
tidb隔離級別詳解: 1.TiDB 支持的隔離級別是 Snapshot Isolation(SI),它和 Repeatable Read(RR) 隔離級別基本等價,詳細情況如下: ● TiDB 的 SI 隔離級別可以剋服幻讀異常(Phantom Reads),但 ANSI/ISO SQL 標準中的 ...
tidb隔離級別詳解:
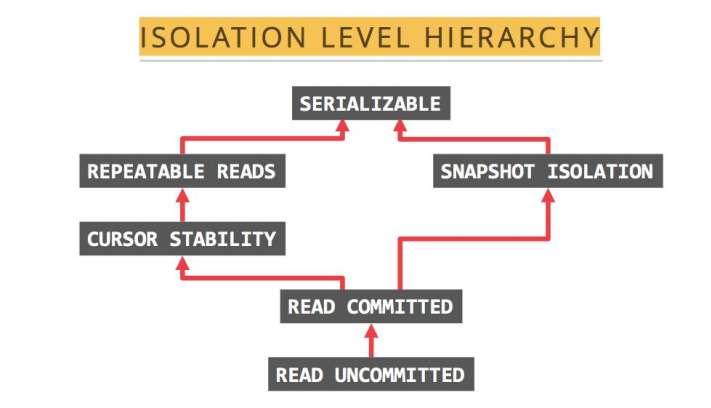
1.TiDB 支持的隔離級別是 Snapshot Isolation(SI),它和 Repeatable Read(RR) 隔離級別基本等價,詳細情況如下:
● TiDB 的 SI 隔離級別可以剋服幻讀異常(Phantom Reads),但 ANSI/ISO SQL 標準中的 RR 不能。 所謂幻讀是指:事務 A 首先根據條件查詢得到 n 條記錄,然後事務 B 改變了這 n 條記錄之的 m 條記錄或者增添了 m 條符合事務 A 查詢條件的記錄,導致事務 A 再次發起請求時發現有 n+m 條符合條件記錄,就產生了幻讀。 ● TiDB 的 SI 隔離級別不能剋服寫偏斜異常(Write Skew),需要使用 Select for update語法來剋服寫偏斜異常。寫偏斜異常是指兩個併發的事務讀取了兩行不同但相關的記錄,接著這兩個事務各自更新了自己讀到的那行數據,並最終都提交了事務,如果這兩行相關的記錄之間存在著某種約束,那麼最終結果可能是違反約束的。 例如,值班表有兩列,姓名以及值班狀態,0 代表不值班,1 代表值班| 姓名 | 值班狀態 |
| 張三 | 0 |
| 李四 | 0 |
| 王五 | 0 |
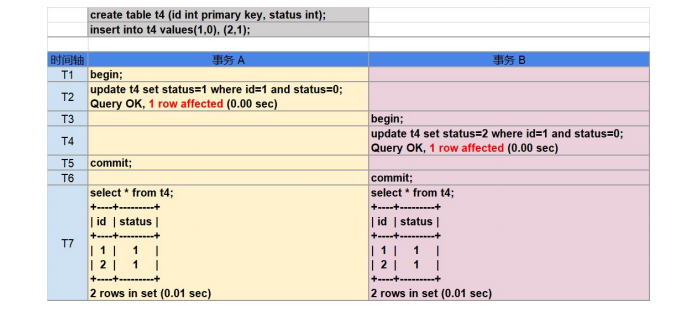
這是由於在顯式執行的事務中 DML 操作與提交操作分開被執行,在事務提交過程中,如果由於事務衝突,找不到 TiKV,網路不穩定等原因而發生了重試,TiDB 將獲取新的時間戳
重新執行本事務中的 DML 操作,原本的 SI 隔離級別在重試後會產生類似 RC 隔離級別的不可重覆讀與幻讀異常現象。 由於重試機制在內部完成,如果最終本事務提交成功,用戶一般是無法感知到是否發 生了重試的,因此不能通過 affected rows 來作為程式執行邏輯的判斷條件。 而隱式事務中(以單條 SQL 為單位進行提交),語句的返回是提交之後的結果,因此 隱式事務中的 affected rows 是可信的。 3. 避開丟失更新影響的應用開發方法 TiDB 使用了樂觀鎖機制,樂觀鎖僅在提交時才會進行衝突檢測和數據上鎖。在使用了 非 select for update 的 SQL 語句時,TiDB 會對提交時遇到衝突而發生退避的事務進行自動重 試(由 tidb_disable_txn_auto_retry 變數控制,預設行為是自動重試),當事務達到退避次數限 制(預設 10 次)依然不能成功提交時,事務會被回滾。 發生了退避的事務會重新獲取時間戳,重新執行事務中的增刪改語句,這樣設計是為 了規避上一次造成提交失敗的原因(包括但不限於鎖衝突),但也因此導致了併發事務可能出 現丟失更新異常。 可以通過妥善的應用實現方式來避免丟失更新造成的影響。 場景一,在不做餘額檢查的類似轉賬交易場景中,一般通過賬號篩選出需要修改餘額 的記錄,然後直接在資料庫中進行數學運算的 SQL 來實現對賬戶餘額的更新,諸如此類寫法 的事務即使在併發執行時遇到了丟失更新異常,也可以正確的完成轉賬操作,並不會被用戶感 知到: update account set realtimeremain = realtimeremain-100 where cuno='A'; update account set realtimeremain = realtimeremain+100 where cuno='B'; commit; 同上轉賬場景,如果實現方式是應用獲取了當前轉入轉出賬戶的餘額後,在應用中計 算出轉賬後兩賬戶的餘額,使用常值寫入餘額欄位,這樣的實現方式在事務併發執行時將會導 致錯誤: select realtimeremain from account where cuno='A'; --返回 1000 select realtimeremain from account where cuno='B'; --返回 1000 --應用中計算出兩賬戶轉賬後的餘額分別為 900 和 1100 update account set realtimeremain = 900 where cuno='A'; update account set realtimeremain = 1100 where cuno='B'; commit; 4. 