
前面的文章中我們講道,像趣頭條類的APP對於收徒和閱讀行為給予用戶現金獎勵的方式勢必會受到大量羊毛黨黑產的註意,其實單個用戶能薅到的錢是沒有多少的,為了達到利益最大化,黑產肯定會利用各種手段構建大量賬號來薅APP運營企業的羊毛,因為收徒的獎勵遠高於閱讀,所以賺取收徒獎勵就成了最嚴重的薅羊毛手段。前文 ...
前面的文章中我們講道,像趣頭條類的APP對於收徒和閱讀行為給予用戶現金獎勵的方式勢必會受到大量羊毛黨黑產的註意,其實單個用戶能薅到的錢是沒有多少的,為了達到利益最大化,黑產肯定會利用各種手段構建大量賬號來薅APP運營企業的羊毛,因為收徒的獎勵遠高於閱讀,所以賺取收徒獎勵就成了最嚴重的薅羊毛手段。前文提到為了更好的識別出這些異常用戶,我們利用用戶的師徒關係構建連通圖,把同一個連通圖上的用戶視為一個社群,利用Spark Grahpx實現了一個簡單高效的社群發現功能。具體內容可以查看上一篇文章《基於Spark Grahpx+Neo4j 實現用戶社群發現》,但生成社群不是目的,我們的目標是能夠對社群用戶進行分析,根據規則和演算法的方法找出社群內的異常用戶及異常社群,從而達到風控的目的。
規則的方法主要是,我們在設備,IP,用戶基礎信息,用戶行為信息等維度組合構建用戶的風控畫像,然後開發規則引擎,制定閾值,過濾出超過閾值的異常用戶。但只通過規則的方法往往是不夠的,大量的用戶單從個體上看看不出多少異常,但如果上升一個層次,從社群的整體角度去分析,就會發現用戶的很多相似之處。
就像我們之前文章說的壞人往往是扎堆的,物以類聚,人以群分,而且黑產想達到一定規模,肯定會藉助作弊設備,腳本,機器等手段,機器的行為一般都有一些相似性,我們就可以利用這些相似性對用戶進行聚類分析,所以除了規則的方法外,我們還可以用機器學習的方法將具有相似行為的用戶進行聚類,然後求出類簇的TOP N相似特征,查看是否可疑,比如設備是否相似,行為是否相似,基本信息,賬號等是否相似,通過機器學習的方法,我們能找出很多規則沒法判定的異常用戶。
聚類就是把相似的用戶聚在一起,一般的方法就是計算兩個用戶特征向量的相似度,這就遇到了第一個問題,對於大量用戶來說,兩兩用戶計算相似度計算量是非常可怕的,比如50萬用戶兩兩計算相似度,總共要計算50w * 50w =2500億次,這計算量就太大了,如果用戶量再大點根本無法計算。對於這種情況,人們一般會利用局部敏感哈希等優化演算法將數據進行降維,然後通過哈希把相似的用戶儘可能的放到同一個桶里,最後再對同一個桶里的數據進行兩兩計算,這樣計算量就小很多了。
下圖是局部敏感哈希演算法的一個示意圖,普通的哈希演算法是儘量將數據打散到不同的桶里,達到減少碰撞的目的,但局部敏感哈希旨在將相似的用戶放到相同的桶里。Spark的Mllib庫里也提供了LSH局部敏感哈希演算法的實現,有興趣的朋友可以自行查看。
