
在陽光明媚最適合打盹的下午, 特意靜音的手機竟然動起來了, 你沒看錯, 它震動了.... 上帝(顧客)來電, "報表查詢系統左側樹狀菜單中設備的中文名稱不能排序", 要增加排序功能....bu la...bu la... , 增加xxx ,增加xxx 開始乾吧! 原諒我上面那麼多廢話... 華麗的分 ...
在陽光明媚最適合打盹的下午, 特意靜音的手機竟然動起來了, 你沒看錯, 它震動了....
上帝(顧客)來電, "報表查詢系統左側樹狀菜單中設備的中文名稱不能排序", 要增加排序功能....bu la...bu la... , 增加xxx ,增加xxx
開始乾吧! 原諒我上面那麼多廢話...
華麗的分割線
直接上代碼
要排序的數據如下圖:

下麵是代碼(廢話):
1 // 數字字母中文混合排序 2 function arrSortMinToMax(a, b) { 3 // 判斷是否為數字開始; 為啥要判斷?看上圖源數據 4 if (/^\d+/.test(a.Name) && /^\d+/.test(b.Name)) { 5 // 提取起始數字, 然後比較返回 6 return /^\d+/.exec(a.Name) - /^\d+/.exec(b.Name); 7 // 如包含中文, 按照中文拼音排序 8 } else if (isChinese(a.Name) && isChinese(b.Name)) { 9 // 按照中文拼音, 比較字元串 10 return a.Name.localeCompare(b.Name, 'zh-CN') 11 } else { 12 // 排序數字和字母 13 return a.Name.localeCompare(b.Name, 'en'); 14 } 15 } 16 17 // 檢測是否為中文,true表示是中文,false表示非中文 18 function isChinese(str) { 19 // 中文萬國碼正則 20 if (/[\u4E00-\u9FCC\u3400-\u4DB5\uFA0E\uFA0F\uFA11\uFA13\uFA14\uFA1F\uFA21\uFA23\uFA24\uFA27-\uFA29]|[\ud840-\ud868][\udc00-\udfff]|\ud869[\udc00-\uded6\udf00-\udfff]|[\ud86a-\ud86c][\udc00-\udfff]|\ud86d[\udc00-\udf34\udf40-\udfff]|\ud86e[\udc00-\udc1d]/.test(str)) { 21 return true; 22 } else { 23 return false; 24 } 25 }
排序結果如下圖:
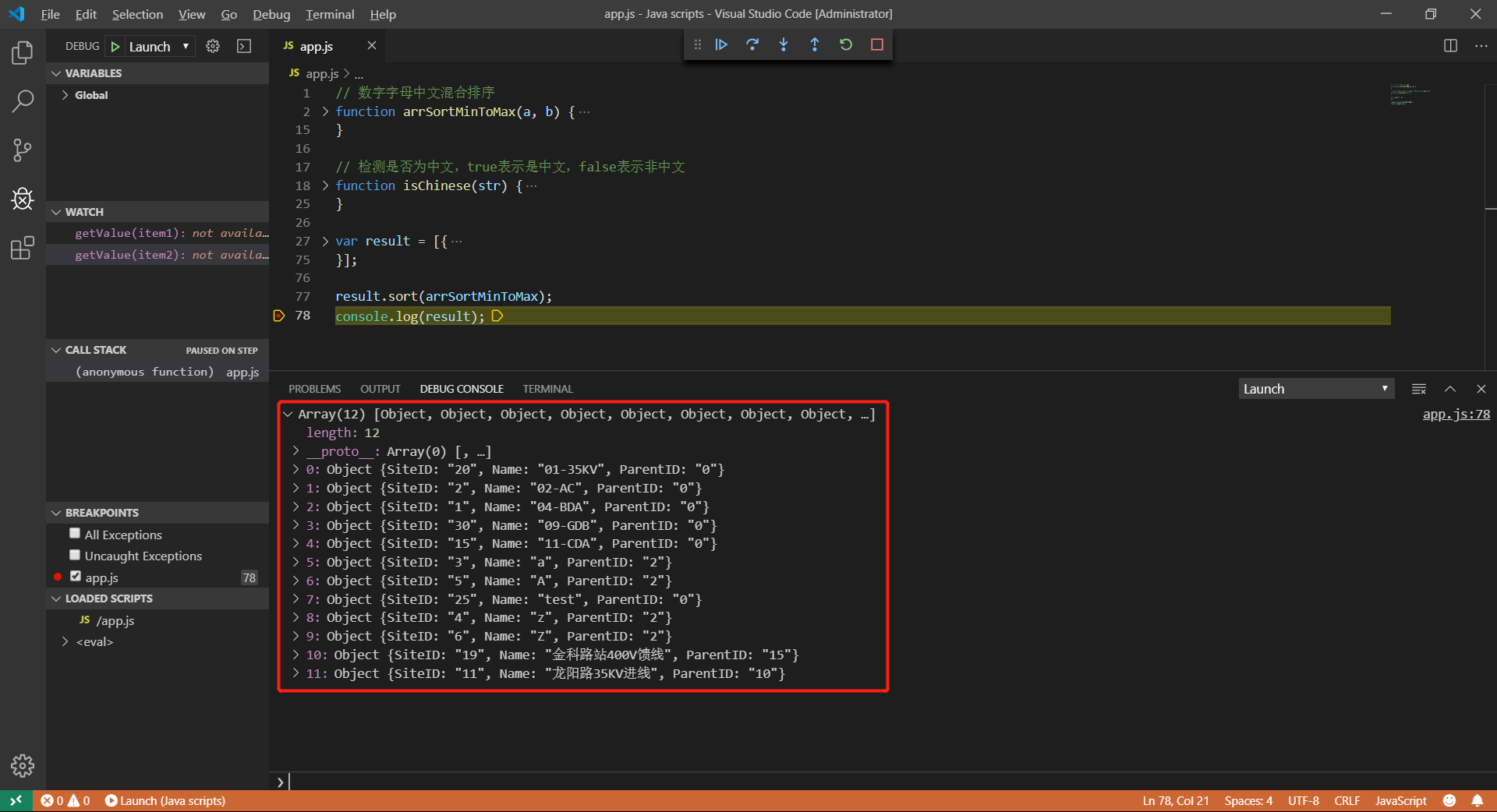
搞定收工!
沒錯, 實現這個排序實際用了不到20行代碼, 開始也當回事, 覺得可以分分鐘搞定(不擅長前端的猿), 結果折騰了大半天....
其實排序關鍵在中文拼音這塊, 還有就是"數字開頭"的字元串要優先按照前面的數字排序. 好了, 為了實現參閱了以下資料, 有興趣再優化的同學可以參考以下連接:
http://www.unicode.org/charts/
http://www.unicode.org/reports/tr38/#BlockListing
String.prototype.localeCompare() 詳解

