
構建ML模型的步驟 現在我們已經看瞭解到了一些ML應用程式的例子,問題是,我們如何構建這樣的ML應用程式和系統? 下圖總結了我們使用ML開發應用程式的方法,我們將在下麵更詳細地討論這個問題: 如上圖所示,建立學習模型的步驟如下: 問題定義:任何項目的第一步不僅是理解我們想要解決的問題,也定義了我們如 ...
構建ML模型的步驟
現在我們已經看瞭解到了一些ML應用程式的例子,問題是,我們如何構建這樣的ML應用程式和系統?
下圖總結了我們使用ML開發應用程式的方法,我們將在下麵更詳細地討論這個問題:

如上圖所示,建立學習模型的步驟如下:
問題定義:任何項目的第一步不僅是理解我們想要解決的問題,也定義了我們如何使用ML來解決問題。這第一步無疑是構建有用的ML模型和應用程式中最重要的一步。在開始構建ML模型之前,我們至少應該回答以下四個問題:
l 當前碰到了什麼問題?這是我們描述和陳述我們試圖解決的問題的地方。例如,一個問題描述可能是需要一個系統來評估小企業主償還小企業貸款項目貸款的能力。
l 為什麼這是個問題?重要的是要定義為什麼這樣的問題實際上是一個問題,以及為什麼新的ML模型將是有用的。也許我們已經有了一個可用的模型,但發現它的表現比以前差了;我們可能已經獲得了新的數據源,可以用來構建新的預測模型;或者我們希望現有的模型能夠更快地產生預測結果。認為這是一個問題,並且需要一個新模型的原因可能有多種。定義它為什麼是一個問題,將幫助我們在構建新的ML模型時,保持在正確的軌道上。
l 解決這個問題的方法有哪些?這是我們集思廣益解決給定問題的方法的地方。我們應該考慮這個模型是如何使用的(需要這是一個實時系統還是會作為批處理運行?),它是什麼類型的問題(這是一個分類問題,回歸,聚類,還是其他東西?),和我們需要什麼類型的數據模型。這將為構建我們的機器學習模型的接下來的步驟提供良好的基礎。
l 成功的標準是什麼?這是我們定義檢查點的地方。我們應該考慮我們將查看什麼指標,以及我們的目標模型性能應該是什麼樣的。如果我們正在構建一個將在實時系統中使用的模型,那麼我們還可以在運行時將目標執行速度和數據可用性設置為成功標準的一部分。設定這些成功的標准將幫助我們繼續前進,而不會在某個特定的步驟上停滯不前。
收集數據:擁有數據是構建ML模型最基本和最關鍵的部分,最好是擁有大量數據。沒有數據,就沒有模型。根據我們的項目,收集數據的方法可能有所不同。我們可以從其他供應商購買現有的數據源,可以抓取網站並提取數據,可以使用公共數據,也可以收集自己的數據。收集ML模型所需的數據有多種方法,但是在數據收集過程中需要記住這兩個數據元素—目標變數和特征變數。目標變數是預測的答案,而特征變數是模型用來學習如何預測目標變數的因素。通常,目標變數不會以標記的形式出現。例如,當我處理微博數據以預測每條微博的情緒時,我們可能沒有為每條微博標記情緒數據。在這種情況下,我們必須採取額外的步驟來標記目標變數。收集了數據之後,就可以進入準備數據步驟。
數據準備:收集完所有輸入數據後,需要準備一個可用的格式。這一步比想象的更重要。如果我們擁有雜亂的數據,而沒有為我們的學習演算法去清理它,那麼我們的演算法將不會從我們收集到的的數據集中很好地學習,也不會像預期的那樣執行。此外,即使我們擁有高質量的數據,如果我們的數據不是我們的演算法可以訓練的格式,那麼擁有高質量的數據是沒有任何意義的。至少我們應該處理以下列出的一些常見問題,以便我們的數據為下一步做好準備:
