
python day4 元組/字典/集合類知識點補充 (學習資源來自老男孩教育) 2019/10/7 [TOC] 1. 元組tuple知識點補充 創建和轉換 ,比如 元組的特性 元組的特性:元組的元素不可修改,但是元素的元素可以被修改。即元組的兒子不能變,但是元組的孫子可以變。 2. 字典dict的 ...
目錄
python day4 元組/字典/集合類知識點補充
(學習資源來自老男孩教育)
2019/10/7
1. 元組tuple知識點補充
- 創建和轉換
t = (11,22,33)
t = tuple(iterable),比如tuple([11,22,33])
- 元組的特性
元組的特性:元組的元素不可修改,但是元素的元素可以被修改。即元組的兒子不能變,但是元組的孫子可以變。
t = (11,22,33,['lan',{'name':'lanxing'}])
t[5]=44 #會報錯,因為元組的元素不可修改
t[3][0]='xing' #不會報錯,因為元組的孫子可以修改。2. 字典dict的知識點補充
- 創建和轉換
dict1 = {'k1':33,'k2':'xy'}
dict2=dict(k1=33,k2='xy')` 本質上都是用的第二種方法。
- fromkeys值的指向是同一個記憶體地址
d1 ={'k1':[],'k2':[],'k3':[]}
d1['k1'].append('x')
print(d1)
d2 =d1.fromkeys(d1,[])
x1 = d2['k1'].append('x')
print(d2) # 因為fromkeys(iterable,v),這個v指向是同一個記憶體地址3. 基本數據類型set
集合set是一個無序且元素唯一的元素集合。集合主要用來做關係測試。
- 創建一個集合
s1 = {1,2,'x','y',True}
s2 = set((1,2,'x','y',True)) set()中的參數是可迭代對象。
本質上集合set就是字典的keys。
- 集合的方法
add,clear,difference,difference_update,discard,remove,intersection,isdisjoint,issubset,
s2 = set((1,2,'x','y',True))
s2.add(3) #往集合裡面添加元素3
s2.add('z')
s1 = {1,2,'x','y',True,'name'}
s1.difference(s2) # 找s1中存在,s2中不存在的元素。即找差集
s1-s2 # 找s1中存在,s2中不存在的元素。與difference功能一樣
s1.difference_update(s2) # 找s1中存在,s2中不存在的元素,並更新自己,也就是s1把兩者之間的交集去掉。
s1.discard('x') #移除指定元素,元素不存在也不報錯。
s1.discard('x') #移除指定元素,不存在則會報錯。
s1.intersection(s2) #找交集,即s1中存在,s2中也存在的元素。
s1.isdisjoint(s2) #判斷是否沒有交集,有交集是False,沒有交集是False。
s1.issubset(s2) # 判斷s1是否是s2是子集合
s1.symmetric_difference(s2) #求對稱差集,即s1中存在,s2中也存在,但不是雙方都存在的元素。
s1 ^ s2 # 求對稱差集
s1.union(s2) #求並集。
s1 | s2 #求並集作業:
有兩個字典old_dict和new_dict,要求:
- 兩個字典的key相同的,將old_dict[key]中的值更新為new_dict[key]的值。
- new_dict.keys()存在的,在old中添加,不存在的,old中刪除。
old_dict =dict(#1=11,#2=22,#3=100)
new_dict = dict(#1=33,#4=22,#7=100)
# 字典的key相同即判斷是否有交集,所以第一步先找出交集
s1 = set(old_dict.keys())
s2 = set(new_dict.keys())
