插入的是一個新節點,則執行addCount()方法嘗試更新元素個數baseCount;
size實現
jdk1.8中使用一個volatile類型的變數baseCount記錄元素的個數,當插入新數據或則刪除數據時,會通過addCount()方法更新baseCount,實現如下:
1、初始化時counterCells為空,在併發量很高時,如果存在兩個線程同時執行CAS修改baseCount值,則失敗的線程會繼續執行方法體中的邏輯,使用CounterCell記錄元素個數的變化;
2、如果CounterCell數組counterCells為空,調用fullAddCount()方法進行初始化,並插入對應的記錄數,通過CAS設置cellsBusy欄位,只有設置成功的線程才能初始化CounterCell數組,實現如下:
3、如果通過CAS設置cellsBusy欄位失敗的話,則繼續嘗試通過CAS修改baseCount欄位,如果修改baseCount欄位成功的話,就退出迴圈,否則繼續迴圈插入CounterCell對象;
【4】總結
其實可以看出JDK1.8版本的ConcurrentHashMap的數據結構已經接近HashMap,相對而言,ConcurrentHashMap只是增加了同步的操作來控制併發,從JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+紅黑樹。
1.數據結構:取消了Segment分段鎖的數據結構,取而代之的是數組+鏈表+紅黑樹的結構。
2.保證線程安全機制:JDK1.7採用segment的分段鎖機制實現線程安全,其中segment繼承自ReentrantLock。JDK1.8採用CAS+Synchronized保證線程安全。
3.鎖的變化:原來是對需要進行數據操作的Segment加鎖,現調整為對每個數組元素加鎖(Node)。
4.鏈表轉化為紅黑樹:定位結點的hash演算法簡化會帶來弊端,Hash衝突加劇,因此在鏈表節點數量大於8時,會將鏈表轉化為紅黑樹進行存儲。
5.查詢時間複雜度:從原來的遍歷鏈表O(n),變成遍歷紅黑樹O(logN)。
二、阻塞隊列
註意:該隨筆內容完全引自http://wsmajunfeng.iteye.com/blog/1629354,寫的很好,非常感謝,複製過來算是個積累,怕以後找不到。
【1】前言
在新增的Concurrent包中,BlockingQueue很好的解決了多線程中,如何高效安全“傳輸”數據的問題。通過這些高效並且線程安全的隊列類,為我們快速搭建高質量的多線程程式帶來極大的便利。本文詳細介紹了BlockingQueue家庭中的所有成員,包括他們各自的功能以及常見使用場景。
【2】認識BlockingQueue
阻塞隊列,顧名思義,首先它是一個隊列,而一個隊列在數據結構中所起的作用大致如下圖所示:

從上圖我們可以很清楚看到,通過一個共用的隊列,可以使得數據由隊列的一端輸入,從另外一端輸出;
常用的隊列主要有以下兩種:(當然通過不同的實現方式,還可以延伸出很多不同類型的隊列,DelayQueue就是其中的一種)
先進先出(FIFO):先插入的隊列的元素也最先出隊列,類似於排隊的功能。從某種程度上來說這種隊列也體現了一種公平性。
後進先出(LIFO):後插入隊列的元素最先出隊列,這種隊列優先處理最近發生的事件。
