
淘寶架構 我們以淘寶架構為例,瞭解下大型的電商項目的服務端的架構是怎樣,如圖所示 上面是一些安全體繫系統,如數據安全體系、應用安全體系、前端安全體系等。 中間是業務運營服務系統,如會員服務、商品服務、店鋪服務、交易服務等。 還有共用業務,如分散式數據層、數據分析服務、配置服務、數據搜索服務等。 最下 ...
淘寶架構
我們以淘寶架構為例,瞭解下大型的電商項目的服務端的架構是怎樣,如圖所示
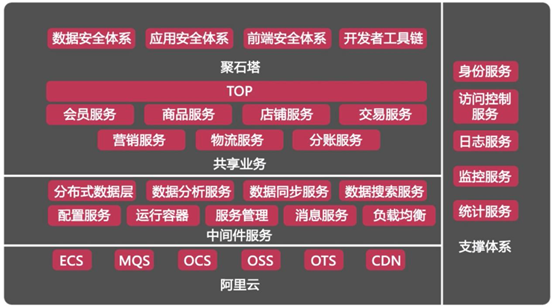
上面是一些安全體繫系統,如數據安全體系、應用安全體系、前端安全體系等。
中間是業務運營服務系統,如會員服務、商品服務、店鋪服務、交易服務等。
還有共用業務,如分散式數據層、數據分析服務、配置服務、數據搜索服務等。
最下麵呢,是中間件服務,如MQS即隊列服務,OCS即緩存服務等。
圖中也有一些看不到,例如高可用的一個體現,實現雙機房容災和異地機房單元化部署,為淘寶業務提供穩定、高效和易於維護的基礎架構支撐。
這是一個含金量非常高的架構,也是一個非常複雜而龐大的架構。當然這個也不是一天兩天演進成這樣的,也不是一上來就設計並開發成這樣高大上的架構的。
這邊就要說一下,小型公司要怎麼做呢?對很多創業公司而言,很難在初期就預估到流量十倍、百倍以及千倍以後網站架構會是什麼樣的一個狀況。同時,如果系統初期就設計一個千萬級併發的流量架構,很難有公司可以支撐這個成本。
因此,一個大型服務系統都是從小一步一步走過來的,在每個階段,找到對應該階段網站架構所面臨的問題,然後在不斷解決這些問題,在這個過程中整個架構會一直演進。
那我們來一起看一下。
單伺服器-俗稱all in one

從一個小網站說起。一臺伺服器也就足夠了。文件伺服器,資料庫,還有應用都部署在一臺機器,俗稱ALL IN ONE
隨著我們用戶越來越多,訪問越來越大,硬碟,CPU,記憶體等都開始吃緊。一臺伺服器已經滿足不了。這個時候看一下下一步演進
數據服務與應用服務分離
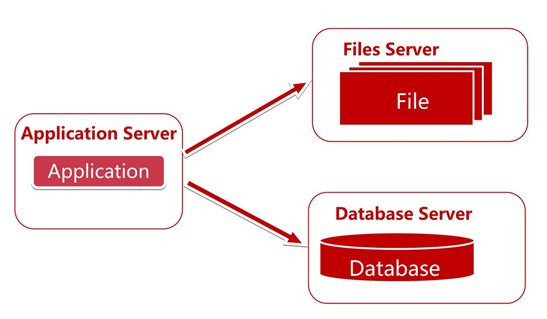
我們將數據服務和應用服務分離,給應用伺服器配置更好的 CPU,記憶體。而給數據伺服器配置更好更大的硬碟。
分離之後提高一定的可用性,例如Files
Server掛了,我們還是可以操作應用和資料庫等。
隨著訪問qps越來越高,降低介面訪問時間,提高服務性能和併發,成為了我們下一個目標,發現有很多業務數據不需要每次都從資料庫獲取。
使用緩存,包括本地緩存,遠程緩存,遠程分散式緩存