s3 = s1.intersection(s2)
# 使用for迭代來更新old中的值
for i in s3:
old_dict[i] = new_dict[i]
# 找到s1與s2的差集,併進行迭代,刪除舊元素。
s4 = s1 - s2
for i in s4:
old_dict.pop(i)
s5 = s2 - s1
for i in s5:
old_dict[i]=new_dict[i]
print(old_dict)4. 三元運算,又叫三目運算
if 1==1:
name ='x'
else:
name='y'
name ='x' if 1==1 else 'y' #這就叫三元運算。5. 深複製淺複製
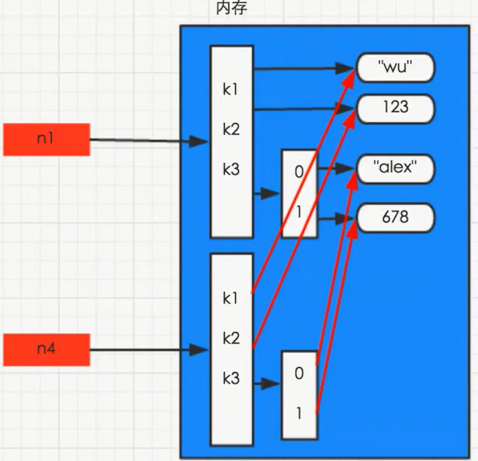
- 對於數字和字元串來說,不需要追究深淺複製的不同,因為他們是不可變對象,永遠指向的同一個記憶體地址。
- 對於列表,字典,元組,集合等,深淺複製是不同的。
淺複製時,只複製第一層記憶體地址,而深複製時,全部複製。
import copy
li1 = [1,2,[3,4]]
li2 = copy.copy(li1) # 淺複製,只是複製第一層元素的記憶體地址引用。即li2的嵌套列表的悠會影響原列表的嵌套列表。
id(li1) == id(li2)
li2[2].append(5)
li2.append(6)
print(li1,li2)
li3 = copy.deepcopy(li1) # 深複製,li3的任何修改都與li1無關了。
li3[2].append(5)
li3.append(6)
print(li1,li3)6. 函數
編程有三類:函數式編程,面向對象過程,面向過程編程。
- 面向過程編程:根據業務邏輯從上到下按順序實現功能,開發過程中最常見的操作就是粘貼複製,也就是將之前的代碼塊複製到現需功能。
- 函數式編程:即將指定的功能編成函數,想用的時候就拿出來。在函數式編程中,每一個功能都是一個函數。函數式編程,先考慮動詞。
- 面向對象編程:將不同對象進行分類,再考慮不同對象擁有哪些功能。開發時先考慮名詞,即不同的對象。
- 定義函數
函數就是擁有功能的代碼塊,可以不斷進行復用。
數學函數:f(x,y)=xy2,f是函數名,x,y是參數,xy2是函數執行語句。
- 定義函數的語法:
def funcname(x,y,z='hello',*args,**kwargs): #定義函數
print(x,y,z,args,kwargs) #函數的執行語句
return x,y,z,args,kwargs #函數的返回值- def是定義函數的關鍵字,funcname是函數的名稱,是一個變數,可以不斷修改,()裡面是函數的參數,return關鍵字後面的內容是函數的返回值。調用函數時,遇到return就結束了。如果沒有return關鍵字,則預設返回None(空)。
函數的調用,如果要使用函數,funcname(1,2),即函數名+括弧(參數1,參數2)即可,就會自動執行函數體(函數的執行語句)。
- 函數的參數
def func(x,y,z='hello'):
pass #pass關鍵字是什麼也不做,表示占位符- 括弧裡面的x,y,z叫做參數中的位置參數,等到執行的時候,func(1,2),即表示將1,2賦值給了x,y,也叫1,2傳入了參數x,y。這裡1,2叫做實參。
- z叫做預設參數,預設參數在函數調用時,是可選傳入的,如果不傳入,則預設z的實參就是'hello'。
- 函數調用時,參數的傳值預設按照位置形參的位置進行傳入。預設參數的實參必須在位置參數的後面。但如果指定形參傳入實參,可以不按照順序
func(1,2),func(y=2,x=1)是一樣的效果,沒有傳入形參z的實參,因為z有預設值。
func(1,2,4) 與func(y=2,z=4,x=1)是一樣的效果。
函數的動態參數:動態參數可以接收無限個實參。
def myfunc(x,y,z='hello',*args,**kwargs): # 其中*args叫做動態位置參數,**kwargs叫動態關鍵字參數
print(x,y,z,args,kwargs,sep=',') #函數的執行語句