多線程環境中,通過隊列可以很容易實現數據共用,比如經典的“生產者”和“消費者”模型中,通過隊列可以很便利地實現兩者之間的數據共用。假設我們有若幹生產者線程,另外又有若幹個消費者線程。如果生產者線程需要把準備好的數據共用給消費者線程,利用隊列的方式來傳遞數據,就可以很方便地解決他們之間的數據共用問題。但如果生產者和消費者在某個時間段內,萬一發生數據處理速度不匹配的情況呢?理想情況下,如果生產者產出數據的速度大於消費者消費的速度,並且當生產出來的數據累積到一定程度的時候,那麼生產者必須暫停等待一下(阻塞生產者線程),以便等待消費者線程把累積的數據處理完畢,反之亦然。然而,在concurrent包發佈以前,在多線程環境下,我們每個程式員都必須去自己控制這些細節,尤其還要兼顧效率和線程安全,而這會給我們的程式帶來不小的複雜度。好在此時,強大的concurrent包橫空出世了,而他也給我們帶來了強大的BlockingQueue。(在多線程領域:所謂阻塞,在某些情況下會掛起線程(即阻塞),一旦條件滿足,被掛起的線程又會自動被喚醒),下麵兩幅圖演示了BlockingQueue的兩個常見阻塞場景
:
如上圖所示:當隊列中沒有數據的情況下,消費者端的所有線程都會被自動阻塞(掛起),直到有數據放入隊列。

如上圖所示:當隊列中填滿數據的情況下,生產者端的所有線程都會被自動阻塞(掛起),直到隊列中有空的位置,線程被自動喚醒。
這也是我們在多線程環境下,為什麼需要BlockingQueue的原因。作為BlockingQueue的使用者,我們再也不需要關心什麼時候需要阻塞線程,什麼時候需要喚醒線程,因為這一切BlockingQueue都給你一手包辦了。既然BlockingQueue如此神通廣大,讓我們一起來見識下它的常用方法:
【3】 BlockingQueue的核心方法:
1.放入數據
(1)offer(anObject):表示如果可能的話,將anObject加到BlockingQueue里,即如果BlockingQueue可以容納,則返回true,否則返回false.(本方法不阻塞當前執行方法
的線程);
(2)offer(E o, long timeout, TimeUnit unit):可以設定等待的時間,如果在指定的時間內,還不能往隊列中加入BlockingQueue,則返回失敗。
(3)put(anObject):把anObject加到BlockingQueue里,如果BlockQueue沒有空間,則調用此方法的線程被阻斷直到BlockingQueue裡面有空間再繼續.
- 獲取數據
(1)poll(time):取走BlockingQueue里排在首位的對象,若不能立即取出,則可以等time參數規定的時間,取不到時返回null;
(2)poll(long timeout, TimeUnit unit):從BlockingQueue取出一個隊首的對象,如果在指定時間內,隊列一旦有數據可取,則立即返回隊列中的數據。否則知道時間
超時還沒有數據可取,返回失敗。
(3)take():取走BlockingQueue里排在首位的對象,若BlockingQueue為空,阻斷進入等待狀態直到BlockingQueue有新的數據被加入;
(4)drainTo():一次性從BlockingQueue獲取所有可用的數據對象(還可以指定獲取數據的個數),通過該方法,可以提升獲取數據效率;不需要多次分批加鎖或釋放鎖。
【4】常見BlockingQueue
在瞭解了BlockingQueue的基本功能後,讓我們來看看BlockingQueue家庭大致有哪些成員?