n 文件格式:如果我們從多個數據源獲取數據,那麼很可能會遇到每個數據源的不同格式問題。有些數據可能是CSV格式,而其他數據是JSON或XML格式。有些數據甚至可能存儲在關係資料庫中。為了訓練我們的ML模型,我們首先需要將所有這些不同格式的數據源合併到一個標準格式中。
n 數據格式:不同數據源之間的數據格式也可能不同。例如,一些數據可能將地址欄位分解為街道地址、市區、省份和郵政編碼,而另一些數據可能沒有。有些數據的日期欄位可能是美國日期格式(mm/dd/yyyy),而有些數據可能是英國日期格式(dd/mm/yyyy)。在解析這些值時,數據源之間的這些數據格式差異可能會導致問題。為了訓練我們的ML模型,我們需要為每個欄位提供統一的數據格式。
n 重覆記錄:我們經常會看到相同的記錄在數據集中重覆出現。此問題可能發生在數據收集過程中,在此過程中,我們不止一次地記錄了一個數據點,或者在數據準備過程中合併不同的數據集。擁有重覆的記錄可能會對我們的模型產生負面影響,在進行下一步之前,最好檢查數據集中的是否存在重覆記錄。
n 缺失值:在數據中看到一些記錄為空或缺失值也是很常見的。當我們在訓練我們的ML模型時,這也會產生不利的影響。有很多種方法可以處理數據中缺失的值,但是我們必須非常小心並很好地理解我們的數據,因為這可能會極大地改變我們的模型性能。處理缺失值的一些方法包括用缺失值刪除記錄、用平均值或中位數替換缺失值、用常量替換缺失值等等方法。在處理缺失值之前,研究我們的數據將會是意見非常有用的事情。
數據分析:現在我們的數據已經準備好了,是時候實際查看數據了,看看我們是否能夠識別任何模式並從數據中獲得一些見解。摘要統計和圖表是描述和理解數據的兩種最佳方法。對於連續變數,從最小值、最大值、平均值、中值和四分位數開始比較好。對於分類變數,我們可以查看類別的計數和百分比。在查看這些彙總統計信息時,還可以開始繪製圖形來可視化數據結構。下圖顯示了一些常用的數據分析圖表。直方圖常用來顯示和檢查變數、離散值和偏差的基本分佈。箱形圖經常用於可視化五位數摘要、離散值和偏差。散點圖經常被用來檢測變數之間明顯的兩兩相關關係:
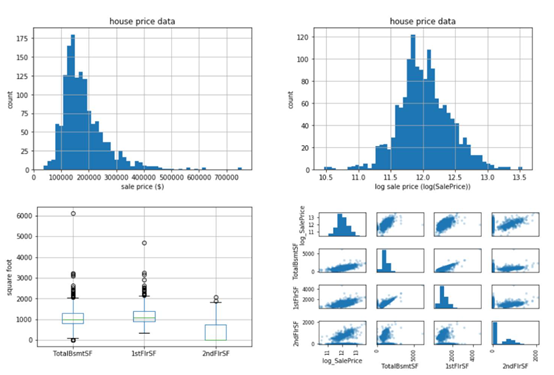
數據分析和可視化。左上:房屋銷售價格直方圖,右上:房屋銷售價格直方圖,左下:地下室、一層、二層建築面積分佈的箱形圖,右下:一層與二層建築面積的散點圖。
構造特征:構造特征是應用ML中模型構建過程中最重要的部分,然而,這是許多教科書和ML課程中討論最少的話題之一。構造特征是將原始輸入數據轉換為更有意義的數據,以供演算法學習的過程。例如,對於我們將要構建的微博情緒預測模型,我們的原始輸入數據可能僅在一列中包含文本列表,而在另一列中包含情緒目標列表。我們的ML模型可能不會學習如何用這些原始數據,來進行很好地預測每條博文的情緒。但是,如果我們轉換這些數據,列出每條博文中每個單詞出現的次數,那麼我們的學習演算法可以更容易地瞭解某些單詞的存在與情緒之間的關係。我們還可以將每個單詞與其相鄰的單詞(bigram)進行分組,並將每條博文中每個相鄰的單詞(bigram)的出現次數作為另一組特征。從這個例子中可以看出,構造特征是一種使原始數據更具有代表性和更能反映潛在問題的方法。構造特征是一門科學,也是一門藝術。構造特征需要良好的數據集領域知識,從原始輸入數據構建新特征的創造力,以及多次迭代以獲得更好的結果。在後面的文章中,我們將會學習一些具體的構造特征的方法。