因為 80% 的業務訪問都集中在 20% 的數據上,也就是我們經常說的28法則。如果我們能將這部分數據緩存下來,性能一下子就上來了。而緩存又分為兩種:本地緩存和遠程緩存緩存,以及遠程分散式緩存,我們這裡面的遠程緩存圖上畫的是分散式的緩存集群(Cluster)。
思考的點
- . 具有哪種業務特點數據使用緩存?
- . 具有哪種業務特點的數據使用本地緩存?
- . 具有哪種務特點的數據使用遠程緩存?
- . 分散式緩存在擴容時候會碰到什麼問題?如何解決?分散式緩存的演算法都有哪幾種?各有什麼優缺點?
這個時候隨著訪問qps的提高,伺服器的處理能力會成為瓶頸。雖然是可以通過購買更強大的硬體,但總會有上限,而且這個到後期成本就是指數級增長了,這時,我們就需要伺服器的集群。需要使我們的伺服器可以橫向擴展,這時,就必須加個新東西:負載均衡調度伺服器。
使用負載均衡,進行伺服器集群
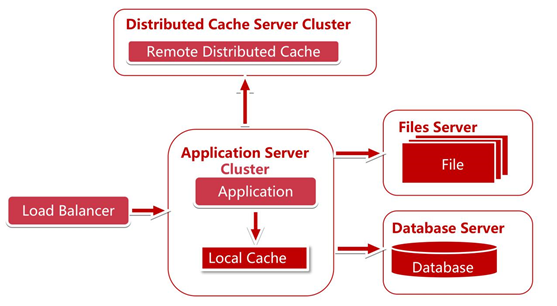
增加了負載均衡,伺服器集群之後,我們可以橫向擴展伺服器,解決了伺服器處理能力的瓶頸。
思考的點
- . 負載均衡的調度策略都有哪些?
- . 各有什麼優缺點?
- . 各適合什麼場景?
打個比方,我們有輪詢,權重,地址散列,地址散列又分為原ip地址散列hash,目標ip地址散列hash,最少連接,加權最少連接,還有繼續升級的很多種策略......我們一起來分析一下
典型負載均衡策略分析
- . 輪詢:優點:實現簡單,缺點:不考慮每台伺服器處理能力
- . 權重:優點:考慮了伺服器處理能力的不同
- . 地址散列:優點:能實現同一個用戶訪問同一個伺服器
- . 最少連接:優點:使集群中各個伺服器負載更加均勻
- . 加權最少連接:在最少連接的基礎上,為每台伺服器加上權值。演算法為(活動連接數*256+非活動連接數)/權重,計算出來的值小的伺服器優先被選擇。
繼續引出問題的場景:
我們的登錄的時候登錄了A伺服器,session信息存儲到A伺服器上了,假設我們使用的負載均衡策略是ip hash,那麼登錄信息還可以從A伺服器上訪問,但是這個有可能造成某些伺服器壓力過大,某些伺服器又沒有什麼壓力,這個時候壓力過大的機器(包括網卡帶寬)有可能成為瓶頸,並且請求不夠分散。
這時候我們使用輪詢或者最小連接負載均衡策略,就導致了,第一次訪問A伺服器,第二次可能訪問到B伺服器,這個時候存儲在A伺服器上的session信息在B伺服器上讀取不到。
Session管理-Session Sticky粘滯會話:

打個比方就是如果我們每次吃飯都要保證我們用的是自己的碗筷,而只要我們在一家飯店裡存著我們的碗筷,只要我們每次去這家飯店吃飯就好了。
對於同一個連接中的數據包,負載均衡會將其轉發至後端固定的伺服器進行處理。
解決了我們session共用的問題,但是它有什麼缺點呢?
- . 一臺伺服器運行的服務掛掉,或者重啟,上面的 session 都沒了
- . 負載均衡器成了有狀態的機器,為以後實現容災造成了羈絆
Session管理-Session 複製