- ArrayBlockingQueue
基於數組的阻塞隊列實現,在ArrayBlockingQueue內部,維護了一個定長數組,以便緩存隊列中的數據對象,這是一個常用的阻塞隊列,除了一個定長數組外,ArrayBlockingQueue內部還保存著兩個整形變數,分別標識著隊列的頭部和尾部在數組中的位置。
ArrayBlockingQueue在生產者放入數據和消費者獲取數據,都是共用同一個鎖對象,由此也意味著兩者無法真正並行運行,這點尤其不同於LinkedBlockingQueue;按照實現原理來分析,ArrayBlockingQueue完全可以採用分離鎖,從而實現生產者和消費者操作的完全並行運行。Doug Lea之所以沒這樣去做,也許是因為ArrayBlockingQueue的數據寫入和獲取操作已經足夠輕巧,以至於引入獨立的鎖機制,除了給代碼帶來額外的複雜性外,其在性能上完全占不到任何便宜。 ArrayBlockingQueue和LinkedBlockingQueue間還有一個明顯的不同之處在於,前者在插入或刪除元素時不會產生或銷毀任何額外的對象實例,而後者則會生成一個額外的Node對象。這在長時間內需要高效併發地處理大批量數據的系統中,其對於GC的影響還是存在一定的區別。而在創建ArrayBlockingQueue時,我們還可以控制對象的內部鎖是否採用公平鎖,預設採用非公平鎖。
2.LinkedBlockingQueue
基於鏈表的阻塞隊列,同ArrayListBlockingQueue類似,其內部也維持著一個數據緩衝隊列(該隊列由一個鏈表構成),當生產者往隊列中放入一個數據時,隊列會從生產者手中獲取數據,並緩存在隊列內部,而生產者立即返回;只有當隊列緩衝區達到最大值緩存容量時(LinkedBlockingQueue可以通過構造函數指定該值),才會阻塞生產者隊列,直到消費者從隊列中消費掉一份數據,生產者線程會被喚醒,反之對於消費者這端的處理也基於同樣的原理。而LinkedBlockingQueue之所以能夠高效的處理併發數據,還因為其對於生產者端和消費者端分別採用了獨立的鎖來控制數據同步,這也意味著在高併發的情況下生產者和消費者可以並行地操作隊列中的數據,以此來提高整個隊列的併發性能。
作為開發者,我們需要註意的是,如果構造一個LinkedBlockingQueue對象,而沒有指定其容量大小,LinkedBlockingQueue會預設一個類似無限大小的容量(Integer.MAX_VALUE),這樣的話,如果生產者的速度一旦大於消費者的速度,也許還沒有等到隊列滿阻塞產生,系統記憶體就有可能已被消耗殆盡了。
ArrayBlockingQueue和LinkedBlockingQueue是兩個最普通也是最常用的阻塞隊列,一般情況下,在處理多線程間的生產者消費者問題,使用這兩個類足以。
下麵的代碼演示瞭如何使用BlockingQueue:
(1) 測試類
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
public class BlockingQueueTest {
public static void main(String[] args) throws InterruptedException {
// 聲明一個容量為10的緩存隊列
BlockingQueue<String> queue = new LinkedBlockingQueue<String>(10);
//new了三個生產者和一個消費者
Producer producer1 = new Producer(queue);
Producer producer2 = new Producer(queue);
Producer producer3 = new Producer(queue);
Consumer consumer = new Consumer(queue);
// 藉助Executors
ExecutorService service = Executors.newCachedThreadPool();
// 啟動線程
service.execute(producer1);
service.execute(producer2);
service.execute(producer3);
service.execute(consumer);
// 執行10s
Thread.sleep(10 * 1000);
producer1.stop();
producer2.stop();
producer3.stop();
Thread.sleep(2000);
// 退出Executor
service.shutdown();
}
}(2)生產者類
import java.util.Random;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 生產者線程
*
* @author jackyuj
*/
public class Producer implements Runnable {
private volatile boolean isRunning = true;//是否在運行標誌
private BlockingQueue queue;//阻塞隊列
private static AtomicInteger count = new AtomicInteger();//自動更新的值
private static final int DEFAULT_RANGE_FOR_SLEEP = 1000;
//構造函數
public Producer(BlockingQueue queue) {
this.queue = queue;
}
public void run() {
String data = null;
Random r = new Random();
System.out.println("啟動生產者線程!");
try {