計數器,秒殺場景的處理方法 如上一段所講,TiDB 採用了樂觀鎖機制,在事務的併發處理中,TiDB 會自動重試提 交時遇到衝突而發生退避的事務;而在使用了 select for update 或關閉 tidb_disable_txn_auto_retry 變數時,這種退避機制會失效,後提交的事務會被回滾。 select for update 被使用於計數器,秒殺,公用賬戶、理財產品、國債的餘額扣減等場 景,技術特點是併發的對同一行數據進行修改。傳統的單機 DBMS 多使用悲觀鎖來實現 select for update,在事務開始的時候即進行鎖檢查,如果事務所需要的鎖和數據上當前的鎖不 相容,就會發生鎖等待,等當前的鎖釋放後本事務才能執行。TiDB 在執行 select for update 時 相當於悲觀鎖系統中將鎖等待時間設置為 0,遇到鎖衝突的事務會執行失敗。 綜上,TiDB 不適合用於處理高併發的對同一行數據進行修改,事務使用了 select for update 語句,可以保證數據的一致性,但併發執行的事務中,只有最先提交的事務會成功,其 餘的併發請求都會被回滾。 處理計數器場景的最佳實踐是將計數器功能轉移到緩存(redis,codis 等)中實現,如 購買國債產品場景中,將國債餘額讀取到緩存中,在緩存中根據餘額與購買額度對請求隊列進 行控制,向合格的請求發放訪問資料庫的令牌,向購買額度超過餘額的請求返回餘額不足的錯 誤,拿到令牌的請求可以併發去修改資料庫中的產品餘額。 在應用了悲觀鎖的 DBMS 中,併發的 select for update 事務實際上是被排成隊列以串列 的方式執行的,因此性能不高,而使用緩存來處理計數器場景也有著較大的性能優勢。 5. “嵌套事務” 遵照 ACID 理論,併發事務間應彼此相互隔離,避免互相干擾。即事務不能“嵌套”。 在 Read Committed 隔離級別下,同一事務中如果存在多次讀取,每次讀到的都是當 時已經提交的數據,在多個事務併發執行時,一個事務內多次讀取的結果可能千差萬別,這種 現象被稱為“不可重覆讀(Non-repeatable Reads)”。應用於傳統金融行業的 RDBMS 產品中,預設隔離級別為 RC 的產品占有絕大部分市 場份額,而應用開發中也很少有人註意到隔離級別的設置,因此“不可重覆讀”往往被應用開發 人員認為是一種功能,甚至據此開發了基於“嵌套事務”的應用。 下圖中的案例描述了一個典型的“嵌套事務”的執行邏輯(紅色箭頭)。session 1 和 session 2 是該程式開啟的兩個會話,左側的 T1 ~ T8 是時間軸。程式在 T1 的時候開啟了一 個會話 session 1,然後執行了一個查詢(註意,在 MySQL 協議中,begin 的下一條有數據 訪問的語句被視為事務的開始)。之後的 T3 ~ T5,程式開啟了另一個會話 session 2,寫入 了一行數據後提交。然後程式繼續操作 session 1,在 T6 時它試圖更新這行剛剛寫入的數據 ,併在 T7 時提交了 T2 時開啟的本事務。 T8 時,session 1 執行了一條查詢語句,來檢查最初在 T4 時由 session 2 寫入的 k=1 對應行的 val 值。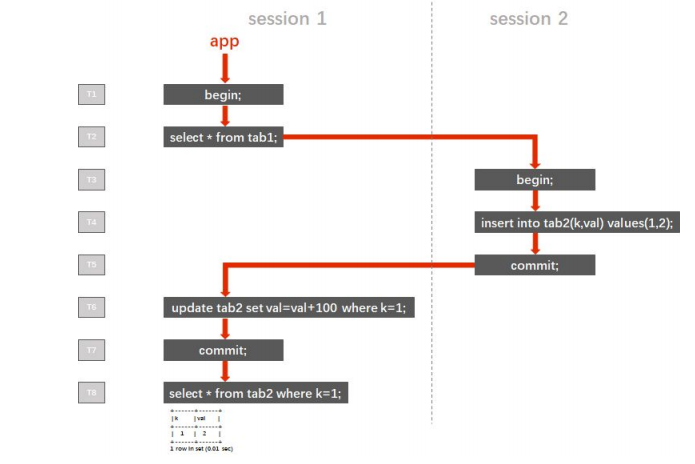