就像我們在所有的飯店裡都存一份自己的碗筷。我們隨意去哪一家飯店吃飯都OK,不適合做大規模集群,適合機器不多的情況。
解決了我們session共用的問題,但是它有什麼缺點呢?
- . 應用伺服器間帶寬問題,因為需要不斷同步session數據
- . 大量用戶線上時,伺服器占用記憶體過多
Session管理-基於Cookie

打個比方,就是我們每次去飯店吃飯,都自己帶著自己的碗筷。
解決了我們session共用的問題,但是它有什麼缺點呢?
- . cookie 的長度限制
- . cookie存於瀏覽器,安全性是一個問題
Session管理-Session 伺服器

打個比方,就是我們的碗筷都存在了一個龐大的櫥櫃里,我們去任何一家飯店吃飯,都可以從櫥櫃中拿到屬於我們自己的碗筷。
解決了我們session共用的問題,這種方案需要思考哪些問題呢?
- . 保證 session 伺服器的可用性,session伺服器單點如何解決?
- . 我們在寫應用時需要做調整存儲session的業務邏輯
打個比方,我們為了提高session server的可用性,可以繼續給session server做集群
中間總結
所以說,網站架構在遇到某些指標瓶頸時,演進的過程中,都有哪些解決方案,他們都有什麼優缺點?業務功能上如何取捨?如何做出選擇?這個過程才是最重要的。
在解決了橫向擴展應用伺服器之後,那我們繼續~~
繼續回到目前架構圖
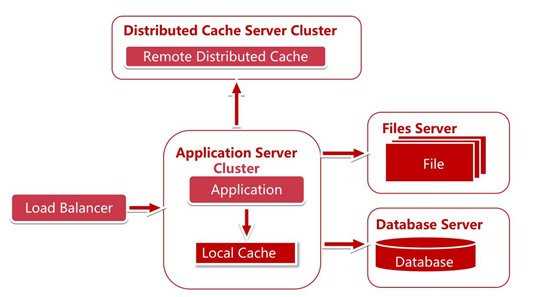
資料庫的讀及寫操作都還需要經過資料庫。當用戶量達到一定量,資料庫將會成為瓶頸。那我們如何來解決呢?
資料庫讀寫分離
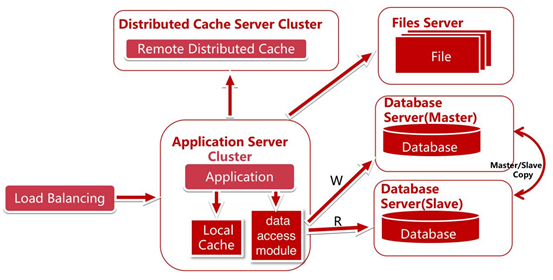
使用資料庫提供的熱備功能,將所有的讀操作引入slave 伺服器,因為資料庫的讀寫分離了,所以,我們的應用程式也得做相應的變化。我們實現一個數據訪問模塊(圖中的data access module)使上層寫代碼的人不知道讀寫分離的存在。這樣多數據源讀寫分離就對業務代碼沒有了侵入。這裡就引出了代碼層次的演變
思考的點
- . 如何支持多數據源?
- . 如何封裝對業務沒有侵入?
- . 如何使用目前業務的ORM框架完成主從讀寫分離?是否需要更換ORM模型?ORM模型之間各有什麼優缺點?
- . 如何取捨?
資料庫讀寫分離會遇到如下問題:
- . 在master和slave複製的時候,考慮延時問題、資料庫的支持、複製條件的支持。
- . 當為了提高可用性,將資料庫分機房後,跨機房傳輸同步數據,這個更是問題。
- . 應用對於數據源的路由問題
使用反向代理和 CDN 加速網站響應
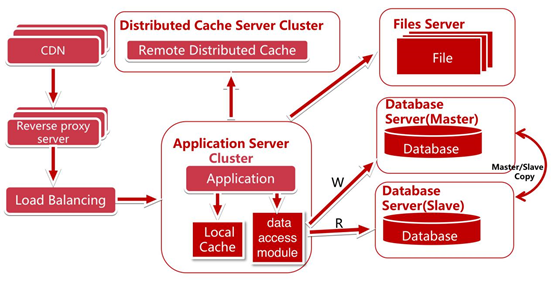
使用 CDN 可以很好的解決不同的地區的訪問速度問題,反向代理則在伺服器機房中緩存用戶資源。
訪問量越來越大,我們文件伺服器也出現了瓶頸。
分散式文件系統
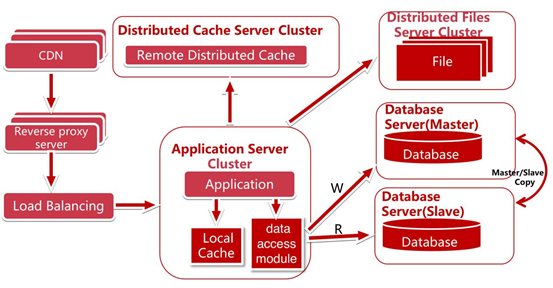
思考的點
- . 分散式文件系統如何不影響已部署線上上的業務訪問?不能讓某個圖片突然訪問不到呀
- . 是否需要業務部門清洗數據?
- . 是否需要重新做功能變數名稱解析?
這個時候資料庫又出現了瓶頸
數據垂直拆分