return x,y,z,args,kwargs #函數的返回值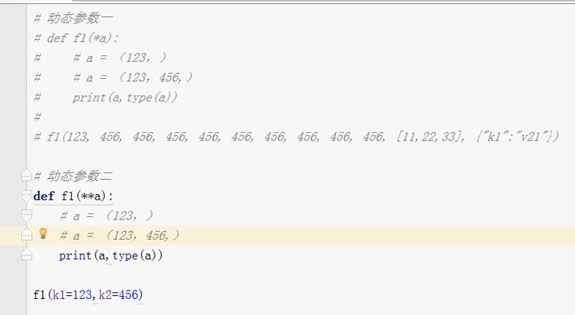
函數調用時,動態位置參數必須在動態關鍵字參數前面。 動態位置參數是一個元組,動態關鍵字參數是一個字典。
myfunc(1, 2, 'hellow world', 4, 5, k='hello,lanxing', my='lanxing')
1,2,hellow world,(4, 5),{'k': 'hello,lanxing', 'my': 'lanxing'}
- 為動態參數傳入列表,字典,元組時,列表,表示將列表中的每個元素都當作位置參數的實參傳入,字典,就是將字典中的每個鍵值對都當作關鍵字參數。
- 全局變數和局部變數
函數內部中的變數只作用於該函數內部,對外界沒有影響。
a=1 #全局函數,都有作用
def func1():
b=2 #局部變數
global a #通過關鍵字global 聲明a是全局變數,會影響函數外部的a
a = 3 #修改了全局變數a的賦值
print(a) #全局變數作用於整個頁面
print(b)
print(a) #這裡輸出的是修改了的全局變數a
print(b) #會報錯,因為局部變數只作用於函數內部
func1() #調用函數
def countLength(s):
li1 = []
li2 = []
li3 = []
for i in range(len(s)):
if s[i].isdigit():
li1.append(s[i])
elif s[i].isalpha():
li2.append(s[i])
elif s[i].isspace():
li3.append(s[i])
return len(li1), len(li2), len(li3), len(s)-len(li1)-len(li2)-len(li3)
#countLength(' 123 xyz aa 藍星***')
def countLen(obj):
if len(obj) >= 5:
print('%s長度大於5' % obj)
else:
print('%s長度小於5' % obj)
# countLen([1, 2, 3, 4])
def isSpace(obj):
a = 0
for i in obj:
for j in i:
if j.isspace():
a += 1
return a
li = ['x y', 'abc12 4 5', ' z y ']
# print(isSpace(li))
def chlist(li):
if len(li) > 2:
return li[:2]
return li
#print(chlist([1, 2, 3, 4]))
def oddSeq(li):
list1 = []
for i in range(len(li)):
if i % 2 != 0:
list1.append(li[i])
return list1
#print(oddSeq([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]))
dict1 = {'k1': 'v1v1', 'k2': [11, 22, 33, 44]}
def lenDict(**kwargs):
for k, v in kwargs.items():
if len(v) > 2:
kwargs[k] = v[:2]
return kwargs
# print(lenDict(**dict1))
def feibonaqi(n):
if n == 0:
return 0
elif n==1:
return 1
else:
return feibonaqi(n-2)+feibonaqi(n-1) #遞歸就是在函數內部調用自己,相當於數學函數中的f(x)=f(x-1),f(0)=0
print(feibonaqi(9))
i = 0
li =[]
while i<10:
li.append(feibonaqi(i))
i +=1
print(li,len(li))