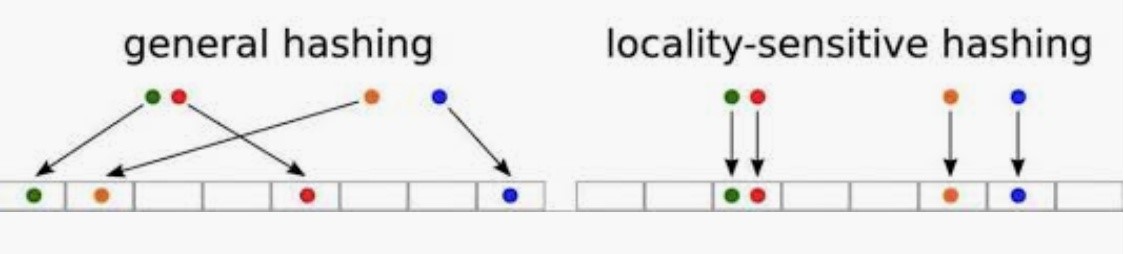
不過我們在用Spark LSH跑數據的過程中,遇到了每次都是最後幾個task特別緩慢的情況,可能跟數據傾斜或CPU計算能力不足有關,多次調試都沒有太好的效果,又限於資源有限,只能另想別的方法,忽然想到我們之前已經按師徒關係生成的社群,本身就是一種把相似用戶放到同一個桶里的操作,而且我們根據師徒關係構建連通圖得到的社群應該是已經很好的把有可能是一個團夥的人聚到了一起,這樣的話,只需對每個社群進行相似度計算就可以了。
計算相似度的方法有多種,像歐氏距離,漢明距離,餘弦相似度,Jaccard 繫數等都是常用的度量方法,但鑒於我們提取的用戶特征既有數值型,又有字元型,而且用戶特征維度一樣,我們想通過定義用戶有多少個共同特征就判為相似的邏輯,所以我們選擇了一個比較簡單的f,即對比兩用戶特征數組相同特征數,滿足閾值即為相似。
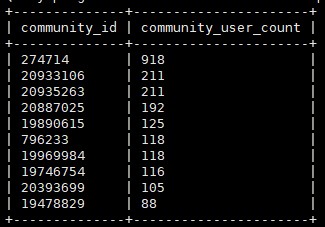
不同社群用戶數
上圖是我們根據師徒關係生成的不同社群及社群人數,下圖為我們基於這些社群,分別計算出的社群內相似用戶及用戶的相似特征。

從上圖可以看出這些相似用戶,有些社群全部是同一個手機型號,並且開機時間相同,手機一直處於充電狀態,師徒高度集中等等,這些都是比較可疑的用戶,需要風控人員重點分析。
至此,我們通過社群相似度計算實現了一個簡單的風控聚類模型,基於這個模型找出了一些相似用戶,而且我們可以增加更多的用戶特征,調節模型閾值來達到更好的風控效果。後面我們還計劃給每個特征定義權重,這樣就可以對社群進行打分,進而可以更直觀的判斷社群的優劣與否。
定義特征權重如下
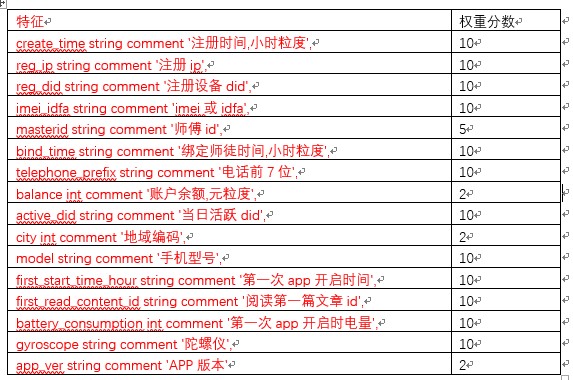
打分規則
目前相似社群風控分數打分規則為:
- 特征占比大於等於50%的特征為該相似社群的相似特征;
- 相似社群風控分數 = 相似特征占比乘以特征權重的累加和
- 如果存在權重大於等於10的相似特征,相似社群風控分數要再加上用戶數mod 100,即每100用戶加1分
比如下麵為相似社群的用戶數和相似特征占比
778 //相似社群用戶數
97% of 'app_ver' is '3.9.1', //權重為2
72% of 'masterid' is '599aa668c0d9db00014239e7', //權重為5
53% of 'battery_consumption' is '100' //權重為10
//計算相似社群風控分數如下
Score = 0.972 + 0.725 + 0.5310 + (778 mod 100) 1 = 17.84
查詢結果表如下