while (isRunning) {
System.out.println("正在生產數據...");
Thread.sleep(r.nextInt(DEFAULT_RANGE_FOR_SLEEP));//取0~DEFAULT_RANGE_FOR_SLEEP值的一個隨機數
data = "data:" + count.incrementAndGet();//以原子方式將count當前值加1
System.out.println("將數據:" + data + "放入隊列...");
if (!queue.offer(data, 2, TimeUnit.SECONDS)) {//設定的等待時間為2s,如果超過2s還沒加進去返回true
System.out.println("放入數據失敗:" + data);
}
}
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
} finally {
System.out.println("退出生產者線程!");
}
}
public void stop() {
isRunning = false;
}
}(3)消費者類
import java.util.Random;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.TimeUnit;
/**
* 消費者線程
*
* @author jackyuj
*/
public class Consumer implements Runnable {
private BlockingQueue<String> queue;
private static final int DEFAULT_RANGE_FOR_SLEEP = 1000;
//構造函數
public Consumer(BlockingQueue<String> queue) {
this.queue = queue;
}
public void run() {
System.out.println("啟動消費者線程!");
Random r = new Random();
boolean isRunning = true;
try {
while (isRunning) {
System.out.println("正從隊列獲取數據...");
String data = queue.poll(2, TimeUnit.SECONDS);//有數據時直接從隊列的隊首取走,無數據時阻塞,在2s內有數據,取走,超過2s還沒數據,返回失敗
if (null != data) {
System.out.println("拿到數據:" + data);
System.out.println("正在消費數據:" + data);
Thread.sleep(r.nextInt(DEFAULT_RANGE_FOR_SLEEP));
} else {
// 超過2s還沒數據,認為所有生產線程都已經退出,自動退出消費線程。
isRunning = false;
}
}
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
} finally {
System.out.println("退出消費者線程!");
}
}
}3. DelayQueue
DelayQueue中的元素只有當其指定的延遲時間到了,才能夠從隊列中獲取到該元素。DelayQueue是一個沒有大小限制的隊列,因此往隊列中插入數據的操作(生產者)永遠不會被阻塞,而只有獲取數據的操作(消費者)才會被阻塞。
使用場景:
DelayQueue使用場景較少,但都相當巧妙,常見的例子比如使用一個DelayQueue來管理一個超時未響應的連接隊列。
4. PriorityBlockingQueue
基於優先順序的阻塞隊列(優先順序的判斷通過構造函數傳入的Compator對象來決定),但需要註意的是PriorityBlockingQueue並不會阻塞數據生產者,而只會在沒有可消費的數據時,阻塞數據的消費者。因此使用的時候要特別註意,生產者生產數據的速度絕對不能快於消費者消費數據的速度,否則時間一長,會最終耗盡所有的可用堆記憶體空間。在實現PriorityBlockingQueue時,內部控制線程同步的鎖採用的是公平鎖。
5. SynchronousQueue
一種無緩衝的等待隊列,類似於無中介的直接交易,有點像原始社會中的生產者和消費者,生產者拿著產品去集市銷售給產品的最終消費者,而消費者必須親自去集市找到所要商品的直接生產者,如果一方沒有找到合適的目標,那麼對不起,大家都在集市等待。相對於有緩衝的BlockingQueue來說,少了一個中間經銷商的環節(緩衝區),如果有經銷商,生產者直接把產品批發給經銷商,而無需在意經銷商最終會將這些產品賣給那些消費者,由於經銷商可以庫存一部分商品,因此相對於直接交易模式,總體來說採用中間經銷商的模式會吞吐量高一些(可以批量買賣);但另一方面,又因為經銷商的引入,使得產品從生產者到消費者中間增加了額外的交易環節,單個產品的及時響應性能可能會降低。
聲明一個SynchronousQueue有兩種不同的方式,它們之間有著不太一樣的行為。公平模式和非公平模式的區別:
如果採用公平模式:SynchronousQueue會採用公平鎖,並配合一個FIFO隊列來阻塞多餘的生產者和消費者,從而體系整體的公平策略;
但如果是非公平模式(SynchronousQueue預設):SynchronousQueue採用非公平鎖,同時配合一個LIFO隊列來管理多餘的生產者和消費者,而後一種模式,如果生產者和消費者的處理速度有差距,則很容易出現饑渴的情況,即可能有某些生產者或者是消費者的數據永遠都得不到處理。
五. 小結
BlockingQueue不光實現了一個完整隊列所具有的基本功能,同時在多線程環境下,他還自動管理了多線間的自動等待於喚醒功能,從而使得程式員可以忽略這些細節,關註更高級的功能。