在 RC 隔離級別下,T8 時查詢的返回值為 102,看上去似乎滿足了“嵌套事務”的功能 需求。但實際上這是錯誤的,案例中僅使用單線程模擬了“嵌套事務”的場景,在實際業務的並 發請求下,多個事務在時間軸上交錯執行,交錯提交,將使“嵌套事務”的執行結果變得不可預 知。 在 SI 或 RR 隔離級別下,直到提交或回滾之前的任何讀取(不限於 tab1 表)所返回 的結果都對應事務開始的那個瞬間的一致性狀態。也就是說,在 T2 時,session 1 中的事務所能讀取到的數據就已經確定了,它就像是給資料庫在 T2 時的留下了一個快照,即使之後的 T3 ~ T5 開啟了新的 session 2,寫入數據並提交,也不會影響 T6 時 session 1 所讀取到的數 據,T6 未讀取到 k=1 的行,因此更新了 0 行。在 T8 時,查詢的返回值為 2。在 SI 或 RR 隔 離級別下,事務間的隔離度更高了,在併發請求下,其結果也是可預期的。 在這個案例中,如果只是想實現 session 1 能夠更新到 session 2 寫入的數據的需求, 只需要控製程序邏輯,在 T2 時的查詢語句之後添加 commit 步驟,及時提交這個查詢事務, 再執行後續步驟即可。
6. 不支持 Spring 框架的 PROPAGATION_NESTED 傳播行為 (依賴 savepoint 機制) Spring 支持的 PROPAGATION_NESTED 傳播行為會啟動一個嵌套的事務,它是當前事 務之上獨立啟動的一個子事務。嵌套事務開始時會記錄一個 savepoint, 如果嵌套事務執行失 敗,事務將會回滾到 savepoint 的狀態,嵌套事務是外層事務的一部分,它將會在外層事務提 交時一起被提交。下麵案例展示了 savepoint 機制:
mysql> BEGIN; mysql> INSERT INTO T2 VALUES(100);
mysql> SAVEPOINT svp1;
mysql> INSERT INTO T2 VALUES(200);
mysql> ROLLBACK TO SAVEPOINT svp1;
mysql> RELEASE SAVEPOINT svp1;
mysql> COMMIT;
mysql> SELECT * FROM T2; +------+ | ID | +------+ | 100 | +------+ TiDB
不支持 savepoint 機制,因此也不支持 PROPAGATION_NESTED 傳播行為,基於 Java Spring 框架的應用如果使用了 PROPAGATION_NESTED 傳播行為,需要在應用端做出調 整,將嵌套事務的邏輯移除。
7. 大事務 基於日誌的資料庫在面對大事務時,需要手動調大可用日誌的容量,以避免日誌被單 一事務占滿。 TiDB 中對於事務量有著硬限制,由於 TiDB 分散式兩階段提交的要求,修改數據的大 事務可能會出現一些問題。因此,TiDB 對事務大小設置了一些限制以減少這種影響(一行數據是一個鍵值對,一行索引也是一個鍵值對,當一張表只有 2 個索引時,每 insert 一行數據 會寫入 3 個鍵值對):
● 每個鍵值對不超過 6MB
● 鍵值對的總數不超過 300,000
● 鍵值對的總大小不超過 100MB 據此,涉及大量數據增刪改的事務(如批量的對賬事務等),需要進行縮減事務量的 改造,最佳實踐是將大事務改寫為分頁 SQL,分段提交,TiDB 中可以利用 order by 配合 limit 的 offset 實現分頁功能,寫法如下:
update tab set value=’new_value’ where id in (select id from tab order by id limit 0,10000); commit;
update tab set value=’new_value’ where id in (select id from tab order by id limit 10000,10000); commit;
update tab set value=’new_value’ where id in (select id from tab order by id limit 20000,10000); commit;