訓練/測試演算法:一旦我們創建了自己的特性,就該訓練和測試一些ML演算法了。在開始訓練模型之前,最好考慮一下性能指標。根據我們正在解決的問題,對性能度量的選擇將會有所不同。例如,如果我們正在構建一個價格預測模型,我們可能希望最小化我們的預測與實際價格之間的差異,並選擇均方根誤差(RMSE)作為性能度量。如果我們正在構建一個信用模型來預測一個人是否能夠獲得貸款批准,那麼我們可能希望使用精確度作為性能度量,因為錯誤的貸款批准(假陽性)比錯誤的貸款不批准(假陰性)具有更大的負面影響。
一旦我們的模型有了具體的性能度量,我們就可以訓練和測試各種學習演算法及其性能。根據我們的預測目標,我們對學習演算法的選擇也會有所不同。下圖展示了一些常見的機器學習問題。如果我們正在解決分類問題,那麼我們可能希望訓練分類器,例如邏輯回歸模型、朴素貝葉斯分類器或隨機森林分類器。另一方面,如果我們有一個連續的目標變數,那麼我們就需要訓練回歸量,比如線性回歸模型,k近鄰,或者支持向量機(SVM)。如果我們想通過無監督學習從數據中獲得一些見解,你可以使用k-means聚類或mean shift演算法:
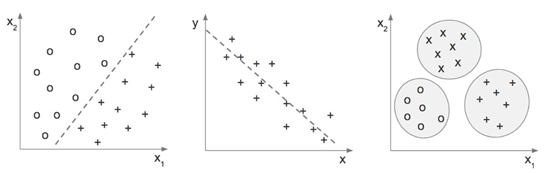
左:分類,中:回歸,右:聚類
最後,我們必須考慮如何測試和評估我們嘗試的學習演算法的性能。將數據集分成訓練集和測試集,並運行交叉驗證是測試和比較ML模型最常用的兩種方法。分裂成兩個子集的數據集的目的,一個用於訓練,一個用於測試。K-fold交叉驗證是評估模型性能的另一種方法。它首先將數據集分割成大小相等的K個子集,並將其中一個子集留作測試,其餘的進行訓練。例如,在3倍交叉驗證中,數據集將首先分成三個大小相等的子集。在第一次迭代中,我們將使用包#1和#2來訓練我們的模型,併在包#3上進行測試。在第二個迭代中,我們將使用包#1和#3在包#2上訓練和測試我們的模型,在第三個迭代中,我們將使用包#2和#3在包#1上訓練和測試我們的模型。然後,我們將性能度量進行平均,以估計模型的性能:
改進結果:到目前為止,我們已經有了一個或兩個表現相當不錯的候選模型,但是可能仍然存在一些改進的空間。也許我們的候選模型在某種程度上過度擬合了,他們可能不符合我們的目標,有多種方法可以幫助提高我們的模型和他們的性能如下:
l 超參數調優:我們可以調優模型的配置,以潛在地提高性能結果。例如,對於隨機森林模型,我們可以調整樹的最大高度或森林中的樹的數量。對於向量機,我們可以調整內核或成本值。
l 集成:集成是將多個模型的結果結合起來以獲得更好的效果。集成是同樣的演算法在不同數據集的子集進行訓練,提高結合不同模型相同的訓練集,進行訓練和疊加,模型的輸出作為輸入的元模型,學習如何結合子模型的結果。
部署:一旦準備好了我們的模型,就到了讓它們在生產環境中運行的時候了。確保在我們的模型完全部署之前,已經進行了大量的測試。為我們的模型開發監控工具也是一個很好的方法,因為隨著輸入數據的發展,模型性能會隨著時間的推移而下降。
總結
在本章中,我們學習了開發ML模型的步驟以及每個步驟中的常見挑戰和任務。在接下來的章節中,我們將遵循這些步驟來完成我們的項目,我們將更詳細地探索某些步驟,特別是在構造特征、模型選擇和模型性能評估方面。我們將根據要解決的問題類型,討論在每個步驟中可以應用的各種技術。
在下一章中,我們將直接應用ML的基本原理來構建垃圾郵件過濾的ML模型。我們將按照本章討論的構建ML模型的步驟,將原始電子郵件數據轉換為結構化數據集,分析電子郵件文本數據以獲得一些見解,最後構建預測電子郵件是否是垃圾郵件的分類模型。在下一章中,我們還將討論一些常用的分類模型評估指標。