資料庫專庫專用,如圖Products、Users、Deal庫。
解決寫數據時,併發,量大的問題。
思考的點
- . 跨業務的事務?如何解決?使用分散式事務、去掉事務或不追求強事務
- . 應用的配置項多了
- . 如何跨庫進行數據的join操作
這個時候,某個業務的數據表的數據量或者更新量達到了單個資料庫的瓶頸
數據水平拆分

如圖,我們把User拆成了User1和User2,將同一個表的數據拆分到兩個資料庫中,解決了單資料庫的瓶頸。
思考的點
- . 水平拆分的策略都有哪些?各有什麼優缺點?
- . 水平拆分的時候如何清洗數據?
- . SQL 的路由問題,需要知道某個 User 在哪個資料庫上。
- . 主鍵的策略會有不同。
- . 假設我們系統中需要查詢2017年4月份已經下單過的用戶名的明細,而這些用戶分佈在user1和user2上,我們後臺運營系統在展示時如何分頁?
這個時候,公司對外部做了流量導入,我們應用中的搜索量飆升,繼續演進
拆分搜索引擎

使用搜索引擎,解決數據查詢問題。部分場景可使用 NoSQL 提高性能,開發數據統一訪問模塊,解決上層應用開發的數據源問題。如圖data access module 可以訪問資料庫,搜索引擎,NoSQL
最後總結
這個只是一個舉例演示,各個服務的技術架構是需要根據自己業務特點進行優化和演進的,所以大家的過程也不完全相同。
最後的這個也不是完美的,例如負載均衡還是一個單點,也需要集群,我們的這個架構呢也只是冰山一角,滄海一粟。在架構演進的過程中,還要考慮系統的安全性、數據分析、監控、反作弊等等......,同時繼續發展呢,SOA架構、服務化、消息隊列、任務調度、多機房等等… ...
從剛纔對架構演進的講解,也可以看出來,所有大型項目的架構和代碼,都是這麼一步一步的根據實際的業務場景,和發展情況發展演變而來的,在不同的階段,會使用的不同的技術,不同的架構來解決實際的問題,所以說,高大上的項目技術架構和開發設計實現不是一蹴而就的。
正是所謂的萬丈高樓平地起。在架構演進的過程中,小到核心模塊代碼,大到核心架構,都會不斷演進的,這個過程值得我們去深入學習和思考。


